CDN日志全链路分析系统的实施
2020-10-26封万里王之伟池庆国孙志惠岑翼刚
[封万里 王之伟 池庆国 孙志惠 岑翼刚]
1 引言
CDN,全称内容分发网络(Content Delivery Network)[1],可以简单地将其理解成一个离客户很近的、可以从上面获取到完整的原始数据的服务器,它会定期和拥有原始内容的服务器进行同步,保证用户可以从上面获取到最新的内容。
对于大规模的CDN运营商网络来说,边缘节点[2]作为一级缓存部署在全国各地,用来响应用户的请求,如果用户访问的资源直接命中边缘节点,则直接返回响应,否则请求会进入内容中心节点[3]。内容中心节点往往是少数的,用来对边缘节点未命中的请求进行集中处理,如果内容中心未命中,用户请求则直接进入源站。上述流程的链路如图1所示。

图1 CDN服务的请求链路
中国移动CDN网络目前在全国拥有约1 800个边缘节点以及上海、北京两个内容中心。
边缘节点与内容中心节点在用户访问高峰期时段常出现命中率偏低、响应延迟偏大的现象,大大影响了用户体验。为了及时排查故障,CDN运维人员需要登录具体的节点服务器查看用户的访问日志并分析网络原因。一条完整的用户请求链条较长、用户日志量较大、各个环节的关联性较强,这些都给运维人员的人工分析工作带来很大的困难。本文设计并开发了一套全链路分析系统,借助大数据存储引擎与搜索引擎,将日志分析工作完全自动化,效率与准确性都得到了很大提升。下文详细介绍系统结构图。
2 本文方案
本文所提出的系统分为日志收集、日志检索、故障自动分析、人工修正4个模块;各个模块都提供独立的系统服务,互不干扰,在生产环境中避免了模块互相干扰造成的服务不可用问题;系统的使用者为CDN运维人员。
2.1 日志收集
该模块分为两个子模块,分别负责日志的采集与落盘保存,均是采用开源的数据加工工具进行操作,下面详细介绍各个模块的实现。
2.1.1 日志采集
结合引言中所述的用户请求的各个环节,CDN网络会产生4种类型的日志,分别是:边缘节点访问日志、边缘节点缓存日志、内容中心访问日志和内容中心缓存日志。这些日志由部署在边缘节点、内容中心节点上的Filebeat、Logstash组件负责收集用户日志并传送至专用的FTP服务器[4],并以文件的形式保存。当前业界还有Flume等日志采集工具[5],用户可以根据使用场景灵活选择。
2.1.2 日志存储
上一步文件里的日志由FTP上的应用负责定时导入Hive集群[6]。Hive脚本先进行简单指标的计算,如下载速率、首字节时延等,再由另一个定时任务将Hive里的数据定时导入ES集群[7]。Hive与ES集群共机部署,这大大缓解了不同组件之间由于网络质量造成的高时延、低可用问题。
目前中国移动的FTP服务器集群位于北京与上海,分别负责收集北方省份与南方省份的日志。相应地,Hive集群与ES集群也有两个。考虑到日志查询接口只部署在上海的机房,将北京与上海的ES集群设置成跨集群[8]服务,达到的效果是:部署在上海的应用可以检索到北京ES集群的数据,数据通过公网传输,同时两个集群均设置了密码,保障了数据跨公网传输的安全性。数据在组件间的流向如图2所示。
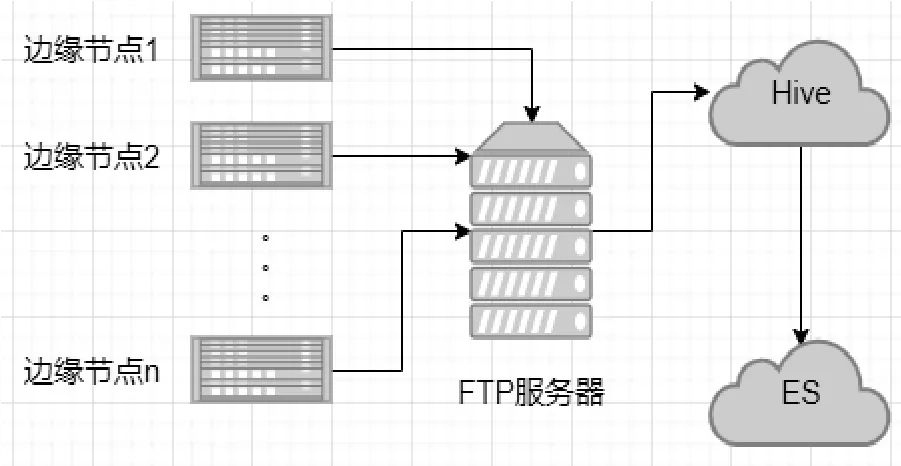
图2 本文方案的数据流向
Hive在数据流程图中起的作用是:有些字段需要基于原始字段进行二次计算,如下载速率、首字节延时[9]分别是基于原始日志里的流量、请求开始时间、请求响应时间等字段计算而来,所以Hive兼具存储与计算引擎的两大优点,并将额外计算出的字段导入ES集群。
生产环境的数据量约每秒3万条日志量,两个ES集群的配置参数为:128 G内存(其中分配给ES的内存为32G)、32核,集群规模为6台,其中Master节点有2个。实际使用中的数据导入延时小于5秒,ES集群的存储周期为6个月。
2.2 日志检索
日志检索模块包括高级检索与日志溯源两个子模块,高级检索即CDN运维人员自定义条件查询数据;日志溯源即原始日志的查询与展示。
2.2.1 日志高级检索
该子模块支持用户请求在整个链路中的日志关联查询,可以根据运维人员填写的日志检索条件进行边缘节点访问日志查询,并将查询结果以列表形式展示,具体展示哪些字段可以由运维人员自行选择。得益于ES底层基于倒排索引[10]的机制,查询跨度为一个月的数据时响应时间约600 ms。检索条件包括:开始时间与结束时间/用户IP/边缘节点IP/资源下载速率大于或小于某一个给定数值/响应状态码(支持多个状态码查询)/用户请求的域名/命中状态。列表最后一列为“日志溯源”功能。
2.2.2 日志溯源
为了从源头追溯用户请求日志,本文从边缘节点开始,对用户访问过程中的每个环节产生的日志增加一个字段 ”traceId”,含义为:链路ID,该ID在全网是唯一的。
日志溯源功能可以由运维人员自行选择查看四种类型的日志,每种日志的所需查看字段可独立选择,互不影响,点击查询后页面会显示用户请求的完整链路图,图中的内容包括。
(1)用户IP;
(2)边缘节点IP,若命中,则直接返回,否则进入下一步;
(3)进入内容中心,若命中,则直接返回,否则进入下一步;
(4)若命中,则直接返回,否则进行回源。
图3中的每个环节都会产生至少一条日志,原始日志有多个字段,为了给运维人员更直观地展示用户在每个环节所产生日志的原始信息,由前端将原始日志缓存,运维人员点击“原始日志”标签时则可以看到详细内容。
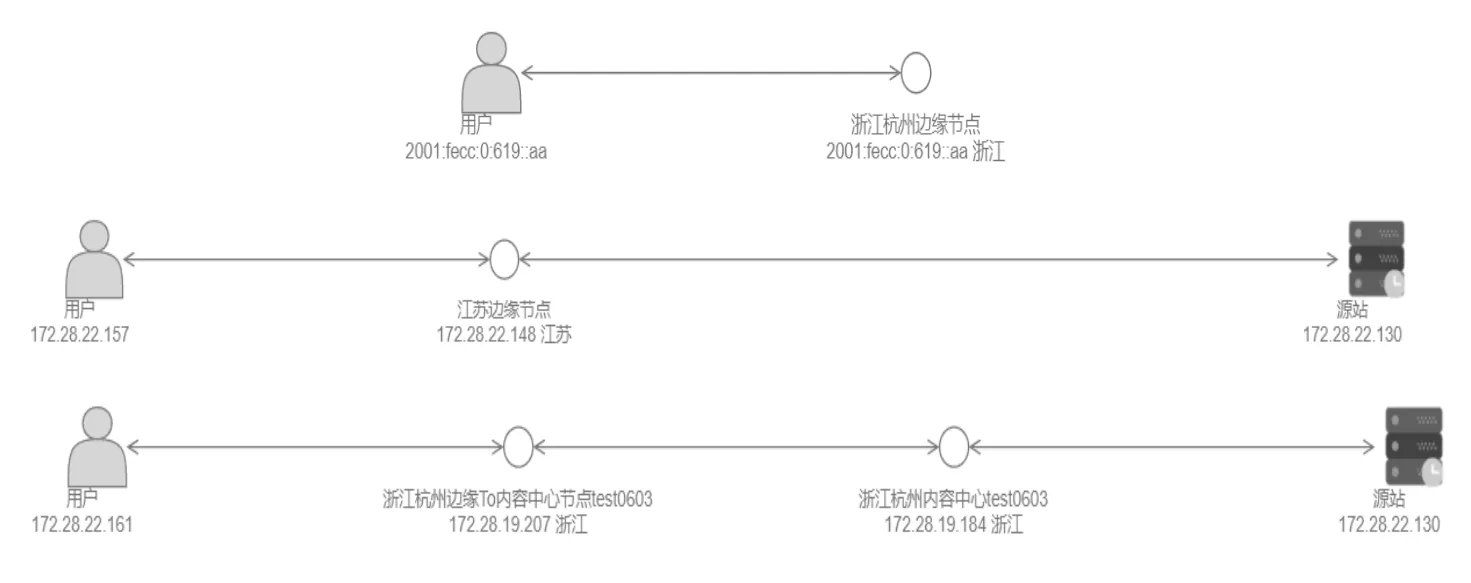
图3 用户请求拓扑图(分别对应(2)、(3)、(4)描述的场景)
2.3 故障自动分析
该模块可以根据指定条件下的日志及指标自动分析故障原因,目前支持分析响应状态码、首字节时延、下载速率3个指标。系统首先基于ES的分桶与聚合[7]机制,根据用户IP、请求IP等指标分桶,生成用户请求链路拓扑图,基于生成的拓扑图,系统的故障分析逻辑如下:
(1)节点服务状态
分析每个节点的服务指标和回源指标。服务指标包括:节点服务请求的状态码的数量及占比,状态码包含200、206、302、300、403、404、416、500、502、504、其他;响应码在2xx、3xx、4xx、5xx下首字节时延、下载速率和命中状态分别的数量和占比。
(2)故障分析结果
系统预设3个阈值[9],阈值为可配。
① 正常响应状态码占比阈值,响应状态码为正常值的占比阈值。若大于该阈值,则指标正常,否则异常响应状态码请求较多。
② 正常首字节时延占比阈值,首字节时延小于正常值的占比阈值。若大于该阈值,则指标正常,否则首字节时延大的请求较多。
③ 正常下载速率占比阈值,下载速率大于正常值的占比阈值。若大于该阈值,则指标正常,否则下载速率小的请求较多。
基于上述阈值直接展示故障分析后的汇总结果,描述客观现象,结果以表格的形式展示,如图4所示,用户看起来更加直观。

图4 故障分析结果
2.4 故障原因人工反馈
2.3节只计算分析了指标占比,不分析故障根因,由运维人员根据异常指标分析出故障根因后进行根因反馈(用于后续机器学习)。
运维人员在页面提交的故障根因存入ES集群,作为机器学习的数据源。提交的具体内容项包括:故障位置(精确到具体IP)、故障原因、故障现象等。由于机器智能分析[11,12]的功能还未开发,本文也会持续跟踪相关功能的开发与使用。
3 应用成效及分析
本文设计的CDN全链路分析系统已经部署在中国移动CDN网络中使用,流量高峰期支撑约3万QPS的数据量,一个月时间跨度的日志检索响应时间大约600 ms。运维人员针对“用户请求延时”故障的分析时间减少约40%,对“请求响应超时”故障的分析时间减少约45%,同时故障处理的准确性也有了很大提升,故障自动分析结果与实际情况基本吻合,CDN网络用户的体验有了明显改善。上述效果主要得益于ES高效的搜索机制,在大数据量下更能发挥出优势。
4 结论
本文针对CDN运维人员人工排查故障低效的情况,设计了一套全链路日志分析系统。通过在CDN网络的各个环节增加特殊的traceId字段追踪每个用户的请求,将CDN的分发、调度日志结合起来分析,对全网数据存储并开发日志搜索接口,根据CDN运维人员自定义的查询条件自动生成用户请求链路拓扑图与故障分析结果,同时运维人员可以在页面人工提交故障分析结果,减轻了人工工作量。但实际应用中发现,系统在流量高峰期时段偶发判断失误的情况,原因是在大流量期间,仅靠简单的阈值判断故障显得比较单一,没能够深层次地挖掘用户日志的各项指标。在后续工作中,将引入自适应阈值[13]与强化学习、反馈学习机制,利用大数据量智能分析链路各个环节的质量,为CDN的分发与调度模块提供决策依据。
