基于编辑距离算法的药房听似药品管理量化指标体系的建立*
2020-10-26胡小刚李拓颖陈万一
胡小刚,向 露,李拓颖,陈万一
(重庆大学附属肿瘤医院,重庆400030)
截至2019年,新版国家基本医保药品目录共计收载药品2 643个。医院及其药房的体量均在不断增加,很多医院在库药品品种上千。这虽给临床选择治疗药物带来了便利,但也给药品的有效管理和正确调剂使用带来了新的挑战。在药品日常管理及使用过程中,常遇到药品名称、外观或外包装相似的情况,这是导致调剂差错的重要原因[1-2]。根据美国药典发布的第八届Medmark年度数据报告,超过1 400种常用药物错误与相似药品相关[3]。当前药品在院内流动的环节,采用人工作业流程环节仍较多,药物调剂错误发生概率较高[4-5],需预先检测并及时防范。本研究中拟通过编程方法实现编辑距离求解,并结合药房相似药品的实际管理场景,探讨其在药房听似药品检测和管理中的应用。
1 对象与方法
1.1 编辑距离理论及程序实现
编辑距离又称Levenshtein距离,用于计算2个字符串间转变所需的字符编辑次数,其中编辑操作包括插入、删除、替换3种状态。在程序实现中需使用动态规划的思想,假设存在2个字符串S1和S2。假设fi,j表示由S1的前i个字符组成的子串S1i转变为S2前j个字符组成的子串S2j,则fi,j满足如下递推关系式。

由此即可计算出2个字符串间的编辑距离LD。则计算两者相似度S=1-LD/Max(n1,n2),其中n1和n2分别为S1和S2的字符长度。
以上运算过程,可以通过Matlab软件编程实现,构建一个函数文件Editdis用于后续应用调用。函数文件内容详见图1。
1.2 听似药品检测
考虑到药品名称除文字内容外,拼音(如前后鼻韵、卷翘舌等)也可能相似。因此,拟从汉字和拼音的相似性2个方面进行检测。药品名称从医院信息系统(HIS)药品字典中获取,按文献[6]方法编写VBA程序,调用getpy()函数将汉字转换为拼音。然后在Matlab程序中调用Editdis函数,可从不同维度(如总体概况、剂型分类概况等)对药品相似性进行计算。

图1 Editdis函数程序
1.3 听似药品管理量化指标体系
根据实践经验可知,2个药品名称需达一定相似度(S),才容易引起差错。假定这个相似性阈值为δ,即将S≥δ的药品作为听似药品的重点监管范围,并假定重点监管的总体相似药品对数为N(S≥δ)。为减少相似导致的差错,2011年版《三级肿瘤医院评审标准实施细则》要求相似药品分开码放,因此可考虑纳入位置信息作为分开码放的度量,用于评估相似药品的管理状况。此处建立“控制率”的概念,用于表征在S≥δ的总相似药品对数中,未成对摆放在特定区域范围内的比例。将听似药品对摆放位置处于同一药架的数量记作n1、听似药品对摆放位置处于同一药架层的数量记作n2,即药房听似药品摆放控制率记为:同架控制率V架=(1-n1/N)×100%(S≥δ),同层控制率V层=(1-n2/N)×100%(S≥δ)。据此可构建丰富的听似药品管理量化指标体系,以防范相关差错。
1.4 研究对象及实证分析
以住院药房812个在架药品为例,按图2所示方法,首先对所有药品的相似性进行汇总与分析,并根据预调研结果,取δ=0.70完成各类指标计算和统计。
2 结果

图2听似药品管理量化指标体系
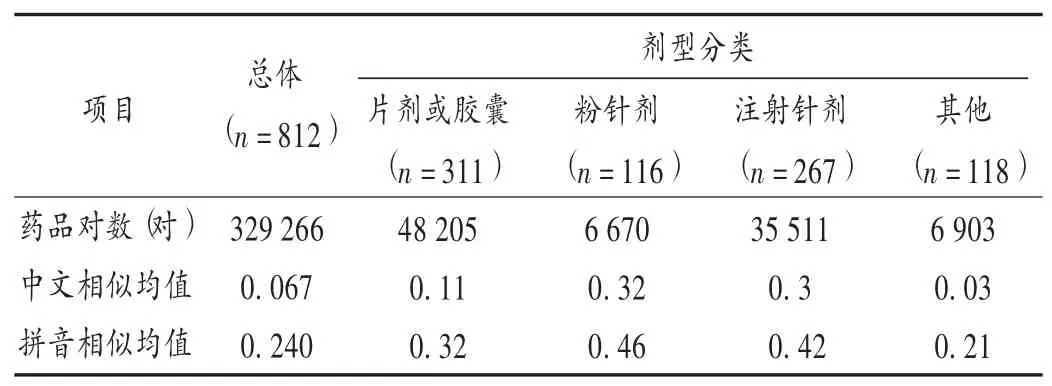
表1药品总体相似性
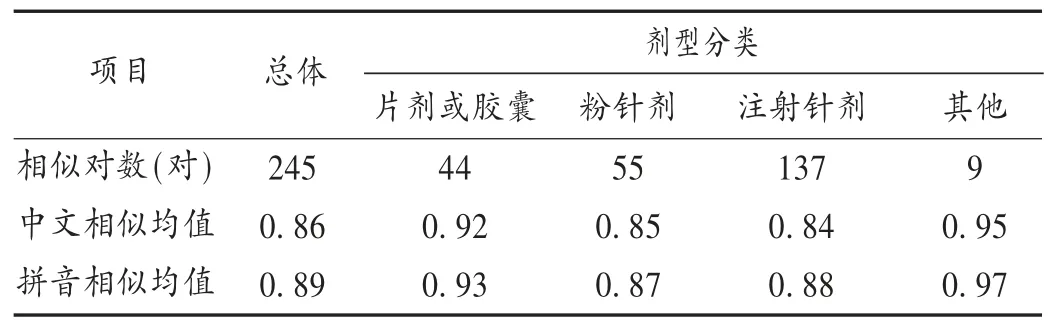
表2药品对相似性(δ=0.70)
结果见表1至表5。δ=0.70时,药品同架控制率为76.73%,同层控制率为95.92%。同层相似药品因字、音太相近,而又处于邻近位置,纳入重点优化管理药品目录。不同剂型药品中文和拼音相似性均小于0.5。便于后期优化。根据结果,住院药房需重点优化管理,药品目录按相似类型归类:同厂不同规格3对,同规格不同厂1对,不同规格不同厂1对,药名不同5对。提示这些药品最好重新调整摆放位置,避免摆放位置相近导致调剂差错。
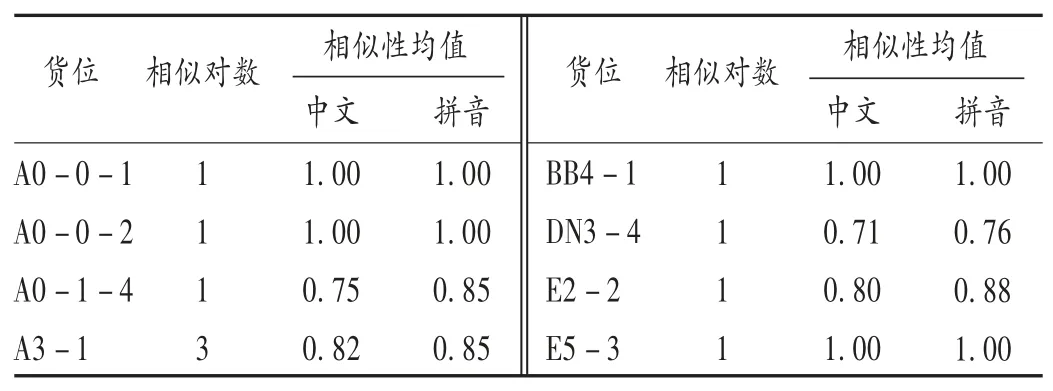
表3同层听似药品相似性
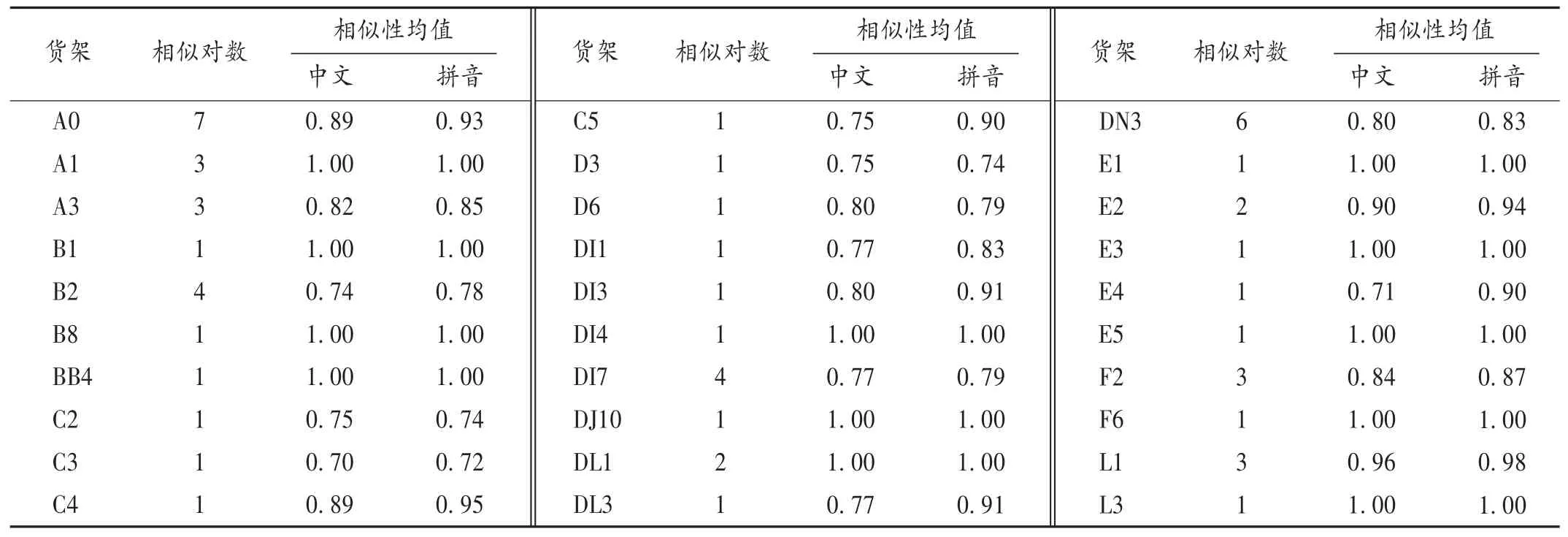
表4同架听似药品相似性
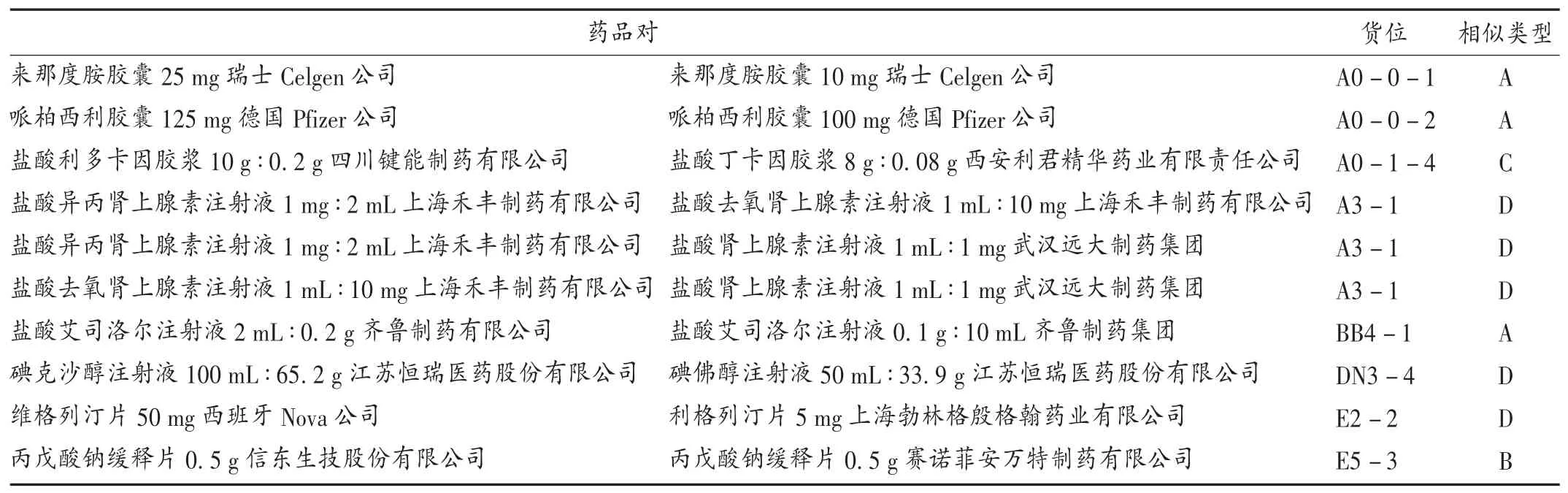
表5重点管理药品目录
3 讨论
药品管理使用环节中,处方、调剂、配置、给药等流程均可能出现错误[7]。工作量大、人员配备不足、外观/声音相似、缺乏知识/经验、分心/中断及配药团队内部的沟通等因素[4],被报道与调剂错误具有相关性,是目前药学工作中不可回避的现实状况。日常差错的防范主要基于既往差错分析及PDCA持续改进[8-9],属事后处理,且主要依赖人力完成,记录存在主观性,耗时较长。《三级肿瘤医院评审标准实施细则》等虽有相似药品分开码放的规定,但具体操作细则和管理量化尺度不明确。因此,对于相似药品引起差错的事前预防及其持续的风险性监督,尚缺乏有效的量化依据,缺乏科学化的管理和监督手段。有研究分析了调剂差错率、复核漏检率及错误发生率的内在关系,指出复核漏检率常高于调剂差错率,并与错误发生率相关性更高[10],提示事后差错的登记可能会忽略潜在的问题。
编辑距离是一种自然语言处理(natural language processing,NLP)领域文本相似度的算法,其可应用于拼写检查、句子相似度分析等多个方面[11]。本研究中将其引入药房听似药品的管理中,并通过程序算法实现计算,介绍了实现过程,构建了相关的量化指标体系。从住院药房药品管理的分析结果来看,该方法可方便计算出药品中文名称和英文名称的相似性,能有效分析药品名称相似性的总体情况,可根据阈值筛选相似药品对。同架/同层相似性分析结果可作为初步判断药品摆放状态及其合理性的依据,作为表征听似药品分开码放的客观量化监测指标。重点优化管理药品目录为后期药品货位优化、差错防范方向提供了改进思路。该系列指标还能持续用于听似药品管理的日常监督,如事前评估新进药物摆放位置是否合适,货位货架的增减是否恰当等。
近年来,医药行业的信息化建设快速发展。研究显示,可用机器学习减小处方错误和药品不良事件[12],通过分析医嘱和诊断声明数据来检测潜在的看似听似(look-alike/sound-alike,LASA)错误[13]和基于信息系统减少外观包装设计的相似性[14]。另有研究者通过文献回顾,汇总了避免相似药品用药错误的方法,包括设置标签、加强检查、信息系统等方面[15]。本研究中基于编辑距离算法建立药房听似药品管理量化指标体系,从药房药师实践角度进行听似药品量化管理探讨,为进一步探索信息化药房管理提供了思路。
