基于i-vector 的电子伪装语音鲁棒还原方法研究
2020-10-23郑琳琳张雄伟李嘉康张星昱
郑琳琳,张雄伟,孙 蒙,李嘉康,张星昱
(陆军工程大学指挥控制工程学院,南京,210007)
引 言
语音伪装是指通过改变说话人的个性特征,故意隐藏或伪造说话人的身份[1]。随着智能语音交互应用的不断发展,语音代表个人身份特征的场景日益广泛,伪装语音技术的出现给说话人身份的辨识带来很大的挑战。目前,利用各类变声器及变声软件可以对语音进行个性伪装,致使人耳甚至部分说话人识别系统无法辨识出说话人的身份,严重影响语音检验鉴定效果,使犯罪分子有机可乘[2-4]。因此,如何进行伪装语音的说话人身份识别已成为信息安全领域的一个重要且紧迫的课题。
语音伪装方法可以分为两种类型:人为伪装和电子伪装[5]。人为伪装是借助人本身的技能进行伪装,包括说话时采用捏鼻、咬物等方法;电子伪装是指采用电子设备或语音处理软件对说话人的原始语音进行变声伪装。电子伪装使用复杂高效的算法,以其高质量的伪装效果和便捷的实现方式,得到了越来越广泛的应用[6]。文献[7-9]的研究表明,语音经过伪装后,会明显降低说话人识别系统的准确率,而且不同的伪装方法对说话人识别的性能影响各异。实验发现,利用当前比较成熟的基于高斯混合模型(Gaussian mixture model,GMM)和通用背景模型(Universal background model,UBM)的声纹识别模型对电子伪装后的语音进行识别,等错误率(Equal error rate,EER)高达40% 以上[10],几乎无法辨认出伪装者的身份。因此,在鉴别伪装者的身份之前,首先需要对伪装语音进行还原处理。电子伪装语音的还原问题可以抽象简化为伪装因子的估计问题[11]。文献[12]通过动态时间规整(Dynamic time warping,DTW)模型进行伪装因子估计,再利用矢量量化(Vector quantization,VQ)模型进行说话人识别,一定程度上缓解了VQ 说话人识别系统对电子伪装语音识别率过低的问题。文献[10]利用基频比估计伪装因子,提出了一种改进的梅尔倒谱系数(Mel frequency cepstral coefficient,MFCC)提取算法,能够有效地从电子伪装的声音中还原出原始语音的MFCC。针对电子伪装后的语音,将该算法还原出来的MFCC 特征输入到GMM-UBM 的自动说话人确认(Automatic speaker verification,ASV)系统,说话人确认EER 仅为3%~4%,明显优于未经还原的MFCC 特征的40% EER。鉴于该方法的良好性能,本文将其设定为基线系统,并在其基础上进行改进研究。
实验发现,文献[10]所述的伪装因子估计方法对语音质量要求过于苛刻,对于真实情况下的含噪伪装语音的还原效果不是很理想。如何对真实含噪情况下的电子伪装语音进行还原,是一个更具挑战性的问题,对后续的伪装语音说话人身份识别具有决定性作用。鉴于此,本文将频域和时域伪装语音的还原问题抽象为伪装因子的估计问题,通过基于i-vector 的自动说话人确认方法估计伪装因子,并引入对称变换进一步提高估计效果。该方法借助于i-vector 的噪声鲁棒性,提高了真实含噪场景下的伪装因子估计的精度,从而改进了电子伪装语音还原的效果。在目前常用的说话人识别数据库VoxCeleb1[13]上的实验表明,利用该方法估计的伪装因子错误率为4.49%,低于基频比伪装程度估计方法的9.19%,为准确进行电子伪装语音说话人身份的辨识提供了前提条件。
1 电子伪装语音
电子语音伪装的目的是改变语音给予人耳的听觉感受,最直接的变化就是改变语音的音调(Pitch)。提高音调,语音变得尖锐;降低音调,语音变得低沉。随着伪装程度的加深,正常语音与伪装语音的差异增大。本节首先介绍电子伪装的工作原理,然后给出电子伪装语音伪装程度的量化表示。
1.1 电子伪装工作原理
音调被用来描述人对语音频率的感知量,电子语音伪装改变音调本质上是按照不同的比例因子对频谱进行压缩和扩展。语音基音频率(Fundamental frequency, FF)是指发浊音时声带振动所引起的周期性振动频率,一般用F0表示,它反映了语音激励源的重要特征,是语音信号短时内较稳定的频率分量。假设原始语音音调为p0、基频为f0,经伪装之后的音调为p1、基频为f1,音调和基频存在式(1)所示的变换关系

式中,α 是音调变换的比例因子。根据伪装变换的方式不同,电子伪装可以分为2 类:频域伪装和时域伪装。这2 类伪装方式都可以通过比例因子α 来定量描述。
1.1.1 频域伪装
频域伪装是指通过直接在语音频域内拉伸或压缩频谱来提高或降低音调的伪装方式,该方式可以改变语音的音调而保持语音节奏不变。
语音频域分析最常用的方法是傅里叶分析法。因为语音波是一个非平稳过程,因此适用于平稳周期信号的标准傅里叶变换不能直接用来表示语音信号,而应该用短时傅里叶变换(Short-time Fourier transform,STFT)对语音信号的频谱进行分析。STFT 首先将信号分帧,然后对每一帧语音信号进行快速傅里叶变换(Fast Fourier transform,FFT),得到频域分析结果[14]。
假设| F ( k ) |和ω( k )分别代表原始语音频域分析后第k 个频率点处的瞬时幅度和瞬时频率,α 是音调变换的比例因子。频域伪装变换根据式(2),将瞬时频率ω( k )利用比例因子α 修改为ω'(αk ),即
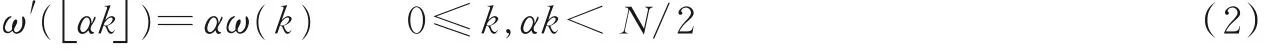
瞬时幅度| F ( k ) |利用线性插值法进行相应的拉伸或压缩变换
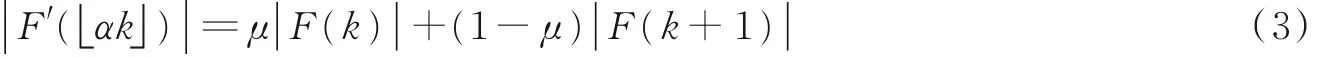
式中,0 ≤k,k' <N 2,k = k' α ,μ = k' α - k。为了简单起见,仍使用k 作为伪装后的瞬时幅度| F'|和瞬时频率ω' 的坐标尺度,记为| F'( k ) |和ω'( k )。根据| F'( k ) |和ω'( k )可得修改后的FFT 系数F'( k )。对F′( k ) 执行快速傅里叶逆变换(Inverse fast Fourier fransform,IFFT),即可得到频域伪装的语音信号。
1.1.2 时域伪装
时域伪装一般通过调整采样率和采用基音同步叠加(Pitch-synchronous overlap and add method,PSOLA)相结合的方法来实现。调整采样率能够改变语音信号的FF 从而改变音调。但是语音信号时频结构之间的约束性使得信号的时域特性和频域特性紧密相关,只利用调整采样率生成的伪装语音往往听起来不够自然,需要采用PSOLA 对语音进行进一步处理。PSOLA 可以对语音的基频、时长和短时能量等韵律特征进行修改,使修改之后的语音与原来语音频谱有着基本相同的包络[15]。这种伪装方式既改变了语音的音调,又改变了语速。
PSOLA 首先检测语音信号x ( t )的音调的位置和轮廓,加窗提取基音周期函数P ( t )。利用式(4)对语音信号进行重采样,修改基音周期函数P ( t ),在误差最小准则下重复或丢弃部分语音帧做补偿,其中α 是伪装比例因子

语音经过时域伪装后,语音时长发生变化的同时音调也会得到相应升降调处理。假设原始语音语速为v0,经伪装之后的语音语速为v1,根据式(1),对于时域伪装语音存在如式(5)的关系

式中,比例因子α 不仅是时域伪装语音的音调变换比和基频变换比,还是时域伪装语音的语速变换比。
1.2 伪装程度的量化表示
语音学中,音调通常用12-半音法来测量,表示音调最多可提高或降低12 个半音[16]。原始语音音调p0与伪装后语音音调p1之间存在着变换关系

式中,s是半音尺度因子,表示提高或降低s个半音。本文将半音尺度因子s称为伪装因子,用来量化表示电子伪装语音的伪装程度。如果伪装因子s>0,说明提高了s个半音;如果s<0,说明降低了s个半音;如果s= 0,说明未改变音调。
根据式(1,6)可知,音调变换比例因子α和伪装因子s之间的变换关系为

2 伪装因子估计基线方法
电子伪装是按照不同的比例因子对频率分量进行缩放,从而改变语音的音调。考虑到伪装前后基频的变化能反映频率分量整体的缩放程度,Wang 等[10]提出用基频比来估计伪装因子,进而还原语音,其原理如图1 所示。该方法根据待测语音与注册语音的基频比来估计伪装因子,利用估计出的伪装因子修正待测语音的MFCC,从而得到还原后的MFCC 特征。将提出的方法作为特征还原工具应用于GMM-UBM 说话人识别系统的前端,可提高电子伪装语音伪装者的识别准确率。在TIMIT 语音库上的实验表明,估计所得的伪装比例因子α' 与真实的比例因子α较接近,平均误差也很小,最大错误率在1.6% 到7.7% 之间,说明基频比估计作为伪装还原的手段是可行的。

图1 利用基频比确定伪装因子原理图Fig.1 Estimation of disguising factor by the ratio of fundamental frequencies
本文将文献[10]中提出的利用基频比估计伪装程度的算法作为基线系统。在训练阶段,提取伪装嫌疑人Sj的基频f0的平均值fj;在测试阶段,计算待检测语音Yi的基频f0的平均值fY,通过式(8,9)估计出伪装因子s'

基于基频比的伪装因子估计方法首先利用简化逆滤波跟踪法(Simplified inverse filter tracking,SIFT)提取基频[17],考虑到每条语句两端发音的不稳定性,舍弃基频序列的前15% 和后15% 数据,保留中间的70% 数据用来计算基频平均值[10]。
然而,基频提取准确度与语音质量有很大关系,当待测语音中含有环境噪声或者捏鼻、捂嘴等人为伪装时,基频提取会产生较大误差。对比实验发现,该基线系统对语音质量要求过于苛刻,对于真实情况下的含噪语音的伪装因子估计结果不是很理想,相关实验结果将在第4 节给出。真实含噪场景下的电子伪装语音还原是一个更具有实际应用价值的问题,对于推动电子伪装语音身份鉴定技术的应用和发展具有重要作用。因此,本文借助于ASV 系统的噪声鲁棒性,利用ASV 系统估计伪装因子,并引入对称变换进一步提高估计精度。
3 基于说话人确认的伪装因子估计方法及改进
本节首先介绍基于说话人确认的伪装因子估计方法,然后引入对称变换提高自动说话人确认估计伪装因子的精度。该方法以目前发展比较成熟的基于i-vector 的说话人确认模型为基础,通过概率线性判别分析(Probabilistic linear discriminant analysis,PLDA)最优得分时的自变量取值来估计伪装因子,从而实现电子伪装语音的还原。
3.1 基于说话人确认的伪装因子估计
说话人确认是说话人识别任务的一种,旨在利用语音信号中能反映说话人生理和行为的特征来判断两段语音是否来自同一个说话人。近年来,说话人确认方法的性能得到了显著提高,如Reynolds 在实验室环境中使用TIMIT 语音数据库对630 个人进行实验,识别率近乎达到100%[18]。现实使用中,说话人确认被应用于访问控制、交易认证和军事侦察等诸多涉及逻辑和物理访问的真实身份验证场景[19]。
基于GMM-UBM 和i-vector 的说话人确认方法是目前发展比较成熟且被广泛采用的说话人确认模型,原理如图2 所示。该模型首先对提取的语音信号的特征(如MFCC 等)在大量语料上训练一组GMM-UBM 作为通用背景。 在注册和测试阶段,从待测语音S中提取特征,并将这些特征作为观测值对训练好的GMM-UBM 做最大后验概率估计(Maximum a posteriori,MAP),得到高斯超矢量,并进一步提取说话人的特征i-vector,用λ表示[20]。通过对比注册语句和测试语句所提取的i-vector 的相似程度,即可完成2 条语句是否来自同一个说话人的判决任务。
基于说话人确认系统的伪装因子估计方法如图3 所示。该方法通过遍历伪装因子的理论取值范围,对待测伪装语音进行逐一还原,然后说话人确认系统对每条还原语音与伪装嫌疑人的语音进行打分,得分最高的还原语音对应的伪装因子即认为是正确的伪装因子。本文中说话人确认模型选择了通过GMM -UBM 提取的i-vector,具体步骤如下:
(1)训练阶段,利用伪装嫌疑人Sj的正常语音进行注册,通过说话人确认中的特征提取部分计算得到该说话人的注册特征λj;
(2)测试阶段,待测语音Yi是经过电子伪装的语音信号,但伪装因子未知,根据电子伪装语音的变声规律,利用伪装因子的理论取值s(3 ≤|s| ≤11,s∈Z)对待测语音Yi的频谱特征进行还原,而后经过Griffin_Lim 算法[21]得到还原语音Yi(s);
(3)利用说话人确认分别提取每个因子的还原语音Yi(s)的特征,与伪装嫌疑人Sj的注册特征λj计算得分,按照式(10),分数最高的还原语音对应的伪装因子即为估计所得的伪装因子s'。

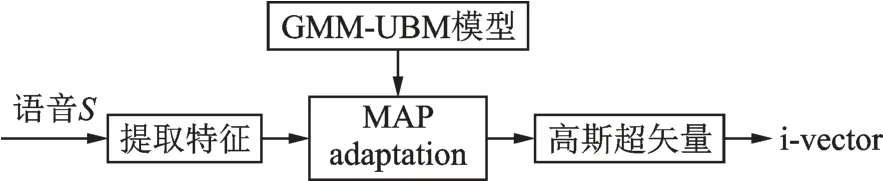
图2 基于GMM-UBM 的i-vector 提取方法Fig.2 The i-vector extraction by GMM-UBM
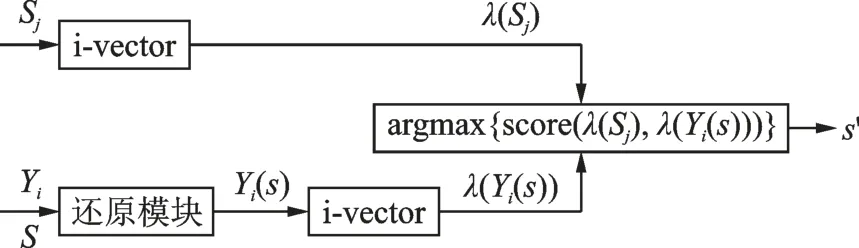
图3 基于说话人确认的伪装因子估计方法Fig.3 Estimation of disguising factor by automatic speaker verification
3.2 基于对称变换的伪装因子估计
语音经过升调(s>0)电子伪装后,频率范围拉伸,原始语音的高频部分会被丢弃。因此,升调电子伪装语音的还原过程需要将频率范围压缩,并且需要将高频部分的数据额外补全。然而,高频部分的频谱数据补全过程中会存在误差[22],导致升调电子伪装语音的还原语音与原始语音存在一定差距,还原语音和原始语音的频谱对比图在第4 节中给出。所以第3.1 节介绍的方法对升调电子伪装语音的伪装因子估计存在潜在误差。为提高升调电子伪装语音的伪装因子估计精度,本节通过引入伪装因子的对称变换,对基于说话人确认的伪装因子估计方法进行改进,如图4 所示。具体步骤如下所述:
(1)注册阶段,通过将伪装因子遍历取值范围3 ≤s≤11 来修改伪装嫌疑人Sj的语音,加上该说话人的正常语音,共得到10 组语音,所以注册阶段可得到该说话人的10 个模型(每组语音注册1 个模型),如图4 左半部分所示;
(2)测试阶段,仅利用伪装因子的降调理论取值范围对待测语音Yi进行还原,即-11≤s≤-3,得到还原语音Yi(s),如图4 右半部分所示;
(3)计算伪装嫌疑人Sj的正常语音模型与还原语音Yi(s) 的得分score-11~score-3,伪装嫌疑人Sj的9 个升调伪装语音模型与待测语音Yi的得分score3~score11,比较上述18 个得分,最高分对应的伪装因子就是估计所得的伪装因子s',如图4 中间虚线框所示。
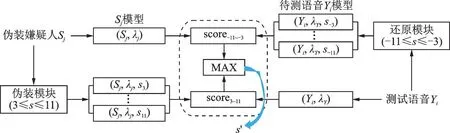
图4 利用对称变换改进基于说话人确认的伪装因子估计方法Fig.4 Improving estimation of disguising factor based on automatic speaker verification by symmetric transform
4 仿真实验及结果分析
4.1 实验设置
4.1.1 电子伪装语音生成
实验用的电子伪装语音由SoundStretch 音频处理软件产生。SoundStretch 可以对音频文件执行实现变速不变调(Rate)、变调不变速(Pitch)、变速同时变调(Tempo)3 个操作。由于Rate 处理对说话人确认系统以及人耳辨识干扰不大,这里只考虑基于频域伪装的Pitch 处理和基于时域伪装的Tempo 处理作为变声手段。当伪装程度过小或过大时,伪装效果不明显或不能辨别出语义特征,对说话人确认系统以及人耳辨识系统的威胁很小。因此,本文考虑了18 种伪装程度的伪装语音,对应伪装因子取值范围为+3~+11 以及-3~-11。
4.1.2 数据集
实验用的数据集包括TIMIT 和VoxCeleb1 两个语音数据集。
由德州仪器(Texas Instruments, TI)、麻省理工学院(Massachusetts Institute of Technology, MIT)和斯坦福研究院合作构建的声学-音素连续语音语料库TIMIT 是一个评价语音识别和说话人识别常用的权威语音库,包括630 人8 个不同地区的美国方言录制的音频信息。该语音库采用16 kHz 采样率、16 位量化和RIFF/WAV 格式,每段录音的时长约为3 s。实验利用该语音库训练GMM-UBM 模型。
VoxCeleb1 是一个视听数据集,含有语音数据和视频数据,其中语音部分由从上传到YouTube 的采访视频中提取的语音短片组成,带有真实噪声,且噪声出现时间点无规律。说话者覆盖到了不同年龄、性别、口音;语音的场景也非常丰富,包括红毯走秀、室外场馆、室内录影棚等,属于完全真实的英文语音[13]。本文随机选取该数据集中100 位说话人,每人11 条语音,其中10 条用来注册1 条用来测试。测试语音利用SoundStretch 音频处理程序进行不同程度的伪装处理,得到18 组伪装因子为+3~+11以及-3~-11 的频域电子伪装语音和18 组伪装因子为+3~+11 以及-3~-11 的时域电子伪装语音,每组含有100 位说话人各1 条待测电子伪装语音。
4.2 伪装因子估计结果
4.2.1 基线系统估计伪装因子结果
在含噪语音库VoxCeleb1 的频域伪装数据集上利用基频比估计伪装因子,实验结果如表1 所示。
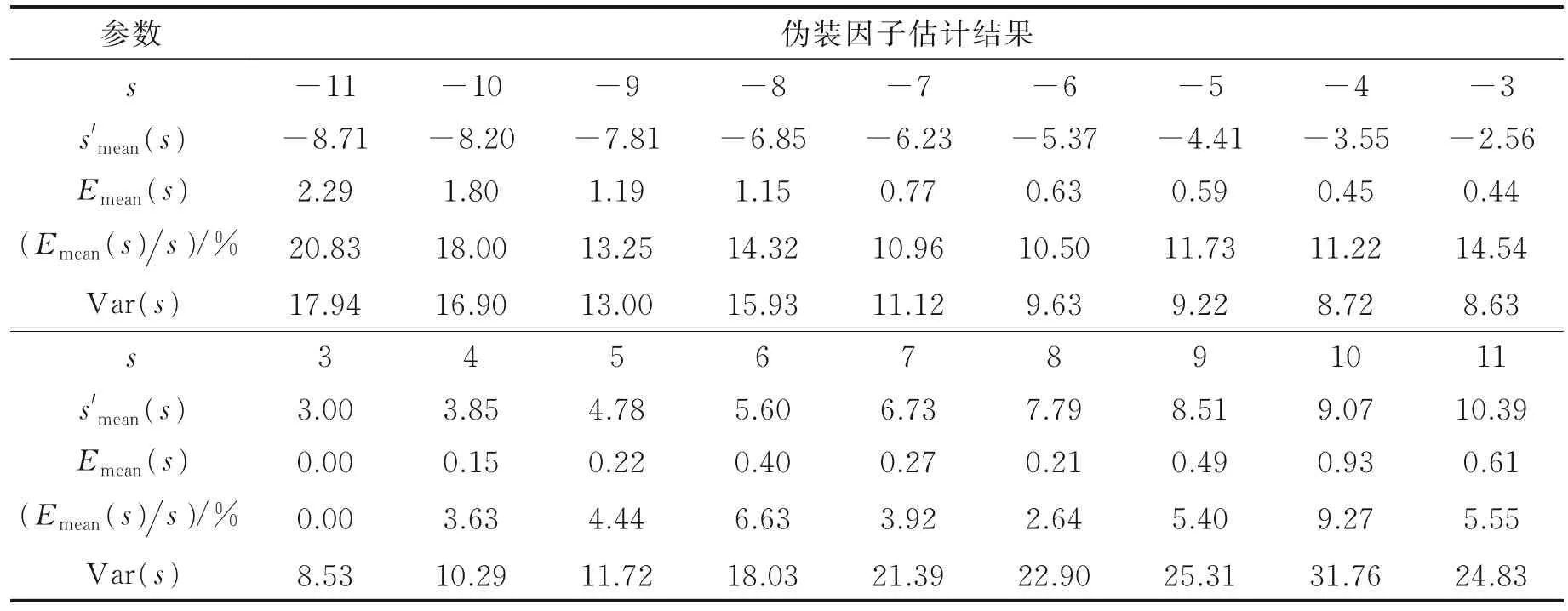
表1 VoxCeleb1 频域伪装数据集上利用基频比估计伪装因子的实验结果Table 1 Performance on the estimation of disguising factor using F0-ratio on VoxCeleb1 with frequencydomain disguise
表1 中,s是真实伪装因子,s'mean(s)是每组数据估计出的伪装因子的平均值,Emean(s)=|s'mean(s)-s|是平均误差,Emean(s)s是平均误差率,Var(s)是每组实验数据的方差。
从表1 中可以看出,随着伪装程度增大,伪装因子估计误差也呈增大趋势,最大错误率高达20.83%。表1 的实验结果还表明,估计所得的伪装因子平均错误率达9.27%,平均方差为15.88,估计偏差远大于干净语音库上的实验结果。基于基频比的伪装因子估计方法在VoxCeleb1 的时域电子伪装数据集上也得到了类似的结果,此处不再赘述。
4.2.2 利用说话人确认估计伪装因子的实验结果
利用GMM-UBM 和i-vector 的说话人确认方法对VoxCeleb1 频域伪装数据集和时域伪装数据集分别进行伪装因子估计实验,实验结果在表2 和表3 中给出。利用说话人确认系统估计的伪装因子在频域伪装数据集上的平均错误率为12.26%、平均方差为5.05,在时域伪装数据集上的平均错误率为14.13%、平均方差为6.44。
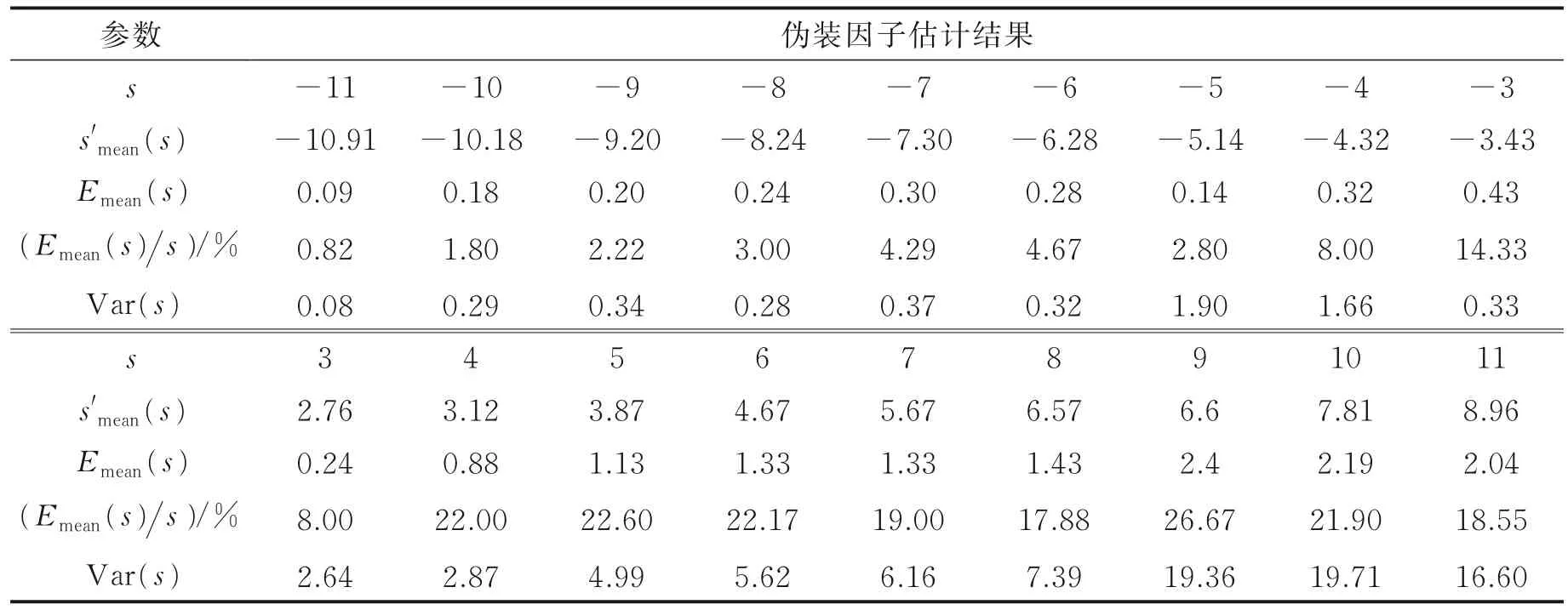
表2 VoxCeleb1 频域伪装数据集上利用ASV 估计伪装因子实验结果Table 2 Performance on the estimation of disguising factor using ASV on VoxCeleb1 with frequency-domain disguise
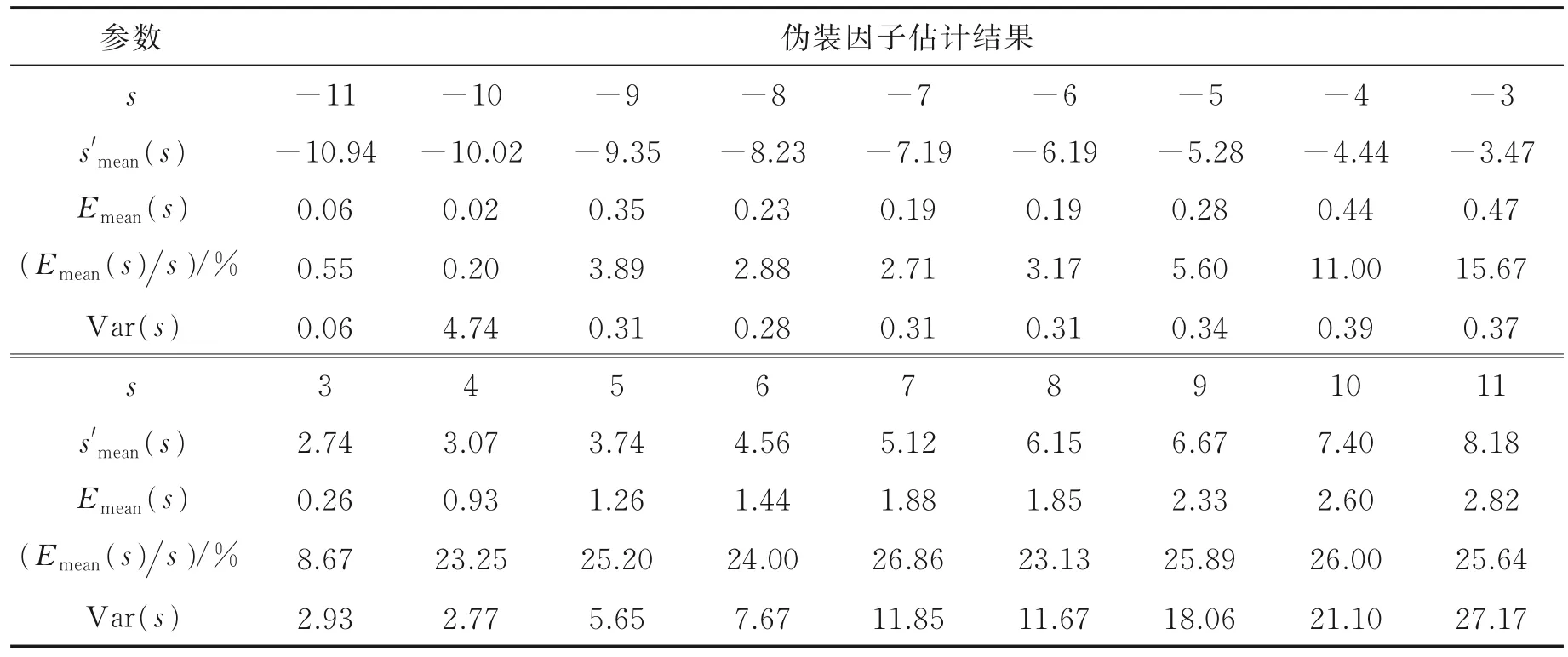
表3 VoxCeleb1 时域伪装数据集上利用ASV 估计伪装因子实验结果Table 3 Performance on the estimation of disguising factor using ASV on VoxCeleb1 with time-domain disguise
当s<0 时,估计的伪装因子偏差较小,方差最大值仅为4.74,说明基于说话人确认的伪装因子估计方法对降调伪装语音的效果较好。当s>0 时,估计的伪装因子方差仍明显小于基线系统,但偏差较大(≈20%)。我们做出正常语音、升调伪装语音以及升调伪装语音的还原语音的频谱图进行对比,如图5所示。正如3.1 节所指出的,对升调语音进行还原时,高频部分不能被有效恢复。虽然还原后的语音不影响人耳听觉效果(人耳听觉对低频信息敏感,对高频信息不太敏感),但丢失了大量高频信息,对说话人确认方法的性能造成了较大影响,从而影响了伪装因子的准确估计。
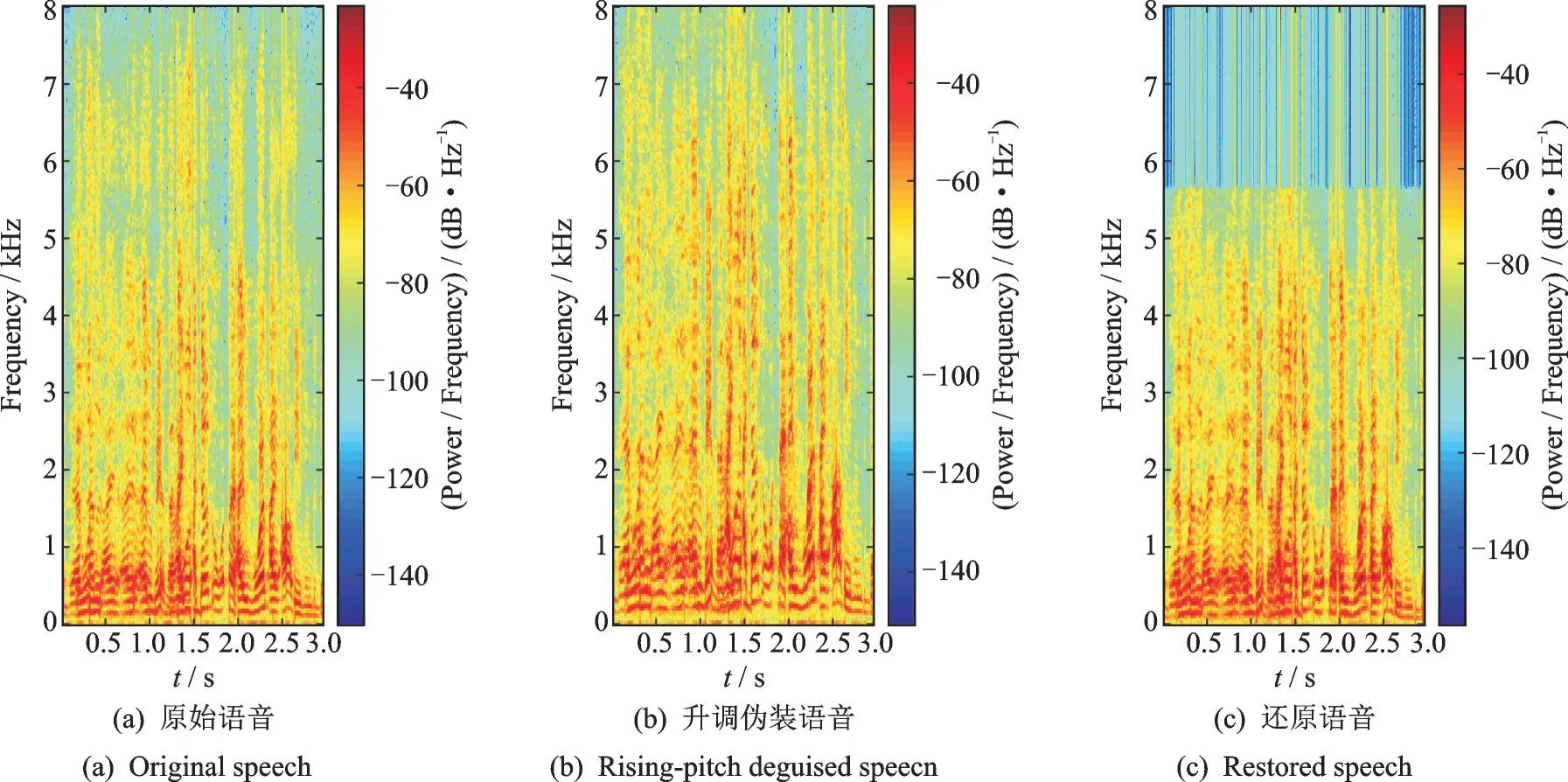
图5 正常语音、伪装语音及还原语音的频谱图Fig.5 Spectrum of normal speech, disguised speech and restored speech
4.2.3 利用对称变换改进说话人确认估计伪装因子的实验结果
本文利用VoxCeleb1 伪装数据集对经过对称变换改进后的基于说话人确认的伪装因子估计方法进行了测试,实验结果在表4 和表5 中给出。可以看出,与3.1 节中的伪装因子估计方法相比,改进后的方法对升调伪装语音的伪装因子估计的错误率仅为6%,最大方差为0.74,准确率明显提高。同时也可以发现,改进模型对降调伪装语音的伪装因子识别率较4.2.2 节中的结果有所下降,除伪装因子-11 外,识别准确率仍明显优于基线系统。经计算,利用改进模型估计的伪装因子在频域伪装数据集上的平均错误率为4.49%、平均方差为6.19,在时域伪装数据集上的平均错误率为3.17%、平均方差为3.75,均明显优于基线系统。
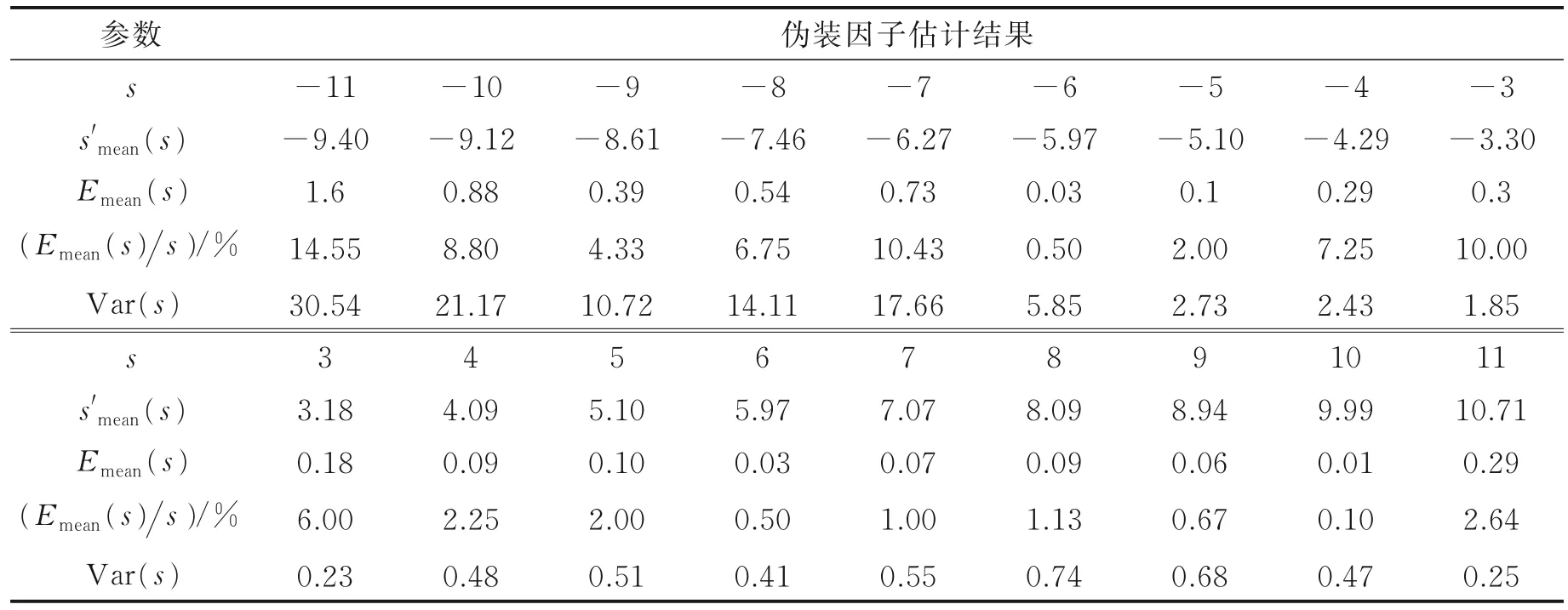
表4 VoxCeleb1 频域伪装数据集上利用对称变换改进伪装因子估计的实验结果Table 4 Performance on estimation of disguising factor using ASV and symmetric transform on VoxCeleb1 with frequency-domain disguise
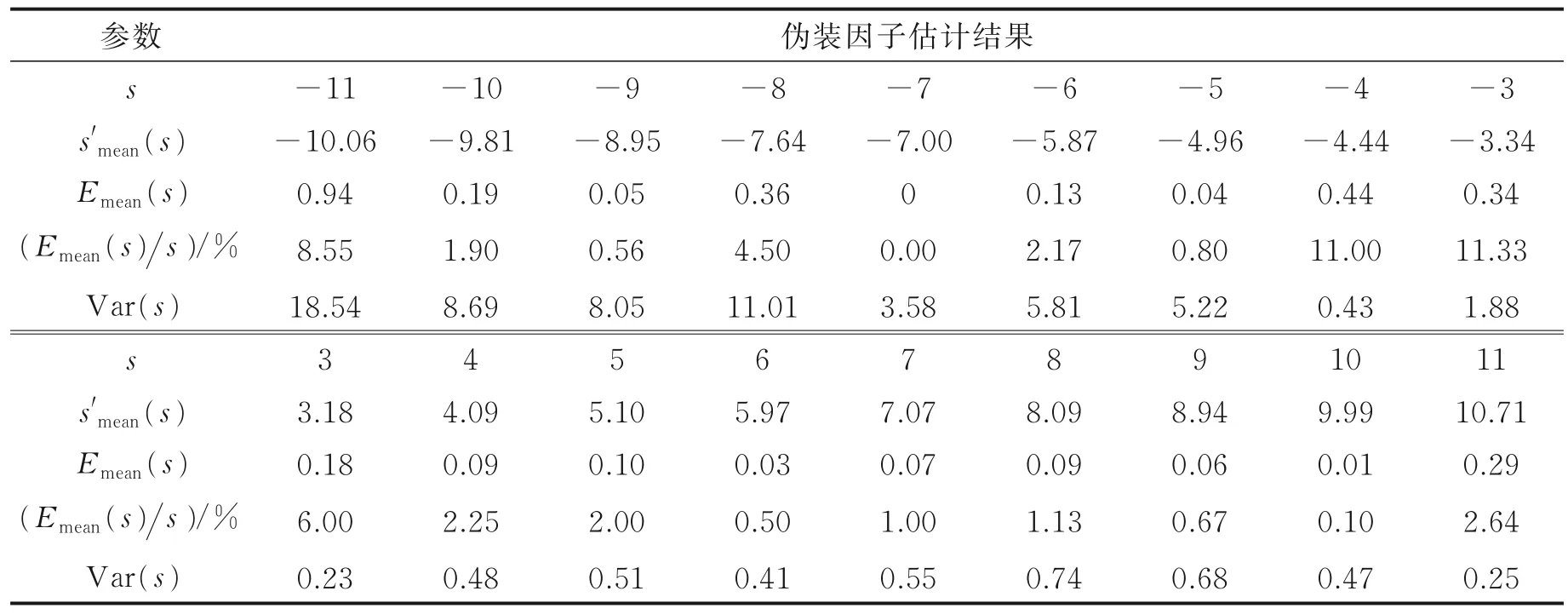
表5 VoxCeleb1 时域伪装数据集上利用对称变换改进伪装因子估计的实验结果Table 5 Performance on estimation of disguising factor using ASV and symmetric transform on VoxCeleb1 with time-domain disguise
对上述3 种伪装因子估计方法的结果进行综合比较,可以看出,本文利用说话人确认估计伪装因子的错误率明显低于基线系统,对于降调电子伪装语音的估计结果与理论值误差很小,但对于升调电子伪装语音效果略差。改进后的基于对称变换的伪装因子估计方法的误差对于升调电子伪装语音保持在较低的水平,对于降调电子伪装语音误差增大,但总体伪装因子估计均值明显优于基线系统,说明本文提出的利用伪装因子对称变换改进的基于说话人确认的伪装因子估计方法是有效的。
此外,本文中的i-vector 自动说话人确认模型是在干净语音库TIMIT 上训练的,而测试集是含噪语音库Voxceleb1。在训练集和测试集噪声条件不匹配的情况下,基于说话人确认的伪装因子估计方法的实验效果仍明显优于基线系统。因此,本文改进的电子伪装语音还原方法不仅具有噪声鲁棒性,还具有较好的泛化性能。
4.3 说话人确认性能
伪装因子的估计过程本质上就是电子伪装语音的还原过程,得到了伪装因子,就能相应地得到还原语音。利用基频比方法估计得到伪装因子后,对电子伪装语音的基频进行逆变换,就可以对应得到基于基频比方法的还原语音;利用本文提出的基于说话人确认的伪装因子估计方法得到伪装因子后,相应地也可以从N 句预还原语音中找出正确的还原语音。基于不同的伪装因子估计方法,可以将电子伪装语音还原方法分为以下几种:基于基频比的基线还原方法、基于说话人确认的还原方法以及利用对称变换改进的基于说话人确认的还原方法。
为了进一步评测语音还原的效果,引入了说话人确认中的EER 作为另一种客观指标。不同的电子伪装语音还原方法的说话人确认系统性能如表6,7 所示。从表中可以看出,电子伪装语音对说话人确认系统影响很大,不采取任何还原措施的电子伪装语音说话人确认系统EER 高达40% 以上。基于基频比的还原方法得到的还原语音说话人确认性能得到一定的改善,但EER 仍高于24%。基于说话人确认的还原方法和利用对称变换改进的基于说话人确认的还原方法得到的还原语音说话人确认性能得到明显改善,EER 低于20%。

表6 频域伪装数据集上不同还原方法得到的还原语音说话人确认性能对比Table 6 Comparison of recognition performance of restored speech speakers using different methods on frequency-domain disguise
利用对称变换改进的基于说话人确认的还原方法对于升调伪装与降调伪装的伪装因子估计准确率类似,但对于升调伪装的EER 尚存在差距,值得进一步探索其原因。
5 结束语
语音技术的发展给人们带来了极大的便利,然而电子伪装语音技术的出现给说话人识别带来了极大挑战,电子伪装语音的身份识别成为目前语音处理和信息安全领域非常有实用意义的研究问题。本文针对当前伪装程度估计方法在真实含噪数据集上不理想的问题,提出了一种基于对称变换和ASV 的电子伪装语音还原方法,能够有效估计含噪电子伪装语音的伪装因子,错误率仅为4.49%,明显低于利用基频比确定伪装因子的方法,为深入开展电子伪装语音的说话人身份识别任务奠定了基础。
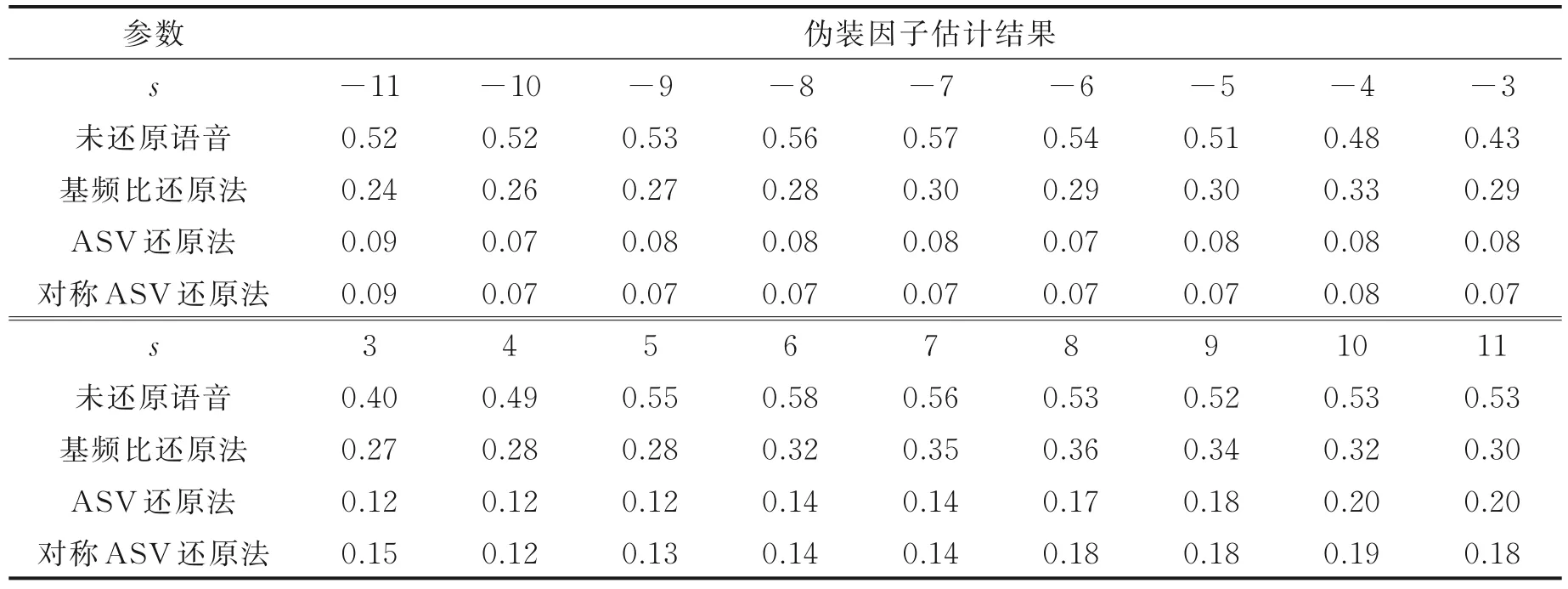
表7 时域伪装数据集上不同还原方法得到的还原语音说话人确认性能对比Table 7 Comparison of recognition performance of restored speech speakers using different methods on timedomain disguise
