基于集成一致性的多源跨领域情感分类模型
2020-10-23梁俊葛线岩团王红斌
梁俊葛,线岩团,2,相 艳,2,王红斌,2,陆 婷,许 莹
(1.昆明理工大学信息工程与自动化学院,昆明,650500;2.昆明理工大学云南省人工智能重点实验室,昆明,650500)
引 言
传统的跨领域情感分类是将在源域学习到的特征表示迁移到目标域中[1-3]。由于不同的源域与目标域之间的特征分布的不同,单源域迁移的分类器仅仅利用了单源域迁移至目标域的特征,对多源域的迁移特征并没有充分利用。在实际应用中,跨领域迁移可以利用多个源域的情感标签数据,从多个领域进行情感迁移,而不是仅仅只利用单一的领域。例如,Kitchen 产品领域可能包括对烹饪书或电子设备的评论,这些评论不能完美的与单个领域(如书籍或电子产品)的特征对齐,通过集成来自多个领域的不同信息,可以更好地适应目标域的特征分布,得到更好的情感分类结果。
利用多个源域数据的直接方法是将它们的数据组合成单个领域。然而,这种策略没有考虑到不同源域和目标域实例之间的关系,将不同领域的特征构建到共同的特征空间中可能会清除部分领域的特征,并导致负面转移,影响情感分类器在目标域的性能[4-5]。对此,本文提出一种无监督的多源跨领域情感分类模型。使不同的源域与目标域在特征空间对齐,得到不同的基分类器。对于每个目标域实例,其预测结果为各个基分类器预测结果的加权组合,分类器权重反映了目标域实例与源域的相关程度。引入集成一致性度量函数,分类器权重是该度量函数的主要参数。当不同基分类器对目标域实例预测结果高度一致时,该度量函数达到最大值,此时的分类器权重最优。与传统方法相比,本文提出的基于集成一致性的多源跨领域情感分类模型,不需要任何的目标域情感标签,摆脱了目标域实例预测时对情感标签的依赖。本文采用亚马逊公开数据集和Skytrax 数据集作为模型的评测数据集,并与6 种跨领域情感分类模型进行了比较。实验结果表明,本文方法与传统的单源模型和多源模型相比,具有更高的跨领域情感分类准确率。
1 跨领域情感分类方法
1.1 单源跨领域情感分类方法
多源跨领域情感分类方法以单源跨领域情感分类为基础。现有的单源跨领域情感分类方法大多是通过对齐源域特征和目标域特征,来减少不同领域间的域间差。Yu 等[6]用2 个神经网络来学习在跨域任务中有用的句子嵌入,通过共同训练卷积递归神经网络模型,预测源域句子的情感标签,并同时预测枢轴的存在。Bollegala 等[7]提出了跨领域词嵌入表示模型,通过约束枢轴特征在不同领域之间有着相似的词嵌入表示,来解决跨领域任务中枢轴特征的词嵌入分布问题。Ganin 等[8]提出DANN 模型,利用领域对抗训练方法来使神经网络产生混淆领域分类器的表示。为了提高深度模型的可解释性,Li等[9]将内存网络合并到了DANN 模型中以自动识别枢轴特征。Ziser 等[10]提出了神经结构对应模型,通过结合结构对应学习和自编码器模型,提出了AE-SCL 模型和AE-SCL-SR 模型。利用神经网络结构的优势,在非枢轴特征和枢轴特征之间建立起映射关系。通过自编码器将不同领域的特征迁移到低维度的特征空间中去,得到跨领域任务的迁移特征;基于迁移特征来减少源域和目标域之间的域间差。
1.2 多源跨领域情感分类方法
多源跨领域情感分类任务需考虑的主要问题是不同领域间的联系。Yasuhisa 等[11]提出了多源域到目标域的跨领域情感分类的概率生成模型。在该方法中,每个特征都分配了领域标签、领域独立性标签以及情感极性3 个属性。然而,该方法并没有考虑源域和目标域之间的相似性,此外,尽管方法中使用了未标记的数据,但未利用未标记目标域中有用的情感知识。Duan 等[12]提出一种基于域适应机制的方法,通过利用在多个源域中独立训练的分类器,学习目标域中的最小二乘SVM 分类器,以监督的方式使用标记数据来学习全局域相似性度量。Yu 等[13]使用标签数据以监督方式学习全局域相似度。Bhatt 等[14]利用目标域的未标记数据,来构建与目标域实例相似的源域实例的辅助训练集。Chen 等[15]将源域特征与全局的目标域特征对齐,而不考虑每个源域对于目标域实例的重要性。 与以上方法不同的是,本文将集成一致性度量函数作为集成分类器的目标函数,当不同的基分类器对目标域实例的类别预测达到高度一致时,表明分类器达到集成一致性,此时分类器的权重最优。基于此权重集成基分类器,可以达到更好的跨领域情感分类效果。
2 本文方法
问题描述:本文遵循多源跨领域情感分类设置,设定源域标签数据来源于m个源域:Si=表示第i个源域中第t个实例及其对应的情感标签。目标域数据定义为:T=表示目标域中第t个实例。多源跨领域情感分类任务的目标是集成多源域数据,并在目标域中取得较好的分类效果。
2.1 算法流程
基于集成一致性的多源跨领域情感分类模型流程如图1 所示。选定基分类器,通过源域至目标域的迁移特征,训练得到不同源域到目标域的基分类器;由此得到目标域实例在不同源域中的分类概率。此时引入集成一致性作为集成分类器的目标函数,并优化不同源域到目标域的分类器的权重,当各个基分类器对目标域实例的预测达到集成一致性最大时,表明集成分类器的性能最优。目标域实例的预测结果由最优权重下的各分类器加权集成得到。
2.2 集成一致性
基于信息熵的集成一致性原则描述如下:利用不同源域到目标域的迁移特征训练得到不同的分类器,并预测目标域实例的情感极性;当各分类器对目标域实例预测高度一致时,信息熵达到最小,模型达到集成一致性。
本文使用Logistics 分类器为基分类器。定义集成分类器,第hi个Logistics 分 类 器 对 输 入实例的极性预测概率为pi,那么m个分类器的平均概率分布为

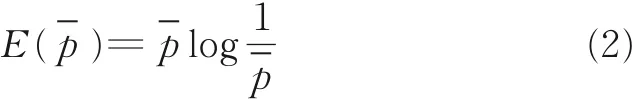
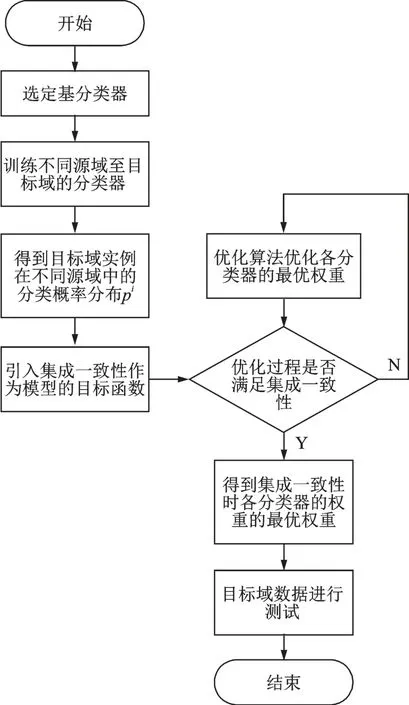
图1 基于集成一致性的多源域跨领域情感分类流程图Fig.1 Flow chart of multiple source domain cross-domain emotion classification based on ensemble consistency
本文以情感二分类问题为例来说明一致性度量的作用,如表1 所示。

表1 概率分布与一致性度量Table 1 Probability distributions and consistency measures
表1 中 ,xT1,xT2为 目 标 域 的 实 例 ,p1,p2,p3分 别 为 各 源 域 至 目 标 域 的Logistics 基 分 类 器h1,h2和h3对目标域实例的预测结果,-p 为平均概率。 对实例的预测结果的维度为2 维,分别表示实例属于类别1 和类别2 的概率。 对于实例xT1,所有分类器预测达到完全一致,以100% 的概率属于类别2。 3 个分类器对实例预测结果的共识程度达到最大值,因此可以判断出实例xT1属于第2 个类别,此时平均概率-p 的信息熵E ( 0,1 ) 达到了最小值0。 对于实例xT2,前2 个分类器分别预测它属于类别1 和类别2,而第3 个分类器预测它分别属于类别1、2 的概率各占50%。 3 个分类器对实例的预测结果完全不一致,几乎不能判别实例所属的类别,共识程度为最小,此时平均概率-p 的信息熵E ( 0.5,0.5 ) 达到其最大值log2。 因此,信息熵的负数可作为不同预测结果的一致度量。 基于熵的一致性度量为

式中,C 为一致性度量值,p1,…,pm为m 个分类器对实例预测的概率,E 为式(2)所示的信息熵,-p 为由式(1)得到的平均概率。信息熵的和取相反数即一致性度量值C。
2.3 权重优化
基于加权集成分类器模型的一致性度量函数为
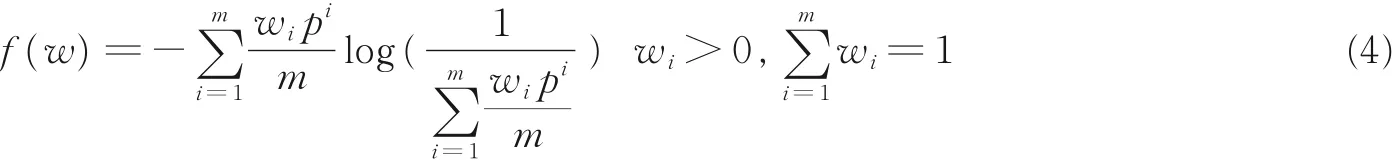
式中,w 为集成分类器的权重集合,wi为第hi个分类器对应的权重,m 为基分类器的数目,f ( w )为集成分类器的一致性度量值,当不同分类器加权后计算得到的f ( w )值达到最大时,分类器对目标域实例预测结果的共识程度达到最大。
本文使用模拟退火(Simulated annealing, SA)算法寻找最优参数wi使f ( w ) 的值达到最大。模拟退火算法以一定的概率接受比当前解效果差的解,更有利于跳出局部优化达到全局优化,得到集成一致性的全局最大值,算法描述如下:
(1) 给定初始值t0,终止值t1,T = t0,给定初始可行解wi,i = 1,2,…,m,目标函数f ( w ),设定每一个T 值下的迭代次数L;
(2) 迭代次数计数器l = 1,2,…,L,重复步骤(3)至步骤(6);
(3) 产生新解wi_new,不断更改自变量的值wi_new= wi+ Δw,Δw 为[ 0,1 ]之间产生的随机变量;
(4) 计算 Δf = f ( wi_new)- f ( wi),优化目标f ( w );
(5) 如果Δf ≥0,接受wi_new为当前解,否则以一定的概率接受新解为当前解;
(6) 判断每个T 值下的是否达到迭代次数L,达到终止条件,则退出;
(7) 判断T值是否达到终止条件,设T的下降幅度为α,T=α∗T,逐渐下降,T>t0,转步骤(2)。否则,获得当前最优解f(w)。
基于集成一致性的多源跨领域分类模型的时间复杂度主要为其寻优算法的时间复杂度,即模拟退火算法的时间复杂度O(n)。
3 实验与分析
3.1 实验数据
本文方法在亚马逊产品评论数据集[16]上进行了实验。该数据集为跨领域情感分类任务中的标准数据集,一共包括4 个领域,即电子产品(Electronics)、书本(Book)、厨具(Kitchen)和DVD,如表2 所示。每个领域中提供了2 000 条已标记数据,其中1 000 条数据为正向数据,1 000 条数据为负向数据。另外,每个领域还包括大量的无标签数据,用于辅助训练非枢轴特征和枢轴特征的映射。
本文方法还在Skytrax 评论数据集[17]上进行了实验,该数据集由航空公司(Airline),机场(Airport),休息室(Lounge)和座位(Seat)4 个领域组成,Skytrax 数据如表3 所示。
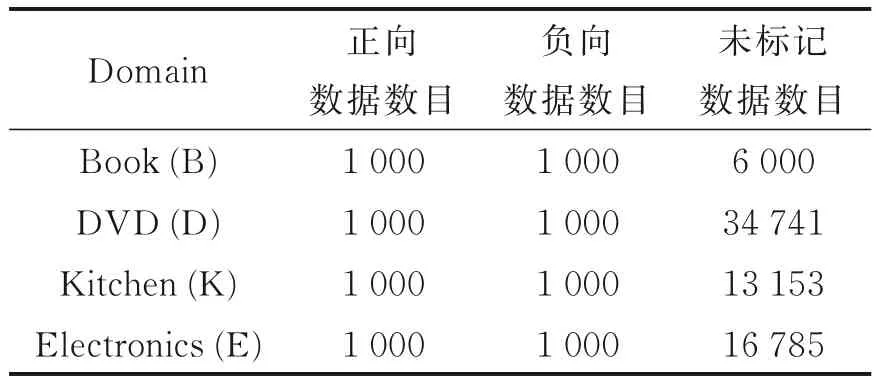
表2 亚马逊产品数据Table 2 Datasets of Amazon Product
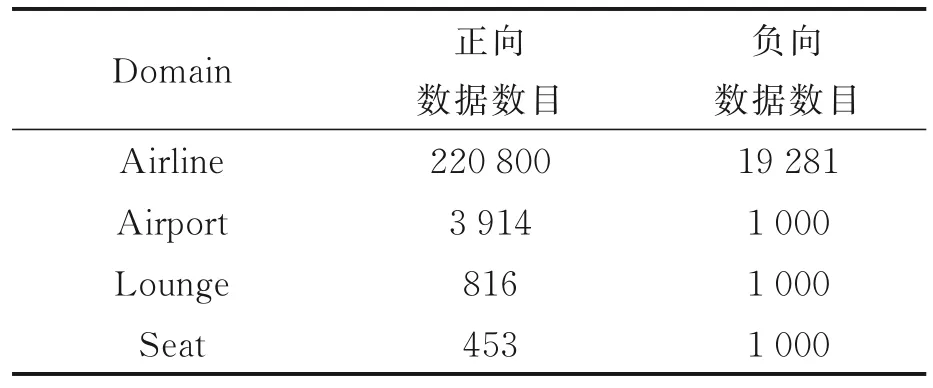
表3 Skytrax 数据Table 3 Datasets of Skytrax
3.2 基线模型
(1)AE-SCL 模型
该模型为文献[10]所提出的模型,枢轴特征在源域和目标域数据中出现词频均超过20,枢轴特征的数目设为100,隐层特征空间维度为500 维。
(2)AE-SCL-SR
该模型为文献[10]所提出的模型,模型参数与AE-SCL 模型一致,其中隐层到输出层的权重矩阵固定不变,以得到更好的迁移特征。
(3)IDDIWP
该模型为文献[11]所提出的模型,通过识别依赖和不依赖域的独立词极性,来进行多域情感分析。Gibbs 采样的迭代次数为300,然后根据最近的50 次的迭代结果来确定文档的极性。
(4)DWHC
该模型为文献[18] 所提出的模型,通过加权不同源域来得到目标域分布表示,加权参数α∈{ 0.1,0.2,…,1.0 }。
(5)CP-MDA
该模型为文献[19]所提出的模型,该模型通过使用伪标签来训练目标域的分类器。将用于计算权重的拉普拉斯图矩阵设置为二进制类型,N近邻中的N值为10,使用五折交叉验证,惩罚因子γA设置为0.014。
(6)DAN
该模型为文献[8]所提出的模型,利用领域对抗神经网络,来完成多域情感分类。使用5 折交叉验证法,学习率设置为0.000 1,丢失率设置为0.4,隐层特征空间维度分别为1 000 和500 两层。
(7)MAN
该模型为文献[15]所提出的模型,通过对抗训练模型,可以学习跨多个领域的常规和领域特定特征。使用5 折交叉验证法,训练、验证以及测试数据比例为3∶1∶1。(8) PBLM-LSTM
该模型为文献[20]所提出的模型。通过自动构建情感字典并使用它来学习基于枢轴特征的语言模型,然后将语言模型学习到的嵌入特征送入到LSTM 层中进行情感分类。枢轴特征在源域和目标域数据中出现词频均超过20,枢轴特征的数目为500,隐层维度空间为256 维度。
3.3 实验设置
本文实验分2 部分,第1 部分为本文集成方法与单源域迁移的实验结果对比。本文分别选用AESCL 和AE-SCL-SR 模型来提取单源域迁移特征,AE-SCL 和AE-SCL-SR 模型将非枢轴特征向量矩阵作为神经网络的输入,将枢轴特征向量作为神经网络的输出,通过在非枢轴特征和枢轴特征之间建立起连接,得到隐层的迁移特征。在得到迁移特征后,训练Logistics 分类器预测情感极性。第2 部分为本文模型与基线模型的实验结果对比。本文从数据集中选取1 个领域为目标域,剩下3 个领域为源域。选用Logistics 作为基分类器,训练得到3 个源域到目标域的分类器h1,h2,h3。模拟退火优化算法中,初始值t0= 10 000,终止值t1= 0.1,迭代次数L = 1 000。设置Logistics 分类器h1和h2的初始权重w1,w2为[0.1,0.5]区间的随机值,分类器h3的权重w3= 1- w1- w2,T 值不断下降,下降幅度 α = 0.95。
3.4 实验结果与分析
3.4.1 实验评估指标
本文采用准确率来评估情感分类的效果,定义为

式中,T 为预测正确样本数,N 为样本的总数。准确率度量的是所有样本中预测正确样本的百分比。
3.4.2 集成方法与单源跨领域模型的实验结果对比
本文分别用AE-SCL 和AE-SCL-SR 作为提取单源域迁移特征的模型,在得到单源域迁移特征后,使用本文方法训练并集成Logistics 分类器,得到多源跨领域情感分类的结果。实验结果对比如表4所示。
从表4 的结果可以看出,以AE-SCL 为特征迁移模型时,本文方法明显优于AE-SCL 单源域的准确率。其中以B 为目标域时,本文方法比E→B 单源域情感分类准确率提高了5.9%;以E 为目标域时,本文方法比B→E的单源域情感分类准确率提高了7.35%。

表4 集成方法与单源跨领域模型的实验结果Table 4 Experimental results of ensemble method and single source cross-domain model
以AE-SCL-SR 为特征迁移模型时,本文方法明显优于AE-SCL-SR 单源域的准确率,其中以B为目标域时,本文方法比E→B单源域情感分类准确率提升了6.1%;以E为目标域时,本文方法比B→E单源域情感分类准确率提升了5.7%。
以上实验结果说明了使用不同的特征迁移基模型时,本文方法均可以取得较好的实验结果。与单源域实验结果对比,基于集成一致性多源域的方法可以更准确地预测目标域实例所属的情感类别,减少了目标域对单源域的依赖,缓解了因源域不同导致分类性能差异较大的缺点。
3.4.3 与基线模型实验结果对比
为了验证本文方法的有效性,本文在亚马逊产品评论数据集以及Skytrax 数据集上进行了实验。亚马逊数据集上的实验结果如表5 所示,Skytrax 数据集上的实验结果如表6 所示。
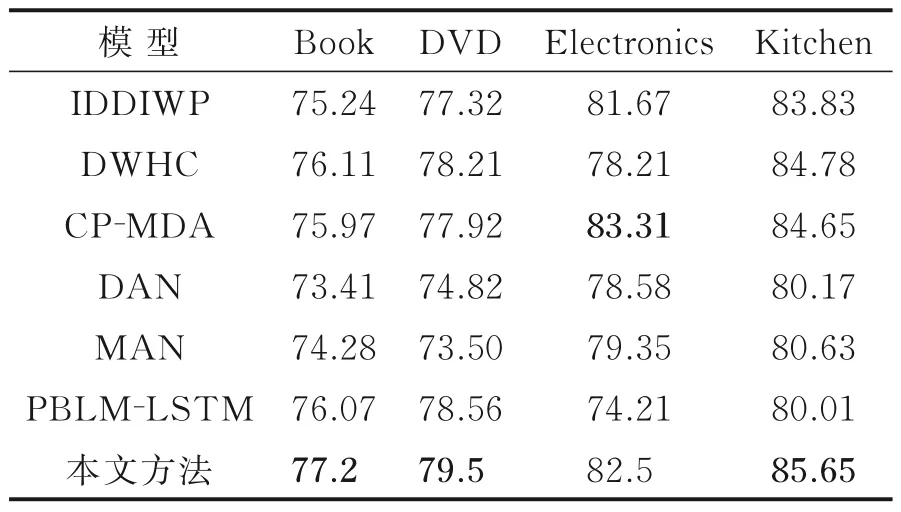
表5 亚马逊数据集的实验结果Table 5 Experimental results of the Amazon datasets
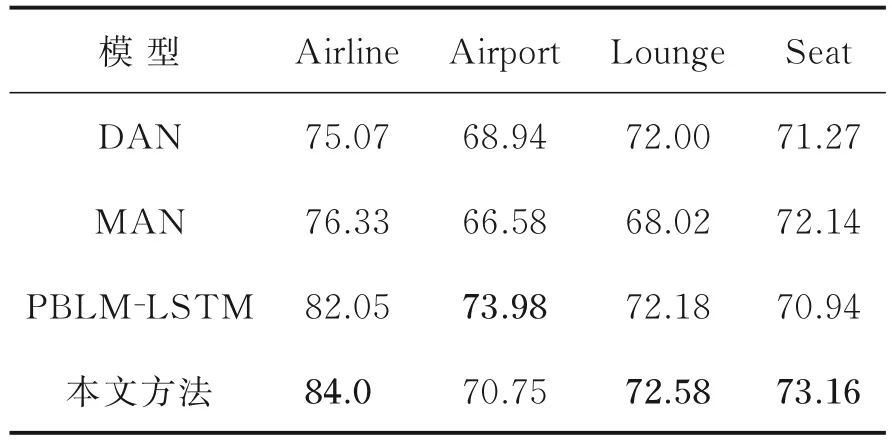
表6 Skytrax 数据集的实验结果Table 6 Experimental results of the Skytrax datasets
从表5 可以看出,对于多源跨领域情感分类任务,本文方法在4 组实验中有3 组实验结果取得所有模型中最高的准确率。与IDDIWP 模型相比,本文方法在以DVD 为目标域的分类实验中准确率提升了2.12%,在4 组实验中平均提升了1.7%。与DWHC 模型相比,本文方法在以Electronics 为目标域的实验中准确率提升了5.10%,在4 组实验中平均提升了1.89%。与CP-MDA 模型相比,本文方法在以DVD 为目标域的实验中分类准确率提升了1.58%,在4 组实验中平均提升了0.75%。与DAN、MAN、PBLM-LSTM 模型相比,本文方法在4 组实验中均取得了最好的分类效果。可以看出,将集成一致性作为目标函数,通过优化不同分类器间的权重,可以得到对目标域实例的最佳预测。
从表6 可以看出,在Skytrax 数据集上的实验,本文方法取得了较好的分类结果。与DAN、MAN 模型相比,本文在4 组目标域的实验中,分类准确率均优于DAN 模型和MAN 模型,其中以Airline 为目标域的实验中,本文方法优于DAN 模型8.93%,优于MAN 模型7.67%,验证了在跨领域情感分类任务中,集成多源域可以达到更好的分类效果。与PBLM-LSTM 模型相比,本文有3 组实验结果优于该模型,其中以Seat 为目标域的实验中,本文方法优于该模型2.22%。充分验证了本文方法引入集成一致性的有效性。
与基线模型的实验对比验证了本文方法的有效性,说明基于集成一致性的多源域跨领域情感分类模型,可以很好地集成目标域实例在不同源域的表征,更准确地预测目标域实例的情感极性。并且,基于一致性的集成多源域情感分类结果比较稳定,不再局限于单域的影响,摆脱了当源域不同、域间差异不同时,分类性能差异明显的缺点。本文模型训练以及预测过程中,并没有用到目标域的标签,相对于弱监督、半监督任务需要部分目标域标签来辅助训练,本文模型摆脱了对目标域标签的依赖。
4 结束语
针对跨领域情感分类任务,本文提出了基于多源域集成的跨领域情感分类模型。充分利用不同源域分类器对目标域实例的预测概率,引入集成一致性,最大化不同源域分类器对同一目标实例的预测共识。通过优化算法得到分类器权重,达到多源域集成模型的一致性。本文方法集成了多源域的优势,得到了稳定的情感分类结果。实验结果表明,本文方法相比基线模型能够更好地解决跨领域情感分类任务。本文的多源域集成方法性能受限于单源域迁移特征,在今后的工作中可以考虑使用其他单源域特征迁移方法,以进一步提高分类质量。
