最强基站MAC 地址匹配的RSSI 加权室内定位方法
2020-10-22孙玉曦李晨辉
孙玉曦,甄 杰,郭 英,李晨辉,3
(1. 中国测绘科学研究院,北京 100036;2. 山东科技大学 测绘科学与工程学院,山东 青岛 266590; 3. 辽宁工程技术大学 测绘与地理科学学院,辽宁 阜新 123000)
0 引言
随着社会的发展,室内场所的面积越来越大,出现了许多大型的商场、办公场所、娱乐场所等,而且人们大部分的活动时间都在室内,对室内位置服务(indoor location based service, ILBS)的需求日益强烈[1]。当前,依赖可移动智能设备(智能手表、智能手机、平板电脑等)的室内移动位置服务,在人们生活中扮演着不可或缺的角色,具有巨大的市场潜在价值。
目前可用于室内定位的技术有很多,如芬兰Quuppa 公司[2]推出的蓝牙天线阵列系统,苹果公司推出的基于低功耗蓝牙的iBeacon 系统[3],谷歌公司则把视觉定位技术(visual positioning service, VPS)[4]列为其核心技术,还有较为常见的射频识别(radio frequency identification, RFID)[5]、无线局域网(wireless local area networks, WLAN)[6]、蓝牙[7]、超宽带(ultra-wide band, UWB)[8]、地磁[9]等,许多研究机构与学者利用这些技术开发了不同的室内定位系统,满足了不同用户的室内定位精度需求。
由于蓝牙、WLAN 等价格低廉、易于布设等优点,使其在室内定位领域应用十分广泛。其主要采用测距交会和指纹匹配2 种方法[4]:测距交会法[10]对室内难以精确定义的信号传播模型的依赖性,使其精度受到限制;指纹匹配法[11]依靠的是识别表征目标位置的信号特征,利用各点信号的差异性实现定位,不受信号传播多路径、反射的影响,且室内复杂的信号传播模型对其定位精度的影响较小。因此在室内环境下,指纹匹配定位方法会有较好的定位效果。
指纹匹配定位方法分为确定性指纹定位算法和概率性指纹定位算法。确定性算法主要有最邻近法(nearest neighbor, NN)、k-邻近法(k-nearest neighbor, KNN)、带有权重的 k-邻近法(k-weight nearest neighbor, KWNN)、神经网络法(artificial neural networks, ANNS)[12];概率性算法主要是贝叶斯算法等[13],定位需要大量的假设统计工作,导致在线定位阶段算法更加复杂。确定性算法中的神经网络法也存在类似的问题,离线阶段需要大量的工作。KNN 算法与这2 种相比,实现更为简单,并且对硬件要求不高,但是该算法在判定近邻点时,会引入距离待定点较远的参考点,从而影响定位精度。利用动态加权最近邻算法[13](enhanced weighted k nearest neighbor, EWKNN)可以设定1 个阈值来动态选择k 值,提高定位精度,但该算法选择的参考点也有出现距离较远的现象。
基于上述问题,本文在离线阶段,通过模糊c均值聚类算法(fuzzy c-means algorithm, FCM)先进行定位区域划分,生成聚类指纹库。在线阶段,首先进行区域定位,然后在动态加权最近邻算法动态选择k 值的基础上,根据待测点和选定区域内,参考点介质访问控制(media access control, MAC)地址序列进行匹配,只信任最强的基站,进一步剔除较为偏远的参考点,从而筛选出k 个中最优的参考点。最后,计算最优参考点对应坐标的加权平均值作为待测点的最终估计位置。
1 基于RSSI 的位置指纹定位算法
基于接收信号强度指示(received signal strength indicator, RSSI)的位置指纹定位算法,分为离线勘测和在线定位2 个阶段。离线勘测阶段主要是信息采集和样本训练,利用参考点的已知位置数据和接收到接入点的RSSI 信号特征值,包括RSSI、MAC 地址、均值、方差等,建立位置-指纹数据库,从而建立空间位置与RSSI 序列准确的映射关系;在线定位阶段,利用接收到的待定点的RSSI 序列与建立的位置指纹数据库进行匹配,然后运用某一定位匹配算法,解算出待定点的位置信息[14]。所采用的匹配算法会直接关系到定位结果的准确性。
2 在线匹配算法
2.1 动态加权最近邻算法原理
1)将待定点采集的RSSI 信息与指纹库中的指纹信息进行相似度匹配,获取近邻点,其相似匹配依据是信号的欧氏距离,其计算公式为
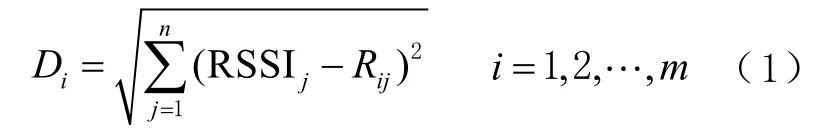
式中:RSSIj为第j 个基站的信号强度RSSI 值;Rij为位置指纹库中第i 个参考点接收到的第j 个基站的信号强度RSSI 值;m 为位置指纹库中参考点的个数;n 为待测点接收到的基站的个数。每个参考点的坐标 Pi( xi,yi)和对应的RSSI 序列 Rij构成了定位区域的位置指纹库位置指纹库(point RSSI, PR)。
2)通过设定1 个阈值 R0,保留式(1) Di中不大于 R0对应的 Di,并将其记为 Si(i =1, 2,…, L)将剩下的 Si按从小到大的顺序排列,并计算其平均值E ( S )为
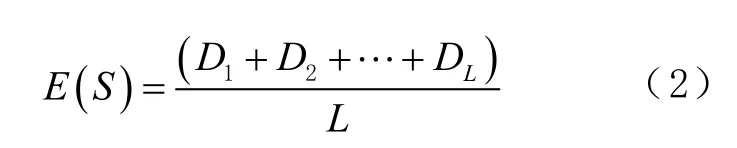
3)将 Di和 E ( S )进行比较,保留那些距离差 Di不大于平均值 E ( S )的参考点,这些参考点的数目就是动态变化的k 值,这样就可以避免由于固定k值把距离偏远的参考点选入而影响定位精度的问题。最后,将保留下来的k 个值对应的坐标( xk,yk)加权平均,得到该待定点的估计位置( x, y )为
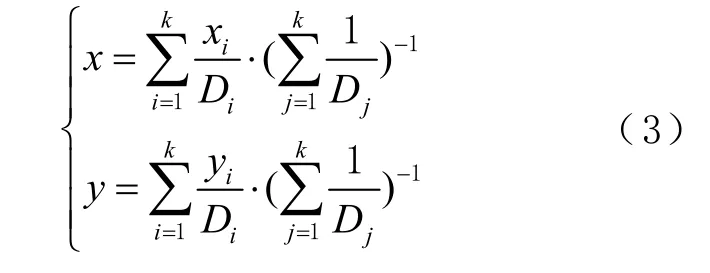
2.2 改进算法
在大型场所定位时,遍历所有参考点的计算量较大,并且会大大降低系统的实时性。为了减少待匹配参考点的个数,本文首先用模糊c 均值聚类算法,将定位场所划分成若干个区域,在线定位阶段,首先进行区域定位,然后再用改进的MAC 地址匹配算法在该区域内进行位置估计,既可减少指纹匹配时间,提高定位的实时性,也能提升定位精度。
2.2.1 模糊c 均值聚类算法划分定位区域
模糊c 均值聚类算法是1 种以隶属度来确定每个数据点属于某个聚类程度的软聚类算法[15]。其目标函数为
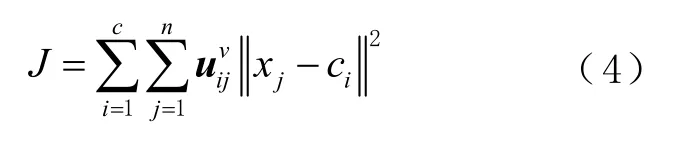
其约束条件为
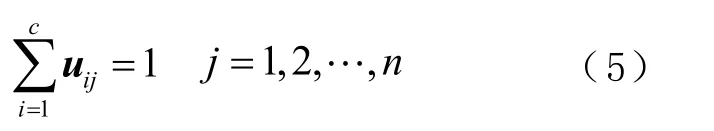
式中:n 为聚类样本数;c 为聚类数目;X= { x1, x2,… , xn}为 样本集合;C = {c1, c2,… , cn}为 聚类中心;v 为1 个加权系数; uij为样本集χj归属于所有类别的隶属度矩阵。
由拉格朗日乘数法求解,目标函数式(4)取极小值满足的条件为[15]:
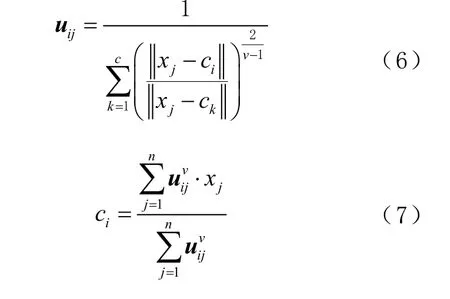
采用迭代的方法求解式(6)和式(7),直至满足收敛条件,得到最优解。
FCM 算法对于满足正态分布的数据聚类效果会很好,因此本文用该算法对离线位置指纹库PR进行聚类分析,划分定位区域。采用FCM 算法对离线指纹库进行聚类,每1 个子类包含1 个聚类中心,代表该类的特征,用于在线定位阶段进行区域匹配定位。算法具体步骤为:
第1 步,根据实验训练经验值给定聚类数c 和初始聚类中心 0C ,初始化加权系数 2v= ,设定迭代收敛条件(迭代截止误差ε 、迭代计数l)
第2 步,更新隶属度矩阵,其计算公式为
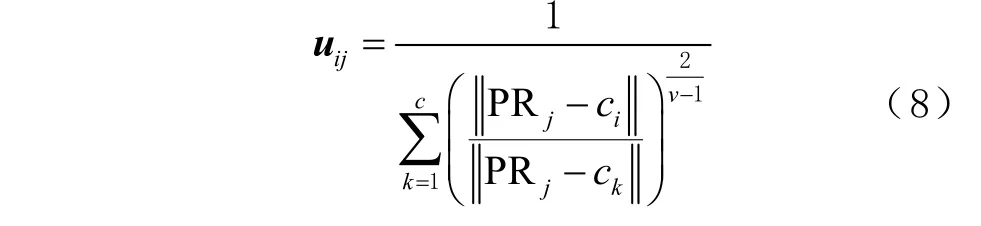
第3 步,更新聚类中心,其计算公式为
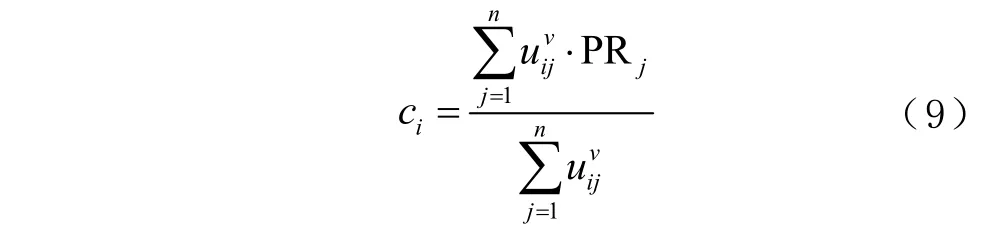
第5 步,计算每个聚类中心C 区域参考点数目,设定阈值,如果小于阈值,迭代停止,划分为c 类区域;否则跳转到第1 步,进行下一层次区域划分。
2.2.2 基于最强基站MAC 地址筛选参考点
研究移动端接收到不同基站的 RSSI 数据时发现,位置接近的待测点与参考点,他们的MAC地址有紧密相关性,尽管其RSSI 强度略有波动,但其MAC 地址序列基本一致[16]。因此本文在动态k 值筛选参考点基础上,引入基站MAC 地址匹配度进一步筛选出最优的参考点,进而提高定位的精度。
1)在线阶段待测点的MAC 地址序列跟离线指纹库中参考点的MAC 地址序列进行匹配,其匹配公式为

式中:iL 为求得的第i 个参考点的匹配度;ijN 为定位阶段与第i 个参考点匹配时,前j 个基站的MAC 地址相同的个数。如果基站的MAC 地址序列完全相同,则iL 取最大值。
2)实验结果表明,即使距离很近的2 个位置, 其基站MAC 序列也不是完全一致的。为了减少信号波动的影响,基于信任最强基站的想法,式(10)取 1j= ,即只选取信号强度最强的基站RSSI 地址进行筛选匹配,从而剔除参考点,提高定位的精度。
2.2.3 不同基站信号强度加权
动态加权最近邻算法在寻找用于定位的参考点过程中,通过求解参考点与待测点之间RSSI 相似度来确定若干个用于定位的参考点,对这几个参考点给予权值区别对待,与定位点接收信号强度相似度高的参考点,在确定定位点坐标时有较大的权值。
然而这一过程并没有对来自于不同基站的信号强度区别对待,在实际情况下,接收到某个基站的信号强度越高,则来自该基站的信号强度对定位的贡献程度应该最大,所以在定位中可以对不同基站加以可信度,给每个基站分配不同的权值进行RSSI 相似度的计算[17]。
在动态加权最近邻算法第1 步,即计算待测点与参考点接收到第j 个基站的信号强度相似度时,对欧氏距离加以权值 Wj,Wj和待测点与参考点之间RSSI 相似度的计算公式分别为:
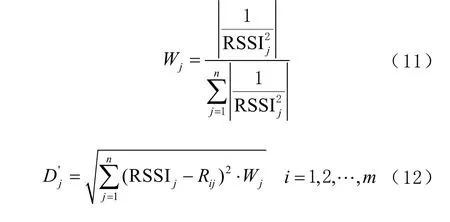
式中:RSSIj为第j 个基站的信号强度RSSI 值;Rij为位置指纹库中第i 个参考点接收到的第j 个基站的信号强度RSSI 值;m 为位置指纹库中参考点的个数;n 为待测点接收到的基站的个数。
2.3 整体改进算法流程
本文在动态加权最近邻算法的基础上做了改进,具体流程为:离线阶段,通过FCM 算法进行定位区域划分,生成聚类指纹库。在线阶段,首先计算待测点与各区域聚类中心的相似度,确定待测点所在的目标区域;然后根据RSSI 强度加权后的待测点与目标区域参考点的指纹信息,设定阈值,动态选择k 值,从而剔除距离偏远的参考点;再次通过RSSI 地址序列匹配的方法,只信任最强的基站,进一步筛选出k 个中最优的参考点;最后计算最优参考点对应坐标的加权平均值,作为待测点的最终估计位置,其流程如图1 所示。
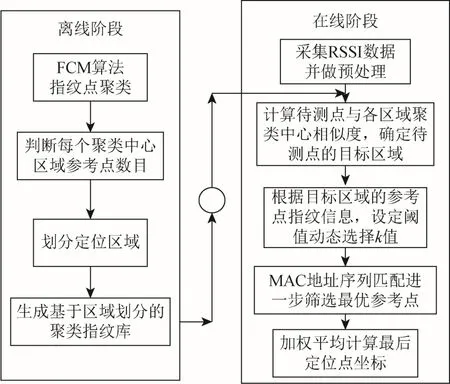
图1 算法流程
3 实验与结果分析
3.1 实验描述
实验场地为某5 层楼的3 层,包含走廊及318 房间。走廊长45、宽3.6 m,每隔5~6 m 布设1 个iBeacon 基站(共有7 个基站);318 房间长11.5、宽5.5 m,布设5 个基站,基站附着在天花板上。将智能手机(小米6)作为采集设备,信号的采样率设为1 Hz。实验者手持采集设备在每个采样点上分别在东、西、南、北4 个方向上采集60 s 的数据,用均值滤波处理RSSI 数据,然后存入后台指纹库 (密度为1 m)。实验场地、指纹参考点以及基站布设情况如图2 所示,实验分为318 房间实验以及走廊部分实验。
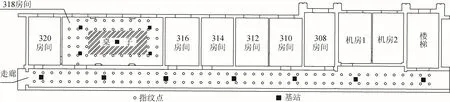
图2 实验环境
3.2 结果分析
3.2.1 FCM 区域划分实验
使用FCM 算法对318 房间及走廊区域进行区域划分,其参考点的分布情况如图3 所示,大部分参考点都可以按照区域进行划分,只有少量参考点未能按区域划分。
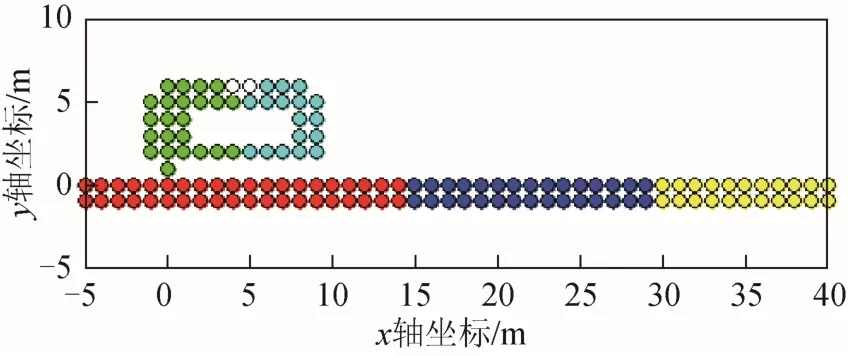
图3 FCM 区域划分
3.2.2 在线定位实验
1)318 房间定位实验。在318 房间4 个已知点上分别采集10 s 的RSSI 数据,运用本文的改进算法和EWKNN 算法进行数据处理,对2 种结果进行比较。
分别计算2 种算法的定位误差(如图4(a)所示)和误差累计概率分布(如图4(b)所示),并将各类数据进行统计(如表1 所示)。本文将最小定位误差、最大定位误差、平均误差和不同定位 精度下的误差累计概率作为衡量定位精度的标准。
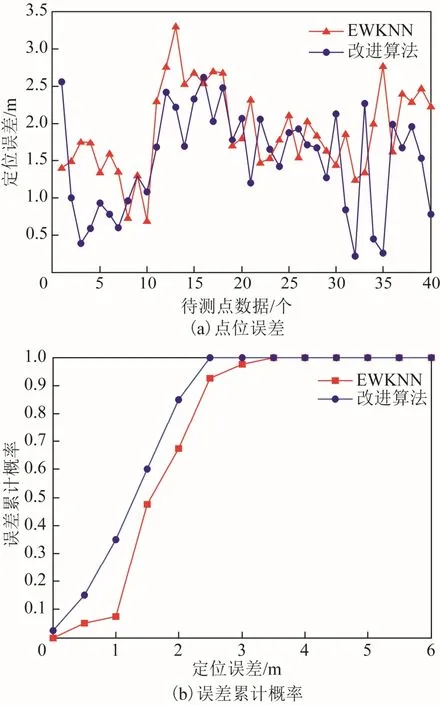
图4 2 种算法定位误差与误差累计概率

表1 2 种算法精度对比
由图4(a)、图4(b)及表1 测试结果可知,改进的算法优于EWKNN 算法:EWKNN 算法的平均定位误差为1.90 m,误差在1 和2 m 以内的可信度分别为7.5%和67.5%;而改进算法的平均定位误差为1.51 m,误差在1 和2 m 以内的可信度分别为35.0%和85.0%;改进算法的最大定位误差为2.60 m,EWKNN 算法的最大定位误差为3.29 m;而且改进算法的定位误差均在3 m 以下,而EWKNN 方法定位误差在3.5 m 以下。
2)走廊区域定位实验。在走廊区域2 个已知点上分别采集10 s 的RSSI 数据,运用本文的改进算法和EWKNN 算法进行数据处理,对2 种结果进行比较。
分别计算2 种算法的定位误差(如图5(a)所示)和误差累计概率分布(如图5(b)所示),并将各类数据进行统计(如表2 所示)。

表2 2 种算法精度对比
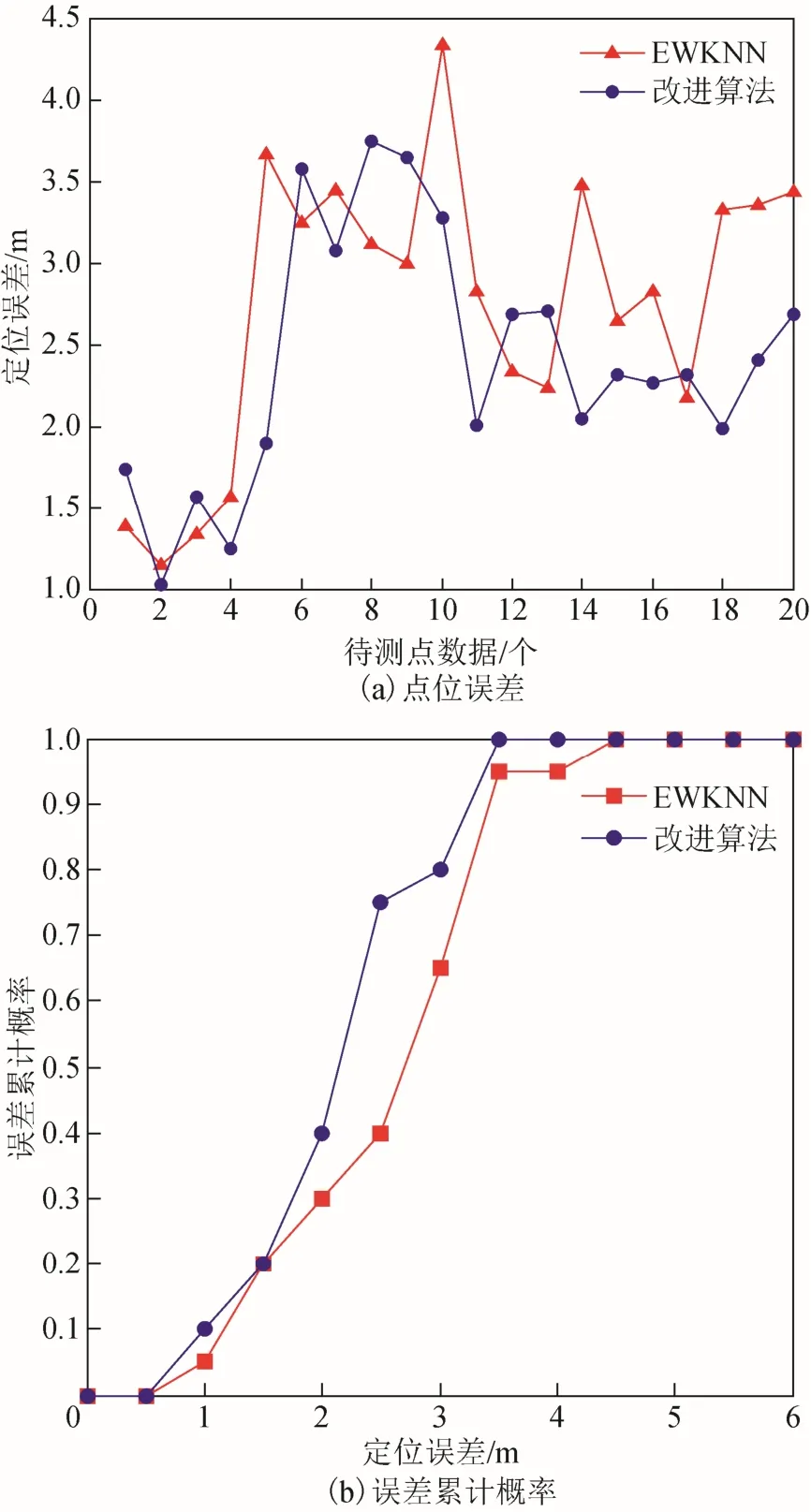
图5 2 种算法定位误差与累计概率
由图5(a)、图5(b)及表2 测试结果可知,改进算法的定位误差在 2.5 m 以下的概率大于EWKNN 算法。EWKNN 算法的平均定位误差为2.74 m,改进算法在此基础上降低了0.33 m,改进算法的定位误差均在4 m 以下,而EWKNN 方法定位误差在4.5 m 以下。
通过以上实验分析可知,本文改进算法在房间以及走廊区域的平均定位误差、最大误差相比EWKNN 算法均有所改善,误差累计概率有较好的提升,这说明该算法通过FCM 区域划分、MAC 地址匹配筛选后,能够有效剔除较为偏远的参考点,提高定位精度。
4 结束语
本文提出的最强基站MAC 地址匹配的RSSI加权的改进室内定位方法,能够在室内复杂环境下有效剔除距离偏远的参考点,削弱信号不稳定对定位结果的影响,提高定位精度,并且降低定位计算的复杂度,对室内定位的研究有一定的参考价值。但随着室内应用场景越来越多、室内面积越来越大,如何做好离线指纹库的快速采集和有效维护是接下来要进一步研究的工作。
