时域模型对视频行人重识别性能影响的研究
2020-10-19林染染黄子源侯建华
项 俊,林染染,黄子源,侯建华
中南民族大学 电子信息工程学院,武汉 430074
1 引言
近年来,随着公共安全需求的不断增长和监控摄像网络的迅速发展,行人重识别(person re-identification,Re-ID)研究受到了广泛的关注。行人重识别的任务是从图像或视频中检索出特定行人,按照输入对象的不同分为基于图像的行人重识别和基于视频的行人重识别。前者主要由特征表达学习和距离度量学习两部分组成,其中鲁棒性的特征提取使得分类器更具辨别性,而度量学习构建特定的度量空间,使得在此空间内相同行人距离接近,不同行人则相互远离。本文主要关注基于视频的行人重识别,即给定一个特定行人的查询视频,在视频库中识别出包含该行人的视频。相比于单帧图像,视频Re-ID所处理的视频序列中含有更丰富的时域信息,因此基于视频的行人重识别算法中不仅包括特征提取、度量学习模块,还需设计时域模型用以挖掘视频序列中行人特有的时域信息。时域模型是基于视频的行人重识别算法中的研究热点,目前常用的时域建模方法包括时域池化模型、时间注意力模型、循环神经网络等。鉴于当前主流的Re-ID 算法普遍采用深度学习技术[1-3],以下简要回顾基于深度神经网络的时域模型在Re-ID 算法中的应用。在视频Re-ID 中,时域建模方法可分为两大类:基于循环神经网络(Recurrent Neural Network,RNN)、基于时间注意力(temporal attention)。
基于循环神经网络:Zhang 等人[4]在Image-to-Video Re-ID 研究中,用卷积神经网络(Convolutional Neural Networks,CNNs)提取查询集中的行人特征;对于库图像中的视频序列,首先使用CNN提取每帧图像特征,再将这些特征经过长短时记忆网络(Long Short Term Memory,LSTM)进行时域建模,得到视频序列的特征表达;最后通过相似性度量,计算查询图片与库图像中视频序列的相似性。为了提取更加有效的特征,Xu等人[5]在获得CNN特征基础上,引入了空间金字塔池化层,再采用RNN 网络提取行人视频序列中的时间信息。McLanghlin 等人[6]利用RNN 建模不同帧之间的时域相关信息,将RNN 细胞输出的平均作为视频序列特征。Yan等人[7]用RNN最终的隐状态作为视频序列的特征编码。Zhang 等人[8]利用CNN 提取不同时间尺度的特征,再通过双向GRU模型获取过去和未来的依赖特征信息。
基于时间注意力:Zheng 等人[9]将重识别问题看作是一个分类问题,利用行人视频序列中的多帧图像,采用交叉熵损失训练CNN 模型,再利用最大池化(Max-Pooling)将多个行人的单帧图像特征融合为一个序列特征。Liu等人[10]提出了一种质量感知网络(Quality Aware Network,QAN),在提取每帧图片特征的同时还预测该图片的质量(即注意力权重),再将各帧特征进行加权平均;该方法对质量好/差的图片赋予大/小的权重,从而改善视频序列特征质量。文献[11]针对视频重识别问题,提出了一种联合时空注意力机制网络;输入为图片的3个RGB 通道和2 个光流通道,用CNN 提取特征后再经过空间金字塔池化层,获得图片层次的特征;再通过RNN 和时间注意力池化层,获得视频序列特征。与文献[11]类似,Zhou等人[12]利用了RNN和时间注意力模型来学习行人视频序列特征,其中RNN 模型提取上下文信息,时间注意力模型用以自动筛选序列中更具代表性的视频帧。Liu等人[13]利用多距离度量框架来自动挖掘训练过程中的困难样本图片,以此来学习一个更具判别力的度量框架。
综上所述,时域模型是设计视频Re-ID算法的关键环节之一,本文研究不同时域模型对视频Re-ID算法的影响。但由于上述算法中采用的图片特征提取方法、训练网络的损失函数各不相同,对于每种时域建模方法难以直接进行对比。例如,文献[6]采用3层卷积神经网络对图像进行编码,文献[10]中则使用VGG模型[14]提取图像特征;不同的特征提取策略和损失函数都将对算法性能产生显著的影响。本文借鉴文献[15]的思路,在固定图片特征提取器和损失函数条件下,研究了三种常用的时域模型结构:时域池化(Temporal Pooling)、时域注意力(Temporal Attention)和循环神经网络,通过在iLIDS-VID[1]和Mars[9]数据集上的实验结果,分析与比较不同时域模型对视频Re-ID算法性能的影响。
2 基于时域建模的视频行人重识别算法
2.1 特征提取
图1 给出了视频行人重识别算法中的视频序列特征生成流程图。给定视频输入序列,经过特征提取器得到各帧的图片级特征(image-level feature)并构成特征序列;再通过时域模型提取视频序列中的时域信息,生成行人最终的特征表达,即视频序列特征。

图1 视频序列特征生成流程图
图片级特征提取一般采用卷积神经网络,从最初的VGGNet[14]、AlexNet[16],到目前的ResNet50[17]、DenseNet[18]等,模型从开始的简单浅层网络变得更深更复杂。本文主要研究时域建模,因此对特征提取模型的选取未做特别要求,综合衡量后选取模型大小适中、同时在ImageNet上分类性能优异的ResNet50[17]网络作为基础网络。ResNet50网络是用于分类任务的,其最后两层是全连接层用以预测类别;而本文采用ResNet50提取行人特征,因此将ResNet50模型中最后两层全连接层被去除后的结果作为图片特征。
2.2 时域模型
设输入视频序列s={x1,x2,…,xL},即某个行人的视频中含有L帧图片。设f(⋅)表示特征提取函数,本文选取ReaNet50 模型,视频序列经过ReaNet50 后得到各帧图片级特征{f(x1),f(x2),…,f(xL)}。时域模型Tem(⋅)提取这些图片级特征中的时域信息,得到视频序列的特征表达F(s)。图2给出了本文研究的三种时域模型,分别为时域池化模型、时域注意力模型、循环神经网络模型。

图2 三种时域模型
时域池化:时域池化选取文献[9]中所用的时域平均池化(average-pooling)模型,即对视频序列中行人每帧图像的特征进行平均加权融合的操作:

理论上时域池化属于均值处理操作,存在的问题是特征融合时无法去掉噪声,只能一定程度上弱化噪声干扰,对有效信息的鉴别能力存在麻木性,但因其不引入模型参数,在实际应用中有很高的便捷性。
时域注意力:时域注意力模型选取文献[10]所提到的QAN 模型。QAN 时域模型依据每帧图像的预测质量赋予不同的权重,用于指导序列特征的融合过程,如遮挡、模糊等图像赋予较低的权重,因此可以有效减小视频序列中噪声的影响。QAN模型最终输出的视频序列为:

注意力机制模型在特征融合过程中能有效鉴别多线索特征的有效性,一定程度上可以起到抑制噪声,突出有用信息的目的,然而高效准确的注意力机制网络模型设计提高了模型复杂度,尤其是行人重识别领域在缺少大样本时序样本集前提下有效性样本的鉴定任务极具挑战。
循环神经网络:本文选取文献[15]中的循环神经网络模型,具体采用LSTM模型。该模型对于输入的L帧行人图片特征,输出o(f(xi)),i∈(1,L),再对循环神经网络的输出进行平均池化,得到行人视频序列的特征表达。

递归神经网络能有效建立时序数据间的相关性,体现在行人重识别中可以理解为行人空域外观动态特性,这种动态特性本身就具备身份验证特性,由于是时域动态特性,理论上能一定程度自适应光照、形变等动态特性,从而提高外观特征的鲁棒性。存在的问题是行人重识别缺少大规模时序行人训练样本集,为避免过拟合,设计模型复杂度不能太高,而递归神经网络模型训练存在梯度消失问题,有效学习周期内模型训练未必能实现有效特征学习。
2.3 损失函数
损失函数是度量训练模型有效性的重要指标,其中交叉熵损失定义为网络预测类别与真实类别的分布偏差,被广泛运用于神经网络模型训练。基于交叉熵损失的行人重识别本质是将重识别问题理解为分类问题,好处是有利于挖掘具有身份鉴别特性的表观特征,且身份作为类别监督信息,有效保证模型训练的收敛性。然而这与行人重识别本质是身份再验证问题相违背。身份再认证问题本质上属于排序问题,也即构建测试图片与比对图片相似性顺序问题。而三元组损失将度量学习引入网络训练,通过三元损失定义,将原始像素域图片变换到编码空间,满足同类样本的编码表观特征距离小,不同类样本的编码特征距离大,因此基于三元损失的外观特征更适用于排序问题。存在的问题是三元损失函数在训练过程中监督信息较弱,训练收敛较慢。为此本文利用三元组损失结合交叉损失训练网络模型。好处是利用交叉熵损失引入丰富的类别监督信息,保留具有身份鉴别特性的同时引入度量学习,使得所提表观特征即具有身份验证信息同时兼顾度量排序的目的,也即拉近同类样本之间的距离,推开不同类样本间的距离,加速了网络的收敛效率,同时在测试集上有了精度提升。
具体来说本文在得到行人视频序列的特征表达F(s)后,分别选取三元组损失和交叉熵损失来训练网络。对于三元组损失,选取三个行人视频序列(sa,sp,sn),并且满足(sa,sp)属于同一类别,(sa,sn)属于不同类别。下式给出了三元组损失的定义:
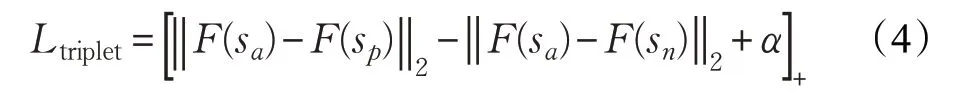
其中α为阈值,用来约束特征空间内不同类别样本之间的距离。
对于交叉熵损失,在得到视频序列s的特征表达F(s)后,把行人重识别当作分类问题,假设分类器预测行人类别为qi,行人真实标签为pi,则交叉熵损失定义如下:

模型的最终损失为三元组损失和交叉熵损失之和:

3 实验
3.1 实验设置
以下介绍实验设置与相关细节,包括数据集、基准算法、评测指标等。
数据集:实验数据集选自iLIDS-VID[1]和MARS[9]数据库。MARS 数据库是目前已公开的最大视频行人重识别数据集,包含1 261个行人,采集于6个不同的摄像头,每个人被2~3 个摄像头捕捉到,每个行人平均含有13.2个视频序列。iLIDS-VID数据库包含从两个无交叠摄像头采集的300 个行人的600 个视频段,每个行人视频段含有23 到192 帧图像不止,平均含有73 帧。在实验中,把两个数据集图像尺寸归一化为224×112。
基准算法(Baseline):为了更好地验证时域模型的有效性,以基于图像的行人重识别算法作为基准算法(Baseline)。该方法以文献[19]为基础,即采用预先在ImageNet数据集上训练好的ResNet50 网络提取行人特征,然后引入交叉熵损失,再和原来文献[19]中的三元组损失一起共同训练神经网络。
在Baseline 的基础上,分别加入时域池化、时域注意力和循环神经网络三种时域模型。在训练阶段,每次送入的训练样本个数(即Batchsize)大小设置为32,即每次送入32个行人视频,采用AdamSGD[20]优化方法;在测试阶段,使用训练好的模型提取行人视频特征,再根据特征之间的相似性距离进行排序。
评测指标:采用行人重识别领域广泛使用的累计匹配特性曲线(Cumulative Matching Characteristic Curve,CMC)CMC@Rank-1,5,10,分别表示在一次查询结果中,排序列表的前1、5、10 个排序样本中含有正确样本的概率;同时还采用检索任务中另一个常用的评测指标mAP(mean Average Precision),表示检索结果的精度平均值。
本文实验在Pytorch 深度学习框架下进行,代码主要参考文献[15](https://github.com/jiyanggao/Video-Person-ReID)。
3.2 实验结果与分析
在Baseline 的基础上,分别加入时域池化、时域注意力和循环神经网络三种时域模型,本节给出了不同的时态建模方法在Mars 和iLIDS-VID 数据集上的实验结果。基准Baseline算法提取行人视频序列图像级特征,三种时域模型根据图像特征生成最终的视频序列特征表达。
(1)时域池化模型。首先考察在输入不同视频序列长度(即所包含的图片帧数)条件下的时域池化模型的效果,时域池化模型采用简单的平均方式,即在Baseline提取的图像级行人特征基础上,对每帧图像特征进行平均融合。实验结果如表1 所示,实验中,每段视频送入的帧数T分别为1、2、4、8,采用AdamSGD优化方法,学习率设置为0.000 3,T=1 对应的是基于图像的基准算法。从表1可以看出,与基于图像的基准算法(T=1)相比,加入时域池化模型后(即T≥2),基于视频的Re-ID方法在Rank-1、Rank-15、Rank-10、mAP 指标上均有改善,例如T=4 时在Mars数据集上对应的Rank-1和mAP分别提升了2.9个百分点和3个百分点,在iLIDS-VID数据集上对应的Rank-1 和mAP 分别提升了3.3 个百分点和4.3个百分点。此结果证明了时域池化模型的有效性。
(2)时域注意力模型。表2给出了时域注意力QAN模型在Mars 数据集上的实验结果。QAN 模型在ResNet50 提取特征的基础上进行卷积池化和全连接操作,根据图像质量学习出不同帧的权重大小,随后指导序列特征的加权融合。实验中,Batchsize 设置为32,送入的帧数分别为2、4、8、16;当学习率设置为0.000 3时,模型训练效果最好。表2 结果证明了时域注意力模型同样可以改善算法的性能指标,与表1中的基准算法相比,T=4 时在 Mars 数据集上对应的 Rank-1 和 mAP 分别提升了1.6个百分点和0.8个百分点,在iLIDS-VID数据集上对应的Rank-1 和mAP 分别提升了2.0 个百分点和2.7个百分点。值得指出的是,与时域池化模型相比,时域注意力模型并未呈现优势,分析原因在于行人视频持续时间较短,序列间图像质量差异变化不大,因此时域注意力的优势没有充分发挥出来。
(3)循环神经网络。RNN 选取LSTM 作为基本单元,每个时刻送入一帧行人图像特征,并将LSTM 每个时刻的输出特征保存,最后把LSTM输出的所有特征进行平均作为最终的视频特征表达。测试了LSTM 隐状态个数分别为512、1 024、2 048 三种情况,当隐藏状态个数为512 时,模型性能最好,因此该参数取为512;学习率设置为0.000 1。表3 给出了循环神经网络模型在不同帧长下的实验效果。与表1中的基准算法相比,加入循环神经网络模型后的效果有所下降,这表明RNN在捕获序列时域信息方面没有效果,或者在Mars和iLIDSVID 数据集上训练RNN 网络效果不佳。如文献[15]所分析,RNN之所以在文献[6]中能够改善算法性能,其原因可能是文献[6]中采用的是浅层CNN 特征,而其后的RNN时域模型的效果更多体现为特征提取的补充。而本文使用在Imagenet 上预训练好的Resnet50 网络提取特征,其已具有一定程度的鲁棒性。故RNN 可能不能对其此特征再进行表达方面的学习而只是进行简单的行人分类,因此导致模型效果不佳甚至略有下降。

表1 时域池化模型在Mars和iLIDS-VID数据上的结果 %
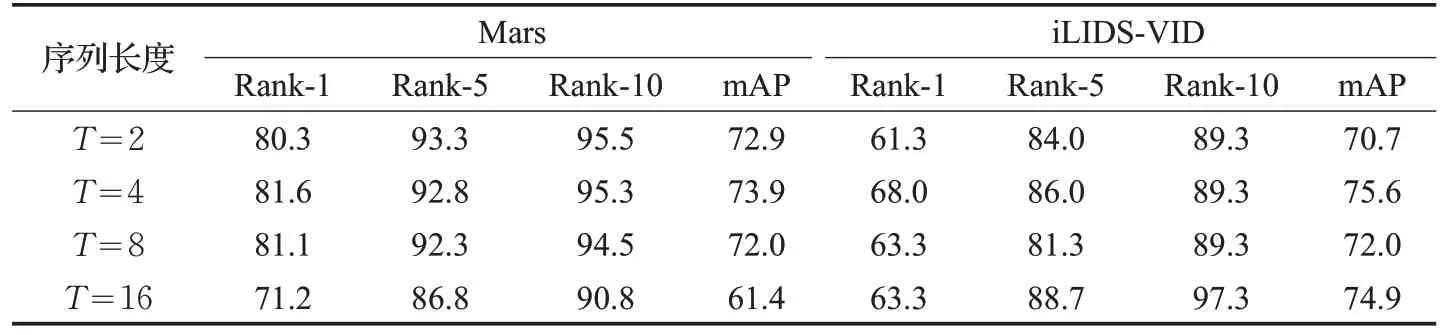
表3 循环神经网络模型在Mars和iLIDS-VID数据上的结果 %

表4 时域模型特性分析
(4)三种时域建模方法的比较。表4 给出了T=4时本文三种行人重识别时域模型的对比。时域池化模型的机制简单而直观,参数量最少。时域注意力模型需额外的网络模型来学习注意力权重,故网络结构最复杂且参数量最多。隐藏状态个数为512 时的循环神经网络参数量较少,能够自动学习模型参数。
(5)与其他视频行人重识别算法的比较。表5给出了当前主流的视频行人重识别算法和本文研究的3 种时域模型方法在Mars 和iLIDS-VID 数据集上的实验结果,其中Ours(image)代表基于图像的行人重识别算法,即表1 中T=1 的基准算法;Ours(pooling)、Ours(attention)、Ours(RNN)分别为表1、表2、表3 中T=4 对应的算法。
从表5可以看出,本文所研究的方法在识别性能上均普遍超过了文献[9-10,12,19,21]中的方法,其原因在于本文选取的ResNet50模型在图像特征提取上性能更优,同时本文研究的方法中采用三元组损失和交叉熵损联合训练模型。例如,文献[9]采用交叉熵损失训练CNN 模型,再利用最大池化(Max-Pooling)将多个行人的单帧图像特征融合为一个序列特征;相比之下,Ours(pooling)选用三元组和交叉熵联合损失函数,并采取了平均池化的方式融合特征,Rank-1从65%提升到83.4%,mAP 从 45.6%提升到 76.2%。Ours(attention)是在文献[10]基础上的改进,文献[10]采用VGG网络提取图像特征,本文使用的是ResNet50模型,同时又引入了三元组损失,因此取得了比文献[10]更好的结果。在文献[12]中,作者使用三元组损失和循环神经网络提取行人鲁棒性特征;相比于该文献,Ours(RNN)是针对行人图片特征使用循环神经网络,也取得了优于文献[12]的结果。

表5 与其他视频行人重识别算法的比较%
4 结束语
基于视频的行人重识别是近几年兴起的一个研究热点,相比于基于图像的行人重识别,视频Re-ID 需设计时域模型用以挖掘视频序列中特有的时域信息。本文通过在Mars 和iLIDS-VID 数据集上的实验,比较与分析了三种不同的时间建模方法。实验结果表明,与基于图像的行人重识别基准算法(Baseline)相比,采用时域池化模型或者时间注意力模型均可以将Rank-1、mAP等指标提高2%~3%;而循环神经网络的时域建模性较差,其效果比基准算法有所下降。与当前主流的视频行人重识别算法比较,本文讨论的四种算法在CMC@Rank-n、mAP 指标上均有较大幅度的提升,这说明了图像特征提取、损失函数设计对视频Re-ID的性能也将产生很重要的影响。上述结论将为设计基于视频的行人重识别算法提供有意义的借鉴。
