结合触发事件及词性分析的敏感信息识别方法
2020-10-19王永利周子韬张才俊
刘 聪,王永利,周子韬,犹 锋,张才俊
1.南京理工大学 计算机科学与工程学院,南京 210094
2.南瑞集团有限公司/国网电力科学研究院有限公司,江苏瑞中数据股份有限公司,南京 210094
3.国家电网有限公司客户服务中心,南京 210094
1 引言
近年来,我国境内暴力恐怖袭击事件的发生频率有所上升,严重影响了社会秩序和人民生活。
目前敏感信息的识别主要包括了文本、图像、音频、视频等文件格式中敏感信息的识别,其中,应用较为广泛的是文本中敏感信息的识别。传统敏感信息的识别主要是实现诸如人名、地名、机构名等命名实体的识别,或者是通过词典匹配实现敏感信息的识别。然而传统敏感信息识别方法忽略了上下文语境和关键词词性给敏感信息的识别带来的影响,例如:实例1“李明准备国庆期间去天安门旅游”和实例2“李明准备国庆期间去天安门安置炸弹”,传统敏感信息识别方法将“天安门”定义为敏感词,最终识别所得的结果为两个实例都是敏感信息。然而结合上下文语境而言,实例1并不是敏感信息,传统敏感信息识别方法出现了误报,将非敏感信息识别为敏感信息。在敏感信息识别过程中,结果的误报和漏报对敏感信息识别的精确度都造成了一定的损伤。此外,文本中往往存在许多与敏感信息识别结果不相关的文本信息,传统的敏感信息识别方法将与识别结果不相关的信息纳入识别范围,不仅占用了大量的空间,还降低了敏感信息识别的性能。
1.1 文本表示技术
文本的表示可以分为对词语的表示以及对文本的表示,词语的表示通常分为两种:One-hot 表示、词向量表示。One-hot 表示是基于规则、统计学习模型中最常见的词语表示方法[1],但是One-hot表示方法得到的词向量十分稀疏,向量维度过高,可能导致维数灾难。词袋模型(Bag of Words,BOW)是一种向量空间模型,在该模型中,文本被视为无序的词汇集合[2]。词袋模型仅仅记录每个单词在文档中出现的频率,且不会考虑单词出现的顺序,因而忽略了语法和词汇之间的顺序关系。向量空间模型(Vector Space Model,VSM)是一种将文本表示为向量的代数模型[3],该模型的向量空间上的相似度可以表示语义的相似度,然而该模型忽略了词语的位置关系。通过上述文献可以得知,在传统的文本表示方法中,特征工程至关重要。神经网络语言模型(Neural Network Language Model,NNLM)是神经网络语言模型的经典之作[4],该模型训练得到的词向量满足“上下文相似时,词向量也相似”的特性,其缺点在于参数规模大,算法的时间复杂度高。文献[5]提出了Glove(Global Vectors for Word Representation)模型,该模型通过把一个单词表达成一个实数组成的向量,捕捉单词之间的语义特性,但是该模型在训练过程中需要使用全局信息,耗费大量内存。Mikolov 等人[6]提出了CBOW 和Skip-gram 两种模型进行词语的分布式表示,这就是Word2vec的原理。这两种模型通过减少训练过程中所需要的参数,从而避免过拟合,在保证词向量质量的同时,提升了训练效率,节省了内存空间。受文献[1-6]的启发,为了有效捕获单词之间的语义特性,保留待识别文本的完备性,同时避免词向量的训练过程过于复杂,本文基于Word2vec表示方法进行文本的向量化表示。
1.2 文本相似度计算
针对文本相似度的计算,文献[7]提出了N-gram相似度识别方法,N-gram是给定文本序列的前n项子序列,通过计算每一个单词的N-gram值来计算单词之间的相似度。但是该方法忽略了文本的上下文信息,不能反映文本潜在语义。文献[8]提出了一种考虑语义和词序的句子相似度计算方法,该方法通过计算两个句子的语义相似度和词序相似度,最后加权得到两个句子的最终相似度。文献[9]提出了一种基于VSM的文本相似度计算方法,并以加权的方式对传统的TF-IDF 算法的权重计算方法进行改进。文献[10]基于改进型VSM 结合余弦相似度的文本相似度计算方法和HowNet文本相似度计算方法,实现了基于改进型VSM-HowNet融合相似度算法。文献[11]提出了一种汉明距离的文本相似度计算方法,通过把文本表示0/1 向量,并计算编辑距离,最终得到文本的相似度。文献[12]综合TF-IDF 算法以及HowNet 的语义信息,利用汉明距离实现了文本相似度的计算。文献[13]通过考虑单词之间的语义关系,使用语义资源来减少维度,使用反向索引过滤出候选文档集,最终提出一种基于语义向量空间模型的文本相似性计算方法VSI-Cilin。文献[14]建立了基于神经网络的词向量模型,对搜狐、世界新闻等中文语料库进行训练,提出了一种利用词向量的计算文本语义相似度的方法。文献[15]提出了一种基于词向量的微博事件跟踪方法,利用词向量计算出词与词之间的语义相似度,提高了微博之间语义相似度的准确性。
针对传统文本相似度方法识别效率较低的问题,本文提出对文本进行敏感触发事件抽取,并根据敏感触发事件中关键词的词性对文本相似度识别算法进行改进,最终识别文本中的暴恐敏感信息。本文所做的贡献如下:(1)定义词性选择、敏感触发事件抽取的概念,在中文文本中通过敏感触发事件的抽取,获得词汇层面和句子层面的事件特征;(2)结合敏感触发事件的特征改进文本余弦相似度算法,降低敏感信息识别过程中出现的误报率、漏报率,提高敏感信息识别的性能。
2 敏感信息识别模型
传统的敏感信息识别方法忽略了词性、文本语境框架以及词序等对识别精确度造成的影响。此外,对文本中所有内容进行识别需要耗费大量的时间、空间。针对上述问题,针对暴恐敏感信息,本文提出将文本中的动词、名词构成的词性序列作为敏感触发事件,将词性序列中待识别的词语定义为关键词。结合敏感触发事件中词性序列的种类以及关键词的词性改进文本相似度算法,最终实现准确且高效地识别暴恐敏感信息。
暴恐敏感信息识别的流程如图1所示,主要有两个阶段,暴恐敏感词典构建阶段和暴恐敏感信息识别阶段。暴恐敏感词典构建阶段主要步骤包括扩充语料库,分词处理,将文本训练成词向量,构建暴恐敏感词典。暴恐敏感信息识别阶段主要由两个部分构成:构建敏感触发事件,结合词性改进文本相似度算法。

图1 敏感信息识别流程图
2.1 文本预处理
在中文文本敏感信息识别过程中,对文本的预处理是必要阶段。文本预处理操作包括:对文本进行分词、去停用词、词性标注、词性选择等。整个文本预处理的流程如图2所示。

图2 文本预处理流程
在文本预处理过程中,首先对文本进行分词处理,然后根据停用词表去掉分词结果中的停用词。在去除分词结果的停用词之后,进行词性标注和词性选择,选择出文本识别所需的关键词。
定义1(词性选择)为了通过词性筛选提取词汇层面和句子层面的事件特征,定义词性选择为通过关键词的词性对关键词进行筛选,最终得到构建敏感触发事件的关键词。
中文文本由九种基本短语组成:名词短语np、动词短语vp、形容词短语ap、副词短语dp、数词短语mp、区别词短语bp、地点短语sp、时间短语tp、准数词短语mbar。其中,地点短语sp、时间短语tp 可作为是名词短语np 的子类,而名词短语np、动词短语vp、形容词短语ap、副词短语dp 是中文文本中四类最常见的短语。区别词短语bp可视为形容词短语ap的子类,数词短语mp描述了汉语中比较特殊的名量、动量、时量和指量结构,准数词短语mbar的设定是为了解决目前的数词切分规范与句法分析的衔接问题。在上述的基本短语中,名词短语和动词短语对暴恐敏感信息的识别十分重要,为了提高敏感信息识别的精确度和效率,通过磁性选择进行敏感触发事件的抽取。
2.2 敏感触发事件抽取
在完成文本预处理操作之后,将预处理所得到词性序列用于敏感触发事件抽取。
定义2(敏感触发事件抽取)敏感触发事件(Sensitive Trigger Event,STE)是指在敏感信息识别过程中,判断文本是否是敏感信息的决定性事件。敏感触发事件抽取(Sensitive Trigger Event Extraction,STEE)通过抽取出词汇层面和句子层面的事件特征,最终获取文本的敏感触发事件。
采用确定有穷自动机(Daterministic Finite Automata,DFA)表示敏感触发事件的抽取过程,STEE可表示为一个抽象的计算模型:E=(W,Σ,f,S,Z),其中,W表示敏感触发事件的状态集合,即经过文本预处理获得的文本内容;Σ表示经过预处理后关键词词性的输入集合;f表示敏感触发事件的抽取函数,是W×Σ→W上的映射,如f(wi,a)=wj(wi∈W,wj∈W),即当前状态为wi,当输入的关键词的词性为a时,则会转移到状态wj;S∈W表示初始状态集合,包括动词状态、名词状态两种;Z是终态集合,即敏感触发事件的两种类型:名动词词性序列、动名词词性序列。
针对文本中反恐、暴乱等敏感信息的识别,将敏感触发事件分为两种:动名词词性序列和名动词词性序列。将分类规则定义如下。
定义3(敏感触发事件分类规则)词性序列以动词开始,之后由名词、动词构成的词性序列称为动名词词性序列;以名词开始,之后由动词、名词构成的词性序列称为名动词词性序列。
将动名词词性序列表示为X=v(n*|v*|(n|v)*|ε),动名词词性序列触发事件可能出现以下几种情况:
(1)动名词词性序列中的动词是敏感词,则该词性序列中动词作为敏感信息的触发事件,包含该动词的文本则为敏感信息。例如“放火”“杀人”“砍杀”“开枪”等。
(2)动名词词性序列中的动词不是敏感词,则有以下几种情况:
①若不存在敏感名词,则该文本不为敏感信息。例如“买苹果”。
②若存在敏感名词,且敏感名词之后没有动词,则该文本为敏感信息。例如“扔炸弹”。
③若存在敏感名词,且敏感名词之后存在动词,则该文本不为敏感信息。例如“去天安门旅游”。
动名词词性序列模板如表1所示。

表1 动名词词性序列模板
将名动词词性序列表示为X=n(n*|v*|(n|v)*|ε),名动词词性序列和动名词词性序列存在区别,名动词词性序列中可能出现以下几种情况:
(1)名动词词性序列中只有名词,文本的敏感性由名词的敏感性决定。若名词中含有敏感词,则文本为敏感信息;若名词中不含敏感词,则文本不为敏感信息。例如“枪支弹药”“本·拉登、李明”“香蕉苹果”。
(2)名动词词性序列中含有一个或者多个名词、动词,则有以下几种情况:
①若动词中含有敏感词,则该词性序列为敏感信息。例如“李明要杀人”。
②若动词中不含有敏感词,且名词中含有敏感词,则该文本为敏感信息,例如“本拉登坐飞机”。
③若动词中不含敏感词,且名词中也不含有敏感词,则该文本不为敏感信息,例如“李明坐飞机”。
名动词词性序列模板如表2所示。

表2 名动词词性序列模板
在网络文本中,暴力、反恐信息主要是由名词和动词所构成的短文本。
通过敏感触发事件的抽取,提取出词汇层面和句子层面的事件特征,抽取敏感触发事件的目的是获得对敏感信息识别贡献较大的信息。敏感触发事件的抽取不仅保留了文本语义的完备性,还减少了因忽略上下文语境而造成的识别结果的误报、漏报等,降低了无关信息对敏感信息识别性能的影响。
2.3 结合词性改进文本相似度计算算法
在实现敏感触发事件的抽取之后,通过计算敏感触发事件与暴恐敏感词典之间的文本相似度实现敏感信息的识别。
在传统的文本相似度算法中,不同词性的关键词权值都一样,然而关键词的不同词性对敏感信息识别的贡献度是不同的。因为名词、动词在暴恐敏感信息识别的过程中贡献度不同,所以应当具有不同的权值。因此本文提出一种结合敏感触发事件中关键词词性的文本相似度算法(Text Similarity Algorithm Combining Part of Speech,STEAP),该算法有助于提高文本相似度计算的准确性,从而提高敏感信息识别的准确性。结合敏感触发事件中词性信息的改进后文本相似度(敏感度)计算公式如下:
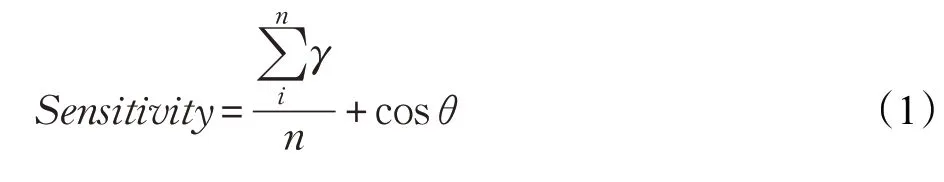

式中,n为待识别文本中提取出来的词性序列的关键词个数,γ为权重系数,且满足条件α,β,δ,μ∈(0,1);C(wi)为敏感词wi的词向量,C(wj)为待识别文本中关键词wj的词向量,cosθij为敏感词wi和关键词wj的词向量相似度,计算公式为:
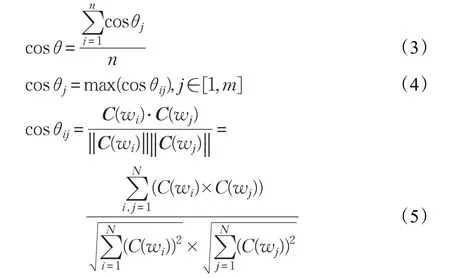
结合敏感触发事件中关键词词性的文本相似度算法伪代码如下所示:

在STEAP 算法中,输入内容为待识别的文本。该算法首先利用Word2vec 模型对语料进行训练,然后构建暴恐敏感词典d1=(w1,w2,…,wm),并用词向量C(wi)表示暴恐敏感词典中的各个敏感词。随后构建敏感触发事件d2=(w1,w2,…,wn),利用STEW 算法为敏感触发事件中的关键词分配权重,用词向量C(wj)表示敏感触发事件。然后利用WTW算法计算词向量C(wi)和词向量C(wj)的相似度。最后利用公式(1)计算敏感度,获得待识别文本的敏感度。
敏感触发事件中关键词权重计算算法的伪代码如下所示:

在STEW算法中,输入是敏感触发事件d2,根据定义3 对敏感触发事件d2进行分类,根据d2的种类以及关键词的类型为敏感触发事件中关键词分配权重,权重的分配规则如公式(2)所示。
敏感触发事件和暴恐词典中敏感词的相似度计算算法伪代码如下所示:

WTW算法中,输入词向量C(wi)、C(wj),首先计算关键词与敏感词典中各敏感词的相似度,然后取最大值,然后利用公式(1)计算敏感度。
根据STEW算法,敏感触发事件中关键词的权重的计算时间复杂度为O(n),根据WTW 算法,敏感触发事件和暴恐敏感词典中关键词的相似度的计算时间复杂度为O(n×m)。因为暴恐敏感词典中关键词个数远大于1,所以STEAP算法的时间复杂度为O(n×m),其中n表示敏感触发事件中词语的数量,m表示敏感词典中词语的数量。
3 实验结果与分析
3.1 构建暴恐敏感词典
为了使敏感信息的识别更加准确,需要尽可能完善暴恐敏感词典。在构建暴恐敏感词典的过程中,将人民网、台湾品聪网站、新浪微博的相关报道以及相关的评论作为本文数据的来源,在通过爬虫技术获得数据以后,根据近20年发生的暴恐事件进行文本的筛选,将暴恐事件集中的部分地区、民族、背后势力、使用武器等作为筛选因素,最终得到有效语料58 000条。
将获取的有效语料对Wiki 语料库进行扩充,然后进行文本预处理,再利用Word2vec 对扩充后的语料进行训练,用以完善暴恐敏感词典。敏感词是指能够用来判断文本是否含有敏感信息的词语。针对暴恐事件,暴恐敏感词典主要由人名、地名、机构名,暴恐事件中出现的武器、民族、动词等,以及网络中相关的隐晦表达词、网络用语等构成。
本文从爬取的语料中选取70%的数据用于敏感词典的构建,剩下的30%的数据用于敏感词典的测试和完善。首先将常见的敏感词添加到敏感词典,然后根据同义词词林对自定义的敏感词词典进行同义词扩展,再通过Word2vec 对语料进行训练得到对应的词向量,然后通过余弦相似度计算获得与敏感词相似度最高的前10个数据的信息,添加到敏感词典中。利用Word2vec 训练时对应的参数为:特征向量的维度size为300,上下文的窗口 window 为 10,训练并行数 worker 为 4,参数sg=0,表示选择CBOW 算法,为防止漏检一些出现频率极低的敏感词,将min_count的值设置为0。最终得到的暴恐敏感词典中一共含有敏感词8 267 个,其中名词5 105个,动词3 162个。
3.2 STEAP算法敏感阈值的确定
实现暴恐敏感信息的识别,除了构建并完善暴恐敏感词典之外,还有STEAP 算法敏感阈值的确定。敏感阈值是能最精确识别出敏感信息时的文本相似度,将相似度0.50作为敏感阈值的底部初始值,取长度0.05为间隔单位,每次实验增加一个间隔单位。将每次的值设定为待选阈值,通过计算该阈值条件下实验的准确率(precision)、召回率(recall)和F1 值三个指标对STEAP算法的敏感阈值进行确定,统计计算后取精确度最高的待选阈值为最终实际使用阈值。实验结果如图3所示。

图3 通过实验获得最佳阈值
由实验结果可知,敏感信息识别的精确率、召回率随着阈值的改变呈现不同的变化趋势。就精确率而言,当阈值小于0.85 时,精确率呈递增趋势;当阈值大于0.85时,精确率呈递减趋势;所以当阈值为0.85时,敏感信息识别的精确率最高,为87%。就召回率而言,当阈值小于0.80时,召回率呈上升趋势;当阈值大于0.80时,召回率呈下降趋势。本文将F1值作为最佳阈值选择的最终指标,经过多次反复实验得知,当阈值为0.80时,所得F1 值最大,为0.862 1,对应的识别精确率为86.36%,所以最终STEAP算法的敏感阈值为0.80。
3.3 对比实验
为了测试STEAP 算法识别敏感信息方面的性能,文本在17 400条文本测试集上进行多次实验,将本文提出的方法与其他几种方法在敏感信息识别的精确率和召回率上进行对比,实验结果如图4所示。这几种方法分别为:字典法、基于Word2vec 的余弦相似度算法(记为余弦相似度算法)、基于TF-IDF 的余弦相似度算法(记为TF-IDF算法)。

图4 敏感信息识别实验结果
从图4中可以看出,字典法在敏感信息识别实验中精确率和召回率最低,该方法过多依赖于所构建的敏感词典的大小。基于Word2vec的余弦相似度算法与基于TF-IDF的余弦相似度算法识别的精确率和召回率均比字典法高出了许多,这说明余弦相似度算法在文本的相似度识别方面具有较好的效果。STEAP 算法对基于Word2vec 的余弦相似度算法进行改进,通过识别文本中由名词、动词构建词性序列来识别文本中的暴恐数据,最终识别的精确率和召回率都高于前三种算法。
4 结语
本文提出一种结合词性的文本相似度算法STEAP。该方法首先通过词性选择对文本进行过滤筛选,然后针对文本中的暴恐敏感信息构建以名词、动词为主的词性序列,将其作为敏感触发事件。最后结合词性序列对基于Word2vec 的余弦相似度算法进行改进,得到STEAP算法。
实验结果表明本文提出的STEAP算法与传统的敏感信息识别方法相比,最终识别的精确率和召回率都更高,并且对于敏感信息的识别更加有效,降低敏感信息识别过程中出现的误报率、漏报率,提高敏感信息识别的性能。
在接下来的研究中,为了更加精确地识别出文本中的敏感信息,将利用深度学习方法研究基于情感分析的敏感信息识别方法。
