基于改进的深度信念网络的入侵检测方法
2020-10-19宋雪桦王昌达徐夏强蔡冠宇
汪 盼,宋雪桦,王昌达,陈 锋,徐夏强,蔡冠宇
1.江苏大学 计算机科学与通信工程学院,江苏 镇江 212013
2.江苏仅一联合智造有限公司,江苏 丹阳 212300
3.镇江市丹徒区科学技术局,江苏 镇江 212000
1 引言
随着通信技术的迅速发展,基于Internet 的研究和应用越来越广泛,网络安全问题日益凸显,安全防护技术已成为研究热点之一。入侵检测系统[1](Instrusion Detection System,IDS)是一种保护用户隐私和数据的重要网络安全防御手段。IDS 能够主动发现和识别入侵行为并采取相应操作,从而确保网络运行安全可靠。
为有效识别各种网络攻击,研究者将机器学习方法引入IDS 中,其中支持向量机算法[2](Support Vector Machine,SVM)较早应用在入侵检测技术中。假设n为训练样本数,则SVM 算法的时间、空间复杂度分别为O(n3)、O(n2),当网络入侵样本较少时,SVM 算法具有良好的学习和检测能力。文献[3]提出了一种基于交替决策树(Alternating Decision Trees,ADT)分类的入侵攻击方法,通过与朴素贝叶斯算法的对比实验验证了该方法提高检测准确率的同时降低了误报率。近来,遗传算法、随机森林[4]等算法先后应用于网络入侵检测。但是面对海量入侵数据的分类问题,传统浅层机器学习方法会受到时间和空间的限制,系统处理速度大幅度降低。
基于此,面向海量数据的入侵检测方法的研究重点在于进行特征学习和降维。Han等人[5]提出的入侵检测方法将朴素贝叶斯网络与主成分分析算法(Principal Component Analysis,PCA)结合,采用PCA 提取主要数据特征,可以有效减少网络数据的维数。Hinton 等人[6]提出的深度信念网络(Deep Belief Network,DBN)可以实现对大量无标签数据进行特征提取,该理论已成功地运用在语音识别、计算机视觉等领域。高妮等人[7]提出了面向IDS 的DBN 模型,深入分析和验证了DBN 网络结构对异常入侵行为识别性能的影响,实验结果表明DBN 适用于高维、非线性的海量无标签数据的关键特征提取。文献[8]充分考虑了DBN能够挖掘海量网络数据的丰富内在信息,提出了基于DBN-MSVM入侵检测方法。文献[9]将DBN与核极限学习机(Kernel Extreme Learning Machine,KELM)结合,提出了一种混合深度学习算法。汪洋等人[10]针对网络入侵检测中数据分布不平衡问题,提出了DBN-WOS-KELM 算法,能够实现在线更新输出权重。
为了DBN在重建误差时获得更好的收敛速度和训练效果,本文引入自适应学习速率(Adaptive Learning Rate,ALR)思想,根据参数每次迭代方向的异同来动态调整学习率,提出了一种基于改进的深度信念网络的入侵检测(Softmax Classification based on Improved Deep Belief Network,IDBN-SC)方法。在训练DBN模型过程中,利用自适应学习速率实现模型参数的快速收敛,采用softmax分类器对网络入侵行为进行识别分类。该方法可以有效提高对网络数据的检测准确率而且检测速度快。
2 特征提取原理
2.1 受限玻尔兹曼机
受限玻尔兹曼机[11](Restricted Boltzmann Machine,RBM)是一个包含可视层单元(v)和隐藏层单元(h)的两层神经网络,如图1所示。

图1 RBM结构模型
可视层单元v(v1,v2,…,vn)表示输入数据,隐藏层单元h(h1,h2,…,hm)进行特征提取,W为连接v和h之间的权重矩阵,a,b分别表示隐藏层和可视层的偏置向量,v和h服从伯努利分布。RBM 采用对比分歧算法(Contrastive Divergence,CD)的学习方法更新RBM 模型的参数θ(W,a,b)。

2.2 深度信念网络
在入侵检测过程中,网络数据只有部分特征被真正利用,因此通过深度信念网络进行提取数据特征,实现对海量高维原始网络数据特征降维。DBN结构模型如图2所示,DBN是由多层受限玻尔兹曼机网络和单层反向传播(Back Propagation,BP)网络依次堆叠构成的深层神经网络[12]。
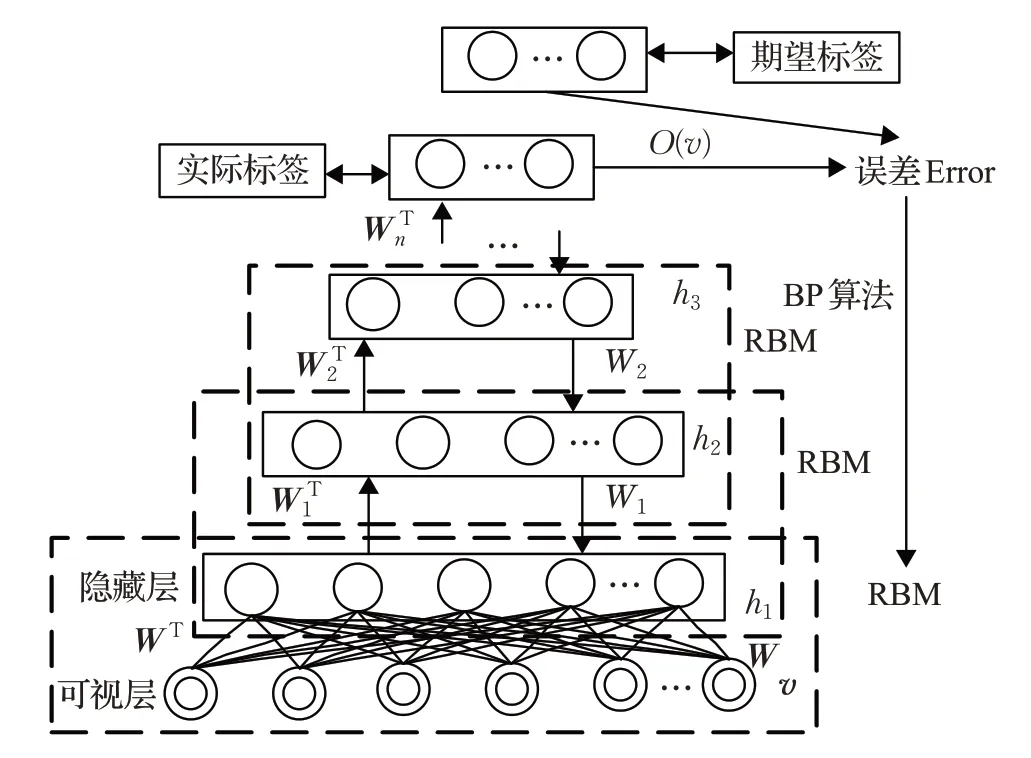
图2 DBN结构模型
在训练深度信念网络模型过程中,DBN 可以分为无监督的预训练和基于BP算法的权值微调两个过程。
(1)无监督的预训练:通过对比分歧算法逐层训练RBM 网络,将无标签原始网络数据映射至不同特征空间,从而保留数据的关键特征信息,获得较优的低维表示。
(2)基于BP 算法的权值微调:BP 网络设置在深度信念网络的最后一层,利用被附加到DBN 顶层的带标签数据,将误差损失自顶而下地逐层传播至每一层RBM 网络,对整个DBN 的权值进行调整,从而获得最优的低维表示数据[13]。
在基于BP 算法的权值微调过程中,首先计算训练样本xi经过DBN 的实际输出表示xi',对于输出层节点k,根据式(7)计算其实际输出表示与期望输出表示xi的误差项δk:

计算每个隐藏层节点h的误差项δh,更新每个网络模型参数θij:

其中,θhk为隐藏层节点h与后续输出层节点k的连接权值,η表示学习速率。
2.3 自适应学习速率
一般来说,逐层训练RBM网络需要较长的时间,因此选择适当的学习速率参数是提高DBN性能的重要因素。由于RBM在训练过程中每次迭代后的梯度更新方向不尽相同,为了提高RBM网络训练收敛速度,本文提出了一种自适应学习速率(ALR)方法。
与RBM 网络采用全局学习速率不同,ALR 方法是每个连接权重Wij对应一个学习速率εij。在更新模型参数过程中,学习速率由式(11)确定:

其中,μ表示学习速率的增量系数 (μ >1),d表示学习速率的衰减系数(d <1)。
如果两个相邻的更新梯度具有相同的方向,则当前模型参数的学习速率增加,而对于方向相反的参数更新梯度,则学习速率减小,从而可以有效避免训练过程中在非最优解处产生振荡。
传统固定学习率在网络更新权值过程中并不总是朝着减少损失函数的方向进行每一步调节,这导致收敛速度大幅度下降,但自适应学习速率方法可以根据相邻两次更新方向的异同自适应变化,能够克服传统固定学习率方法的缺点,通过自动调节学习率以变步长的方式加速了每个RBM 网络无监督学习(即从可视层输入高维数据到隐藏层所表示的低维抽象数据的过程)。
预训练阶段,在求解目标函数的最优解过程中,ALR 方法实现利用误差曲面的凹凸性自动增大或减少学习速度,确保模型能够准确且迅速地找到最优点。采用ALR方法的DBN模型不仅能够提高训练网络的鲁棒性,还能减少收敛过程所需的时间。
在每个RBM 的无监督学习过程中,网络输出与吉布斯采样过程的中间状态有关,ALR方法以变步长的方式有规律地增大或者减小模型对数据内在关联的学习力度。同时分层降维能够达到高维数据维数呈指数下降趋势,因此,在单个RBM 运用ALR 方法加速收敛的情况下,由多个RBM构成的DBN能够产生收敛速度指数提高的效果。
3 IDBN-SC入侵检测方法
3.1 入侵检测方法设计
本文提出的入侵检测方法总体设计框架如图3 所示,主要包含3个模块:数据预处理、IDBN特征降维、入侵识别。

图3 IDBN-SC入侵检测方法总体框架
(1)数据预处理。首先数值化NSL-KDD 数据集[14]存在的所有字符型属性特征,再归一化处理数值型数据,获得标准化数据集。
(2)IDBN 特征降维。对预处理后获得的数据集进行无监督的预训练和基于BP 算法的权值微调,获得最优的低维表示[15]。
(3)入侵识别。把降维数据输入到softmax分类器[16]进行训练分类。softmax 分类器输出的是分类概率,选取概率最大的分类,以具体的入侵类别的形式输出结果。
3.2 数据预处理
NSL-KDD 数据集的每条数据由38 个数字型属性特征和3个字符型属性特征组成。训练之前,需要对数据进行预处理。首先采用属性映射方法将所有字符型特征变换成数值型数据。例如“protocol_type”属性特征存在3种类型取值:tcp、udp、icmp,将其分别转化为二进制向量[1,0,0] 、[0,1,0] 和[0,0,1] 。以此类推,“service”属性特征存在70种类型取值,“flag”属性特征存在11种类型取值,这样可以建立符号值与其对应特征向量的映射关系,将41 个原始属性特征映射成122 维特征数据。然后最小-最大规范化处理获得的数据,以消除各属性间的量纲影响。根据式(12)将各属性特征归一化到同一数量级,即[0,1] 范围。

其中,y为特征属性值,ymax、ymin分别为该属性的最大值和最小值。
3.3 softmax分类器
设样本类别数量为k,模型参数为θ,对于给定的样本输入x,根据式(13)计算每一个类别j的概率值p(y=j|x):

对有m个样本点的数据集,softmax 回归[17]的损失代价函数为:
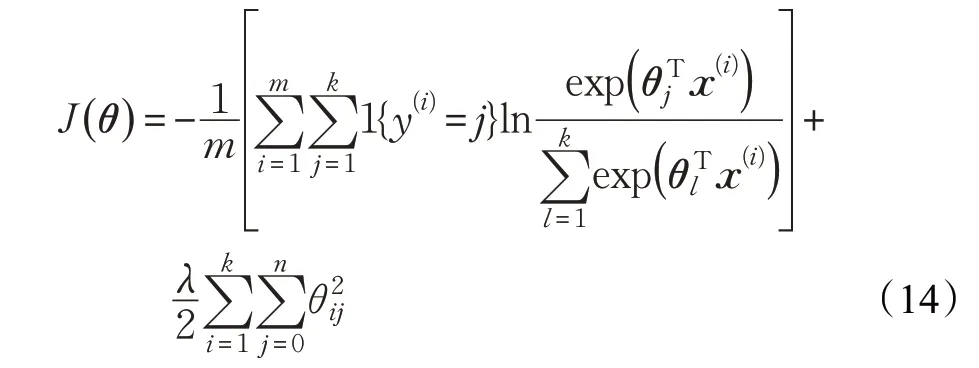
其中λ是权重衰减项,1{⋅}是示性函数,其取值规则:1{值为真的表达式}=1,1{值为假的表达式}=0。
式(14)运用了贝叶斯正则化的思想使J(θ)为严格凸函数,保证函数存在唯一解。对式(14)进行极小化,求出J(θ)对θj的偏导数,得到:

根据式(16)更新模型参数θ:

其中α为学习速率。
与SVM分类器相比,softmax分类器计算简单且高效,主要用于解决多分类问题。SVM 的计算是无标定的,并且难以针对所有分类的评分值给出直观解释,而softmax 函数将原始分类评分转化成归一化的对数概率,允许计算出对于所有分类标签的可能性,鼓励正确分类的归一化的对数概率变高,其余的变低。
针对网络数据的入侵识别问题,每种网络攻击类型之间是互斥的,softmax分类器的目标函数选择交叉熵,使得目标类的1{}⋅等于1,其他类的示性函数等于0。同时在softmax分类过程中网络数据的属性特征对其分类概率的影响是乘性的,使得目标类的对数概率远大于其他类。
4 实验及结果分析
4.1 实验环境和数据描述
硬件环境:64位Windows10操作系统、Intel i7处理器、8 GB内存和4 GB GPU的计算机。
开发环境:Eclipse+PyDev。
编程语言:Python。
测试数据集:NSL-KDD 数据集。该数据集包含125 973 个训练数据和22 543 个测试数据,各类数据具体分布情况如表1所示。

表1 各种类型数据分布情况
NSL-KDD 数据集被分成拒绝服务攻击(Denial of Service,DoS)、远程用户攻击(Remote to Local,R2L)、用户到根攻击(User to Root,U2R)、端口扫描攻击(Probe)4大类攻击类型和1类正常(Normal)数据。
4.2 实验评价指标
实验中,采用检测准确率(Accuracy,AC)、误报率(False Alarm Rate,FAR)、检测时间(Ti)和重构误差(error)作为衡量模型的性能的评价指标。

其中,n为样本个数,m为每层网络输入层节点个数,vki为第k个样本的原始数据,vki'为第k个样本的重构数据。
4.3 实验结果及分析
本文设计了3组实验:(1)不同IDBN网络深度对入侵检测的性能影响;(2)不同学习速率对重构误差的影响;(3)本文提出的入侵检测方法与其他方法的性能对比。
实验中自适应速率的初始值设置为0.05,增量系数μ和衰减系数d分别取值为1.25和0.8,将IDBN预训练的迭代次数设置为100 次,基于BP 算法的权值微调的迭代次数设置为120次。
4.3.1 IDBN网络深度实验
针对IDBN 的深度是影响入侵检测效果的重要因素,实验对5 种不同的IDBN 网络结构进行检测准确率和误报率对比。设置 IDBN2、IDBN3、IDBN4、IDBN5和IDBN6分别表示为122-110-30、122-110-70-30、122-110-90-60-30、122-110-90-70-50-30 和 122-110-95-70-50-40-30的RBM网络结构(IDBNi表示IDBN包含i层RBM)。从图4 可看出,IDBN 采用 4 层的 RBM 网络结构的检测准确率最大,误报率最低。
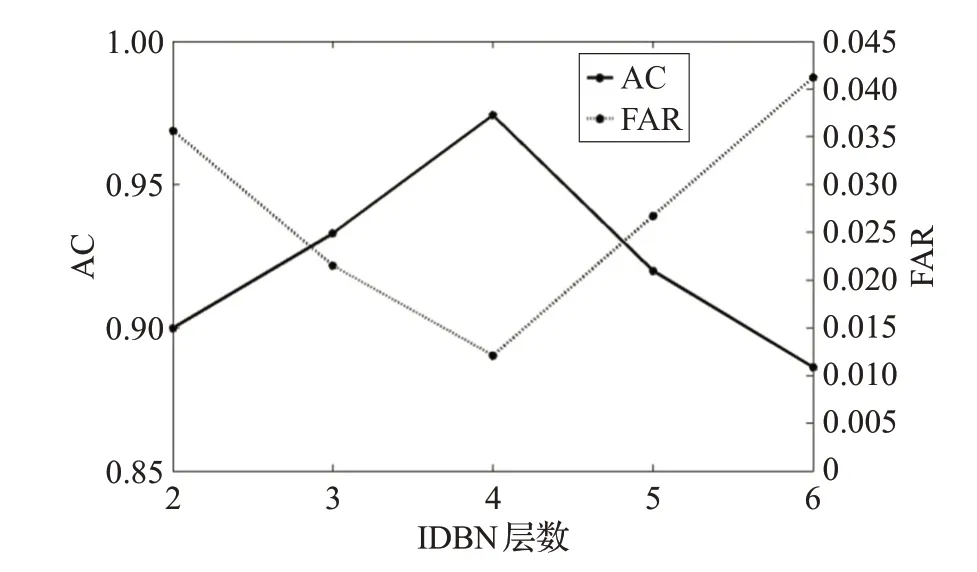
图4 不同深度的IDBN的性能对比
4.3.2 学习速率对比实验
本文提出的入侵检测方法中,IDBN 选取4 层RBM网络对输入数据进行特征降维。NSL-KDD数据集中41个属性特征经过数据预处理转化成122维特征,因此设置IDBN 的输入层节点数为122,隐藏层节点数依次选取110,90,60和30。
将自适应学习速率与三个不同的全局固定学习速率 (ε=0.005,ε=0.05 和ε=0.5) 进行比较,对比结果如图5所示。对于固定的学习速率来说,设置ε=0.5 的重构误差最大,ε=0.005 的训练收敛速度缓慢,而ε=0.05的结果最好。与固定学习速率相比,ALR在迭代次数为90左右之后,重构误差趋于平稳,在保证低重构误差的同时具有较快的收敛速度。
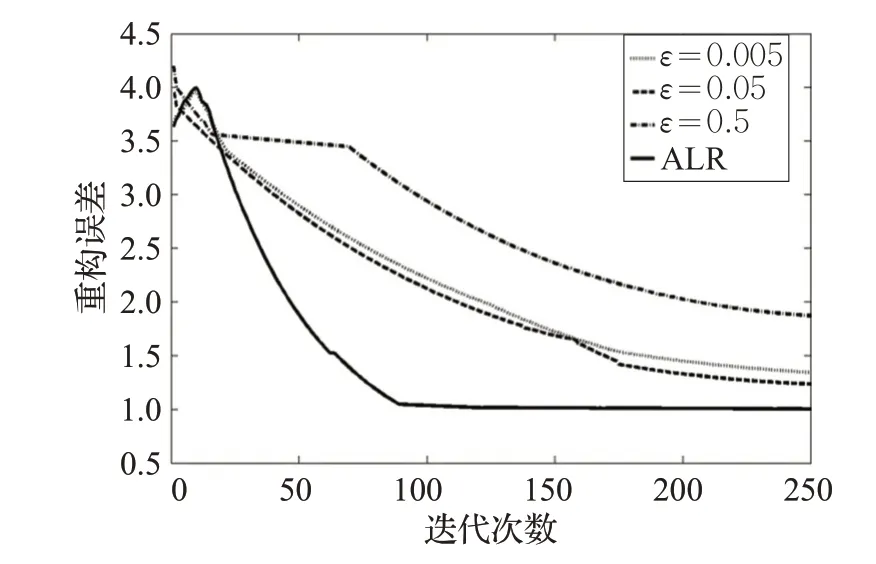
图5 ALR与固定全局学习速率的重构误差对比
4.3.3 各分类方法的检测性能对比实验
将IDBN、PCA、自编码网络(AutoEncoder Network,AEN)方法进行对比来分析特征降维效果。首先利用特征学习方法进行降维,然后采用softmax 分类器对降维后的网络数据进行入侵分类。在训练过程中分别抽取NSL-KDD数据集中20%、40%、50%、70%的数据进行实验分析。
从表2可以看出,在70%数据训练阶段,IDBN方法的准确率较PCA 和AEN 分别提高了2.97 个百分点和1.19个百分点。IDBN结合了无监督学习和有监督学习的优点,通过多次映射能够发现海量网络数据中的复杂结构及其概率分布。因此,对不同的数据集的测试表明,IDBN的准确率都比较高,对高维无标签网络数据的特征提取效果最好。

表2 IDBN与其他特征学习方法的准确率对比%
在NSL-KDD数据集中随机提取不同攻击类型进行分类实验,对比分析不同入侵行为的准确率和误报率。其中SVM 的核函数采用径向基函数,设置核函数控制因子g=0.000 01,惩罚因子C=1 000,采用10 折交叉验证获得较高的准确率。人工神经网络(Neural Network,NN)采用5层结构,利用BP算法优化网络,其余参数和DBN类似。
从表3可以看出,IDBN-SC方法对Normal、DoS、R2L、U2L 和Probe 的识别准确率分别是98.34%、97.25%、83.47%、78.12%和96.26%,相比其他四种方法准确率平均提高 7.49 个百分点。IDBN-SC 方法对 Normal、DoS、R2L、U2L 和 Probe 的误报率分别是 0.87%、1.23%、10.49%、17.12%、2.94%,误报率平均降低6.01 个百分点。IDBN-SC 方法利用IDBN 模型保留网络数据的关键重要特征,去除冗余特征,实现高维特征向量的特征提取,同时softmax 分类器支持类别互斥的数据分类。因此,实验结果表明IDBN-SC 方法在对不同入侵行为的检测准确率方面要高于其他四种分类方法,且更能精确检测网络入侵行为。

表3 针对不同攻击类型的性能比较 %
进一步验证IDBN-SC 方法的性能,随机抽取NSLKDD 数据集中20%、40%、50%、70%的数据,分别进行检测准确率和时间的对比分析。
从表4可以看出,IDBN-SC方法在不同的数据集上的准确率分别为96.43%、98.65%、97.37%、98.24%,相比较其他四种方法准确率平均提高3.02 个百分点。而IDBN-SC 方法在不同数据集上的分类处理时间分别为6.87 s、10.56 s、14.64 s、18.73 s,相比softmax方法平均缩短5.58 s,相比IDBN-SVM 方法平均缩短2.77 s。实验结果表明IDBN-SC方法在准确率上显著提高了网络入侵数据的识别能力,极大地缩短了softmax 分类器的训练时间。SVM分类器的时间复杂度是其输入向量的指数函数,softmax 分类器的时间复杂度是其输入向量的一次函数,ADT 分类器的时间复杂度与其输入向量和树的深度有关,NN 算法的时间复杂度与其输入向量和网络层数有关。因此,通过IDBN进行特征降维,IDBN-SC方法有效地减少分类器输入向量维数,以缩短网络数据分类的处理时间。

表4 几种入侵检测方法的性能对比
5 结束语
针对传统的入侵检测方法很难快速准确地分类通信过程中海量无标签网络数据的问题,本文利用深度学习在数据特征降维的优势,提出基于改进的深度信念网络的softmax 分类入侵检测方法。该方法利用IDBN 将大量高维无标签数据进行特征提取,使用ALR 保证模型参数快速收敛,采用softmax 分类器进行入侵行为识别。实验表明本文提出的IDBN-SC方法不仅提高了网络攻击分类准确率,同时显著地缩短了入侵检测的分类处理时间。IDBN-SC方法为入侵检测在区块链、物联网等领域的网络安全应用提供了一种高效、可行的研究方法。
