基于汉语框架语义的共指消解研究
2020-10-15吕国英武宇娟1b张月平郭少茹
吕国英,武宇娟,李 茹,1b,2,张月平,关 勇,郭少茹
(1.山西大学 a.计算机与信息技术学院; b.计算智能与中文信息处理教育部重点实验室,太原 030006;2.山西省大数据挖掘与智能技术协同创新中心,太原 030006)
0 概述
语义理解是完成语篇理解、机器翻译以及问答系统等语言处理任务的前提,基于框架语义的推理是实现语义理解的有效手段。基于汉语框架语义的推理是指通过框架语义推理解决问题,框架元素之间的语义相关性可以建立篇章句子之间的联系,这种联系正是实现框架语义推理的一种路径。框架元素内部表述的共指阻碍了框架元素之间联系的建立,因此,研究框架元素中的表述共指至关重要。
本文提出一种基于汉语框架语义的共指消解方案。对在CFN资源下标注的篇章进行数据预处理,采用基于规则的方法识别框架元素中的表述,利用分类模型进行表述消解,借助汉语框架语义信息提升消解效果。
1 相关工作
早期的共指消解研究方法主要是基于规则的方法。文献[1]提出2种基于句法分析树的算法,一种只考虑句法知识,另一种同时考虑句法和语义知识。文献[2]提出一种基于中心理论[3]的BFP算法,其通过设置词汇句法、约束以及类型标准等筛选条件为代词寻找合适的先行语。文献[4]简化了文献[5]提出的RAP算法,其通过分析得到文本的句法功能和词性,根据这些信息为特征赋予不同的重要性(突显性),然后根据突显性得分来确定先行词。
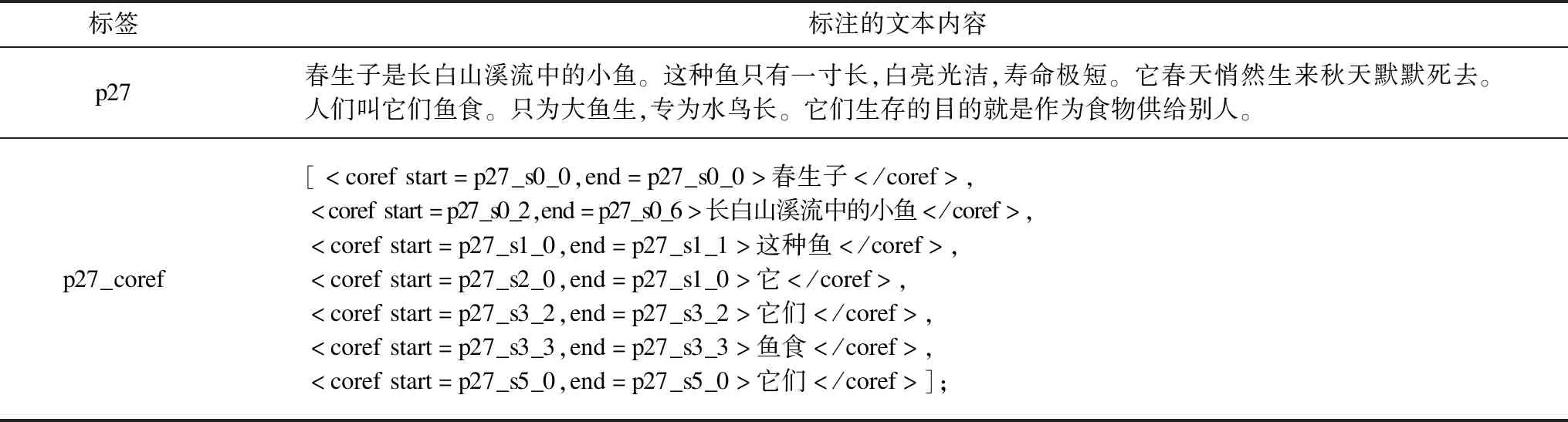
在基于机器学习的共指消解研究方法中,实例构建和特征选择是重要步骤,其中主要的学习模型为表述对模型、实体-表述模型和表述排序模型。文献[6]使用表述对模型提出一种实例构建的规则以降低正负例的不平衡性,为文本中的每个表述mi选取其前面最近的共指表述mj(j 近年来,深度学习成为共指消解的主流方法,其依赖大规模的语料集。文献[10]采用Esay-first原则,即先进行简单决策,当学习到更多的特征和更精确的权重时再进行复杂决策,这种方法使用神经网络自动学习可用信息。文献[11]结合表述对模型和表述排序模型的优点,其整合得分以定义有用的实体级特征,并利用表述对模型得分删减搜索空间,从而学习有效的共指策略。文献[12]将强化学习直接应用于神经网络排序模型,使用强化策略梯度算法和最大间隔损失函数进行实验,在CoNLL 2012 Shared Task数据集的中英文部分都取得了很好的结果。 与英文共指消解研究相比,中文共指消解研究起步较晚。研究人员结合中文文本的特点,将类似英文的消解方法用于中文消解的研究中,取得了一定的成果。文献[13]基于树核函数从使用中心理论、集成竞争者信息和融入语义角色相关信息等方面动态扩展结构句法树,从而提升代词消解的性能。文献[14]提出一种表述识别的改进方法,针对代词和专有名词进行分类过滤,保留所有的名词短语,其有效提升了全自动的汉语指代消解性能。文献[15]提出一种DBN模型的Deeping Learning学习机制,使用多层无监督的RBM网络和一层有监督的BP网络,获取文本语义特征并进行指代消解,ACE04英文和ACE中文上的实验结果表明,该方法通过增加训练层数提高了系统性能。 基于汉语框架语义的共指消解是指从篇章句子中找到框架元素中的实体表述,并对这些表述进行共指消解,其任务示例如例1所示。 例1对荷兰而言, 问题为什么 例1为在汉语框架网(Chinese FrameNet,CFN)体系下标注过的语篇片段,包括3个句子。对于句子S1和S2,目标词“是”激起框架“状态”,其框架元素集合为{Entity(实体),State(状态)}。其中,“实体”分别为“中国”和“荷兰”,“状态”分别为“非常重要的贸易伙伴”和“中国在欧盟的第二大贸易伙伴”。对于句子S3,目标词“有”激起框架“拥有”,其框架元素集合为{Owner(物主),Possession(拥有物)},其中,“物主”为“两国”,“拥有物”为“巨大的合作潜力”。在回答问题“为什么两国拥有巨大的合作潜力”时,首先需要确定“两国”的指代对象。虽然人们可以很容易判断“两国”代表的是“荷兰与中国”,但是对于计算机而言,这是一个难度较高的问题。在CFN下回答这类推理问题时,仅通过框架标注不能直接确定“两国”为“荷兰与中国”,但如果加入“荷中”与“两国”、“荷”与“荷兰”以及“中”与“中国”的共指关系,就很容易确定“两国”的贸易关系,得到“合作潜力”体现为“贸易伙伴关系”。需要从框架元素中抽取并判断为共指关系的表述为[荷中,两国]、[荷,荷兰,第二大贸易伙伴]、[中,中国,贸易伙伴,我国]。 CFN[16]以框架语义学[17]为理论基础构建,其为一个大规模的词汇语义知识库,应用于语言学、计算语言学和自然语言处理等领域的研究。通过框架语义可以挖掘词语潜在的概念结构和语义场景[18]。框架是指由词元以及与其相联系的框架元素构成的表达特定场景的句子语义结构形式。本文研究基于标注的CFN资源。在CFN中,对于每个框架按照“框架”“框架元素”“词元”和“框架关系”4个方面进行描述。为了便于理解本文任务,介绍框架语义标注中的一些重要概念,具体如下: 1)词元(框架承担词)包括动词、形容词和名词,目标词是指在句子中能激起框架的词元。 2)框架中涉及的各种参与者、外部条件等称为框架元素。框架元素分为核心框架元素与非核心框架元素,核心框架是一个框架在概念理解上的必要成分[19],在不同框架中它们的数量和类型不同,显示出框架的个性。非核心框架元素则表达时间、地点等通用语义成分。 3)对每一个承担语义角色的框架元素进行3层标注,包括语义角色标注(语义信息)、短语类型标注(词性)和句法结构标注(句法信息)。比如,例1中框架元素 4)框架关系是指语义场景之间的关系,CFN详细定义了8种框架关系[19],分别为继承、使用、总分、透视、先后、因果、起始和参照,框架通过这些关系形成了网状结构。 共指主要指2个表述(一般是名词,包括专有名词、名词短语和代名词)指向真实网络世界中的同一实体[14],其为一种等价关系。共指消解主要研究的是在一篇文本中如何找到指向同一实体的名词,形成若干共指链。回指是指当前的照应语与前文出现的词、短语或句子存在指代关联,不一定满足等价性。共指与回指构成了指代的全部内容,早期研究没有明确区分共指与指代,因此,一些针对指代消解的研究方法同样适用于共指消解。 基于框架语义的共指消解问题可以形式化描述为:给定已标注框架语义的篇章[19]D={s1,s2,…,sn},其中,sk(k∈[1,n])为篇章D的第k句。sk中能激起框架的目标词的集合为Tk={Tk1,Tk2,…,Tkp},目标词对应的框架集合Fk={Fk1,Fk2,…,Fkp}。对于某个框架Fki,其框架元素集合为FEki={Feki,1,Feki,2,…,Feki,q}。对于某个框架元素Feki,x,其中包含了若干个表述Feki,x={menki,x,1,menki,x,2,…,menki,x,m}。基于框架语义的共指消解就是找到篇章中指向同一实体的表述menki,x,l,形成若干条共指链。因此,本文的研究步骤为:首先识别出框架元素中的表述,然后判段表述是否指向同一实体从而生成共指链。基于框架语义的共指消解系统结构如图1所示。 图1 基于框架语义的共指消解系统结构Fig.1 Coreference resolution system structure based on framework semantics 由共指消解实体表述的类型可知,能够成为表述的主要有专有名词、名词性词和代名词(名词性代词,指向的实体类型为实体名词)三类。实体表述识别的主要工作是确定篇章中哪些名词短语需要进行共指消解。对于该任务,本文根据框架多样性的特点设置了以下识别方法,其中,例2为文本在篇章库中的存储格式。 1)抽取文本中的表述 应用CFN的资源标注规则,将标注框架中类型为“np”“tp”和“sp”的短语直接用作表述。比如,例2中的“大陆人”“它”,其标注格式为 应用相关文法信息对框架元素内部的短语进行抽取。比如,例2中框架元素“其植株”中的“其”和“植株”,标注格式为 例2 2)选择相关规则过滤表述 本文使用的规则集是文献[20]提出的中文平台特有的规则集。先去除停用词,所有出现在停用词表中的名词短语均被认为是非表述,然后按照排除规则集,将符合特定模式的某些名词短语标注成非表述,最后按照保留规则集,将符合特定模式的某些名词短语标注成表述。 实体表述的消解旨在对识别出的表述进行消解,形成若干条包含实体表述的共指链,其基本思路是采用分类思想判断2个表述是否指向相同的实体,并利用传递关系将指向同一实体的表述链接成一条共指链。 3.2.1 表述对构建 共指消解是一个分类类别(共指和不共指)已经确定的分类问题,本文将共指问题转换成二元分类问题。将抽取出的篇章框架元素中的所有表述两两配对形成不重复的二元组,如下: 上述二元组可以包括重复的文本,但其在语料中的标识是唯一的,这样共指问题就转换为每一对实体表述是否指向同一实体的二元分类问题。 3.2.2 特征选择 本文使用共指消解的基础特征和框架特征进行实验,选取的基础特征参考文献[21],它们是共指研究中的常用特征。表1所示为共指消解的基础特征集。 表1 共指消解的基础特征描述Table 1 Basic features description of coreference resolution 本文表述的单复数属性值主要分为单数、复数和无单复数3类,根据一些明显的特征词来构建单复数字典,通过字符匹配判定其单复数,特征不明显的表述赋值为无单复数。比较2个表述的单复数属性值,一致则返回1,不一致则返回0。长字符Dice系数如式(1)所示: (1) 其中,comm(s1,s2)是表述对相同字符的个数,leng(s1)和leng(s2)分别是表述对的字符串长度。 考虑到在每个表述对中,不同的字符串长度对公共字符串的敏感程度不同,本文对传统Dice系数进行变形,得到短字符Dice系数,如式(2)所示: (2) 本文分析框架标注信息及框架之间的关系,得到表2所示的框架特征集。 表2 共指消解的框架特征描述Table 2 Framework features description of coreference resolution 本文使用余弦相似度来计算2个目标词的相似度。具体地,使用Word2Vec工具训练词向量,通过式(3)计算2个框架的目标词相似度: (3) 其中,CosDis(t1,t2)用来计算2个目标词对应词向量t1和t2的余弦相似度,n为词向量的维度。需要说明的是,对于同一表述分属于不同框架的框架元素,本文采用的方法是分别计算每一对目标词相似度然后取均值,这是因为目标词激活了不同框架,需要综合多个框架信息。 如图2所示,2个表述激起的框架名为“命名”和“陈述”,通过一个框架“信息交流”建立联系,则框架关系路径返回值为1。各个框架通过这些关系形成了框架的网状结构,有时2个框架间的关系路径不止一条,则选择最近的一条。 图2 框架关系路径示意图 句法功能和短语类型返回实数类型值。以短语类型为例,假设当前表述对为(表述1,表述2),从表述列表中分别检索出表述1和表述2,得到其短语类型type1和type2,如果type1与type2相同则返回1,否则返回0。比如,“太原”和“首都”都被标注为“sp(处所短语)”,而“2019年1月”被标注为“tp(时间词性短语)”,则“北京”和“首都”更容易存在共指关系。句法功能特征与短语类型具有相似的处理方法。一般而言,具有共指关系的表述的短语类型往往相同,且句法结构也存在一定关联。 本文使用核心框架元素来表示框架特有的语义信息。在数据预处理阶段,抽取出每个框架下的核心框架元素,使用Glove模型分别训练词向量,某个框架的向量表示为该框架下的所有核心框架元素的向量均值。对于某个框架Fk,其核心框架元素集合为FEk={Fek,1,Fek,2,…,Fek,q},计算公式如下: (4) 比如在“比赛结果”框架下,其核心框架元素有“赛事名称”“参赛者”“参赛双方”和“对手”,则将4个词向量的向量均值作为框架“比赛结果”的框架向量,然后计算2个表述的框架向量相似度作为返回值。 3.2.3 成对分类模型 成对分类模型即表述对的二元分类模型。本文使用的语料选自汉语框架标注的资源,由于标注平台还不够完善,标注的语篇语料较少,受限于语料规模,适合使用传统的机器学习算法。 以支持向量机(SVM)为例构建分类模型。给定训练数据集D={m1,m2,…,mt},其中,特征向量m={f1,f2,…,fn},n为特征个数。SVM算法根据给定的D寻找最佳决策边界划分数据的共指类别和不共指类别。定义模型的决策边界函数h(x)为: h(x)=wTx+b “你有没有想过,万一我,或者夏冰被警方抓了,我们拒不承认开车撞了人,警方说不定会怀疑那个拍照的人?尤其是夏冰,他可能供出你。” (5) 其中,w为特征权重向量,b为偏移向量,用于训练各特征的权重。共指分类问题可以写成如下形式的优化问题: (6) s.t.yi[wTΦ(xi)+b]≥1-ζi,ζi≥0 (7) 在训练时可以选择调节参数C和ζ,本文使用sklearn的SVM工具包,通过不同的参数设置进行实验。在分类问题中,特征选择的优劣直接影响模型的性能,本文将表1、表2所示特征经过处理后作为分类器的输入从而训练模型。 常用的共指消解语料有MUC语料、ACE语料和OntoNotes语料3种。其中,OntoNotes语料中包含英文、中文以及阿拉伯文3种语言,为共指消解研究人员提供了标注的训练语料以及测试语料,是当前比较流行的共指数据集。 在汉语框架标注的资源中,没有专门针对共指消解研究的语料,而在大数据集上构建CFN标注资源需要耗费大量的人力和时间。因此,本文在CFN资源的基础上增加共指标注,仿照ACE语料共指的标注,通过共指链描述篇章中的共指关系。增加的标注内容如表3所示。 表3 标注的共指语料Table 3 Annotated coreference corpus 其中,p27表示裸文本的内容,p27_coref表示增加的共指标注内容。实体链之间用“;”分隔,一个“[ ]”表示一个实体,表述文本包含在共指标签内,“”表示表述的开始位置和结束位置,“start=”和“end=”表示表述在文档中的位置,其作为表述的唯一标识。 本文使用的语料涉及地理、历史和科技等15个领域,共216篇。通过山西大学人机协同标注平台进行句子集语义角色标注,共指标注由专业人员进行手工标注和检验。实验数据统计如表4所示。 表4 实验数据统计结果Table 4 Statistical results of experimental data 本文采用MUC评价标准,有准确率P、召回率R和F值3个重要指标,其中,准确率反映消解结果的准确性,召回率反映消解结果的完备性。两者分别定义如下: 其中,TP表示表述对之间的关系为“共指”且预测为“共指”,FP表示表述对之间的关系为“不共指”而预测为“共指”,FN表示表述对之间的关系为“共指”而预测为“不共指”。使用F值评价系统的总性能,F值是召回率和准确率的综合体现,定义如下: 其中,β为召回率和准确率的相对权重,一般取1,因此,F值可以表示为: 利用本文方法对语料进行实验,结果如表5所示。从表5可以看出,相比单独使用普通特征或单独使用框架特征,同时使用这2类特征在不同分类器上的F值均有所提高,原因是框架特征是一种句子级的语义特征,其有效刻画了表述的局部特征。分析分别使用SVM[22]、朴素贝叶斯(NB)[23]、最近邻(KNN)和决策树(DT)[24-25]的实验结果可以看出,SVM分类效果优于其他分类器,表明在汉语框架标注的资源中,SVM更适合解决共指消解问题。SVM算法在结合框架特征以后,其准确率得到明显的提高,但是召回率提升不明显,原因是语料规模小,使得框架的所有语境并不能被完全覆盖,某些具有关系的框架由于框架缺失而不能建立联系。加入框架特征后F值虽有提升但仍然不佳,究其原因,一是在表述识别任务中无法检验识别表述的有效性,二是同一目标词会激起语义的不同框架(框架排歧),而不同目标词也会激起相同框架(同一框架下的不同词元),使得框架语义存在偏差。 表5 不同特征类型在4种分类器中的实验结果Table 5 Experimental results of different feature types in four classifiers % 为了选出有效的特征组合,本文进行大量的对照实验。以SVM为例,分别从特征组合中去掉每个框架特征,得到表6所示的实验结果。 表6 单个框架语义特征消融实验结果Table 6 Experimental results of single frame semantic feature ablation % 从表6可以看出,虽然每个特征对共指结果的影响不尽相同,但是3项指标的结果非常接近,说明框架特征刻画的是语义的不同方面,且相互之间具有促进作用。其中,对准确率影响较大的特征为框架元素距离(F3)、句法功能(F4)和短语类型(F5)。 分别去掉组合中的一些框架特征,得到表7所示的实验结果。 表7 多个框架语义特征消融实验结果Table 7 Experimental results of multiple frame semantic features ablation % 从表7可以看出,在2个特征组合中,框架关系路径(F2)和框架元素之间的距离(F3)对准确率的影响较大,可见框架之间的关系能够提升实验效果。而对F值影响较大的是核心框架元素(F6)和目标词激起的框架元素相似度(F8),这2个特征是从语义方面对表述对进行描述。 本文通过研究框架元素中表述之间的共指关系,确定框架元素以及句子之间的联系,从而实现框架语义推理。对于表述识别任务,使用汉语框架标注资源结合基于规则的方法进行表述抽取和过滤。通过结合框架特征与基础特征实现表述消解。实验结果验证了本文方法的可行性。表述识别是解决共指消解问题的基础,下一步将在扩大语料的同时结合框架语义类型,设计一种有效的表述识别方法以提升消解效果。2 相关技术介绍
2.1 汉语框架网
2.2 共指消解
3 框架元素中的表述识别与消解建模

3.1 表述识别
3.2 表述消解

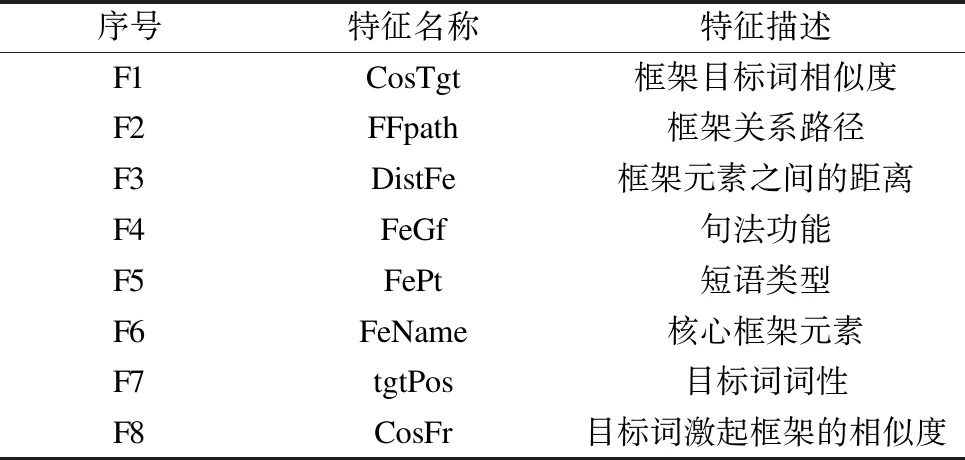

Fig.2 Schematic diagram of framework relationship path4 实验结果与分析
4.1 实验方案

4.2 评价指标
4.3 结果分析



5 结束语
