Neighborhood fusion-based hierarchical parallel feature pyramid network for object detection
2020-10-15MoLingfeiHuShuming
Mo Lingfei Hu Shuming
(School of Instrument Science and Engineering, Southeast University, Nanjing 210096, China)
Abstract:In order to improve the detection accuracy of small objects, a neighborhood fusion-based hierarchical parallel feature pyramid network (NFPN) is proposed. Unlike the layer-by-layer structure adopted in the feature pyramid network (FPN) and deconvolutional single shot detector (DSSD), where the bottom layer of the feature pyramid network relies on the top layer, NFPN builds the feature pyramid network with no connections between the upper and lower layers. That is, it only fuses shallow features on similar scales. NFPN is highly portable and can be embedded in many models to further boost performance. Extensive experiments on PASCAL VOC 2007, 2012, and COCO datasets demonstrate that the NFPN-based SSD without intricate tricks can exceed the DSSD model in terms of detection accuracy and inference speed, especially for small objects, e.g., 4% to 5% higher mAP (mean average precision) than SSD, and 2% to 3% higher mAP than DSSD. On VOC 2007 test set, the NFPN-based SSD with 300×300 input reaches 79.4% mAP at 34.6 frame/s, and the mAP can raise to 82.9% after using the multi-scale testing strategy.
Key words:computer vision; deep convolutional neural network; object detection; hierarchical parallel; feature pyramid network; multi-scale feature fusion
Considering the problem of small object detection, a neighborhood fusion-based hierarchical parallel feature pyramid network is proposed. This network extracts features with rich context information and local details by fusing the shallow features of similar scales, that is, the constructed feature pyramid network has no connection between the upper and lower layers. This network is integrated into the SSD framework to achieve object detection.
Object detection is an important computer vision task that uses image processing algorithms and models to detect instance objects of a specific class in digital images, providing fundamental information for further image understanding. Objects can appear anywhere in the image in a variety of shapes and sizes. Besides, detection is also affected by perspective, illumination conditions, and occlusion, making it a Gordian knot. Early object detectors are closely related to hand-engineered features that are applied to dense image meshes to locate objects in the sliding-window paradigm, such as the Viola-Jones (VJ) face detector[12], the histogram of oriented gradient (HOG) pedestrian detector[3], and deformable part models (DPMs)[4]. Recently, with the emergence of convolutional neural networks (CNN) and the rapid development of deep learning, object detection has also made great strides forward. Researchers have proposed many excellent object detectors, which can be roughly classified into the one-stage models and the two-stage models.
The two-stage model divides the detection tasks into two phases and has become the dominant paradigm of object detection. It generates a sparse set of candidate regions (ROI) first (via selective search[5]or region proposal network[6]), and then classifies these ROIs into a particular category and refines their bounding boxes. R-CNN[7]and SPPNet (spatial pyramid pooling convolutional network)[8]are classic works that implement this idea. After years of research, the superior performance of the two-stage detectors on several challenging datasets (e.g., PASCAL VOC[9]and COCO[10]) has been demonstrated by many methods[6,1116].
In contrast, the one-stage model can directly predict the category and location of objects simultaneously, thus abandoning the region proposal. Its straightforward structure grants it a one-stage model higher detection efficiency with a slight performance degradation exchange. SSD[17]and YOLO[18]achieve ultra-real-time detection with a tolerable performance, renewing interest in one-stage methods. Many extensions of these two models have been proposed[1925].
Current state-of-the-art object detectors have achieved excellent performance on several challenging benchmarks. However, there are still many conundrums in the field of object detection: 1) Feature fusion and reusing. Features rich in high-level semantic information is beneficial for object detection. Lin et al.[15,1920,26]obtained more characterized features through multiple feature fusion. 2) The trade-off between performance and speed. For the sake of practical applications, a delicate balance must be struck between performance and detection speed.
This paper rethinks the feature fusion and reusing while taking into account the inference speed. As an efficient feature extraction method, FPN[15]has been adopted by many state-of-the-art detectors[14,19,21,27]. Heuristically, this paper reconstructs the feature pyramid network in a hierarchical parallel manner (neighborhood fusion-based hierarchical parallel feature pyramid network), and then it is integrated into the SSD framework to verify its effectiveness. The main contributions are summarized as follows: 1) Proposing a simple and efficient method for constructing the context-rich feature pyramid network; 2) Integrating the hierarchical parallel feature pyramid network into the SSD framework and showing its performance improvement on standard object detection benchmarks compared with some FPN based models.
1 Feature Pyramid Network
Many experiments have confirmed that it is profitable to use multi-scale features for detection. For example, SSD[17]uses the multiple spatial resolution features of VGG nets[28]. These multi-scale features taken directly from the backbone network can be consolidated into a primary feature pyramid network, in which the top layer has rich semantic information but a lower resolution, while the bottom layer has less semantic information but a higher resolution. Fig.1 summarizes some typical feature pyramid networks. In this figure, the circle outline represents the feature map, its larger size represents higher resolution, and its darker color represents stronger semantic information. FPN[15]performs a top-down layer-by-layer fusion of the primary feature pyramid network with additional lateral connections for building high-level semantic features on all scales. On the basis of FPN, PANet (path aggregation network)[29]adds a bottom-up route to enhance its network structure, which is conducive to shortening the information propagation path while using low-level features to locate objects. NAS-FPN[30]can be regarded as the pioneering work of NAS application in object detection. It automatically learns the structure of the feature pyramid network by designing an appropriate search space, but it requires thousands of GPU hours during searching, and the resulting network is irregular and difficult to interpret or modify.

(a)
Fig.2 shows several similar methods for constructing the feature pyramid network based on the SSD framework. In this figure, the rectangular outline represents the feature map, its width represents the number of channels, and its height represents the resolution (i.e., 512×38×38). For brevity, some similar connections are omitted. DSSD[19]is inherited from SSD and FPN, building a more representative feature pyramid network by layer-by-layer fusing. In this case, low-resolution features are constantly up-sampled to mix with high-resolution features. RSSD (rainbow single shot detector)[20]constructs a feature pyramid network in a fully connected manner. That is, the feature map of each resolution in the feature pyramid network is obtained by fusing all inputs. In the structure of Fig.1(b), Fig.2(b) and Fig.2 (c), the input features inevitably undergo multiple consecutive resampling for constructing the feature pyramid network, which also causes some additional sampling noises and information loss.
In order to alleviate this potential contradiction, and take into account the training and inference speed, this paper manually limits the resampling times of the input features, ensuring that each feature map will undergo up-sampling and down-sampling at most once. The model structure is shown in Fig.1(d) and Fig.2(d), which only fuses shallow features on similar scales, abandoning multiple consecutive resampling used in DSSD and RSSD. Subsequent experimental results demonstrate the effectiveness of this approach. On the VOC 2007 test set, the NFPN-based SSD with 300×300 input size achieves 79.4% mAP at 34.6 frame/s, DSSD[19]with 321×321 input achieves 78.6 mAP at 9.5 frame/s, and RSSD[20]with 300×300 input achieves 78.5% mAP at 35.0 frame/s. After using the multi-scale testing strategy, the NFPN-based SSD can achieve 82.9% mAP.
2 Network Architecture
The neighborhood fusion-based hierarchical parallel feature pyramid network (NFPN) is shown in Fig.1(d) and Fig.2(d), introducing a neighborhood fusion-based hierarchical parallel architecture for constructing the context-rich feature pyramid network. The basic unit of NFPNis the multi-scale feature fusion module (MF module), which is used to aggregate multi-scale features. This section will introduce the MF module first, and then discuss how to integrate MF modules to construct NFPN and embed it into the SSD[17]framework.

(a)
2.1 MF module
In order to aggregate multi-scale features obtained from the backbone network, this paper introduces a simple multi-scale feature fusion module called the MF module, as shown in Fig.3. The MF module takes three different scale features as inputs (i.e., 4×, 2×, 1×) and resamples these features to the same resolution (2×) through the down-sampling branch (4×→2×) and the up-sampling branch (1×→2×). The subsequent 3×3 convolution layer is designed to refine features and limit noise caused by resampling. Instead of the element-wise operation used in FPN[15]and DSSD[19], the MF module adopts concatenation to combine multiple features, where the status of different features is characterized by the number of channels. The output channel of the basic branch (2× resolution) is set to be 256 to preserve more of its features, while the output channel of the down-sampling and up-sampling branches is set to be 128 to complement the context information. By convention, each convolutional layer is followed by a batch normalization (BN) layer and a ReLU(rectified linear unit) activation layer.
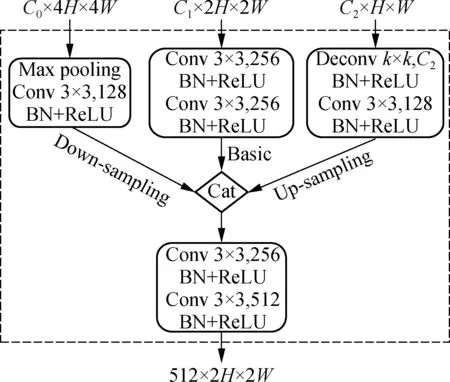
Fig.3 Multi-scale feature fusion module
2.2 Stacking of MF module
Referring to the structure shown in Fig.2(d), NFPN can be implemented by stacking MF modules in parallel among layers of the primary feature pyramid network. SSD[17]performs detection tasks using six scale features (denoted asC4,C5,…,C9, respectively) of the VGG-16[28]. Fu et al.[19]proposed the deconvolution module and prediction module to build a context-rich feature pyramid network in a layer-by-layer fusion manner, while Jeong et al.[20]proposed the rainbow concatenation similar to a fully connected network. These structures can be briefly formulated as
(1)
Pi=rainbow(C4,C5,…,C9)
(2)
where deconv and predict are the deconvolution module and prediction module in DSSD[19], respectively; rainbow is the rainbow concatenation in RSSD[20]. Finally, {Pi} combines into a context-rich pyramid network for multi-scale detection. Considering DSSD and RSSD, the input features of the feature pyramid network inevitably undergo multiple consecutive resampling, which can aggregate more contextual information, but introduce additional resampling noise.
To mitigate this contradiction, this paper manually limits the times of resampling that each input feature needs to perform, ensuring that each input can be up-sampled and down-sampled at most, once. This method is a hierarchical parallel stacking of the MF module and can be formulated as
Pi=MF(Ci-1,Ci,Ci+1)
(3)
where MF represents the MF module shown in Fig.3. Intuitively, NFPN reduces resampling times required for each input feature, and only fuses shallow features with similar resolution. Furthermore, the hierarchical parallel structure does not increase the depth of the computational graph as much as the layer-by-layer structure and is more in line with parallel computing.
This paper is based on the SSD framework to verify the performance of NFPN. In detail, the NFPN-based SSD additionally introduces “conv3_3” (C3in Fig.4) as the down-sampling branch ofP4and deletes the up-sampling branch ofP9while increasing the number of channels of its down-sampling branch from 128 to 256. In summary, the NFPN-based SSD contains six parallel stacked MF modules, as shown in Fig.4.

Fig.4 Stacking of MF module
3 Experiments
Experiments were conducted on three widely used object detection datasets: PASCAL VOC 2007, 2012[9], and MS COCO[10], which have 20, 20, and 80 categories, respectively. The results on the VOC 2012 test set and COCO test-dev set were obtained from the evaluation server. The experimental code is based on Caffe[31].
3.1 Training strategies
For the sake of fairness, almost all the training policies are consistent with SSD[17], including the ground-truth box matching strategy, training objective, anchor set, hard negative mining, and data augmentation. The model loss is a weighted sum between localization loss (Smooth L1) and classification loss (Softmax). NFPN takes seven scale features selected directly from the backbone network as inputs, whose resolutions are 752, 382, 192, 102, 52, 32, and 12, respectively. The convolution and deconvolution layers in NFPN do not use bias parameters, and their weights are initialized by a Gaussian function with a mean value of 0 and a standard deviation of 0.01. For the BatchNorm layer, the moving average fraction is set to be 0.999, while the weight and bias are initialized to be 1 and 0, respectively. All the models are trained with the SGD solver on 4 GTX 1080 GPUs, CUDA 9.0, and cuDNN v7 with Intel Xeon E5-2620v4@2.10 GHz. Considering the limitation of GPU memory, this paper uses VGG-16[28]as the backbone network with a batch size of 32, and only trains the model with input size 300×300.
3.2 Testing strategies
Inspired by RefineDet[25], this paper performed both single-scale testing and multi-scale testing. The spatial resolutions of the output features of MF moduleP4toP9are 382, 192, 102, 52, 32, and 12, respectively. To perform multi-scale testing,P8,P9, and their associated layers are directly removed from the trained model with no other modifications. This will shrink the mAP of the VOC 2007 test set from 79.4% to 75.5% when performing single-scale testing. Multi-scale testing works by imposing different resolution inputs to the model and aggregating all the detection results together, and then uses the NMS with a threshold of 0.45 to obtain the final result on PASCAL VOC dataset while using Soft-NMS on the COCO dataset. The default input resolution isSI∈{1762, 2402, 3042, 304×176, 304×432, 3682, 4322, 4962, 5602, 6242, 6882}. Additionally, the image horizontal flip operation is also used.
3.3 PASCAL VOC 2007
For the PASCAL VOC 2007 dataset, all the models are trained on the union of VOC 2007 and VOC 2012 trainval sets (16 551 images) and tested on the VOC 2007 test set (4 952 images). This paper adopts a fully convolutional VGG-16 net used in ParseNet[32]as the pre-trained model and fine-tunes it using SGD with a momentum of 0.9 and a weight decay of 2×10-4. The initial learning rate is set to be 0.001, then reduced by a factor of 10 at iterations 6×104and 105, respectively. The training cycle is 1.2×105iterations.
Tab.1 shows the results for each category on the VOC 2007 test set. Taking the GPU memory constraint into account, this paper only trains the model with input resolution 300×300 (i.e., NFPN-SSD300). Compared with some models based on the feature pyramid network with a similar input resolution (e.g., RSSD300, DSSD321, and FSSD300), the NFPN-based SSD without intricate tricks shows performance improvements in most categories, producing the increase of mAP of 0.9%, 0.8%, and 0.6%, respectively. Although its accuracy is inferior to some two-stage models, it guarantees real-time detection. After using the multi-scale testing strategy, the NFPN-based SSD can achieve 82.9% mAP, which is much better than single-scale testing (79.4% mAP).
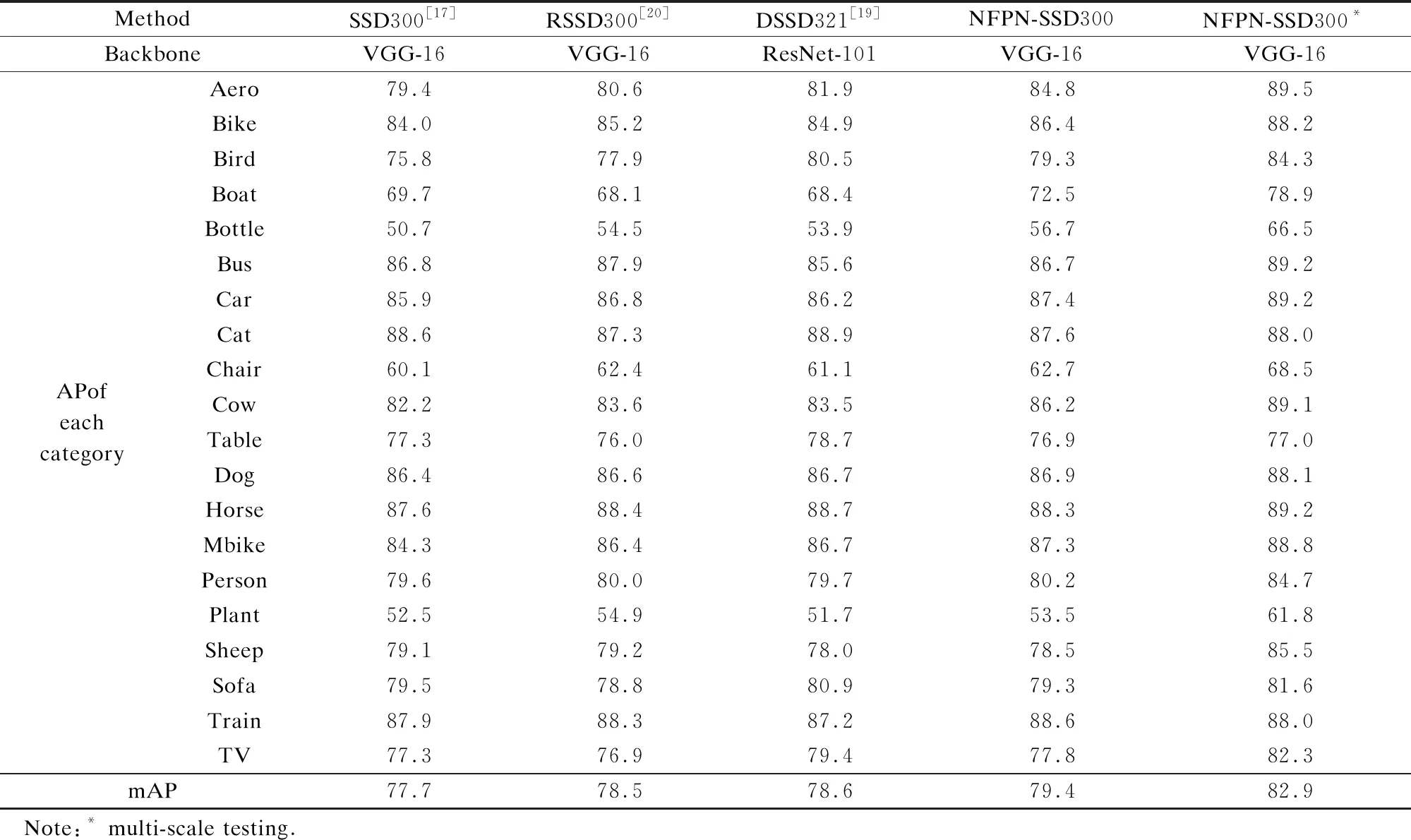
Tab.1 Detection results on the VOC 2007 test set %
Tab.2 shows the inference speed and average precision(AP) of some state-of-the-art methods. NFPN-SSD300 takes 28.9 ms to process an image (i.e., 34.6 frame/s and 79.4% mAP) with no batch processing on a GTX 1080 GPU, which exceeds DSSD321 in both inference speed and detection precision but is slightly inferior to RefineDet320. Compared with some methods with large input sizes, NFPN-SSD300 only retains the superiority of inference speed.
In summary,the NFPN-based SSD exhibits a significant improvement in inference speed and detection precision compared to the structure-oriented modified model RSSD[20]and DSSD[19]. Referring to Fig.5, with the SSD300 model as a baseline, the mAP of NFPN-SSD300 is increased by 2% to 6% for classes with specific backgrounds (e.g., airplane, boat, and cow), while increased by 6% for the bottle class, whose instances are usually small. It is proved that NFPN can extract more fertile contextual information, which is beneficial for the detection of small objects and classes with a unique context. Due to the transportability of this structure, it can also be easily embedded in other detectors to further boost their performance.
3.4 Ablation study on PASCAL VOC 2007
To demonstrate the effectiveness of the structure shown in Fig.2(d), this paper designs four variants and evalu-ates them on the PASCAL VOC 2007 dataset. The training strategies are inherited from Section 3.3. In particular, the batch size is set to be 12, which is the largest batch size that a single GTX 1080 GPU can accommodate. The basic module of NFPN is shown in Fig.3, which has three input branches, i.e., down-sampling, up-sampling, and the basic branch. By cutting out different branches, there are three variants: 1) down-sampling+basic; 2) basic+up-sampling; 3) down-sampling+basic+up-sampling. Furthermore, the fourth variant is a cascade of the feature pyramid network and can be formulated as
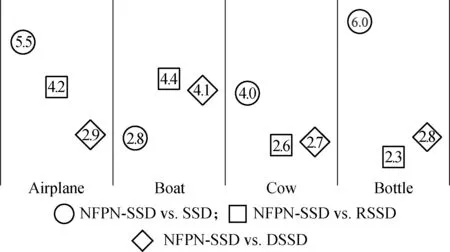
Fig.5 Comparison of improved average precision (%) of specific classes on VOC 2007 test set
(4)

Tab.2 Inference speed vs. detection accuracy on PASCAL VOC dataset
Tab.3 records the evaluation results. It is observed that the variant with three input branches shows better detection performance than those variants with two input branches (mAP 78.6% vs. 78.1% and 78.2%). The cascading of feature pyramid networks can also contribute to the detection performance (i.e., 0.5% higher), but the corresponding memory consumption will also increase. Accordingly, this paper selects the variant model with three input branches in other experiments. Attempts have also been made to integrate the FPN structure into the SSD framework, but it cannot converge to a matching detection performance.
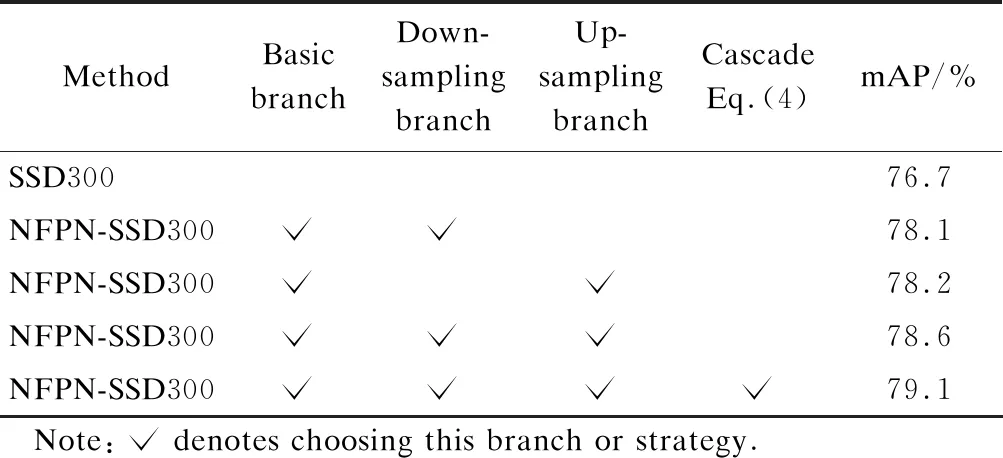
Tab.3 Ablation study on the VOC 2007 test set
3.5 PASCAL VOC 2012
For PASCAL VOC 2012 dataset, all the models are trained on the union of VOC 2007 and VOC 2012 trainval sets plus VOC 2007 test set (21 503 images) and tested on the VOC 2012 test set (10 991 images). The training set is an augmentation of the training set used in Section 3.3, attaching about 5 000 images. Therefore, the NFPN-based SSD model that iterates 6×104times in Section 3.3 is used as a pre-trained model to shorten the training cycle. Other training strategies are consistent with those discussed in Section 3.3. The evaluation results are recorded in Tab.2 and Tab.4. Considering similar input sizes (i.e., 3002, 3212), the NFPN-based SSD still shows performance improvement compared with SSD, RSSD, and DSSD. After using the multi-scale testing strategy, the mAP of NFPN-SSD300 can also catch up with RefineDet320.
3.6 MS COCO
MS COCO[10]is a large-scale object detection, segmentation, and captioning dataset. For the object detection task, COCO train, validation, and test sets contain more than 2×105images and 80 object categories. Object detection performance metrics include AP and average recall(AR).

Tab.4 Detection results on the VOC 2012 test set %
By convention[35], this paper uses a union of 8×104images from the COCO train set and random 3.5×104images from the COCO validation set for training (the trainval35k split), and uses the test-dev evaluation server to evaluate the results. The pre-trained model and optimizer setting are the same as Section 3.3, while the training cycle is set to be 4×105iterations. The initial learning rate is 10-3, then decays to 10-4and 10-5at 2.8×105iterations and 3.6×105iterations, respectively. The experimental results are shown in Tab.5, and some qualitative test results are shown in Fig.8 and Fig.9.
Similarly, to verify the validity of the feature pyramid network constructed in the NFPN-based SSD, the detec-tion results are first compared with DSSD, which integrates FPN and ResNet-101 into the SSD framework with no other tricks. As can be seen from Fig.6, the NFPN-based SSD has been improved in various detection evaluation metrics (e.g., AP and AR) compared with SSD. Additionally, compared with DSSD, the NFPN-based SSD is only inferior in the detection of large objects. That is, the NFPN-based SSD has more performance improvements for small objects. Fig.7 visualizes the first 8 channels of the feature map used to detect small objects. For some images that only contain small instances, the feature map in SSD300 used for detection only has few activated neurons, which makes it difficult to locate objects. The combination of NFPN and SSD gives the model a stronger feature extraction capability so that the feature map used for detection can retain more useful information, as shown in the fourth row of Fig.7. Comparing the feature maps in DSSD and NFPN-SSD, it is not difficult to find that NFPN-SSD can extract more detailed information, which is especially beneficial for the detection of small objects.

Fig.6 Comparison of improved AP (%) and AR (%) on MS COCO test-dev set
Considering additional FPN-based detectors (e.g., RetinaNet400, NAS-FPN),the NFPN-based SSD is still inferior in detection accuracy, but it is superior in inference speed (34.6 vs. 15.6 and 17.8 frame/s). Due to the portability of NFPN, it can also complement these methods to further improve their performance.

Tab.5 Detection results on MS COCO test-dev set

(a)

(a)
4 Conclusions
1) The hierarchical parallel structure of NFPN eliminates the successive resampling of features and does not increase the depth of the computational graph as much as the layer-by-layer structure. Additionally, the gradient can be passed back to the shallow layer along a shorter path, which is beneficial to the optimization of the model.
2) The hierarchical parallel feature pyramid network is more conducive to the parallel acceleration of GPU.
3) NFPN is highly portable and can be embedded in many methods to further boost their performance. It is demonstrated to be effective by integrating NFPN into the SSD framework, and extensive experimental results show that NFPN is more proficient for detecting small objects and classes with specific backgrounds.

(a)
杂志排行

Journal of Southeast University(English Edition)的其它文章
- Hub location of air cargo company in air alliance
- Throughput optimization for multi-channel cooperative CR under reporting channel errors
- Modeling the special intersections for enhanced digital map
- Numerical investigation of liquid sloshing in FLNG membrane tanks with various bottom slopes
- Effects of admixture on properties of recycled aggregate mortar
- Investigation of the environmental impacts of steel deck pavement based on life cycle assessment