基于遗传算法的冶炼厂烟尘排放污染源识别研究
2020-10-10
(南昌师范学院,江西 南昌 330032)
近几年,我国冶炼厂逐渐增多,由于冶炼技术的不成熟,导致冶炼过程中会产生大量的烟尘排放污染物,对周边环境造成了极其严重的影响,因此对冶炼厂烟尘排放污染源识别方法进行研究对治理环境污染至关重要。
空气污染程度的增加,雾霾频繁发生,大气污染问题逐渐严重,并受到了人们的重视。大气环境中,烟尘排放污染物主要以悬浮颗粒物存在[1]。一般情况下,将粒径小于100μm的烟尘排放污染物称为总悬浮颗粒;将粒径小于10μm的烟尘排放污染物称为可吸入颗粒物,其还可以细分为细颗粒(粒径尺寸小于2.5μm)与粗颗粒(粒径尺寸范围为2.5μm~10μm)。为了治理冶炼厂烟尘排放污染情况,提出基于遗传算法的冶炼厂烟尘排放污染源识别方法研究。遗传算法通过数学方式,利用计算机仿真运算,将问题求解过程转换为基因交叉、变异等过程,具备运算速度快、求解精度高等优势,目前被多个领域应用,具有极好的应用前景。将遗传算法应用到冶炼厂烟尘排放污染源识别方法过程中,希望可以提升冶炼厂烟尘排放污染源识别方法的性能。
1 冶炼厂烟尘排放污染源识别方法研究
(1)烟尘排放污染物分布趋势分析。研究将特殊标识元素记为重金属A,分析其分布趋势,为冶炼厂烟尘排放污染源识别做准备。此研究过程中,假设冶炼厂以冶炼重金属A为主,可以通过跟踪其烟尘排放中重金属A的含量识别出污染源。常规情况下,冶炼厂烟尘排放方向随着风向而变化,而风向随着季节呈现周期性变化,从而冶炼厂烟尘排放方向也随着季节呈现一定周期性的旋转。

表1 冶炼厂烟尘排放污染源分布数据表
上述过程完成了冶炼厂烟尘排放污染物分布趋势的分析,为下述烟尘排放污染物分布方程的建立提供数据支撑。
(2)烟尘排放污染物分布方程建立。在大气污染事故治理过程中,大气资料以及周围环境信息不是十分充足,故对一维对流扩散方程进行一定程度的简化,具体简化步骤如下所示:步骤一:将大气污染事故简化为一定区域内(πl2)的烟尘扩散过程,并设定烟尘扩散速度均匀不变,同时大气介质保持均匀;步骤二:假设大气初始环境以及区域边缘的烟尘排放污染物浓度近似为零;步骤三:烟尘排放污染物在大气环境中沿扩散方向均匀混合,并存在着一定的衰减现象。
依据上述简化步骤,得到多源烟尘排放污染物进入大气环境后的浓度分布偏微分方程为

式(1)中,C表示的是引起大气环境污染的烟尘排放污染物浓度;t表示的是时间;u表示的是烟尘排放污染物扩散速度;x表示的是沿风向方向的位置坐标;Ex表示的是烟尘排放污染物扩散系数;K表示的是综合衰减系数;q表示的是烟尘排放污染源总数量;Mi表示的是突发大气污染事故污染物质总量;δ表示的是狄拉克函数;xi表示的是烟尘排放污染源坐标。
常规情况下,已知烟尘排放污染源位置xi以及污染物质总量Mi,来求解烟尘排放污染物浓度分布情况C(x,t),此属于冶炼厂烟尘排放污染事故模拟预测的“正问题”,而此研究是通过某些测点的烟尘排放污染物浓度值,识别烟尘排放污染源,此属于“反问题”。在“反问题”求解问题较为复杂,需要利用“正问题”构建“反问题”的优化目标函数,以此为基础,求解公式(1)的偏微分方程,得到公式(1)的解为:

(3)烟尘排放污染源识别模型。基于遗传算法的烟尘排放污染源识别步骤如下所示:
步骤一:设置遗传算法参数,主要包含基因取值范围、个体基因个数Ng、种群中个体总数Im、交叉概率Pc、变异概率Pm以及最大迭代次数Tm。其中,交叉概率、变异概率与种群个体总数需要根据实际情况进行具体的设置;

步骤三:初始种群生成,表达式为

式(3)中,ranf是产生区间范围[0,1]内随机数的函数公式;
步骤四:构建适应度函数。遗传算法只能使个体向着适应度值提升方向变化,而公式(3)表示优化变量需要向适应度值减少方向变化,故修正适应度函数,得到适应度函数表达式为:
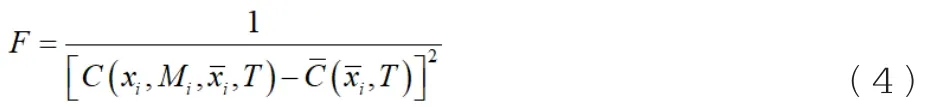
步骤五:遗传优化搜索。对步骤三生成的初始种群应用选择算子、交叉算子与变异算子进行操作运算,当迭代次数达到设置的最大迭代次数时,遗传算法终止。
2 仿真实验与结果分析
采用MATLAB软件设计仿真实验,具体实验过程如下所示。
(1)实验参数设置。为了保障仿真实验的顺利进行,设计仿真实验参数,指的是实验工况参数设置,具体数值如表2所示。

表2 实验工况参数设置表

如表2所示,以种群规模为划分变量,将实验划分为10中工况,依据上述参量进行仿真实验,验证提出方法的识别性能。
(2)实验结果分析。仿真实验通过烟尘排放污染源识别误差以及收敛代数反映方法的性能,具体实验结果分析过程如下。实验设定烟尘排放污染源位置为排放方向的0.5m处,通过仿真实验得到烟尘排放污染源识别误差数据如表3所示。

表3 烟尘排放污染源识别误差数据表
如表3数据显示,提出方法的烟尘排放污染源识别误差范围为-10.00%~10.00%,满足现今烟尘排放污染源识别需求。
现今,收敛代数标准数值为40,通过仿真实验得到收敛代数数据如图1所示。

图1 收敛代数数据图
如图2数据显示,提出方法收敛代数均低于标准数值,平均值为24.6。
上述实验结果显示:提出方法的烟尘排放污染源识别误差范围为-10.00%~10.00%,收敛代数平均值为24.6,低于标准数值,满足现今烟尘排放污染源识别需求,充分说明提出方法具备较好的识别性能。
3 结束语
此研究将遗传算法应用到冶炼厂烟尘排放污染源识别过程中,极大的提升了污染源识别的性能,为冶炼厂的发展与烟尘排放的治理提供精确的数据支撑。
