大数据背景下审计数据采集技术与方法的研究
2020-10-09徐超
【摘 要】 审计数据的采集是进行大数据审计的基础,审计数据采集质量直接关系到审计结果,因此,在大数据背景下进行审计数据采集技术与方法的研究尤为重要。文章以网络爬虫技术为核心进行审计大数据采集技术与方法的探索研究,形成了审计数据采集框架,该框架能够根据具体的审计需求,自动采集和預处理相关的审计公开数据,从而有效补充审计内部数据不足、质量不高等问题,力求快速发现审计问题,提高大数据审计效率。同时,以互联网金融企业专项审计为例,验证审计数据采集框架的必要性和有效性,研究成果为大数据审计提供了一个可供借鉴的研究方法。
【关键词】 审计大数据; 数据采集; 网络爬虫技术
【中图分类号】 TP391;F239 【文献标识码】 A 【文章编号】 1004-5937(2020)19-0114-06
一、引言
大数据的运用给人类社会各行各业带来深刻影响和巨大变化,以大数据技术为代表的信息化、智能化建设,正有力地推动着国家治理能力走向更高水平。审计是党和国家监督体系的重要组成部分,是国家治理的基石,审计行业的使命促进国家良治和全球良知及全球可持续发展。为迎接大数据时代,大力推进大数据审计,已成为我们必然的发展方向和现实选择。
习近平总书记在中央审计委员会第一次会议上指出:“深化审计制度改革,解放思想、与时俱进,创新审计理念,及时揭示和反映经济社会各领域的新情况、新问题、新趋势。要坚持科技强审,加强审计信息化建设。”目前,国家审计署“金审工程三期”正是以大数据审计为核心,开展国家重大工程项目建设,在大数据审计模式下,通过构建全维化数据画像,开展财政、金融与企业间,财务与业务数据间,中央、部门与地方间,部门纵向各级间,单个系统和单个被审计对象与宏观经济运行间的上下、左右、各种关联分析,力图全面、立体、系统地认识被审计对象,以全维视角、智能化技术,实现总体分析,试图建立“国家审计云”。可以说,应用大数据技术是实现审计全覆盖目标的必由之路,大数据审计建设是影响审计事业未来发展的核心技术工程。新时代信息技术下审计技术与方法的研究已经成为当下以及今后一段时期亟需研究的重大课题。
综上所述,本文以网络爬虫技术为核心进行审计大数据采集技术与方法的探索,形成审计数据采集框架。该框架能够根据具体的审计需求,自动采集和预处理相关的审计公开数据,增加审计数据采集质量与完整性,力求快速发现审计问题,提高大数据审计效率。
二、文献回顾
审计大数据采集技术不但完成对大量数据的自动采集,而且能对采集的数据进行各种预处理,也就是数据的ETL(Extract-Transform-Load),为挖掘数据的潜在价值做准备,为用户构建解决方案或者实现决策提供支持。审计大数据采集是审计大数据分析生命周期的重要一环,是实现高效可靠审计的基础,不少学者从数据采集方式方法以及数据采集系统的安全性等方面已经开展了相关研究。在国内,徐超和吴平平[ 1 ]指出,大数据审计工作应该是“三个集成、五个关联”,也就是在审计的时候要将数据、分析和审计工作三方面综合起来进行,而数据作为第一个要素,需要建立有效的采集机制,规范其采集格式及要素。陈琦和陈伟[ 2 ]设计了一种多源的审计数据采集方法,可以对多种不同格式的数据进行集中采集。赵华和闵志刚[ 3 ]基于Oracle数据库,完成了一套高效的数据采集和转换系统,能够有效地提升审计人员的工作效率。张立[ 4 ]和王志之[ 5 ]阐述了如何对采集的审计数据进行预处理,以提高数据质量,更好地为审计服务。卢学英[ 6 ]从数据采集和预处理的四个方面,对如何保证审计数据采集的完整性进行了探讨。赖春林[ 7 ]针对医保基金审计采集的数据如何处理进行了深入分析,给出了一些可能的应用方式。张志恒和成雪娇[ 8 ]以采集的文本数据为出发点,设计了一个审计数据分析框架,重点阐述了如何对采集的文本数据进行预处理并加以利用。在国外,Samtani等[ 9 ]发现数据采集系统并不是绝对安全的,他们基于Shodan搜索引擎,对数据采集设备的安全漏洞进行了评估,识别了大量SCADA数据采集设备的安全漏洞。Colombo 等[ 10 ]针对欧洲核子研究中心ATLAS探测器数据采集系统遇到的数据传输延迟问题,设计了相应的数据采集仿真工具,用以分析不同的流量和调度策略,以及网络硬件情况下的系统行为,为未来改进数据采集系统提供支持。Lee等[ 11 ]使用一个安全的数据采集和签名模块生成用于流数据完整性检查的元数据,然后借助元数据校验远程数据采集的完整性和有效性。
综上可以看出,在大数据审计采集方面主要是运用高效快速的采集技术以及采集质量、采集数据标准化等的研究;而对审计大数据采集的完整性、真实性、有效性研究较少,尤其与被审计单位相关联外部数据采集研究较少。因此,本文主要集中于对被审计单位相关联的外部数据采集的研究,提出利用网络爬虫技术采集与审计对象相关的外部数据,从而对内部数据进行有力补充,力图使审计大数据采集更加完整和真实有效。
三、网络爬虫技术
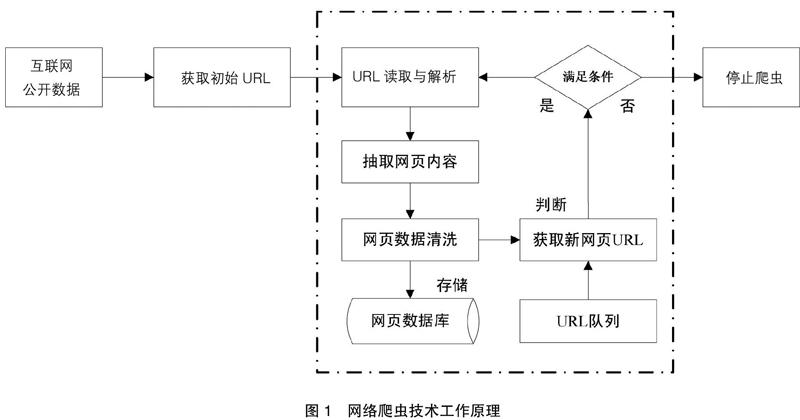
网络爬虫技术是一种基于互联网,自动抓取网页特定的一种技术。它的实现机制类似于人对网页的点击操作,可以在非人工干预下完成客户端(浏览器)和服务器之间的交互,实现对网络数据自动、精准、大范围的提取。根据爬取任务的不同,网络爬虫可分为通用型、聚焦型、优先型、增量型、深层型等多种类型,同时,用户还可以根据实际需求构建自定义网络爬虫。
使用网络爬虫,用户首先要根据自己的需求选择一个或几个目标网站作为网络爬虫的初始URL,并加入到待抓取URL队列中。然后网络爬虫将自动进行以下循环操作:(1)如果待抓取URL队列为空,则终止循环,停止网络爬虫,输出爬取的结果(即网页数据库中的内容);否则,从待抓取队列中取出队首的URL地址,然后在互联网中进行查找,找到它相对应的网页,并把它下载下来。(2)对下载的网页进行数据提取。提取的数据包括URL地址以及感兴趣的内容两个方面。对于提取的URL地址,如果这个URL地址以前没有分析过,那么就将这个URL地址加入到待抓取URL队列中;对于提取的内容,则经过数据清洗,保存到网页数据库中,作为爬虫的结果供后续分析。基本流程如图1所示。
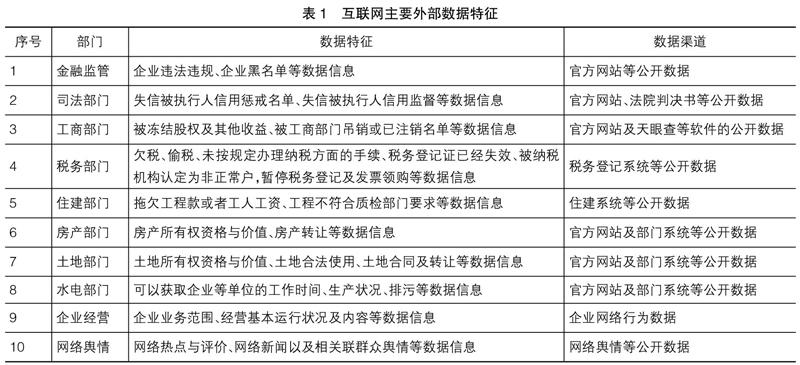
网络爬虫技术在审计领域中的应用,例如商业银行进行小微企业贷款审计,数据采集难一直是审计部门十分困扰的问题。小微企业客户贷款信息的真实一般由自己报送,客户资源的真实性、完整性、有效性亟需验证。审计部门对材料真实审查往往无从下手,通常会面临企业客户的财务信息、非财务信息搜索整合困难,尤其是小微企業的财务信息难以核实、难以识别客户资料信息造假以及来自银行内部工作人员“伪造”信息等一系列问题。网络爬虫技术作为大数据前端的数据采集技术,可以很好地解决这一系列问题。利用网络爬虫技术,配合图像识别、语音识别、语义理解等大数据技术,可以实现海量的外部高价值数据收集,包括如表1所示的政府公开数据、企业官网数据、社交数据、新闻舆情数据等。审计部门得以通过客户动态数据的获取,为客户建立“全景画像”,对客户的实际业务、运行情况以及报送材料的一致性进行全方位、细粒度的实时审查,从而使得商业银行审计部门在审计范围、时效性、前瞻性等方面得到有效改善。
四、基于网络爬虫技术的审计大数据采集框架
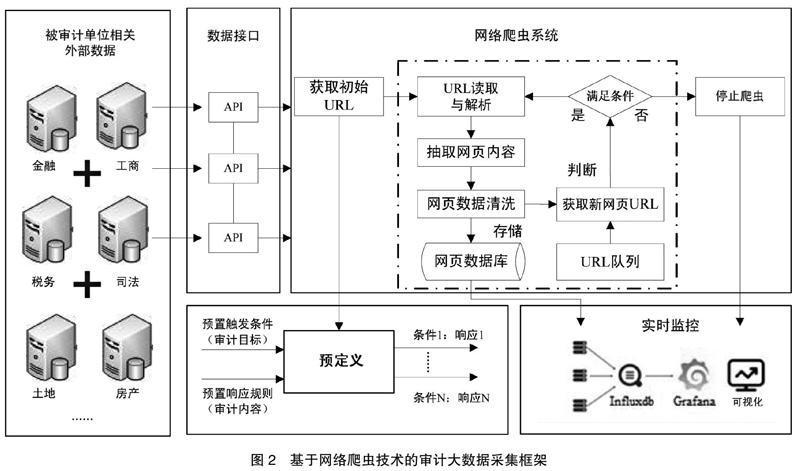
网络爬虫技术下的审计大数据采集框架,需要支持不同部门、不同平台的数据采集,其采集的对象千差万别,而且内容和形式也是多样的,如果采用单一类型的网络爬虫,将难以满足如此灵活的需求,因此本文将通用型爬虫和深层网络爬虫两类技术相结合,首先基于通用型爬虫,对基本的、通用的审计数据进行抓取,其次基于深层网络爬虫,对某些重点方面和特殊需求进行深度分析,以进一步爬取针对性更强的数据。采集框架如图2所示,主要包括审计采集数据预定义、网络爬虫系统、审计采集数据实时监控,具体如下:
(一)审计采集数据预定义
在进行网络爬虫技术下的审计大数据采集前,需要对采集数据预先定义,以确定采集数据的范围和数据精准有效,具体根据审计计划,围绕审计目标,针对具体审计业务内容进行预定义,使得数据采集的来源可靠有效,采集的内容准确高效。
(1)预定义采集需求。针对不同审计目标,用户创建主题,选择可靠数据来源,构建数据爬取的约束条件和触发条件,预定义审计采集标准、需求及内容,选择的数据目标应能实现审计项目方案。在进行采集数据前,首先应在对被审计单位信息系统充分了解的基础上进行外部数据选择,其次需要根据具体审计业务内容来采集所需的审计大数据。
(2)选择审计数据来源。确定审计目标后,应在对被审计单位业务流程及关键控制点充分了解的基础上进行数据来源选择,需要寻找能够完成审计项目方案的可靠数据来源网站或App软件系统进行数据采集。例如,固定资产审计,采集的可靠审计数据来源包括企业官方网站的数据、供应链数据、政府及各部门发布的各类相关数据,如征信数据、司法数据、海关数据、税务数据、工商数据以及网络舆情等相关外部数据。
(二)网络爬虫系统
网络爬虫技术下审计大数据的采集,主要采用链接结构评价的爬行策略,以审计目标预先定义的主题为需求,选择性地爬行与审计对象主题内容相关的页面。但是,互联网数据不是孤立的,爬取的页面之间总存在各种联系,因此,本文基于链接结构的搜索策略模式,利用网页之间的结构特征,根据审计目标构建页面重要性评价方法,以优化爬虫搜索顺序,提高爬虫质量。
网络爬虫策略基于PageRank算法来进行审计大数据的采集。如果一个网页多次被审计对象相关主题预定义或者引用,则可能是很重要的网页,与爬取审计目标密切相关;如果一个网页没有被多次引用,但还是被重要审计主题预定义或者引用,则该网页也有可能是重要的网页。因此,基于这两个基本假设,对每个网页的重要性进行审计大数据采集,具体步骤如算法1所示。
算法1:网络爬虫算法(审计大数据采集)
Intput: 相关审计需求URL
Output: 与之相关各字段采集信息
Step1 审计目标预定义,生成任务模块,根据种子任务获取数据爬取URL,同时,生成待下载任务。
Step2 根据待下载任务,围绕预定义的审计内容进行爬取,如果选择数据源对应的爬虫URL在任务里面不存在时,就会新插入一个任务,并把这个任务ID取出来保存到主题任务表中。
Step3 URL解析与读取,利用正则表达式提取出设定的目标数据,对已经爬取的网页,连同待爬取URL队列中的URL形成网页集合,同时把任务ID和主题ID放在这个URL的后面,在保存数据时会把任务ID保存到全量数据表中。
Step4 对网页集合进行排序去重,计算每个页面的PageRank值,计算完成之后,将待爬取URL队列中的URL按照PageRank值的大小优先级排列,同时对其进行过滤去重,按照该顺序爬取页面,并判断是否继续爬取种子任务。
Step5 种子任务迭代模块,从种子任务队列取出待下载的种子任务生成待下载任务。
Step6 进入循环,转Step2。
Step7 数据约束条件判断,爬取数据保存到全量数据表中就会调用服务端提供的API,并且带上任务ID和主题ID信息,服务端的API会根据这个任务ID和主题ID去全量数据表和主题任务表中获取对应的数据和约束条件。
Step8 根据全量数据表的数据和主题任务表约束条件填充对应的数据到审计业务表里面推送给满足条件的审计用户。
(三)审计采集数据实时监控
在利用网络爬虫技术进行审计大数据采集过程中,会出现爬虫程序异常、自动终止、实时性差、出现错误位置不明确、修复爬虫时间长等问题,因此,对爬虫爬取的数据需要进行实时监控,以确保整个审计大数据采集过程的顺利进行。本文将根据审计目标爬取的审计大数据用时序数据库(Influxdb)进行技术处理,而后利用可视化工具(Grafana)将爬虫数据情况通过可视化图形界面展示出来,这样能够对网络爬虫系统以及采集到的数据实时监测,发现异常及时处理,从而保障了整个网络爬虫数据采集框架的有序运行。时序数据库(Influxdb)是一款开源的时间序列数据库,专门用来存储和时间相关的数据,例如用它存储某个时间点爬虫抓取信息的数量。可视化工具(Grafana)是一个跨平台、开源的度量分析工具,也是一个实时监控系统,拥有精美的网络产品界面(web UI),支持多种图表,可以展示时序数据库(Influxdb)中存储的数据,并且有报警的功能。
五、互联网金融审计具体应用
(一)审计背景
互联网金融是一种更加普惠的大众化金融模式,在网络上实现支付结算、货币借贷、销售金融产品等,能够提高金融服务效率,降低金融服务成本,这是互联网技术与现代金融有机结合的产物,给金融市场带来了新的活力和发展机遇。互联网金融的主要特点是便捷隐蔽、成本低廉、风险多维性等,对其监管和审计比传统金融更加复杂,审计部门如何对互联网金融开展审计监督成为一个新的命题。
根据审计计划,对某市200多家互联网金融企业进行一次重点专项审计,审计目标是以互联网金融企业为背景,审计某市互联网金融企业在运营过程中是否存在违规、违法现象。主要从四个方面进行关注,即网络非法集资、非法经营或者虚假交易、网络产品的兑付风险、互联网金融信息安全。传统审计主要对互联网金融企业申报信息进行真实性审计,对财务预算、收入、支出等进行合规性审计,同时,与相关人员座谈走访、对互联网金融企业相关金融产品及合同进行抽样检阅等。实践表明,仅仅依靠被审计单位提供的数据进行审计,已经无法满足审计需要。不少审计人员觉得“对会计资料进行逐一审查,未发现有明显的违纪违法现象”,“整本账目上数字工整清晰,毫无违法违规现象”[ 12 ]。因此,在大数据背景下利用网络爬虫技术获取公开外部数据信息尤为重要,是对审计大数据采集完整性、真实性、有效性的极大补充,是快速发现审计问题与线索的关键,是审计报告的重要依据。
(二)审计大数据采集
审计数据采集预定义。根据审计目标,针对某市互联网金融企业的特点以及相关业务内容进行审计数据采集预定义,选择可靠审计数据来源进行审计大数据采集,形成如图3所示的企业基础数据、企业征信数据、企业关联/投资数据、企业历史违约数据以及企业网络舆情数据。
网络爬虫系统。通过以上审计数据采集预定义,审计人员利用网络爬虫技术从公开信息网络中爬取对应互联网金融企业的数据信息,具体使用如图4所示的Python语言编写爬虫代码。
(1)根据预先定义采集数据需求。以互联网金融企业名称为索引,确立数据来源网站。利用网络爬虫技术爬取企业基础数据以及相关信息,如国家企业征信系统、司法系统、天眼查、企查查、启信宝等,重点对工商数据、商标数据、公开诉讼数据、舆情数据以及企业关系的深度挖掘与爬取。
(2)构造种子URL初始化爬虫。利用已有互联网金融企业的名称数据,根据各网站的URL特点构造初始化爬虫的URL。
(3)获取网页源文档。利用Python语言的requests、urllib2等库解析种子URL获得网页源文档。
(4)解析网页源文档。使用Python的pyquery、BeautifulSoup、xpath等库或正则表达式解析网页的源文档,获得需要的文本内容存入数据库,或抽取需要的URL放入待爬取URL队列再进入循环爬取。
(5)数据预处理与存储。对采集的审计数据进行预处理,使得数据满足审计需求,并使用Pymongo存储到MongoDB数据库。
审计数据采集实时监控。对网络爬虫等采集系统采集到的数据进行實时监控,避免出现爬虫程序异常自动终止,实时性差,错误位置不明确修复爬虫时间长等问题,用时序数据库(Influxdb)进行技术处理,而后通过可视化工具(Grafana)将爬虫数据情况通过可视化图形化界面展示出来,如图5所示。
(三)审计采集结果分析
利用网络爬虫技术的审计大数据采集框架,获取互联网金融企业基础数据、企业征信数据、企业关联/投资数据、企业历史违约数据以及企业网络舆情数据等外部数据,补充对互联网金融企业专项审计项目工作,使审计采集数据更加完整,从而对某市的互联网金融企业审计数据分析更加准确、真实。在对公开获取的外部数据进行整合清洗之后,审计发现能够迅速判断互联网金融企业是否存在伪造经营状态信息、企业股东之间是否存在关联关系、企业是否存在信用问题。同时,在研判网络非法集资、非法经营或者虚假交易、网络产品的兑付风险、互联网金融信息安全等方面发挥重要作用。
六、总结与展望
随着大数据时代的到来,未来审计必将从目前的发现问题逐渐发展为预测问题、预防问题,而这一系列的发展必将基于大量高质量数据的获取和积累。因此,本文以目前广泛使用的数据采集技术——网络爬虫技术为基础,探讨了审计领域大数据采集的方式方法,设计了审计数据采集框架,能够针对不同的具体审计需求自动采集和预处理相关的审计公开数据,有效地补充审计内部数据不足。同时,为提升采集的数据质量,本文开发了混合网络爬虫技术,该技术能够结合通用爬虫和深层爬虫,大幅提升网络爬虫获取审计数据的有效性和质量,为大数据审计奠定了坚实的数据基础。
【参考文献】
[1] 徐超,吴平平.浅析各国大数据审计工作现状:基于世界审计组织大数据工作组第一次会议的研讨结果[EB/OL]. http://www.audit.gov.cn / n6 / n41 /c96373 / content.html,2017-06-01.
[2] 陈琦,陈伟.一种基于C#的审计数据采集方法的设计与实现[J].中国管理信息化,2015(17):37-39.
[3] 赵华,闵志刚.Oracle审计数据的采集与转换[J].审计与理财,2015(3):17-18.
[4] 张立.ETL技术在数据审计中的具体应用[J].中国审计,2015(24):52-53.
[5] 王志之.审计数据预处理探析[J].中国经贸,2017(16):260-261.
[6] 卢学英.计算机审计中如何获取真实完整的电子数据[J].价值工程,2017,36(20):205-206.
[7] 赖春林.如何有效利用审计采集的数据?——以医保基金审计为例[J].审计与理财,2016(11):17-18.
[8] 张志恒,成雪娇.大数据环境下基于文本挖掘的审计数据分析框架[J].会计之友,2017(16):117-120.
[9] SAMTANI S, YU S, ZHU H, et al. Identifying supervisory control and data acquisition (SCADA) devices and their vulnerabilities on the internet of things (IoT):a text mining approach[J].IEEE Intelligent Systems,2018,33(2):63-73.
[10] COLOMBO T, FRONING H, GARCIA P J,et al. Optimizing the data-collection time of a large-scale data-acquisition system through a simulation framework[J]. Journal of Supercomputing,2016,72(12):4546-4572.
[11] LEE K M, LEE K M, SANG H L. Remote data integrity check for remotely acquired and stored stream data[J]. Journal of Supercomputing,2018,74(9):1182-1201.
[12] 许伟,雷玥.狼狈为奸终现形[J].中国审计,2013(24):29-30.
