多特征融合的可移植谣言早期检测模型
2020-10-09孙王斌


摘要:针对当前诸多网络平台的谣言泛滥现象,提出结合长短期记忆(Long-short Term Memory,LSTM)网络与支持向量机(Support Vector Machine,SVM)的可移植谣言早期检测模型。将谣言文本转换为向量序列,通过LSTM网络挖掘谣言文本的深层特征,并引入有效度、敏感度与热度特征.通过SVM融合训练拟合表明,该模型在多平台数据集上表现出良好的预测结果。
关键词:谣言检测;可移植;LSTM; SVM
中图分类号:TP391.1
文献标识码:A
文章编号:1006-8228(2020)09-11-06
Rumor early detection model with multi-feature merged and portability
Sun Wanebin
(Central South University, School of Cornputer Science and Engineering, Changsha, Hunan 410012. China)
Abstract: In view of the phenomenon of rumor overspreading among many platforms, a portable rumor early detection model withthe combination of Long-short Term Memory (LSTM) network and Support Vector Machine (SVM) is proposed. Vector sequencesconverted from rumor corpus are fed into LSTM network to mine the hidden text feature. Effectiveness, sensitivity and heatfeatures of rumor corpus are introduced and merged by SVM training. The experimental results show that the model performs wellin multi-platform dataset.
Key words: rumor detection; portable; LSTM; SVM
0引言
随着社会经济、文化的快速发展,截止到2018年底,我国互联网普及率达59.6%,网民规模达到8.29億。互联网技术的进步,极大增强了网络信息的流动性和扩散性[1]。网络信息质量参差不齐及监管机制的缺乏,导致网络谣言肆意传播。谣言泛滥致使人们难以甄别信息可信程度,对人们的正常生活秩序造成影响,甚至引起经济损失及社会动荡。近年来,各大新闻网站及社交平台积极推出官方辟谣平台,如新浪微博辟谣平台或中国互联网联合辟谣平台(以下简称联合辟谣平台)。然而,上述平台需要大量专业人士花费大量时间验证,并且平台资源差异大、谣言重复率高,更加重了验证负担。因此如何在各平台谣言传播初期进行通用有效的自动检测,对于辅助人工验证、降低谣言危害和维护社会稳定具有重要意义。
1相关研究
目前谣言检测主要为二分类问题,即1代表谣言,0代表非谣言。该问题最先由Yahoo实验室研究员Castillo[2]通过对Twitter上的tweet进行整理后于2011年提出,并提出基于用户特征、传播特征和用户特征的决策树分类模型,以此判断事件的真实性。2012年,Yang等人[3]首次基于新浪微博平台进行谣言检测,引入了用户终端类型和用户位置两个新的统计特征,并通过对真实微博数据集的测试证明了上述新特征的有效性。2016年,毛二松等人[4]提出了一种基于深层特征和继承分类器的微博谣言检测方法,利用微博情感倾向、微博传播过程及微博用户历史信息等深层分类特征对集成分类器进行训练,有效提高了微博辟谣性能。2019年,王志宏[5]、过戈提出将事件流行度、模糊度和流传度作为微博谣言事件检测分类器的三项新特征,使谣言事件自动检测效果得到了可观提升。
近年来,深度神经网络在文本分类、图像处理等方面表现优异,自然语言处理(Natural LanguageProcessing,NLP)领域也越趋成熟。2016年,Ma等人[6]首次提出使用循环神经网络(Recurrent NeuralNetwork,RNN)学习微博谣言中的深层特征,捕获相关微博的上下文信息随时间的变化,在真实微博数据集上的测试表明,该方法的准确率较传统检测方法而言取得进一步提高。李力钊[7]等人提出基于C-GRU模型的微博谣言事件检测方法,充分考虑了微博语句的句义特征与微博事件中的微博序列相关特征,有效提高了检测准确率。
虽然现有研究已取得一定成果,但仍存在以下几点问题。
(1)纯传统机器学习方法需要人为构造大量特征,增强了主观性。
(2)研究平台单一,影响模型泛化能力与可移植性。
(3)所依赖的传播模式、评论转发等特征具有时延性,在谣言高速传播窗口期后才能发挥作用,无法完成早期检测。
针对上述问题,本文提出多特征融合的可移植谣言早期检测模型。该模型结合LSTM神经网络挖掘谣言文本特征以提高特征工程质量与模型性能,在剔除时延特征同时引入有效度、敏感度、热度三大通用浅层特征保证早期检测能力,利用SVM进行融合训练,最终在多平台验证集上得到88%预测准确率。
2多特征融合的可移植谣言早期检测模型
谣言早期检测模型流程如图l所示,记谣言事件语料集合为T={t1,t2,…,tm},其中ti(1≤i≤m)代表某一主题的谣言语料。本文首先结合预处理过程提取出有效度、敏感度等浅层特征,再将已处理语料通过NLP技术转换为向量序列输入LSTM网络中学习谣言文本特征,同时利用网络爬虫技术获取热度特征,最后融合所有特征,构建SVM模型进行训练,实现谣言自动检测。
2.1浅层特征构建
本节将对除文本特征外的浅层特征计算方式进行介绍,包括普通特征与引入特征。
2.1.1符号特征
该特征是对语料中符号出现次数与占比的综合,符号包括超链接、感叹号等。谣言语料中常重复加入符号用于加重语气、博人眼球,如联合辟谣平台发布的十大热点谣言中便出现以“《邮政编码要取消了?……》”为题的谣言。利用式(1)对数据进行统计分析得到结果如表1所示,结果表明谣言语料符号平均占比约为非谣言语料的2.5倍,存在明显差距。
f(t)=len(t)-len(t')/c+len(t)-len(t')/len(t) (1)其中t表示输入语料,t'表示删除符号后的语料,len表示语料长度,C为自定义参数。
2.1.2情感特征
该特征指语料的情感正向程度。首欢容等人[8]在2017年提出一种基于情感词典的网络谣言识别方法,在假设高质量信息源信息更可靠的情况下,对特定类型谣言识别取得了较好成果。而情感词典缺乏可移植性,因此本文采用NLP科学工具SnowNLP计算情感值,其输出范围为[0,1】,输出值越大表示情感越趋于正向。随机选取谣言、非谣言样本各50条利用SnowNLP计算情感值发现谣言与非谣言语料平均情感值分别为0.59和0.75,表明非谣言语料较谣言语料而言情感更为积极。
2.1.3有效度特征
该特征指语料信息的有效程度,本文采用语料中的停用词数量进行表示。停用词处理是许多文本处理应用(如信息检索)中最重要的任务之一[9],可以节省存储空间和提高搜索效率。停用词通常不代表具体含义[10],因此语料中停用词数量在一定程度上体现了有效信息的占比,而以往研究没有进行利用。本文以哈工大停用词为主体构建了1677个停用词,对语料集进行统计得到结果如表2所示,证明该特征可以有效区分谣言与非谣言。
2.1.4敏感度特征
该特征指语料信息的敏感程度,以语料中敏感词含量定量表示。敏感词是在谣言中高频出现的词语,如“震惊”、“惊呆”以及带有性暗示的词语等。而网络文化的发展与舆论监管机制的完善更让这一特征显得复杂,缩写、变换字体、改用谐音等逃脱检测的手法层出不穷。本文对健康、政治及两性等领域的敏感词及变体进行搜集并构建敏感词库,利用词库对语料库统计分析发现,谣言中敏感词的数量远高于非谣言,详细结果如表3所示。
其特征计算公式如下:
f(t)=1/k∑k i=1 ∪Swi t (2)其中t为输入文本,K为敏感词总数,∪Swi t為敏感词Swi在语料中的出现次数。
2.1.5热度特征
该特征指语料在网络环境中的热度值。为保证各平台衡量标准一致,本文以语料于百度搜索引擎中的搜索次数表示。本文在数据收集过程中发现谣言语料多由个体发布,往往通过更改人物、地点等进行重复传播以提升热度,因此具有一定热度基础。非谣言语料则主要由个体或官方发布,而官方平台的存在会造成较大的热度差异。随机选取谣言、非谣言语料各5000条,得到热度分布如图2所示。图中结果证明了特征的有效性,当热度值较低时,谣言语料频数远高于非谣言语料;而随着热度值增加,非谣言语料频数则普遍高于谣言语料。
2.2基于LSTM的谣言深层文本特征构建
文本是谣言信息的主要载体与直观体现。喻国明[11]基于腾讯大数据筛选鉴定的6000+谣言语料,对谣言语料的叙事结构、议题场景构筑及标题特征进行了详细分析,反映出谣言文本特征的复杂性与重要性,体现了广泛的分析意义与应用价值。考虑到人为构造特征的不完备性,本文采用LSTM神经网络[12]对谣言深层文本特征进行学习。
LSTM模型构建过程如图3所示,本文将其划分为四大模块:输入模块、LSTMl模块、LSTM2模块和分类模块。输入模块负责接收输入语料以及进行向量化操作;LSTM1模块负责对来自输入模块的向量矩阵进行语义适应;LSTM2模块利用LSTM1模块输出矩阵进行强化学习,深层次挖掘谣言文本特征;分类模块根据LSTM2模块的输出进行分类总结,得出分类结果,详细步骤如下。 (1)输入模块将预处理后的谣言语料序列作为输入,经分词得到词序列集合Ws={W1,W2,…,Wm}。设置词数阈值Th,对于词序列Wi(1≤i≤m)采用截断补齐策略保证数据规整性。利用预训练Word2Vec词向量模型,将词语转化为低维稠密向量,词序列Wi则对应转换为矩阵Mebd∈RTh*D,其中D为词向量模型中的向量维度,则文本集合可转换为Ws∈Rm*Th*D。图4以m=4,Th=5,D=4为例kk直观展现了上述过程。
(2)LSTMl模块将Ws作为输入序列,通过LSTM单元进行语境自适应,将词向量维度更新为D,得到新的语料集合表示:
Ws=Ω(f(Ws·U1+b)
(3)其中f为Relu函数,U1为网络权重,b为偏置项,Ω为防止模型过拟合的Dropout操作。
(3)LSTM2模块利用LSTMl模块的输出进行拟合训练。对于谣言文本Ti,LSTM单元综合其词向量序列Wsi,提取句意、句式等隐藏特征,并将结果融合为窗口大小为D。的一维向量,最后通过Dropout层得到特征序列为
(4)其中Ω为Dropout操作,g为Softsign函数,U2为网络权重,b为偏置项。
(4)分类模块使用Sigmoid函数将LSTM2模块最后时间步的输出转换为对应谣言与非谣言的分类概率p,其即为文本特征值,p值越大表示语料为谣言的概率越高。
2.3SVM模型构建
在保证学习性能的同时,本文融合深、浅层特征构建特征向量,采用传统机器学习模型SVM进行拟合以提高物理性能。作为机器学习中流行且功能强大的监督分类器,SVM已经成功应用于模式挖掘、计算机视觉和信息检索等领域[13]。
SVM可以应用于可分离和不可分离的数据集[14]。令向量xi为文本Ti的特征向量,yi为谣言标签,则数据集Xtrain可表示为
Xtrain=(5)
考虑到数据来自多个平台,相互之间容易造成噪音干扰导致线性不可分,本文采用高斯径向基函数(Radial Basis Function,RBF)作为核函数K,该函数可将样本从原始空间映射到高维空间,使得样本在高维空间中线性可分。
3实验过程与结果分析
3.1实验数据
微博与微信作为目前国内顶级流量平台,其数亿级的用户群体使得其中流动着海量信息,其中不乏网络谣言。2018年联合辟谣平台正式上线,至今已精确辟谣数千条网络谣言。此外,各大论坛及直播平台均有谣言滋生。因此,本文将从上述平台采集实验所需谣言数据。同时,为保证数据合理性,本文从网络开源新闻数据集中抽取部分语料作为非谣言数据。结合网络爬虫与正则表达式技术,最终,经聚类去重处理,为谣言识别任务构建的数据集分布情况如表4。
3.2超参数优化与实验结果
本文需要训练两个模型:计算文本特征的LSTM模型和融合多特征的SVM模型。随机选取12000条数据作为训练集,2000条数据作为交叉集,3000条数据作为验证集。
3.2.1LSTM模型实验结果
该模型用于学习谣言深层文本特征。设置词向量维度D为180,文本分词后的词数阈值Th为100,LSTM1模块输出维度为100×64,LSTM2模块输出维度为1×64。模型损失函数采用Binary_crossentropy函数,并使用自适应矩估计优化器(Adam)对模型进行优化。设两层Dropout值为Dr1与Dr2,筛选范围均为0.2-0.5,以0.1为调整步长。设置洲练一交叉集迭代次数为10,图5呈现的Dropout参数调优过程表明Dr1=0.5、Dr2=0.4时达到最优性能,其对应洲练过程如图6所示。
图6表明第8次迭代时,交叉集损失值达到最低随后开始增加造成过拟合,说明模型达到最优,最终在验证集中取得80%预测准确率,详细评测结果见表5。
3.2.2SVM模型实验结果
为进一步提高模型性能,利用SVM融合上述特征进行训练。基于RBF核函数的SVM中参数C与σ的搭配很大程度上决定了模型性能,因此本文将C与σ范围缩小为[1,100]后,采用网格搜索确定其最佳组合为C=30,σ=40,结果如图7所示。
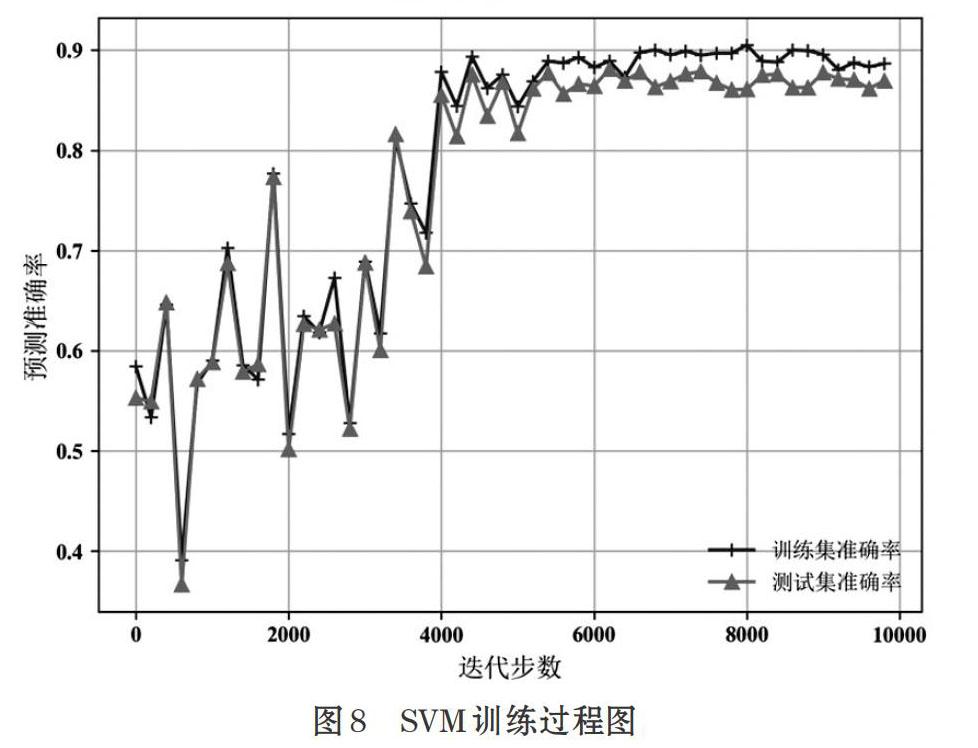
以迭代步数为自变量绘制模型对应准确率曲线如图8所示,当迭代步数达到5000步时,模型逐渐收敛达到最佳性能,最终取得88%准确率,相对仅使用文本特征的LSTM模型提高了8%。
3.2.3对比分析
令R表示谣言,NR表示非谣言,使用如下方法与本文提出方法进行对比。
(1)王志宏[5]等提出的动态时序特征表示方法和三项新特征的检测方法SVMDTSall。
(2) Ma等人[6]使用的tanh-RNN、LSTM、GRU检测方法。
结果如表6所示,如第1章所述,本研究主要采用微博或Twitter数据进行检测,而人们在不同平台针对某一事件的表现形式存在一定差异,对模型可移植性造成影响。本文在平台差异性增强了数据集噪音的情况下,进一步将准确率提高到了88%,证明了模型的谣言早期检测能力以多平台间的可移植性。
4结束语
作为互联网时代的消极产物,网络谣言对个人、社会和国家带来了巨大影响。本文提出多特征融合的可移植谣言早期检测模型摒弃传统的时延特征,引入常被以往研究忽略的有效度、敏感度、热度特征;结合深度神经网络挖掘谣言深层文本特征,进一步增强了对谣言语料的表征能力。在对多平台数据集的测试表明,本文所提出的模型展现了可观的谣言早期检测能力,并表现出更为优秀的可移植性。下一步工作中我们将获取更大数据集,对数据进行深度分析,发现网络谣言更有效的特性以提高模型准确率。除此之外,谣言传播方式繁多,如图片、视频等,因此仅考虑文本形式的谣言存在一定局限性,需要进一步地思考如何将其进行融合以达到更好的检测效果。
参考文献(References):
[1]张鹏,兰月新,李昊青等,基于认知过程的网络谣言综合分类方法研究[J],图书与情报,2016.4:8-15
[2]Castillo C,Mendoza M,Poblete B.Information credibilityon twitter [C]// Proceedings of the 20th internationalconference on world wide web. ACM,2011:675-684.
[3]Yang F,Liu Y, Yu X, et al. Automatic detection of rumoron Sina Weibo[C]//Proceedings of the ACM SIGKDDWorkShop on Mining Data Semantics. ACM,2012:13
[4]毛二松,陳刚,刘欣等,基于深层特征和集成分类器的微博谣言检测研究[J].计算机应用研究,2016.33(11):3369-3373
[5]王志宏,过弋.微博谣言事件自动检测研究[J].中文信息学报,2019.33(6):132-140
[6] Ma J,Gao W, Wong K, et a/ Detecting rumors frommicroblogs with recurrent neural networks[C]// InProceedings of the Twenty-Fifth International JointConference on Artificial Intelligence. New York: AAAIPress,2016:3818-3824
[7]李力钊,蔡国永,潘角,基于C-GRU的微博谣言事件检测方法[J].山东大学学报:工学版,2019.49(2):102-106,115
[8]首欢容,邓淑卿,徐健,基于情感分析的网络谣言识别方法[J].数据分析与知识发现,2017.1(7):44-51
[9] Mohammad S,Jesus V. Automatic identification of lightstop words for Persian information retrieval systems.Journal of Information Science,40(4):476-487
[10] Kaur J,R. Saini J.Punjabi Stop Words:A Gurmukhi,Shahmukhi and Roman Scripted Chronicle. InProceedings of the ACM Symposium on Women inResearch 2016. ACM,2016:32-37
[11]喻国明,网络谣言的文本结构与表达特征——基于腾讯大数据筛选鉴定的6000+谣言文本的分析[J],新闻与写作,2018.2:53-59
[12]Hochreiter S, Schmidhuber J. Long Short-TermMemoW. Neural Comput,1997.46:1735-1780
[13] Cheng Fan, Chen Jiabin, Qiu Jianfen. et a/.A subregiondivision based multi-objective evolutionary algorithm forSVM training set selection[J].Neurocomputing,2020.
[14]Mary Francis L Sreenath N. TEDLESS-Text detectionusing least-square SVM from natural scene[J].Journal of King Saud University-Computer andInformation Sciences,2020.32(3).
收稿日期:2020-04-26
作者簡介:孙王斌(1998-),男,江西宜春人,本科生,主要研究方向:自然语言处理。
