基于LSTM的动车组故障率预测模型
2020-10-09陆航杨涛存刘洋于卫东田光荣肖齐李方烜
陆航, 杨涛存, 刘洋, 于卫东, 田光荣, 肖齐, 李方烜
(中国铁道科学研究院集团有限公司机车车辆研究所,北京 100081)
1 研究背景
由于我国现役动车组速度等级和运营环境差异较大,同时又存在多种技术平台的背景,基于传统统计学概念的数学方法研究故障规律及其回归问题的方法不足以满足研究需要。同时由于动车组本身涉及多种功能系统的故障研究对象,单纯通过机理建立故障层级联系成本过高,系统或部件级的失效关系很难直接描述其逻辑映射[1-3]。因此当分析动车组故障率趋势时,考虑通过数据驱动的方式,不深入探究其变化机理,如因高级修大量更新部件的系统,源头质量整治、技术规章改进后故障率大幅降低,气候因素导致的故障率波动,涉及动车组生命周期内大量转配问题导致其运行环境的改变等。
与通过数理统计及机理模型不同,机器学习的概念是通过特征提取、数据驱动的方式找到输入与输出数据间的某种联系。循环神经网络(RNN)是接受序列数据为输入,在序列的演进方向(随故障率统计的自然年推进)进行递归,利用回归问题的监督学习,所有节点按链式连接的递归神经网络,在解决复杂、非线性、难以直接找到其规律的时序问题时有较好效果[4]。在预测问题如股票价格与投资量化等经济学领域[5-6]以及分类问题如网络流量分析[7]和人类行为识别[8]等RNN 均有广泛运用。陆冰鉴等[9]对传统模态分析(EMD) 后的子时间序列进行长短期记忆(LSTM)序列建模,在预测风速方面取得进展。电力通信网络流量也有类似随机波动性强的特性,黄国伦等[10]提取多个本征模态分量和残差差分量。对于前者运用类似EMD-LSTM 混合模型预测趋势,对后者用SVR 拟合建模预测,可以更好体现整体流量的发展趋势。Simão 等[11]提出将16 通道肌电信号 (EMG)以步长分为静态、动态判别的方法,其中静态识别采用前馈神经网络(FFNN),动态序列识别采用LSTM 分析,实际测试效果较好。对比其他机器学习算法,如动态贝叶斯与马科夫链等基于概率的模型,由于前述大长交路运营环境差异,同时存在动车组检修、转配产生的统计难度,很难建立独立事件下的先验知识模型。在交通领域,利用循环神经网络预测的相关研究可见于:利用多源输入数据的公交到站时间预测及其与其他 KNN、SVR 等主流预测模型的对比[12]。李万等[13]通过相关性分析得到铁路营业里程、国家铁路客车拥有量、国内生产总值和年末总人口作为铁路客运量的重要影响因素并利用LSTM对铁路客运量进行预测。
2 基于RNN的序列分析方法
介绍序列分析方法(同时考虑确定性和随机性因素),建立对应动车组服役性能演变规律的以RNN为基础的LSTM模型,以揭示动车组整车及关键系统的服役性能演变。利用高铁开通10 年来的历史故障数据进行特征提取,作为模型输入源,通过模型优化、参数调整及训练结果泛化等机器学习技术,实现对系统级故障规律的预测。
2.1 RNN基本结构与数据流
运用RNN 处理等间隔动车组故障率数据流程见图1,其下、中、上3 层结构可简单理解为输入层—隐含层—输出层,实线箭头部分自下而上的数据流为神经网络前馈传递的过程。在输入层中,提取动车组信息管理系统(EMIS)的结构化与非结构化信息,对故障数据原因等进行人工文本标注与自然语言处理[14],并与结构化故障数据匹配。将数据依运行速度级、车型高级修周期关联分为几种车型,作为输入层数据源。该特征提取后的自然年维度等间隔时间序列,从t时刻向前n个周期(包括t时刻)输入。每个输入层节点包含该时刻6 个关键子系统故障率,其中n视数据结构特征及训练泛化的结果而定。
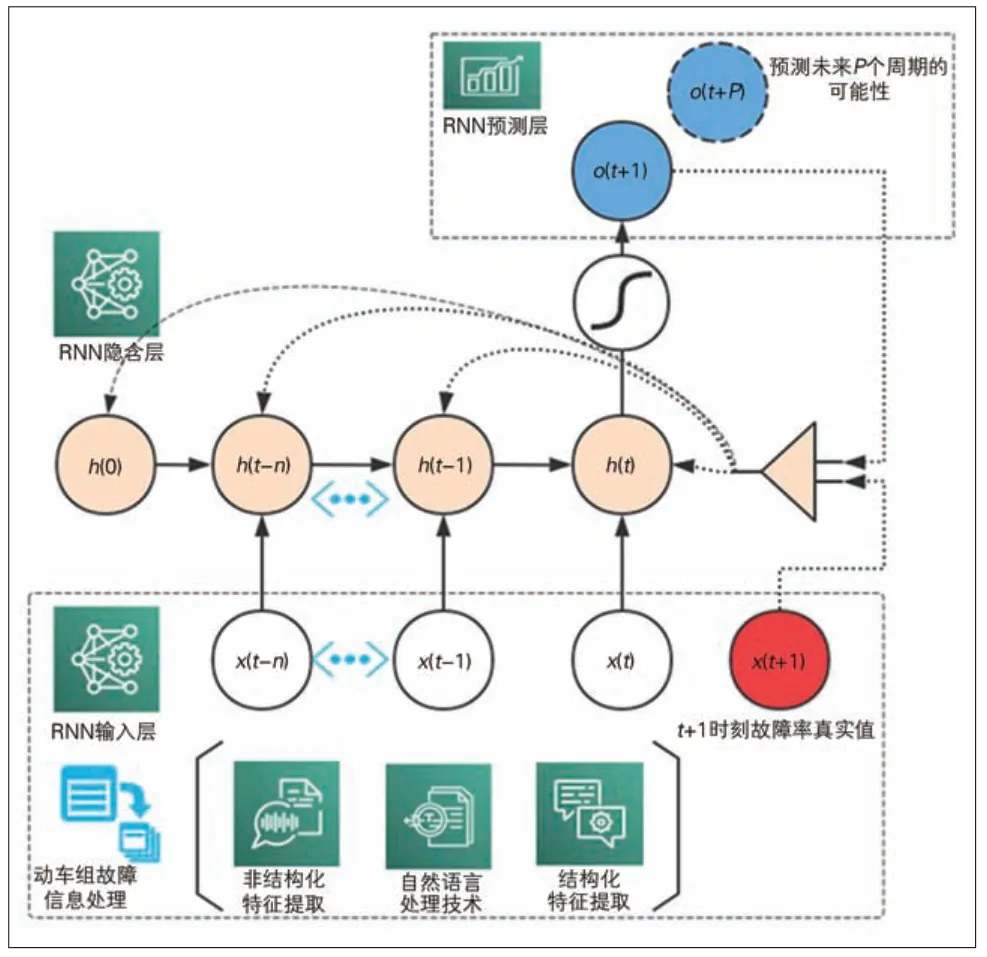
图1 运用RNN处理等间隔动车组故障率数据流程
模型结构中的隐含层与传统前馈(又称前递)神经网络(FFNN)不同的是,前一时刻(t-1)的状态也会影响t时刻模型运算。具体地说,为了预测下一周期,即t+1 时刻的动车组故障率,除了考虑t-n,…,t时刻的实际故障率数据外,还需RNN 模型前n个时刻隐含层运算的结果。而从结构上说,FFNN 经过训练,只需前几个时段的故障率作为运算输入预测t+1时刻数据。需要注意的是,RNN 结构图不代表神经元的个数与具体位置关系,如h(t)为t时刻隐含层全部神经元运算的状态。
在预测层中,节点o(t+p)代表向后预测P周期的可能性。向后预测的能力除取决于模型训练的效果,也要依据运用需求而定,为反映时间跨度的新车造修与运营维护水平,以及某几个系统故障率对预测整体故障率产生的影响。该需求确定P=1,以期利用预测结果给该年份源头质量整治、修程修制优化等工作提供方向性建议。
2.2 激活函数
激活函数在图1 中被描述为从RNN 隐含层到输出之间的节点,实际连接上一层各隐含层神经元的输出,激活过程也称点火,符合人脑神经饱和的规律。激活函数的非线性单调性特征是为了更好处理复杂的非线性问题,当上一层神经元输入趋近正无穷时,激活结果趋近于1,防止单一神经元权重过度影响整体结果。
激活函数主要包括Sigmoid、Tanh、ReLU共3 种。3种激活函数曲线见图2。
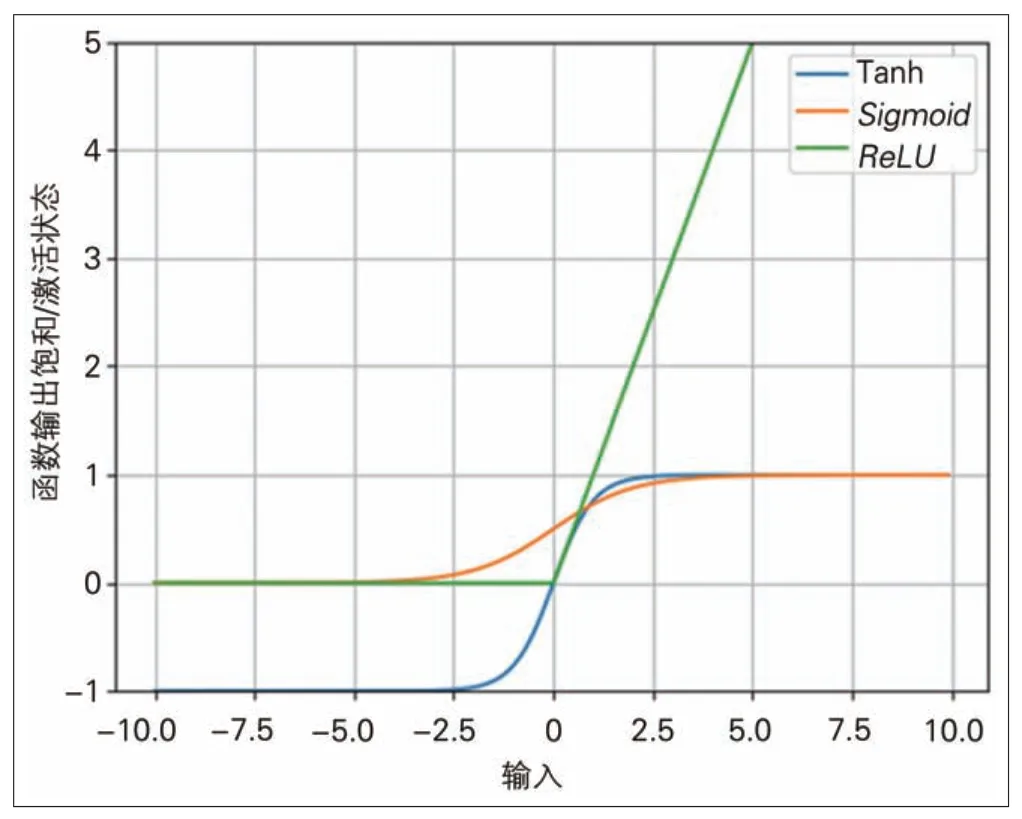
图2 3种激活函数曲线
(1)作为神经网络中最常见的激活函数Sigmoid在输入处于[-1,1]时,函数值变化敏感,一旦接近或超出区间就失去敏感性,处于饱和状态。Sigmoid函数数学表达式如下:
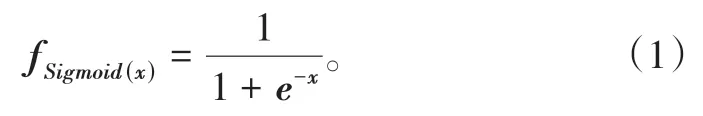
(2)双曲正切函数Tanh,比Sigmoid函数延迟了饱和期,以影响神经网络预测的精度值。Tanh 的输出和输入能够保持非线性单调上升和下降关系。Tanh 函数数学表达式如下:

(3)ReLU是1 种较新的激活函数,由于省略了Tanh与Sigmoid中的指数运算,节约了硬件算力以适应更复杂的模型设计。泛化速度较快,大于0 维持原值,可加速梯度下降的收敛速度。但需保证较小的学习速率α,否则容易出现神经元不起效果的情况[12]。ReLU函数数学表达式如下:
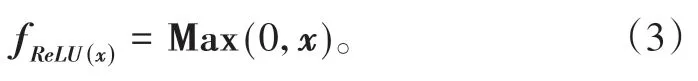
2.3 RNN模型泛化及训练方式
该循环神经网络采用反馈方式实现监督学习,其训练过程在图1中用右侧点状虚线描述。监督学习的核心思想是将模型预测值(以o(t+1)为例)与实际该时刻的真实故障率(以x(t+1)为例)对比,将差异反向传递给隐含层神经元。这些神经元通过不断权重调整,以获得更小的整体误差,即损失函数中的Eloss,其函数数学表达式如下:
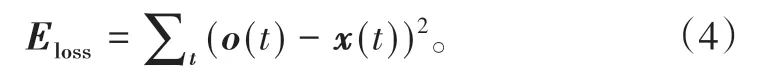
梯度下降的概念即利用上述Sigmoid与Tanh等激活函数的可导性,求导趋于0 代表该神经元的局部最优。每次训练的隐含层向量权重更新称为迭代:
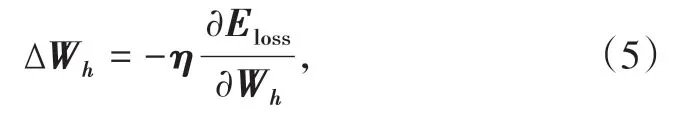
式中:ΔWh为隐含层整体权重状态。式(5)的含义是,每次更新迭代的各节点权重如何沿梯度方向随损失函数Eloss的偏导方向改变。而需注意训练数据集与验证数据集误差的概念:模型通过一系列训练(权重调整),过度适应训练可能针对某些训练数据集结果优异,但对验证数据拟合误差过大,泛化能力较差。过拟合的情况有:(1)验证数据集明显劣于训练集;(2)训练周期过多;(3)几次迭代之间Eloss波动较大,即训练不稳定;(4)训练陷入局部极小值而限制整体权重更新。反之,存在以下问题时,RNN会出现欠拟合情况:(1)迭代次数不足,损失函数还存在进一步改进的趋势;(2)模型隐含层神经元数量不足,设计过于简单,不适用于非线性度较高的故障率时间序列,训练集中表现较好但趋于饱和。学习率η决定了模型训练泛化的速度,如果η过大,训练数据集可能出现过拟合问题,反之则泛化过程过慢,学习效率低。
3 LSTM模型优化训练与预测研究
传统循环神经网络预测模型中,由于网络各隐含层的权重在传递过程中影响逐渐减弱,对多隐含层后节点影响过小,导致后层节点无法接受较远层传递的信息,进而影响整个网络的预测性能。使用LSTM神经网络处理各系统故障率在不同时长对整体故障率的影响关系。另外,解决非线性度高的RNN 往往参数体量巨大,LSTM 更合理的结构优化了运算过程,也能一定程度上避免过度训练问题[15-17]。
3.1 LSTM网络结构及其优化
为解决传统RNN 模型中梯度消失问题,即反向传播更新权重时,前几个状态的隐含层向量作用逐渐降低,训练效果不显著[15-16]。而分析动车组故障率数据时,输入数据中某些系统级故障率的作用差异,可能会对n>1 时长即1 年后的整车及故障率作用较大,这意味着前述RNN 中输入层的动车组各系统故障率数据随时间的抽象级别较高。LSTM 神经网络能利用若干个神经元叠加得到的长短时记忆储存器处理这类复杂序列问题[15]。LSTM数据流及结构见图3。
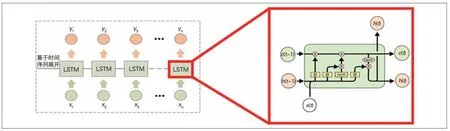
图3 LSTM数据流及结构
将图3 中的LSTM 与图2 的RNN 做结构对比,在传统RNN 的前馈过程中,只有1 个激活层连接隐含层与输出层,而在LSTM储存器中有多个激活函数交叉的节点。同时,LSTM 网络增加细胞状态信息c以影响整个序列神经元状态h(n):上一时刻隐含层状态h(t- 1)、细胞状态c(t- 1)及该时刻x(t)各系统故障率实际输入层数据,通过非线性激活函数Sigmoid及Tanh进行一系列耦合得到的结果。该结果除包含对上一时刻细胞状态的保留程度,还叠加了激活后的上一时刻隐含层与该时刻实际输入。因此能实现非线性度与复杂程度更高的故障率序列预测。LSTM 模型采用Tensorflow 1.13.1版本构建,Python语言环境为3.6。模型输入端包含t时刻归一化动车组6个关键子系统故障率,同时考虑输入层数量及年份样本数量,将隐含层神经元个数定为20。该LSTM模型的损失函数取用式(4)中的Eloss进行训练泛化,利用均方根相对误差(MSE)作为训练与测试评价指标。
模型训练过程中采用4种优化策略:
(1)随机梯度下降法(Stochastic Gradient Descent,SGD)。从训练样本中随机抽出1 组,训练后按梯度更新1 次,然后再抽取1 组,再更新1 次,可能不用训练完所有样本就可获得Eloss在可接受范围内的模型。虽易收敛到局部最优,但容易被困在鞍点。
(2)惯性(Momentum)算法。借用物理动量概念,模拟物体运动时的惯性,即更新时在一定程度上保留之前更新的方向。可在一定程度上增加稳定性并有一定摆脱局部最优的能力。
(3)RMSprop 算法。增加1 个衰减系数控制历史信息的获取程度。
(4)Adam(Adaptive Moment Estimation)。是另一种自适应学习率的方法,利用梯度的一阶与二阶矩阵估计动态调整每个参数的学习率。Adam 的优点主要在于经过偏置校正后更新学习率,使得训练更稳定[12]。
研究针对车型数据特征,分别用4种优化过程进行训练,迭代次数(epoch)为500,保证各算法得到充分训练,以损失函数作为检验标准。发现RMSprop 算法最先达到饱和状态,Adam与其接近,均在50次迭代后使LSTM 模型得到泛化。但二者相比,Adam 算法的训练更稳定,相邻2次的波动最小,综合泛化最好。惯性算法相对最长时间达到训练饱和,泛化效果与两者相差不大。而随机SGD 算法则耗时最长,同时很难达到饱和状态。
综上考虑各因素,最终选取Adam 作为优化策略。学习率α取值过大可能导致收敛速度过快,造成更新的ΔWh振荡较大。因此针对不同车型类别,调整整体学习率,针对各参数优化后α=0.90~0.95。
3.2 数据验证
出于保密性考虑,将某些车型(分类为车型一、车型二)的百万公里故障率数据进行归一化处理,形成无量纲等时距数据样本(见图4、图5 中黑色目标曲线)。将2010—2017年的各系统级故障率输入泛化后的LSTM 模型,测试其t+1 年份的故障率曲线,即2011—2018 年故障率数据(见图4、图5 中蓝色预测曲线)。将最近1年的预测结果与实际得到的整车故障率进行比对,以验证模型准确性并进一步优化调整模型参数,调整上述优化过程的迭代次数以防止过拟合问题的发生。
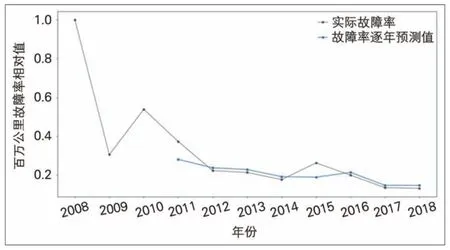
图4 车型一动车组故障率预测结果
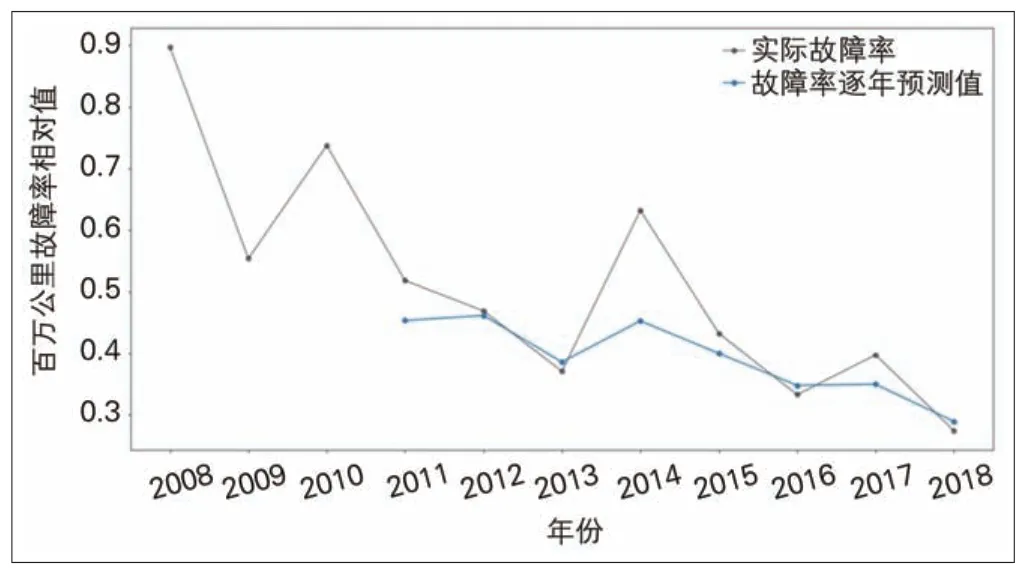
图5 车型二动车组故障率预测结果
从图4、图5 可以看出,单纯以此数据驱动的方式,对于某些车型某些年份的大幅度波动预测存在一定难度;但LSTM模型输出的预测曲线可在一定程度上把握数据的主成分趋势,并且时间序列能够考虑输入变量对时间序列的依赖性,具有复杂趋势的学习能力。
4 结束语
以整车及关键系统的故障规律为对象,以车辆责任故障条目为分析源,匹配EMIS 中的动车组履历信息,建立数据库并进行清洗。利用时序分析方法(同时考虑确定性和随机性因素),建立对应动车组服役性能演变规律的机器学习模型,以揭示不同高级修周期内动车组整车及关键系统的服役性能演变。利用高铁开通10 年来的历史事故及故障数据驱动,通过模型优化、参数调整及训练结果泛化等机器学习技术,实现对下一时间段故障率的预测。RNN 接受序列数据为输入,在序列的演进方向进行递归,所有节点按链式连接的递归神经网络,其中通过LSTM结构中对前数个周期神经元状态的遗忘与保留,对非线性度较高的故障率序列训练效果较好,并测试其具备以时间为维度系统故障率的模型基础。
考虑故障数据样本特点,解决了目前机器学习领域的小样本学习问题,优化神经元函数与训练泛化能力提升等大数据机器学习领域研究问题。该故障率分析预测模型的建立—训练—验证提供了掌握整车安全态势的新视角:以数据驱动的方式建立了各系统级故障率到整车故障率之间的映射。
