基于Hadoop 平台的快速日志挖掘方法∗
2020-10-09昂鑫徐建张宏
昂 鑫 徐 建 张 宏
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
随着互联网和电子商务的不断发展,越来越多的人选择网上购物,这些用户访问、交易的过程和系统状态都会以日志的形式记录下来。显然这些日志数据是异构的,且数量巨大,并且,其中蕴含着很多有价值的信息。比如,通过挖掘Web 日志,可以统计分析出服务器在不同时段的用户访问量,访问者IP 地址的分布情况,访问网页的时间等,然后给用户定向推送相关产品信息和广告。再比如,可通过日志分析某网站访问量是否异常,进而判断是否有黑客攻击或者非法链接请求等,所以,日志挖掘是非常有意义的工作。然而,一个可接受的日志标准还没有被开发,因此,如何快速解析来自不同系统的日志数据是一个极具挑战性的问题。
目前已知的日志模式发现方法主要分为两大类:基于正则表达式的日志匹配方法,基于聚类算法的日志模式识别。许多公司开发了日志分析工具,如:Splunk,Sumo Logic,loggly,LogEntries 等,还有一些开源软件包也被用于日志分析,如Elastic-Search[1],OSSIM[2]等。这些工具和软件包大多使用正则表达式来匹配日志数据,仅支持监督匹配,不适用于大量异构日志。此外,正则表达式的编写过程复杂、容易产生冲突的特点给日志分析工作带来了很大的困难。尤其,过度泛化的正则表达式规则降低了日志数据的处理效率。Vaarandi[3]开发了简单的日志文件聚类工具SLCT。SLCT 本质上是基于频繁单词的聚类算法,即具有相同频繁单词的日志会被聚集在一起。SLCT 利用了日志中单词的高度倾斜分布的特点进行聚类,该特点也被很多日志挖掘聚类算法应用。Makanju 等[4~6]在日志数据分析方面开展了一系列工作。在文献[6]中,作者提出了IPLoM,这是一种迭代的日志聚类算法,实验证明了该算法优于其他日志聚类算法,比如上文提到的SLCT。但是IPLoM 易生成小的、没有统计意义的簇碎片,簇质量也难以控制。尤其是,IPLoM假设等长的日志具有相同格式,使得它不适合在大量异构日志中使用。C.Xu 等[7]提出了一种无自定义参数的聚类Web日志的算法,然而该算法的时间复杂度为O(n3),其中n 是日志的数量,不能扩展到大数据集。Xia Ning 等[8]研究了一种无监督的HLAer 框架,该框架用于自动解析异源日志数据,对异构日志具有健壮性,由于运行需要大量的内存开销,所以也不可扩展。以上的算法或工具的共同问题在于:无法扩展到大量异构日志数据集中。
近年来,Hadoop 平台在处理大数据集上表现出了优异的性能,MapReduce 是Hadoop 平台的计算框架。李洋等[9]研究了基于Hadoop 与Storm 的日志实时处理系统,实验证明了在四个节点的集群环境下提取相同频繁项集的运行时间比单机大约减少了一半。吴洁明等[10]提出了一种基于Hadoop的Web 应用日志挖掘算法,该算法能准确进行日志模式发现,并在效率方面较单节点模式有着极大的提升。许抗震等[11]研究了基于Hadoop的网络日志挖掘方案的设计,实验表明了Hadoop 集群拥有良好的计算扩展性,通过增加节点的方式,且不需进行很多复杂的配置就能解决海量日志数据的处理问题。
因此,本文提出了基于Hadoop 平台的快速日志模式发现方法,该方法在分布式平台下,通过扫描一次日志,就可快速将日志聚类并提取相应的日志模式。本文主要工作概述如下:1)描述一个完整的日志模式发现的框架;2)描述在Hadoop 平台下进行日志聚类和模式发现算法;3)将本文提出的日志模式发现方法与HLAer进行对比实验。
2 快速的日志模式发现
日志来源于特定的用于系统监测或状态感知的组件,通常是基于特定模板产生的,因此具有明确的格式,当然产生于不同组件的日志格式不尽相同。本文所提出的快速的日志模式发现方法就充分考虑了产生日志消息的模板是有限的,不同的日志消息可能源于相同的模板,它们之间存在相关性的这一特性。这显然有别于传统的聚类方法,它们将每个样本都视为独立对象,并不考虑相互之间的关系。下文首先通过一个实例阐述日志数据的特性,而后设计用于快速日志模式发现的框架,在此基础上提出一种分布式的日志聚类和模式发现方法。
2.1 日志实例和特性分析
图1 给出了一个jenkins 可持续集成系统的日志作为示例用于阐述日志特性。与文档,网页等同样采用自然语言的数据相比,日志数据具有以下特点:
1)日志数据的语法结构弱。为了记录应用程序或系统的运行状态,日志通常是简短的,且不遵循标准的语法结构,因此NLP解析器无法在日志中识别有意义的语法。
2)日志的词汇量有限,但词汇统计呈偏斜分布,某些词出现的频率高,有长尾现象。
3)基于模板生成日志。由于日志记录从源代码生成,具有明确的格式,使得日志数据比其他文本数据更容易聚类。
4)类型相同的日志会有冗余。日志记录的冗余是日志数据与传统文本数据的主要差异,当日志记录用于管理时,相同类型的日志会重复多次出现,因此,可以对相同类型的日志数据进行下采样,以减少内存和CPU使用的负担,也可提高日志分析的效率。
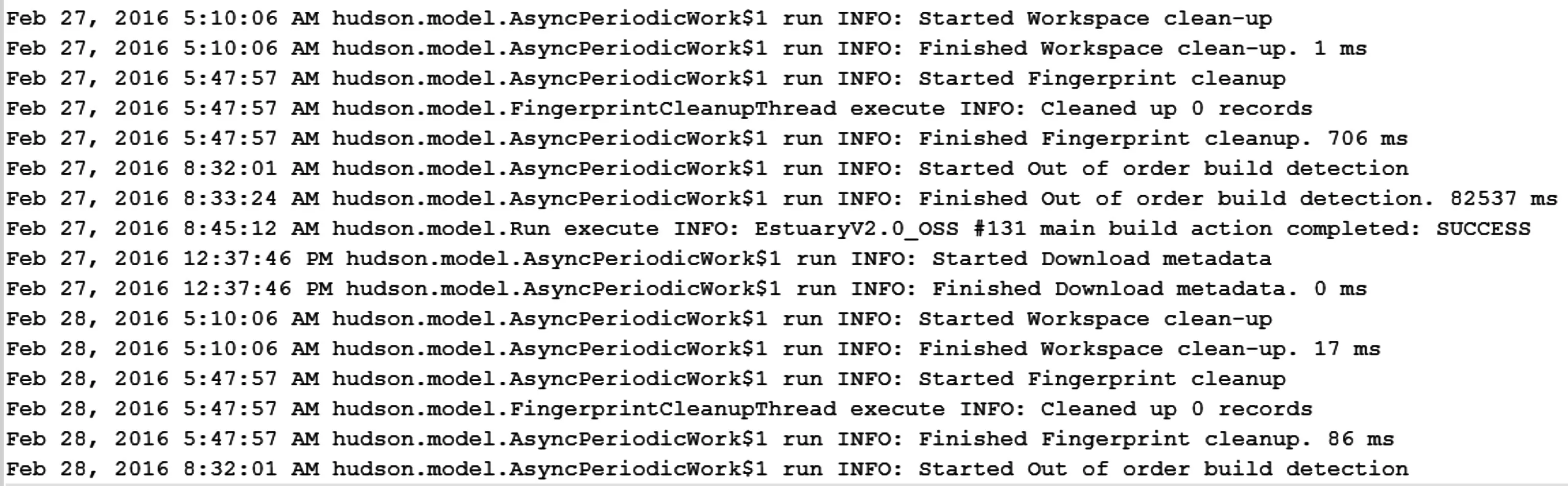
图1 jenkins可持续集成系统的日志
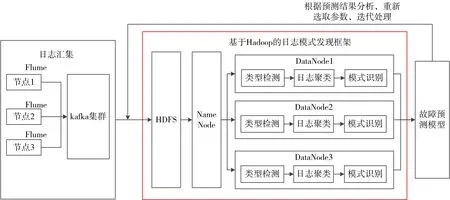
图2 日志模式发现框架
2.2 框架
图2 给出了日志模式发现的框架,聚焦于分布式日志模式发现组件。首先,通过flume和kafka等构成的日志汇集组件将分布式环境中的日志汇聚到Hadoop 平台。然后,对日志进行预处理,采用聚类方法将相似的日志聚集在一起,再利用日志模式识别方法提取每个簇的模式。最后,将这些模式传递给故障预测模型等应用。本质上,产生的日志模式是将原始日志的特征空间进行了降维,且保留了关键特征。最后,根据模型的预测效果,重新选取参数迭代进行日志聚类、模式识别、模型训练等操作,以获得最佳效果。本文将重点阐述分布式日志模式发现部分。
2.3 分布式的日志模式发现方法
日志数据具有明确的格式,在大量异构日志源的情况下,相同日志源的日志很相似,大多只是同类型字段的数值不同,在高维空间中,会形成完全分离和高度密集的区域。因此,我们可以充分利用这个性质,先将日志数据预处理,再采用One-Pass日志聚类方法,只扫描一次日志就可将所有日志准确聚类,而不必像传统聚类算法一样,需要多次迭代寻找簇中心。最后,对于每个簇,顺序合并日志以生成日志模式。
2.3.1 标记和类型检测
首先通过空格分隔每条日志数据来进行预处理,然后,定义一组类型,如date,time,IP,number和URL 等,再用正则表达式匹配日志和定义的类型,并用类型值替换实际值。例如,用date 替换2018-07-09,用IP 替换192.168.1.115。虽然这个步骤不是强制性的,但是,经过预处理,日志的相似性度量更加准确。否则,两条日志会因为同类型字段的数值不同获得低相似性。因此,为避免产生多余的日志模式,需要进行标记化和类型检测。
2.3.2 日志的相似性度量
其次,给出日志的相似性度量方法,如果简单地从两条日志的第一个单词开始按顺序比较是否相同,那么就忽略了日志原来的模板。为了完全捕获日志的结构和内容的相似性,需要先对齐日志,再计算相似度。这里采用Smith Waterman[12]算法,它利用动态规划的思想从两条日志的第一个单词开始向后递归地比较,直到最后一个单词结束,期望获得最大的相似性得分,以此可将日志对齐,并用一个得分矩阵记录当前位置日志对齐的最高分数。得分函数如式(1):

其中,L1(i)表示第一条日志的第i个单词,L2(j)表示第二条日志的第j个单词。S1表示第一条日志的第i个单词与第二条日志的第j个单词对齐;S2表示第二条日志的第j 个单词与间隙对齐,相当于在第一条日志的第i个单词后面添加了一个间隙;同理,S3表示第一条日志的第i个单词与间隙对齐。如此向前迭代并更新得分矩阵,最终通过回溯得分矩阵得到对齐的日志,回溯的路径长度就是对齐后日志的长度。对齐时,为了减少添加间隙,设定单词与间隙匹配的得分为0。对齐后两条日志长度相同,将Sim归一化可得相似度,归一化表达式如式(2):
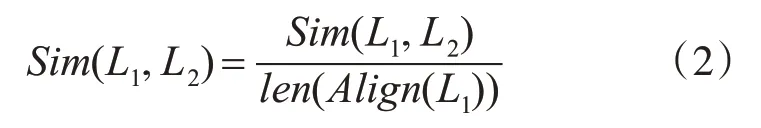
其中Align(L1)表示对齐后的第一条日志。
现在,我们还要定义match 函数。如果只考虑单词是否相同,而不考虑语义相似性是不准确的。例如,在日志中,单词“mistake”和“error”的含义是相似的,不考虑语义相似性的情况下,相似性度量结果为0,显然是不合理的。YH Wang 等[13]使用Word2Vec 模型来计算词向量用于口语检测,Word2Vec 是用神经网络把one-hot 形式的词向量映射为分布式词向量,分布式词向量隐含了词语的信息,两个向量夹角的余弦值可以表示词语的相关性。于是,这里采用Google 训练好的Word2Vec 模型获得两个单词的词向量,若词向量夹角的余弦值大于阈值MinSim,得分为1,否则为0。match 函数定义如式(3):

其中Vec(L1(i))表示第一条日志第i 个词向量,Vec(L2(j))表示第二条日志的第j个词向量。
于是,日志间的距离可定义为
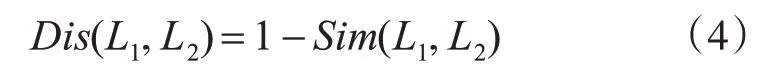
2.3.3 日志聚类
接着,阐述基于One-Pass 的日志聚类过程。定义参数MaxDistance 来表示簇中任何日志数据与簇中心之间的最大距离。因此,同一簇中任意两条日志之间的最大距离为2 倍的MaxDistance。算法从第一条日志数据开始,逐个处理所有日志,直到最后一条。每个簇都有一个簇中心,它也是该簇的第一个成员。当任意新的日志和簇中心之间的距离小于等于MaxDistance 时,则将它插入该簇中,若与所有簇中心都不相似,就创建一个新簇并将其作为该簇的中心。
由于内存中的每个簇只需保留一个簇中心,因此可以用少量的内存来处理大量日志。One-Pass聚类算法的时间复杂度为O(n),其中n 为日志总数。由于相同簇的日志数据相似度极高,而且大多由同一应用程序的同一段代码生成,因此在准确聚类的前提下,算法忽略了大量的日志。当参数MaxDistance 较小时,使用One-Pass 聚类算法可以生成高密度的日志簇。One-Pass 聚类算法对日志数据的顺序(通常是时间顺序)具有很强的依赖性,尤其是在聚类的早期,当每个模式的第一条日志出现时,就会形成一个簇,这样,短时间内易形成多个簇,而剩余的日志将必须与多个簇中心进行比较。然而,来自同一应用程序的日志数据往往同时出现多条,这样更有利于One-Pass聚类。
One-Pass 可以在map-reduce 框架下并行执行。在map 函数中,对于每条日志,创建一个键值对,键为固定值(可以为1),这是为了最终在reduce函数合并成一个日志列表,列表中的每条日志都是一个簇中心。值是经过预处理的日志列表(初始大小为1,只有一条日志)。在reduce 函数中,合并两个日志列表,具体来说,把包含日志多的的列表作为基本列表,然后将另一列表中的日志逐条与基本列表中的每条日志对比,当日志与基本列表中所有日志都不相似时则可作为新的簇中心添加到基本列表中,否则,忽略该日志。最后,基本列表即为合并结果。由于需要为每条日志创建一个键值对,因此map-reduce实现的空间复杂度是O(n),n是日志总数。
Reduce函数:

2.3.4 日志的模式发现
最后,给出完整的日志模式发现算法,将簇中的所有日志生成一个模式。我们可以先合并两条日志,再推广到一组日志。由于之前聚类时将每条日志依次与所有簇中心对齐,再度量距离,以确定其所属的簇。为了避免当前日志的对齐影响后续日志的度量,所以,度量距离后,簇中心和对比的日志都应当还原。那么,在合并两条日志时,仍然需要先采用Smith Waterman 算法对齐日志,对齐后,两条日志的长度相同。然后,将它们按序匹配对应位置的字段,并生成模式。若两个字段完全相同,那么取其中一个作为模式当前位置的字段,如果两个字段类型相同,则取该类型作为模式当前位置的字段,否则取通配符作为模式当前位置的字段,具体算法伪代码如下。

由于簇中日志高度聚集的特性,合并的顺序不会影响模式生成的结果。因此,我们可以从簇的第一条日志开始,将它依次与第二、第三,直到最后一条日志合并,最终生成该簇的日志模式。这同样可以采用map-reduce 框架并行合并日志。由于日志模式发现是在聚类之后进行的,因此我们知道每条日志的所属簇。在map函数中,为每条日志创建一个键值对,键是日志的簇编号,值是日志本身。在reduce 函数中,将来自同一个簇的两条日志合并。reduce 阶段的最终输出是每个簇的日志模式。如果忽略map-reduce 框架的开销,在m 个机器上完全并行运行该算法,时间复杂度为,其中n是日志数,t为每个日志的平均单词数。
3 实验
3.1 实验环境及数据
本文完成了三个实验。因为HLAer 能非常准确地发现日志模式,所以,实验一是将HLAer 框架作为标准,验证本文算法的准确性。HLAer 使用OPTICS[14]算法聚类日志和UPGMA[15]算法生成日志模式。OPTICS 是基于分层的聚类算法,有两个参数:∈和MinPts。它确保最终的簇至少有MinPts个对象,并且簇中任意两个对象之间的最大距离小于等于∈。OPTICS 需要为每条日志计算MinPts 个最近邻,时间复杂度为O(n2),它是高度精确的聚类算法,可以在高维空间中找到任意形状和密度的簇。UPGMA 是一个自下而上的层次聚类算法,通过找到合并日志的最佳顺序,从而合并日志生成日志模式。如果有n 条日志,每条日志平均有t 个字段,则UPGMA 的时间复杂度为O(n2t2)。由于HLAer是单机算法,为了保证比较公平性,实验中,我们的算法也在相同配置的单机上运行。实验环境为Windows 7,64 位操作系统,内存8GB,硬盘500GB,CPU 为Inter(R)Core(TM)i5-4570 @3.20GHZ。采用四个不同的日志集,D1:2000 条Hadoop 集群日志,D2:2000 条jenkins 可持续集成系统的日志,D3:10000 条企业web 系统日志。D4:10000条企业计费系统日志。
实验二比较在单机与分布式平台下运行本文算法的时间,实验采用三个节点,每个节点的环境为Ubuntu16.04 操作系统,内存8GB,硬盘500GB,CPU 为Inter(R)Core(TM)i5-4570 @3.20GHZ。实验数据是按照时间顺序依次选取2000 条、5000 条和10000条Hadoop集群日志,以确保实验有效性。
实验三比较在不同个数的节点下运行算法的时间,实验环境与实验二相同,实验数据是10000条Hadoop集群日志。
实验中为了保证模式发现的准确性,默认将参数MaxDistance设定为0.1,MinSim设定为0.7。
3.2 评价指标
3.2.1 聚类的准确性
给定n 条日志数据S={L1,L2,…,Ln},利用OPTICS 算法进行聚类,得到r 个簇X={X1,X2,…,Xr},运行One-Pass 聚类算法,得到s 个簇Y={Y1,Y2,…,Ys}。OPTICS每个簇的日志条数为a={a1,a2,…,ar},One-Pass 算法每个簇的日志条数为b={b1,b2,…,b}s,记其中i∈1,...,r, j∈1,...,s,表示被放入在X 中第i 个类且在Y 中第j 个类的日志条数,那么,聚类的准确性定义为
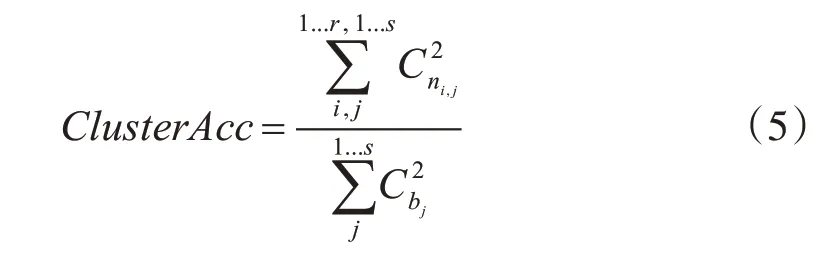
3.2.2 模式发现的准确性
我们通过OPTICS 和One-Pass 对日志数据进行聚类,然后给每个簇用UPGMA 和顺序合并的模式发现算法分别生成一个模式。我们逐个字段比较两个算法生成的模式。模式发现的准确性定义为
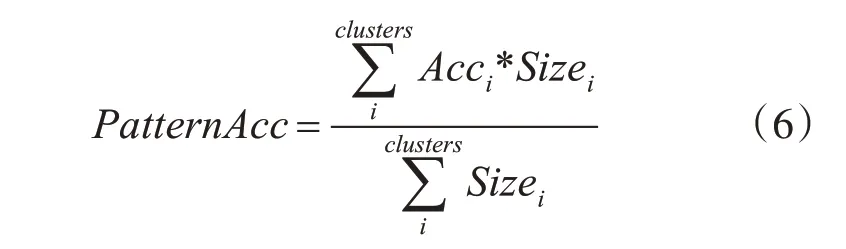
其中,Acci是第i 个簇的模式发现的准确度,是两个算法在第i个簇上生成的两个模式之间匹配成功的字段占所有字段的比率,Sizei是第i 个簇中的日志数量。
3.3 实验结果及分析
为了验证本文提出的One-Pass 聚类算法和顺序合并日志生成模式的准确性,快速以及内存高效,利用上述日志集做出了相关实验。
1)由表1可见,基于One-Pass思想的日志聚类和顺序合并的模式发现方法与HLAer的OPTICS及UPGMA 相比,在D1,D2 两个2000 条的日志集上聚类准确率高达98%以上,模式发现的准确率也在97%以上,在D3,D4 两个10000 条日志集上聚类准确率在96%左右,模式发现的准确率在94%左右,且内存开销远远低于HLAer,运行时间大约是HLAer 的10%。说明本文提出的算法准确、快速、内存高效。
2)由表2 可见,在不同规模的日志集上,采用三个节点搭建的Hadoop 分布式集群运行算法。当只有2000 条日志时,执行算法本身所需的时间不长,由于Map-Ruduce框架的开销,分布式环境相比单机来说,在运行时间上优势不明显;随着数据量的增大,分布式环境在执行效率上体现出了优势。
3)由图3 可见,在相同规模的日志集上,随着节点数目的增加,算法的执行效率也得到了相应的提高。但是,当节点数目超过8 个以后,执行效率提高的越来越少,由此可见,为了最大化资源利用率,需根据数据集的大小选择合适的节点数目。
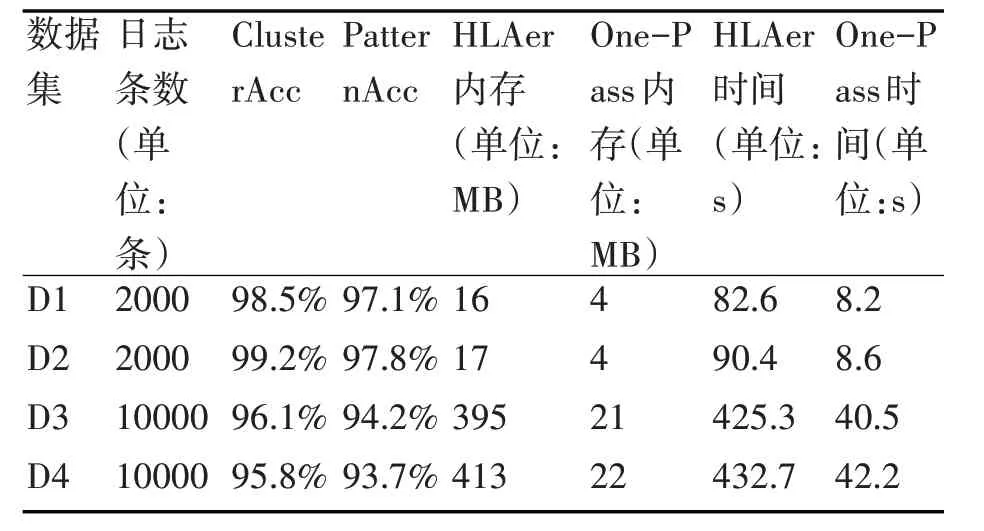
表1 单机版的顺序日志聚类和模式识别算法与HLAer算法比较

表2 单机与分布式环境下算法的运行时间(单位:s)
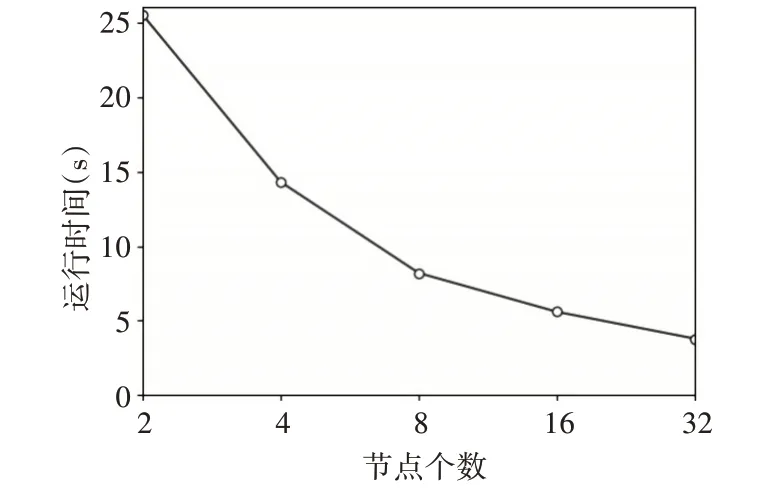
图3 不同个数节点的运行时间
4 结语
本文针对大量异构日志进行聚类和模式发现的主要挑战,根据日志数据的特点,提出了一种基于Hadoop 平台的日志模式发现方法,在四个不同规模的日志数据集上的实验结果表明了该方法在准确聚类和模式发现的前提下,内存开销和运行时间大大降低。该方法具有无监督、可扩展、快速,内存高效且准确的特点,可为企业处理大规模日志数据提供一种可行的解决方案。当然,在预处理阶段,对于大量异构日志,该方法仍然需要先验知识和人工干预,这个问题有待进一步的研究。
