野生大树茶种质资源的品质指标多样性分析评鉴
2020-09-30刘亚兵赵华富乔大河陈娟陈翔曹雨
刘亚兵,赵华富,乔大河,陈娟,陈翔,曹雨*
1. 贵州省农业科学院茶叶研究所(贵阳 550006);2. 习水仙缘红有限公司(习水 564600)
大树茶(学名:Camellia arborescens Chang et Yu)是经过长期的自然选择和人文环境选择下来的结果,主要分布在中国西南地区,具有良好的环境适应性、优良的茶叶品质及深厚的历史文化底蕴[1-2]。以大树茶为原料,加工后的茶叶给人们带来很多生理和保健益处,如止渴、消除疲劳、利尿解毒、防止龋齿等作用[3-4]。
贵州位于中国的西南地区,处于茶树的起源中心地带,境内分布着大量的茶组植物资源,但是因为长期以来经济发展的落后以及可利用土地资源的短缺,对这些丰富茶组植物资源的利用有限。但是,这些尚未开发的茶树资源为研究其遗传多样性、群体结构以及进化关系提供宝贵的资源[5]。特别是习水大树茶种质资源,在历史文化、经济、科研均具有较高价值,是贵州北部分布较广的、较原始的一个原生种,与茶树(Camellia sinensis)在分类学上同属一个组中不同的种[6]。多以半野生型和栽培型大树茶形式生长于我省北部山区,大树茶群落目前总体生长良好,当地农民采摘大树茶原料收获颇丰的经济效益,表现出极大的经济价值和开发潜力。近年来,有研究者对大树茶资源类型、地理位置分布、管理方式及生态环境进行描述,并对其水浸出物、茶多酚、氨基酸、咖啡碱等茶叶内合成分及儿茶素组分进行检测与分析[7]。也有研究者[8]对大树茶资源遗传多样性进行调查研究,因为大树茶资源长期缺乏人工驯化,其遗传多样性要高于人工驯化的栽培型。但是,对其应用还停留在初放的种质混制阶段,而针对种质个体特异性系统及加工后品质指标多样性评价研究还处于初步阶段[9]。
为加快大树茶资源的开发利用,试验通过收集习水的20份大树茶单株,分别测定其6个品质指标:水分、游离氨基酸总量、茶多酚、咖啡碱、表没食子儿茶素没食子酸酯(EGCG)及儿茶素总量,应用相关性分析、主成分分析、逐步回归分析方法建立加工茶叶综合评价指标的回归模型,探究模型拟合度及回归模型显著性,通过聚类分析法对20份大茶树单株进行差异性分析和多样性分析,对品质进行初步划分,分析单株差异对生化成分的影响,从而对品质进行评价,筛选出3个AAA级大茶树单株。所建模型可应用于实际大茶树品质评价,为筛选具有高品质的大茶树提供参考和借鉴,为中国茶产业的发展提供理论基础。
1 材料与方法
1.1 材料
采集原生于习水县境内的习水大树茶鲜叶(以单株作为鲜叶供给主体,形成单株制样;选取单株为对比个体,性状稳定;以一芽二叶或同等嫩度的对夹叶鲜叶为主,占比不小于95%)及其鲜叶原料制成的茶叶产品。
1.2 方法
1.2.1 样品处理
鲜叶→摊青(6 h)→杀青(230 ℃,3~4 min)→干燥(烘箱,85 ℃)→生化成分测定
1.2.2 品质指标测定方法
水分参照GB 5009.3—2016干燥法测定;游离氨基酸总量参照GB/T 8314—2013茚三酮比色法测定;茶多酚参照GB/T 8313—2018酒石酸亚铁比色法测定;咖啡碱参照GB/T 8313—2018紫外分光光度法测定;EGCG及儿茶素参照GB/T 8313—2018高效液相色谱法测定。
1.2.3 试验设计
选择习水境内不同大树茶单株的一芽二叶或同等嫩度的鲜叶为原料,经过绿茶制作工艺,经过摊凉、杀青后,直接烘干形成目标样品[10],处理后测定其水分、游离氨基酸总量、茶多酚、咖啡碱、EGCG及儿茶素总量等品质指标,对所得试验数据进行相关性分析、主成分分析、逐步回归分析方法建立大树茶综合评价指标的回归模型[11],选择拟合度较高、回归模型显著的品种。通过聚类法对20份单株品质进行初步划分,通过分析选择综合评分较高的3份单株作为AAA单株。
将水分定为100分,将其权重系数设为20;游离氨基酸总量越高越好,定为100分,设其权重系数设为15;茶多酚越小越好,茶多酚定为100分,设其权重系数设为20;咖啡碱值越小越好,定为100分,设其权重系数设为15;EGCG含量定为100分,设其权重系数设为15;儿茶素定为100分,设其权重系数设为15。

1.2.4 数据分析
采用SPSS 19.0 统计软件进行单因素方差分析(One-Way ANOVA),主持成分分析;采用Origin Pro 9.0进行聚类法。
2 结果与分析
2.1 不同品种大树茶品质的分析
由表1和表2可以看出,不同品种大树茶的品质成分含量差异明显,其中水分最高是品种2017-15,为10.58%,最低是品种2017-6,为6.69%;品种2017-3的茶多酚含量最高,为27.48%,最低是品种2017-7,为18.64%;游离氨基酸总含量最高是品种2017-5,为4.79%,最低是品种2017-9,为1.56%;咖啡碱含量最高是品种2017-13,为5.51%,最低是品种2017-6,为2.6%;EGCG含量最高是品种2017-3,为11.41%,最低是品种2017-12,为5.45%;儿茶素总含量最高是品种2017-6,为17.62%,最低是品种2017-7,为11.78%。因此,不同品种大树茶各品质差异明显。
将不同大树茶品种按1.2.1所示的加工流程制作成品茶。测定并分析不同品种特征指标,结果如表2所示。不同品种的最值差距明显,方差相对较高,表明不同大树茶加工的品质存在较大差异,不同品种各项品质指标影响方向不一致。

表1 不同大树茶单株的生化指标
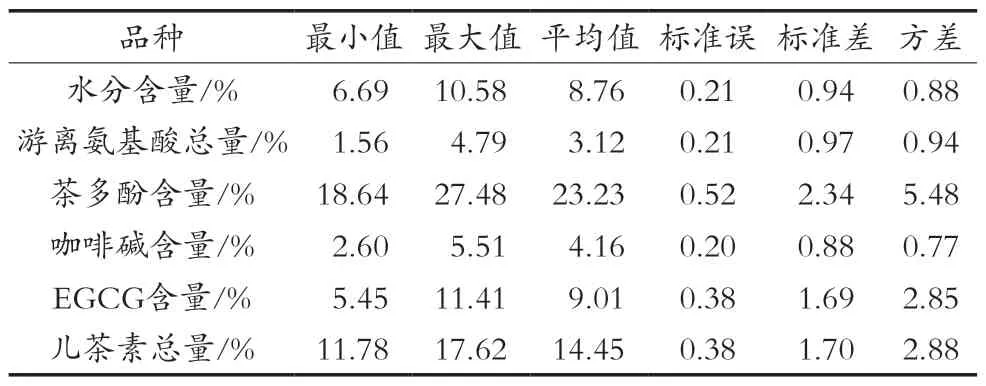
表2 不同大树茶单株品质的描述分析
2.2 不同大树茶单株品质指标的主成分分析
通过SPSS软件对20份大树茶单株的6个指标进行相关分析,结果见表3。通过相关分析表明,水分与茶多酚及儿茶素含量存在极显著的负相关,与咖啡碱含量存在正相关;游离氨基酸总含量与咖啡碱含量存在极显著正相关;茶多酚含量与EGCG含量、儿茶素含量存在极显著正相关;EGCG与儿茶素存在极显著正相关。由于各指标间相关关系的存在,易造成整体信息发生重叠,因此,有必要选取具有代表性的评价指标,消除变量之间相关性,降低评价负担。
为进一步讨论不同品种大树茶品质的贡献程度,采用因子分析和主成分分析法确定影响的主要因素[13],为评价大树茶品质提供依据。对6个指标进行主成分分析,得出评价因子特征值和累计贡献率,如表4所示。由于前2个主成分对应特征值均大于1,对应的累计方差贡献率为91.428%,故可选取前2个主成分,能较全面反映出不同大树茶品质的主要信息。

表3 不同大树茶单株品质的相关性 %

表4 评价因子的特征值和累计贡献率
2.3 主成分载荷矩阵、载荷图及特征向量
主成分载荷反映了各指标对主成分的贡献率的大小[14],其前2个主成分载荷矩阵见表5,由表5可知,第一主成分F1主要反映茶多酚(X3)、EGCG含量(X5)、儿茶素总量(X6);第二主成分F2反映游离氨基酸总量(X2)、咖啡碱含量(X4)和EGCG含量(X5)。

表5 初始因子载荷矩阵及主成分因子的特征向量
为了更直观地反映不同大树茶的品质,采用正交旋转法对大树茶品质所对应数据的主成分因子进行旋转,并计算各个指标的特征向量系数,结果见表5。根据表5的数据,建立主成分与不同大树茶品质指标之间的表达式[15]。
以大树茶水分含量(X1)、游离氨基酸总量(X2)、茶多酚含量(X3)、咖啡碱含量(X4)、EGCG含量(X5)及儿茶素总量(X6)为初始自变量,经过主成分分析,最终得出2个主成分因子的方程表达式如Z1~Z2所示,这2个主成分因子将原来6个品质指标作线性变换,重新组合成一组新的互相无关的综合指标,消除不同大树茶品质6个指标间的相关性,涵盖大树茶品质指标的大部分信息,可代替6个品质指标进行大树茶加工评价模型的建立。

2.4 大树茶品质指标归一化
经回归线性相关性分析,大树茶综合指标Y与大树茶水分相关系数为0.091;与游离氨基酸的相关系数为0.242;与茶多酚相关系数为0.395;与咖啡碱相关系数为0.454;与EGCG相关系数为0.438;与儿茶素相关系数为0.399;与主成分因子的方程Z1和Z2的相关系数分别为0.966和0.982;综合指标与各项大树茶评价指标在显著性水平为0.01上正相关,说明利用该方法得到的综合加工指标准确可靠。
2.5 大树茶品质评价模型建立
以2个主成分因子Z1和Z2为自变量,归一化后综合加工品质指标Y为因变量,采用逐步回归分析方法建立多元线性回归方程。设置进入值为0.05,移出值为0.1,即:如果一个变量的F值的概率小于0.05,那么这个变量将被选入回归方程中;变量的F值的概率大于设置的剔除值0.1,则变量将从回归方程中被剔除。由于自变量Z1和Z2与因变量Y的显著性的概率小于0.05,得到逐步回归方程[16]。

由模型系数表(表6)可看出,自变量显著性水平Sig.=0.000均小于0.05,说明自变量对因变量影响效果显著,存在显著线性关系。
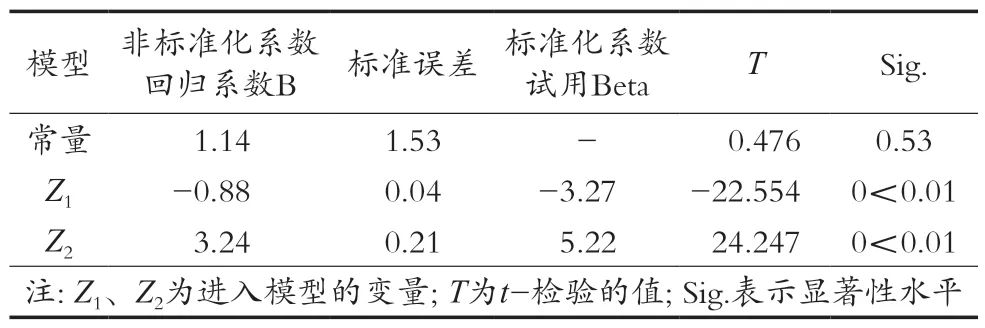
表6 大树茶综合品质评价模型系数
大树茶综合品质评价模型[17]的有效性是通过决定系数R2和F检验进行判断的。对模型进行效果汇总:回归模型的决定系数R2=0.999,调整后R2=0.999,随机误差估计值小,说明模型拟合度较高,能满足实际需求,使用模型评价大树茶综合品质有效。将Z1和Z2替换为初始自变量X1~X6,整理得大树茶片综合指标与不同品质的回归模型。

2.6 模型验证
分别选取20份大树单株茶样品验证回归模型效果[18],将20份单株的6个初始指标数据代入大树茶综合品质评价模型,得出品质综合指标预测值,将预测值与综合品质指标真值进行对比验证,得出的真值与预测值相关系数为0.991,显著性为0.014小于0.05,即在0.05水平上显著相关,说明大树茶综合品质评价模型能有效地预测大树茶的品质。图1为验证试验的真值与预测值散点图,样品点较集中分布在45°线周围,表明预测值接近真值,即通过测定不同大树茶的水分含量、游离氨基酸、茶多酚、咖啡碱、EGCG及儿茶素含量,就可以较准确地预测大树茶的综合品质。
2.7 不同大树茶单株综合指标评价
对20份大树茶单株综合评价指标进行排序,结果如表7所示。
采用K-means聚类算法[19-20]对20份大树茶单株综合指标进行聚类分析,设置k=3,聚类中心没有改动达到收敛时迭代停止,最终迭代次数为10,将20份单株的综合品质初步划分AAA、AA、A这3类(表8)。

图1 综合评价指标预测值与真值散点图
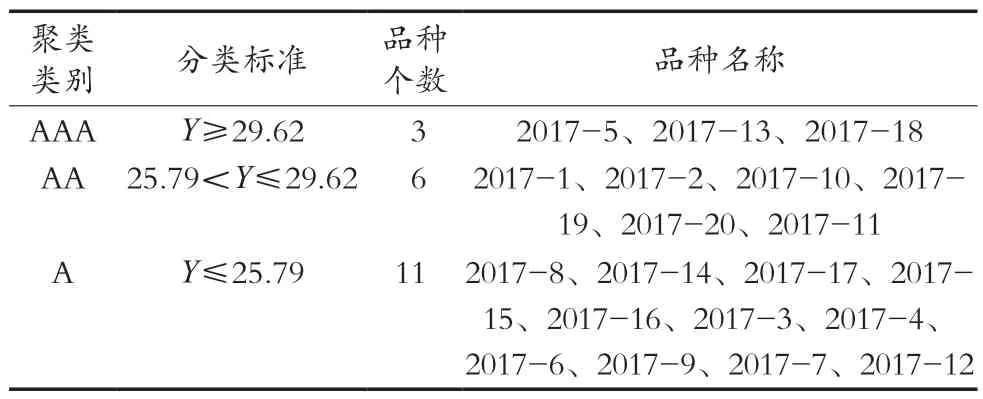
表8 20份大树茶综合品质指标分类
3 讨论与结论
试验收集了习水大树茶资源的20份大树茶单株进行制样,测定水分、游离氨基酸、茶多酚、咖啡碱、EGCG及儿茶素含量6项指标,对大树茶研究原料的6个主要品质指标进行主成分分析,得出2个主成分因子,从而消除原料各个指标间的相关关系,降低后期数据处理的冗余性;通过数据指标归一化方法[20]将大树茶各个指标转化为一组具有代表性的综合评价指标,并将综合评价指标Y与主成分因子(Z1~Z2)进行逐步回归分析,代入初始自变量X1~X6,整理得大树茶综合指标与6个品质的回归模型,回归模型的决定系数R2=0.999[22],调整后R2=0.999,随机误差估计值小,表明该模型可以较准确地预测未知样品的大树茶加工品质;预测值与综合品质指标真值进行对比验证,得出真值与预测值相关系数为0.991,显著性为0.014,小于0.05,说明回归模型能有效地预测大树茶加工后品质;应用K-means算法对20份大树茶单株的综合指标进行初步聚类,筛选出3个AAA大树茶单株,与实际应用情况相符。试验建立的大树茶品质评价模型效果显著,可应用于实际大树茶综合品质评价[23],后期将进一步扩大建模样品数量,探讨多样建模方法,以增强模型的适用性和精确度;此外,大树茶油综合品质K-means聚类的合理性和科学性需进一步探讨,综合品质分类依据及类别将今后研究中继续完善并验证。
