改进的基于冗余点过滤的3D目标检测方法
2020-09-29宋一凡宗立波刘立波
宋一凡,张 鹏,宗立波,马 波,刘立波
(宁夏大学信息工程学院,银川 750021)
0 引言
近年来,自动驾驶获得了学术界内外的广泛关注,众多学者投入到这一具有挑战性的任务当中。在自动驾驶中,3D 目标检测在其中发挥至关重要的作用,3D 目标检测的性能表现直接影响自动驾驶的可靠性。3D 目标检测需要在三维空间中标注出待检测目标的3D 边界框,这比2D 目标检测更具有挑战性,因为要考虑到目标的方向、空间位置、遮挡等空间因素[1]。深度学习在2D 目标检测中已经取得了令人瞩目的进展[2-6],如何将深度学习应用到3D 目标检测中成为了研究人员关注的中心。
很多学者将2D 目标检测框架扩展为3D 目标检测框架,由此出现了一大批基于图像的3D 目标检测算法。Gupta 等[7]将区域卷积网(Region with CNN feature,R-CNN)扩展后在RGB-D 图像中进行目标检测;Chen 等[8]提出的Mono3D 在单目图像中估计3D 边界框;3D 目标建议(3D Object Proposal,3DOP)[9]在立体图形中重构深度信息,并提出能量函数,通过最小化能量函数生成3D 候选区,组后通过R-CNN 对目标进行分类。目前,激光雷达已经成为了自动驾驶车辆的必备组件,因此越来越多的方法开始对激光雷达获取的点云进行处理。激光雷达获取的点云是一种3D数据,提供比图像更精确的深度信息,利用点云能够获取更精确的目标位置和物体边界,但是点云是一种不规则数据,并且具有高度稀疏性,因此不能直接用于传统的卷积神经网络进行特征提取。一些处理点云的方法是将点云转换为标准格式,全卷积车辆检测器(Vehicle detection from 3D lidar using Fully Convolutional Network,VeloFCN)[10]将点云投影到前视图,形成2D 图,再使用传统卷积网络进行处理;Vote3Deep[11]、3D 全卷积网络(3D Fully Convolutional Network,3DFCN)[12]、投票决策在线点云检测器[13]将点云转换为体素格,并对体素格进行手工编码。对点云数据进行转换,不能充分利用点云的3D 特性,最近,Qi等[14]提出了PointNet,直接利用点云进行目标识别和分割,改进后的PontNet++[15]增强了局部特征识别,在对点云进行直接处理的工作中,这两种方法非常具有启发性,为3D 数据的处理提供了一种全新的思路。基于图像的目标检测能够抽取非常丰富细致的纹理细节和高级语义信息,基于点云的目标检测能够精确地定位,基于两种方式结合的方法,会获得更准确的检测效果。多视角3D 检测网络(Multi-View 3D object detection network,MV3D)[16]同时使用RGB和点云进行目标检测,并且使用3D 区域生成网络(Region Proposal Network,RPN)生成3D 目标候选区域,并被认为是最早将RPN 方法用于自动驾驶方面的方法。
以上提到的算法,大部分都聚焦于点云的手工特征表达,人为地将点云转换为2D 结构,比如投影到鸟瞰图(Bird’s Eye View,BEV)平面或者前视图平面。如此做法虽然能够使用成熟的2D CNN 对点云数据进行特征提取,但是会损失部分点云数据的三维精度。针对这一问题,VoxelNet 模型[17]移除了人工特征工程,将点云的特征抽取和目标边界框预测同意在一个单独网络完成,是第一个端对端训练的通用3D目标检测深度网络。但是VoxelNet 使用完整的点云数据作为输入,增加了计算负担、耗费更多的计算资源在背景点云数据上,而且只包含几何信息的点云对目标的识别粒度较低,在较复杂的场景中容易出现误检测和漏检测。
本文在VoxelNet 的基础上进行改进,加入了视锥体候选区,首先使用2D 目标检测器在RGB 图像中得到的感兴趣目标的2D 边界框;之后根据点云雷达坐标与RGB 前视图像像素坐标的一一对应关系,将点云坐标映射至RGB 前视图中,提取出2D边界框内部区域的点云数据,过滤目标之外的冗余点;之后通过对精炼过的点云区域进行端对端的特征学习,对目标进行空间定位。改进算法大幅降低了点云数据处理数量,减少了对背景点的计算量。改进算法在KITTI 数据集[18]上训练并测试,结果和VoxelNet 相比,在简单、中等和困难模式下,鸟瞰图检测精度分别提高了3、10、11个百分点,3D检测精度分别提高了7、11、10个百分点。
1 相关工作
卷积神经网络一般要求输入数据符合某种标准模式,而点云数据是一种不规则格式数据。为了将点云数据作为深度网络的输入,大部分研究者都是将点云数据转换为标准的数据格式,但是这种方法会造成精度缺失。Qi 等[14]提出了PointNet,无需对点云进行规则化处理,使用深度网络直接处理不规则的三维点云数据,在点云的分类和实例分割任务中取得了良好的效果。后来,Qi 等[15]在PointNet 的基础上提出了PointNet++,利用分层结构处理局部特征,弥补了PointNet只考虑全局特征而忽略局部特征的缺陷,在对复杂场景中和表面纹理丰富的目标进行分类时能取得更好的效果。
PointNet/PointNet++在点云分类和目标实例分割中表现出色,但是在3D 目标检测中并不适用。为了提高PointNet/PointNet++的工作效率并能够解决目标空间定位问题,Qi等[19]提出了Frustum PointNets,引入了基于RGB 图像的2D 检测,通过2D 检测结果在空间中提取视锥体,之后使用PointNet/PointNet++分割目标实例,最后使用一个非模态边界框预测模型预测3D 边界框,使PointNet/PointNet++能够进行3D目标检测任务。
为了在高度稀疏的点云数据中使用CNN、RPN 这类在2D检测中取得不错成绩的网络结构,大部分研究者都是先将点云数据进行手工特征表示,将3D 数据转换成2D 表示,比如投射为鸟瞰图视角或前视图,这样虽然可以更好地兼容2D 方法,但是损失了3D 信息。Zhou 等[17]提出了VoxelNet,一种端对端训练的深度网络,无需对点云数据进行手工特征表示和转换,直接对点云进行体素化并编码,使用3D CNN 进行特征提取,和边界框预测都在一个阶段中进行。
Chen 等[16]提出的MV3D 网络,以激光雷达点云和相机RGB图像作为输入,将点云投影至鸟瞰图和前视图,使用卷积网络在RGB 图像、点云鸟瞰图和点云前视图中提取特征图,使用RPN 在鸟瞰图中得到候选区;之后将候选区映射至点云正视图和RGB 图像中,与3 个位面上的特征图形成各自位面的感兴趣区域;最后,通过基于区域的融合网络将3 个感兴趣区域融合,得到最终的检测结果。
Song 等[20]提了一种3D 卷积网络Deep Sliding Shapes,以RGB-D中的物体场景为输入,输出目标的3D边界框。此方法中,作者使用3D 区域生成网络(3D RPN)和联合目标识别网络(joint Object Recogniton Network,ORN)共同进行目标检测。3D RPN 以深度图为输入,生成所有目标的3D 候选区。对于每个3D 候选区,将深度图输入ORN 中的3D CNN,提取目标的几何特征;将RGB图输入ORN 中的2D CNN,提取图像特征。最后将几何特征和图像特征结合,用Softmax 分类器对候选区目标进行分类,以回归的方式预测3D边界框。
骆健等[21]基于稀疏自编码(Sparse AutoEncoder,SAE)和循环神经网络(Recurrent Neural Network,RNN)提出了多模态稀疏自编码循环神经网络(Multi-modal Sparse Auto-Encoder and Recursive Neural Network,MSAE-RNN)模型,从RGB-D图像中的RGB图像、深度图以及由RGB图像和深度图生成的灰度图和3D 曲面法线图分别抽取初级特征,并使用RNN 从初级特征提炼更加抽象的高级特征,最后将4 种特征融合为RGB-D 图像的最终特征,使用SVM 分类器进行目标识别。MSAE-RNN在RGB-D图像中的识别率达到了90.7%。
王旭娇等[22]在PointNet 模型中插入了一个K最近邻图层,在点云空间中构建K近邻图,利用图结构获取点云中点的局部信息,弥补了PointNet 忽略每个点局部信息的缺陷,有效地提高了整体点云分类的准确率,在ModelNet40 上准确率达到93.2%,比PointNet高4.0%。
2 本文算法
VoxelNet是一个通用的3D目标检测网络,在一个单一阶段的端对端学习网络中同时完成特征提取和目标边界框预测,并且不需要对三维点云进行特征工程方面的处理,在基于点云的3D目标检测中取得了突破性的进展。然而,点云也存在一定的局限性:首先,点云数据量很大,通常一帧点云数据包含大约100 000个点,而目标点只占其中的一小部分;其次,点云数据只包含几何信息,目标与背景的识别粒度低。这导致VoxelNet会进行大量冗余计算,而且受到背景点的干扰,会出现误检测和漏检测。受到Frustum PointNets的启发,本文在VoxelNet网络模型的基础上,加入了视锥体提取网络,同时利用RGB图像丰富的语义信息和点云精确的深度信息,提升VoxelNet网络模型的计算效率,并减少误检测率和楼检测率,提高目标检测精度。
平面图像的信息空间要远远小于立体空间,而且和激光雷达获取的点云数据相比,相机拍摄的RGB图形具有更加丰富的纹理细节和高级语义信息,因此基于RGB图像的2D目标检测在目标识别上的表现仍优于3D目标检测,在目标的分类上更为精准。本文提出的算法首先通过2D检测器在RGB图像中检测出目标的2D边界框,并将此2D边界框升维至空间视锥体,将视锥体之外的冗余点云移除,只保留视锥体内的点云,形成目标的3D搜索空间——视锥体候选区,如图1所示。在获取视锥体候选区后,使用VoxelNet仅对视锥体候选区内的点云进行处理,在精炼过的空间中进行3D目标检测,生成3D边界框。本文算法有效地减少了VoxelNet的搜索空间,提升了效率,有效地消除了在背景空间中生成3D边界框的误检测事件。
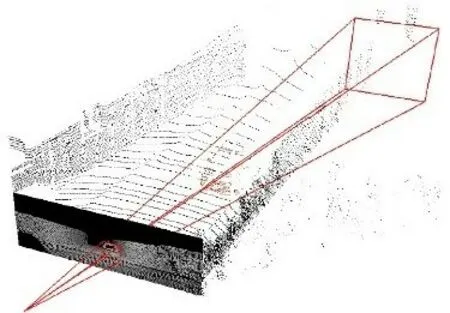
图1 视锥体候选区Fig.1 View frustum candidate region
2.1 视锥体候选区提取
首先利用2D 检测器在RGB 图像中获取目标的2D 边界框,并提取2D 边界框坐上角点的坐标(Xmin,Ymin)和右下角点的坐标(Xmax,Ymax)。之后根据已知的激光雷达坐标与相机坐标的对应关系,计算点云映射至相机平面的投影矩阵。激光雷达获取的点云使用激光雷达坐标系描述,每个点的空间位置使用空间坐标系(x,y,z)表示,与之相应的相机获取的RGB图像坐标为平面坐标(x,y),根据图2(a)所示KITTI 数据集规定的雷达坐标系和相机坐标系的方向规定,RGB 图像坐标和点云雷达坐标关系如图2(b)所示。
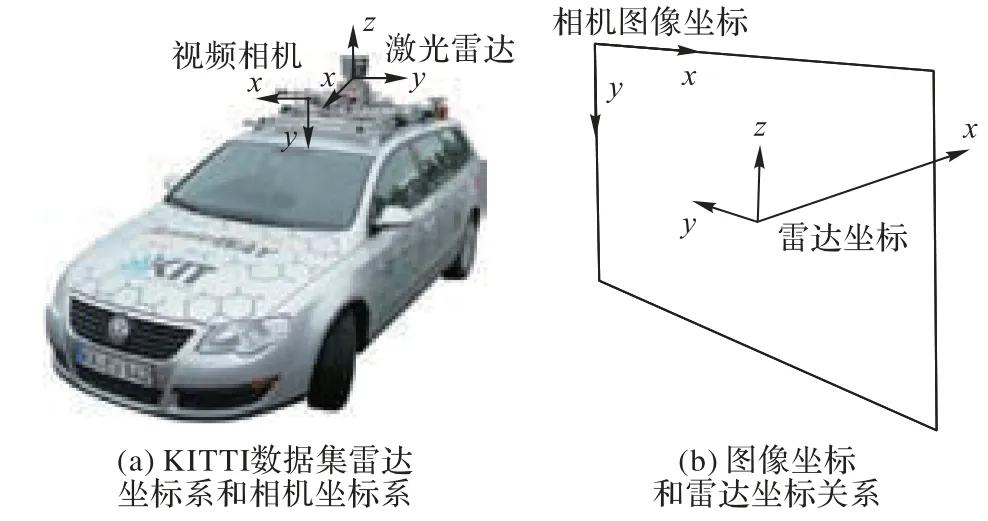
图2 图像坐标和雷达坐标关系Fig.2 Relationship between image coordinates and radar coordinates
激光雷达坐标系定义:相机平面几何中心为坐标原点,水平向左为y轴,竖直向上为z轴,平面向前法线为x轴。图像坐标系定义:图像左上为坐标原点,水平向右为x轴,数值向下为y轴。
点云中的每一个点,在相机前视图的RGB 图像中都有唯一的对应位置,因此RGB 图像和相应的点云之间有一个已知的映射关系,根据这个映射关系可以得知每一个点投影在RGB 图像中的位置,如图3。点云坐标投影至RGB 图像坐标的计算公式如下:
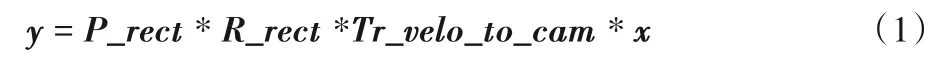
其中:x为雷达坐标系下的点云坐标;y为点云投影至RGB 图像中的平面位置坐标;P_rect是摄像机的投影矩阵,将矫正后的相机坐标投影至相机图像平面;R_rect是相机的矫正旋转矩阵,用于矫正相机;Tr_velo_to_cam是雷达坐标到相机的外参矩阵,用于将点云的雷达坐标投影至相机坐标系。
通过式(1)计算得到点云在RGB图像中的投影坐标P(u,v)后,与之前得到的目标2D 边界框角点坐标比较,计算出一个目标点矩阵T:
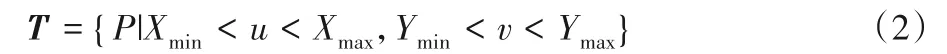
在得到目标点矩阵T后,计算视锥体候选区点云矩阵F:

其中:x是点云雷达坐标;yx是x所投影到RGB 图像上的坐标。最后,保留视锥体候选区点云矩阵F,得到只含有目标物体点云的视锥体空间,移除其他所有点云,完成冗余点的过滤。经过视锥体候选区提取后的点云空间大幅缩小,背景点和其余无关点被充分过滤,目标点云所占比重充分增加,原本每个场景的点云数据包含大约100 000个点,在经过视锥体候选区提取后,每个场景的点缩减到了至多1 000个左右,在目标数量较少的情况下,甚至达到100 个点以内,而且所包含的点基本都属于目标点,这样可以减少背景点云的干扰,提高检测精度,并且减少了对大量无效点的编码计算,提高了有效计算率。

图3 点云投影至RGB图像Fig.3 Point cloud projecting to RGB image
2.2 视锥体合并
在一个场景中,有时会有多个目标,甚至会出现目标重叠的现象。在Frustum PointNets 中,视锥体的提取以目标为单位,在多目标场景中,会生成和目标数量相同的多个视锥体,而且在由目标重叠时,不同的视锥体会包含相同的点云区域,这样不仅会使数据量增加,还会对相同的点进行重复计算。其次,Frustum PointNets 提取的视锥体点云是映射至矫正坐标系下的点,没有保留点云原始的空间结构,不能使用VoxelNet进行端对端处理。因此本文改进了视锥体提取方法,根据点云和前视图的坐标映射关系,直接提取视锥体中雷达坐标系下的点,之后把不同目标的点以矩阵的形式堆叠在一起,将相同的点合并,形成同一场景下的视锥体集合点云数据。
本文改进后的视锥体提取方法与Frustum PointNets 相比:1)保留了点云的原始空间特征,视锥体点云是原始点云的子集,无需改变点云的操作方式;2)将多个目标的视锥体点云融合在一个点云空间中,不会增加数据量;3)视锥体合并后,去除重复的点,避免了对相同点的重复计算。
2.3 体素划分编码
视锥体候选区生成完毕之后,将视锥体点云进行体素划分。体素格大小按照y、z、x轴方向设置为0.2 m、0.4 m、0.2 m,完整点云场景设置为宽80 m,高4 m,纵深70.4 m,此范围之外不考虑,因此整个点云场景按照y、z、x轴被划分为400、10、352 个体素格,每个体素格都包含一定数量的点,或者为空。由于使用了视锥体候选区生成网络,本文方法很大程度减少了点云搜索空间,体素划分之后,大部分的体素格为空,而且非空体素中的点大部分都是目标点,因此大大减少了对无用点的处理。只选取非空体素格进行编码处理,把非空体素格抽取出来,在其中随机抽取固定数量的点向量化,再将同一个体素中的点的特征向量用全连接层聚合成为表达体素特征的向量。此时,整个点云空间被编码成为一个体素特征向量空间,使用3D 卷积网络对体素特征向量进行卷积操作,聚合体素特征信息,增强体素特征的表达,形成体素特征图。之后,使用区域生成网络(RPN)以体素特征图为输入,生成目标3D 边界框。RPN 由3 个全卷积层和3 个反卷积层构成,在反卷积操作之后,得到一个高分辨率的特征图,之后使用两个卷积网络得到最终的检测结果,生成3D边界框。本文算法网络结构如图4所示。
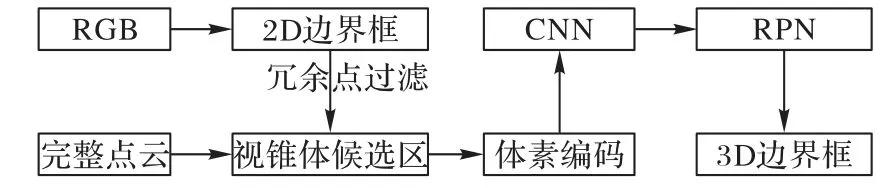
图4 本文算法网络结构Fig.4 Network structure of the proposed algorithm
3 实验结果与分析
本文方法在KITTI 目标检测基准上进行训练和测试。KITTI 数据集是一套面向自动驾驶的公开数据集,提供了7 481 个训练场景和7 518 个测试场景。每个场景都包含一个RGB 前视图、配准的点云数据和标签。由于测试集没有提供标签,所以本实验将训练数据重新划分为训练集和测试集。按照KITTI 的评价设置,本实验将在简单、中等和困难3 个难度场景下进行,分别测试3D 平均精度(3D Average Precision,3D AP)、鸟瞰图平均精度(Bird’s Eye View,BEV)和平均方向相似度(Average Orientation Similarity,AOS),并且和Mono3D、3DOP、VeloFCN、MV3D还有基准VoxelNet进行对比。
3.1 实验设置
训练数据5 000,测试数据2 481,训练epoch 设置为160,batch 设 置 为2。CPU 规 格Intel xeon E5-2620,显 卡Nvidia Quadro P5000,内存64 GB。依据KITTI 的官方标准,BEV、3D AP的交并比(Intersection over Union,IoU)阈值设置为0.7。
3.2 算法性能和检测结果对比
同样训练160回合,VoxelNet与本文方法的训练曲线如图5 所示。本文方法在训练时收敛性更好,且在所有困难度场景中3D AP和BEV AP性能更好。
VoxelNet 和本文算法在测试集上分别测试BEV AP、3D AP和AOS,测试结果如图6所示。
将本文方法的BEV AP、3D AP 与选取的基准算法进行对比。
BEV 检测结果对比见表1。本文方法在3 个难度等级都优于所选基准算法,和VoxelNet 相比,使用相同的RPN,也获得了不小的精度提升,简单、中等、困难3 个等级的检测精度分别提升了3.12、10.29、11 个百分点,表明本文提出算法所引入的视锥体候选区生成对检测结果有很大的提升作用,尤其在困难模式中效果提升显著。
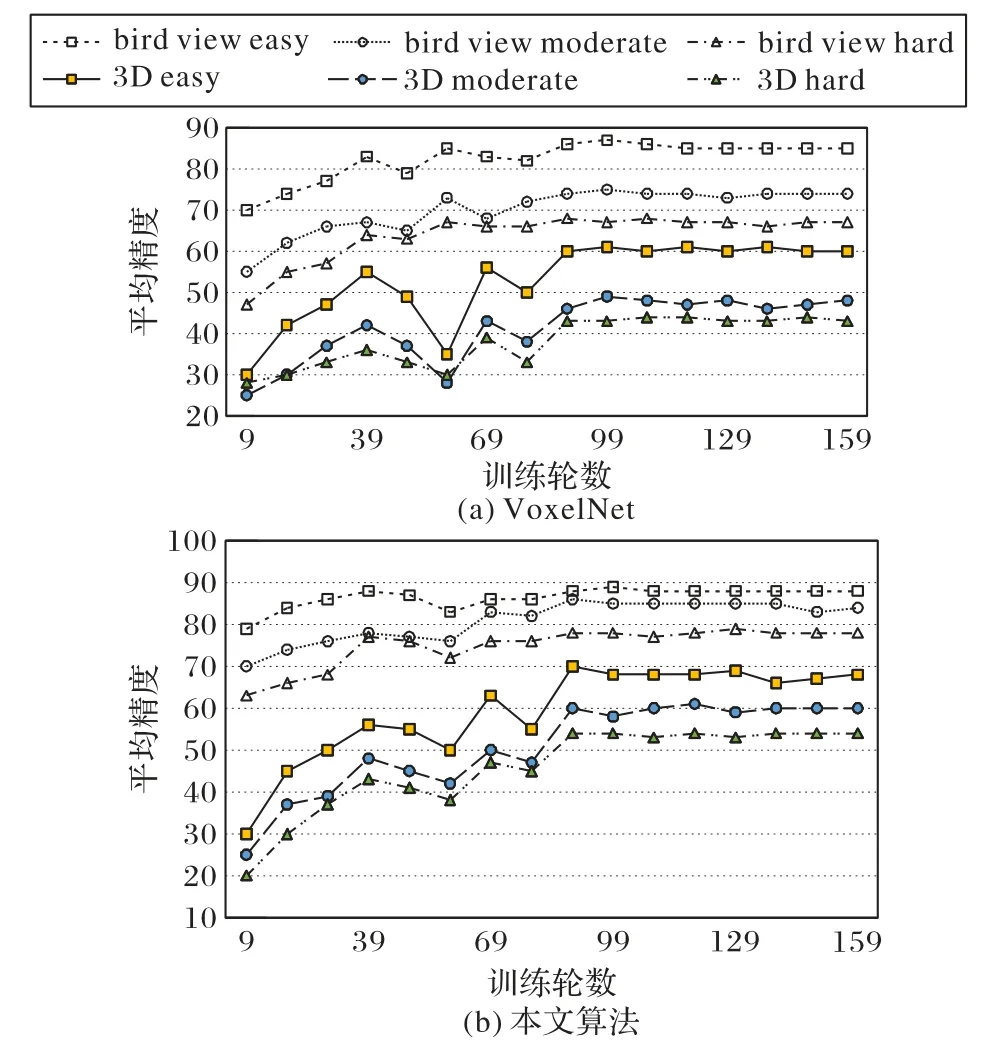
图5 VoxelNet与本文算法的性能对比Fig.5 Performance comparison of VoxelNet and the proposed algorithm
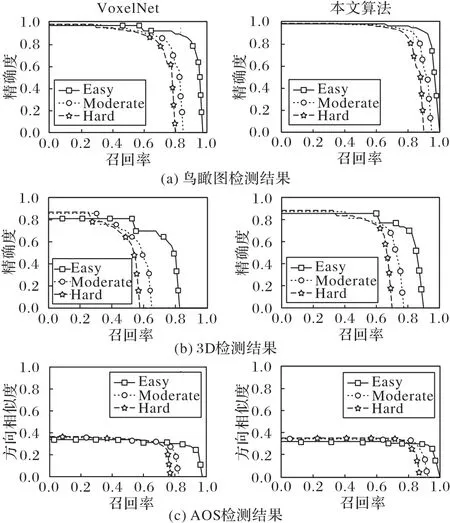
图6 VoxelNet和本文算法检测结果Fig.6 Testing results of VoxelNet and the proposed algorithm
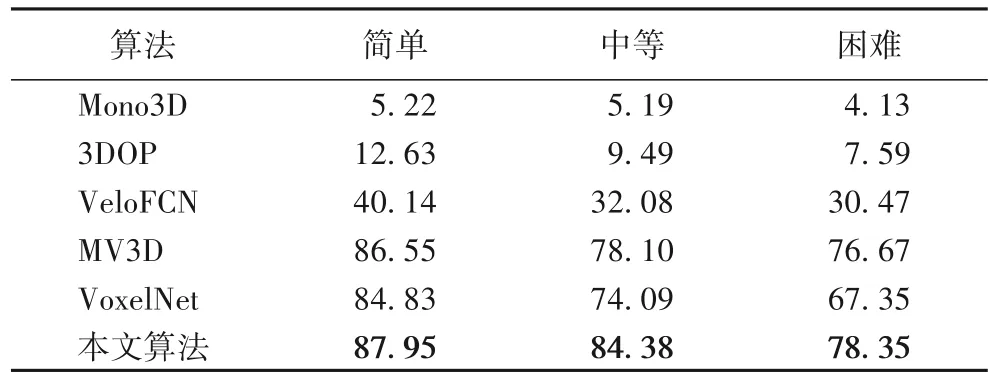
表1 BEV检测结果Tab.1 BEV detection results
3D AP 检测结果对比见表2。BEV 只检测平面上的位置准确率,3D AP 需要在3D 空间中检测到准确的3D 位置,因此更具有挑战性。本文方法在三个难度等级的3D AP 均超越MV3D 以外的基准算法,在简单和困难下略低于MV3D。和VoxelNet相比,每个难度下都有大幅提升。

表2 3D AP检测结果Tab.2 3D AP detection results
3.3 检测结果分析
视锥体候选区生成网络通过RGB 图像上的目标平面位置在点云空间中抽取高价值区域,缩小了3D 目标搜索空间,和完整点云空间相比,点数量缩小到了原有点数量的1/10 到1/100。完整点云空间和视锥体生成网络提取的视锥体候选区点云如图7所示,部分场景的点云数据完整点数量和过滤后的数量对比见表3。由表3可知,视锥体候选区过滤掉了大量的多余点,不仅有助于提高检测精度,降低误检率,还能明显减少计算量,提高计算效率。在训练过程中,本文方法处理一帧数据平均时间为0.78 s,VoxelNet则需要1.12 s。

图7 完整点云和视锥体候选区点云图对比Fig.7 Comparison between full point cloud and frustum candidate region point cloud
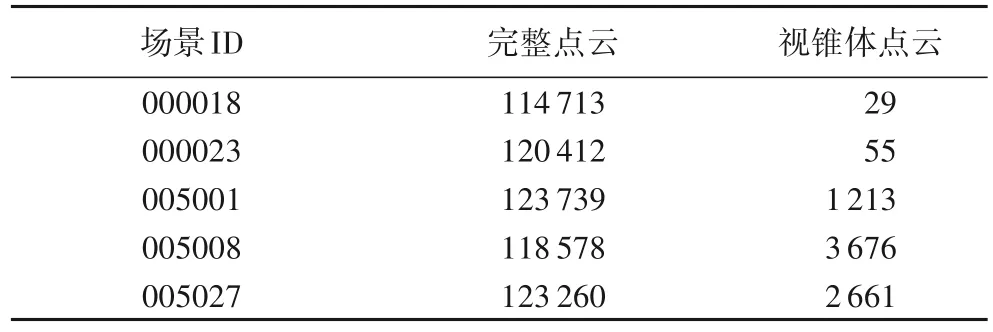
表3 点云数量对比Tab.3 Number comparison of point cloud
在测试集上测试后,将测试结果可视化,Ground Truth和检测结果见图8 中实例。鸟瞰图检测结果如图8所示,使用VoxelNet 的检测结果在部分场景中产生了大量的误检和漏检(图8(a)),本文方法有效地解决了这些问题(图8(b))。这是因为点云数据只有深度信息,不包含语义信息和纹理信息,基于点云的检测算法无法通过高级语义信息和纹理信息对正负样本进行区分,当负样本点的空间分布类似正样本点的分布时,非常容易产生误检测。此外,VoxelNet 对整个点云进行处理,而点云中大部分的点是非目标区域,这就造成了正负样本不平衡的问题,在训练调整权重时,被大量的负样本影响,又产生了漏检现象。本文提出的方法,引入RGB图像检测,通过语义信息在RGB前视图中检测出感兴趣目标,再根据2D检测结果在点云空间中抽取视锥体候选区,不仅缩小了搜索空间,还有效地过滤了负样本区域的点,只保留目标所在区域点云,解决了误检测的问题;同时,还解决了正负样本不平衡的问题,减少了目标漏检。在3D检测中结果中,本文方法所预测的3D边界框与Ground Truth也获得了更高的重合度,如图9所示。

图8 VoxelNet与本文算法的鸟瞰图检测结果Fig.8 BEV detection results of VoxelNet and the proposed algorithms

图9 VoxelNet和本文方法的3D检测结果Fig.9 3D testing results of VoxelNet and the proposed algorithm
4 结语
本文提出了一种基于冗余点过滤的3D目标检测算法,考虑到点云数据只包含几何信息,在目标识别准确率上仍低于基于RGB图像的2D检测,在VoxelNet模型的基础上加入了视锥体候选区,通过2D 检测器在RGB 前视图中锁定目标平面位置,并将2D位置升维至点云空间中的视锥体,得到包含目标点云区域的视锥体候选区,过滤冗余背景点云,缩小点云搜索空间。该算法模型减少了对多余背景点云的计算,提高了点云处理效率,并且通过高价值区域的选定,减小了误检率和漏检率。本文在KITTI数据集上的实验证明,通过缩小点云空间可以有效提升检测精度和工作效率,在简单、中等、困难3种模式下的评价精确率分别为67.92%、59.98%、53.95%,优于VoxelNet模型。另外,本文提出的视锥体候选区提取网络具有通用性,不会改变点云的原有属性和结构,理论上可以应用于任何以点云作为输入的检测框架。然而,使用视锥体候选区的检测方法有一点不足,如果2D 检测器在RGB 图像中发生漏检,该区域点云会直接被忽略,直接影响最终的3D 检测结果。另外,3D检测的平均精度和检测速度和成熟的2D检测器仍有不小的差距。提高视锥体候选区的生成质量和进一步提高3D目标检测的平均精度和检测速度,将是下一步研究的重点。
