基于SVR 模型的建筑空调系统能耗预测方法
2020-09-24丁伟翔倪岳通张莺
丁伟翔 倪岳通 张莺
浙江正泰能效科技有限公司
0 引言
随着建筑全生命期中的用能占社会总能耗的比率不断增加[1],对建筑能耗进行分析,预测为建筑低能耗的实现提供理论指导和评估依据,对提高建筑能源利用率具有重要意义。作为建筑能耗中占比最大的HVAC 能耗,其受到诸多因素的影响:气象、环境、围护结构、居住者行为、设备性能、控制策略等,是一种多因素、非线性交互耦合影响的结果[2],如式(1)所示,其复杂性使得难以准确预测。

选用合适的模型分析能源情况是值得研究的课题,一个有效且高效的模型一直是工程界寻求的目标。基于人工智能的模型在解决包括大量独立参数和非线性关系的复杂环境应用问题时具有很大的潜力,可以为建筑能耗预测带来创新性的技术[3-5]。与预测相关的使用最广泛的人工智能方法与高能力人工智能模型是支持向量机(SVM,Support Vector Machine)。SVM 模型是从历史统计数据中提取模型的一组方法,它们通常用于为输入与输出之间的复杂关系进行建模或发现数据中的模式。通过对模型进行训练和测试,挖掘数据中的有效信息,使模型具有高预测精度,是解决分类,回归问题最好的监督学习算法[6]。显然,对于建筑空调能耗而言,是一组随时间连续变化的值,预测能耗涉及到回归的问题。
支持向量回归SVR(Support Vector Regression)是支持向量在函数回归领域的应用。本文探究人工智能模型与建筑空调能耗预测,能源工程领域相结合的可行性。通过对历史能耗数据的挖掘与学习,训练并测试出相应的SVR 模型,用以预测该建筑未来的能耗,为人工智能在建筑节能领域中的应用提供参考。
1 SVR 模型建立过程
图1 展示了SVR 模型的学习过程:将所采集的历史统计数据分为训练集和测试集,统称为数据样本。两种样本均由目标值(逐时能耗值)与特征值(影响能耗值的变量因素)组成,即用以训练/测试模型的数据样本应有目标值和特征值的完整描述。在能耗预测模型中,所筛选的特征数应与能耗有较大的相关程度。具体步骤如下[7]:
1)首先,运用训练集,设置相关参数,完成对数据的学习,生成SVR 模型。
2)其次,将测试集中的特征值输入所生成的SVR模型中,输出通过该模型所得到的预测目标值。
3)再次,将预测目标值与测试集目标值(真实值)进行对比,评价该模型的性能。
4)最后,若所获得的模型通过评价达到合格,则可将该模型应用于实际。否则,调整优化模型参数设置,重新训练模型。
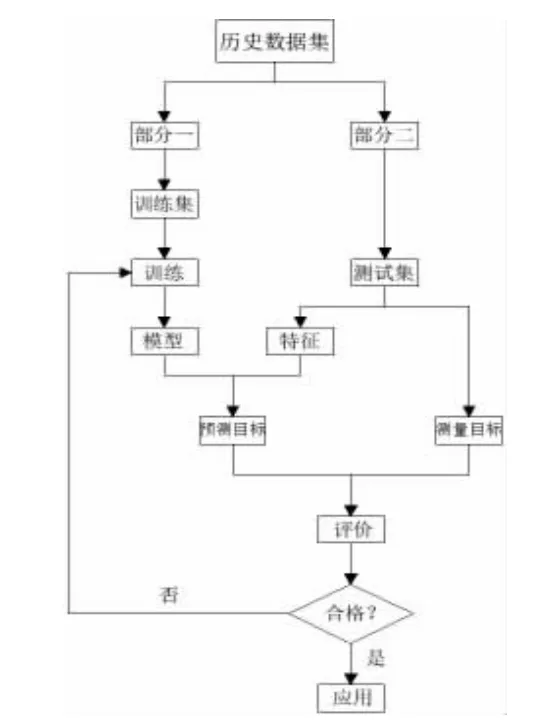
图1 SVR 模型开发及应用流程图
显然,拥有充足的样本数有助于训练模型精度的提升,充分和准确的能耗数据对模型的评价十分重要。因此,在训练模型之前,如何收集足够多的数据样本是模型开发的首要问题。通常的收集方法是通过安装于现场实地的传感器监测采集历史数据。然而,由于影响能耗值的因素较多,实际测量难以获取每个变量的逐时时间序列,造成数据颗粒度不足,且测量耗时长,可能出现测量误差。本文的主要目的是探究人工智能模型在能耗预测中的可行性,通过合理地设置与校准仿真软件,采用模拟的方法可以产生与实际很接近的数据[8]。此处采用DeST 能耗模拟软件,建立了一个虚拟的三维建筑模型,设置相关的边界条件,输出建筑内空调系统的逐时能耗及各个影响因素的瞬时值作为历史数据样本,即认为此时能耗模拟的数据就是真实数据。
2 建筑模型假设
现建立一个简易模型,为一栋位于杭州地区的三层办公楼(图2、3 为该建筑标准层平面图及三维建筑模型),围护结构热工性能均满足国家标准GB50189-2015《公共建筑节能设计标准》[9]。夏季室内制冷的空调系统采用风机盘管+新风的半集中形式,冷源为冷水机组,机组恒温出水(7 ℃),一次泵定流量运行。室内设计温度为26 ℃,空调开启时间为每日8:00-17:00。以8 月份整个月份的逐时能耗(此处的能耗为整个空调系统,包括了冷水机组+水泵+风机盘管+新风机组)作为研究对象——其中,1 日至25 日的能耗数据作为训练集(10×25=250 个样本)进行模型的学习,26 日至31 日的能耗数据作为测试集(10×6=60 个样本)以判断预测模型的精确度。

图2 标准层平面图

图3 三维建筑模型
DeST 能耗模拟软件对整个建筑及系统有完整的描述,如表1 所示。

表1 杭州某办公楼热环境外扰/内扰条件
仿真的过程如图4 所示。

图4 建筑能耗模拟过程
特征数作为变量是影响能耗的重要因素。特征数的选取极大地影响模型的性能,对于模型的开发而言是重要的。一般而言,所选取的特征数与目标值相关程度越高,预测就越准确。然而,并非特征数的数量越多越好,盲目追求提高预测精度会引发“维数灾难”(随着特征数的增加,计算量呈指数倍增长的一种现象)。合理地筛选最契合目标值的特征数,可以对模型进行简化,起到减少训练时间的作用[10]。此处给定了六个影响能耗的特征数,认为它们与能耗大小的相关程度较高,包括:室外温度、太阳辐射量、新风负荷、室内人员数、冷水机组回水温度、冷水机组COP,即这六个特征数构成了预测模型的支持向量(SV,Support Vector)。因此,建立SVR 模型过程的拓扑图如图5 所示。

图5 支持向量拓扑图
表2、3 为通过能耗模拟所得出的用作训练与测试的数据样本。数据集的每个样本都是以单位小时为时间序列的数值。基于训练集来表示目标对特征的依赖关系,产生高预测精度的高性能模型,而通过测试集来评价模型的预测性能。

表2 训练集样本
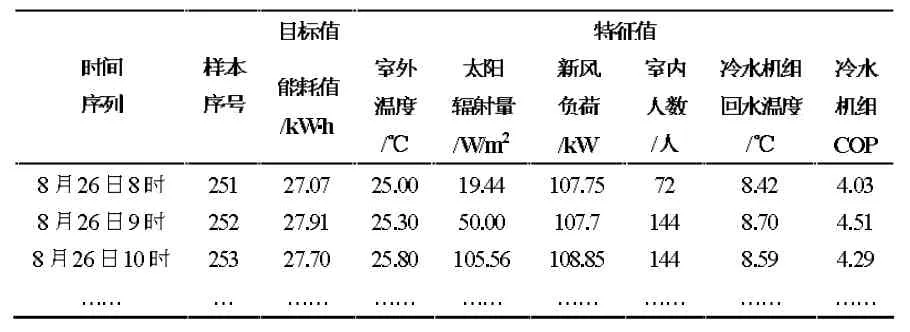
表3 测试集样本
进一步地设置相应的参数建立SVR 模型:支持向量机的类型选取ε-SVR。核函数的类型选取RBF 径向基函数,其易于使用且很好地解决了非线性问题。最好的模型参数应该具有很好的预测未知数据的能力而不会引起过拟合问题,由“循环遍历算法”计算所得的惩罚因子(表征对离群点的重视程度)C=10000,参数gamma=0.025。
3 预测结果分析评价
将测试集中的目标值(真实值,图中的蓝线)与训练出的SVR 模型所得出的预测值(图中的红线)绘制于同一曲线图中进行对比,数据样本是8 月26 日8 时至 8 月 31 日 17 时的总计 60 个样本(No.251~No.310)。采用式(2)“均方误差(MSE,Mean Square Error)(图中的绿线)”作为评价指标[11],判断经训练后的模型的准确性。
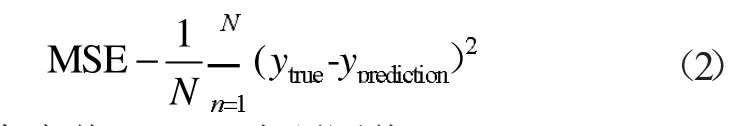
式中:ytrue为真实值,yprediction为预测值。
从图6 中可以看出,基于历史数据拟合出来的SVR 模型的预测性能非常好,测试集中的目标值与预测值十分接近。两者总体的均方误差MSE=0.015。此时,可认为所建立的SVR 模型合理,精确度达标。分析拟合程度如此高的原因:一方面,能耗值(目标值)与影响因素(特征值)之间的规律性极强,能耗对所选择的6 个特征数展示出很好的依赖性。另一方面,SVR 模型在数据挖掘方面的性能良好,泛化能力强,适用于能耗数据的回归拟合。
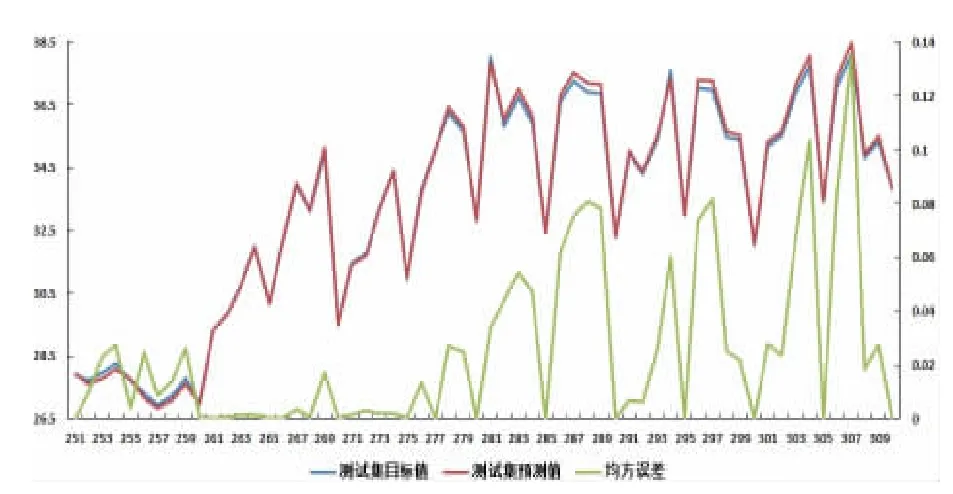
图6 真实值与SVR 模型预测值的对比结果
既然依据上述步骤,通过历史数据的训练集训练出了SVR 模型,又通过测试集验证了模型的精确性及可靠性。那么,此模型便可用以分析未来的某一特定条件下的能耗值。任意给定上述特征数的具体数值,便可以计算出在此种边界条件的描述下建筑空调的能耗。例如,现任意给定一组特征数——室外温度35 ℃,太阳辐射量200 W/m2,新风负荷100 kW,室内人员数100 人,冷水机组回水温度10 ℃,冷水机组COP 值5,则通过该模型预测的空调系统能耗为35.0876 kW·h。
4 结论
本文阐述了人工智能模型与建筑能耗预测两者相结合的可行性。针对模拟搭建的一栋位于杭州的办公建筑,通过模型的介绍,能耗的仿真,参数的设置,特征数的选取以及预测性能的评价等步骤,建立了关于该栋建筑空调系统能耗预测的SVR 模型,得出的结论如下:基于历史数据集训练得出的SVR 模型,挖掘了数据中的潜在信息。经测试后,其预测值与真实值的总体方均误差仅为0.015,模型的精确性合格,能够用于预测未知未来的能耗。可见,支持向量回归模型SVR 可以用来解决非线性、多影响因素的回归问题,即使少量的数据样本,只要模型选择和参数设置合理,可以提供非常准确的预测,为建筑能耗的预测与分析提供了一种方法与参考。
