Knowledge Graph Extension Based on Crowdsourcing in Textile and Clothing Field
2020-09-23CAIZhijian蔡志坚LIXinjie李欣洁TAORanSHIYouqun史有群
CAI Zhijian(蔡志坚), LI Xinjie(李欣洁), TAO Ran(陶 然), SHI Youqun(史有群)
1 College of Computer Science and Technology,Donghua University,Shanghai 201620,China2 College of Information Science and Technology,Donghua University,Shanghai 201620,China
Abstract: Generally,knowledge extraction technology is used to obtain nodes and relationships of unstructured data and structured data,and then the data fuse with the original knowledge graph to achieve the extension of the knowledge graph. Because the concepts and knowledge structures expressed on the Internet have problems of multi-source heterogeneity and low accuracy,it is usually difficult to achieve a good effect simply by using knowledge extraction technology. Considering that domain knowledge is highly dependent on the relevant expert knowledge,the method of this paper try to expand the domain knowledge through the crowdsourcing method. The method split the domain knowledge system into subgraph of knowledge according to corresponding concept,form subtasks with moderate granularity,and use the crowdsourcing technology for the acquisition and integration of knowledge subgraph to improve the knowledge system.
Key words: domain knowledge graph; knowledge fusion; crowdsourcing; visualization
Introduction
Knowledge graph is essentially a knowledge base called semantic network,that is,a knowledge base with a directed graph structure,where the nodes of the graph represent entities or concepts,and the edges of the graph represent various semantic relationships between entities and concepts[1]. Knowledge graph is a way of expressing knowledge,connecting different kinds of information together to get a relationship network. In the process of building a large-scale domain knowledge graph,how to continuously enrich the content,form an organic whole,and gradually expand to form a large-scale knowledge graph is a difficult and hot spot in current research.
Most of the existing knowledge extension methods adopt knowledge extraction technology to extract entities and relationships from unstructured data and structured data on the network and organize them in the form of knowledge graph. Knowledge extraction mainly studies how to extract the factual knowledge that matches the ontology from the content of documents without semantic information. Most current knowledge extraction technologies have the following problems: relationship extraction is difficult[2]; named entity recognition is difficult to identify vocabulary that expresses actions and relationships in text; universal language cannot cover vocabulary in the field[3].
Crowdsourcing mode is a distributed problem-solving mechanism through Internet disclosure. It uses the public crowd on the Internet to complete tasks that are difficult for small crowds to complete,and can solve problems to a certain extent[4]. This paper proposes a method using knowledge extension method of crowdsourcing technology to expand and update the domain knowledge graph in the field of textile and clothing by using group wisdom.
1 Related Work
1.1 Domain knowledge graph
At present,the research of knowledge graph has expanded from large-scale general knowledge graph to domain knowledge graph with specific industry characteristics. Scholars in different fields construct their domain knowledge graphs. Panetal.[5]proposed an ontology construction method based on the seven-step method and Methontology method combining with data characteristics of coal field to realize the core knowledge graph in the coal field. Feng[6]proposed a knowledge graph construction method for water conservancy object data to construct a knowledge graph for water conservancy information. Zhaoetal.[7]designed the military domain knowledge graph framework which was based on the open source data,and proposed the military domain knowledge graph construction method. Rowlingson[8]built the geographically oriented knowledge graph GeoNames. MetaBrainz Foundation[9]built the music-oriented knowledge graph MusicBrainz. There is a problem in the current domain knowledge graph construction methods. That is,the dynamic growth and update of the knowledge graph cannot be achieved,so it is difficult to form a large-scale knowledge graph.
Based on the knowledge graph of Donghua University’s research group and related technologies,the construction of the knowledge graph in the field of textiles and clothing research reveals the structured representation,data association and deep reasoning among knowledge in the field,and provides a theoretical framework for the knowledge organization in the textile and clothing field.
1.2 Swarm intelligence and crowdsourcing
Crowdsourcing technology is a research hotspot that currently realizes swarm intelligence. The idea of crowdsourcing is that using the Internet to gather group wisdom to solve practical problems. The initiator of the task publishes the task on the Internet for participants to choose,and the information interacts through the crowdsourcing platform[4]. Information interaction has promoted the combination and development of human intelligence and machine intelligence.
The main participants of crowdsourcing include task initiators and task finishers. As shown in Fig. 1,when the task initiator has a problem that cannot be solved,it can be solved through crowdsourcing according to the following steps: designing tasks,posting tasks on the crowdsourcing platform and waiting for answers. After receiving the answer,task requester chooses to accept or reject the answer submitted by task finisher,and organize the set of answers submitted.

Fig. 1 Workflow of crowdsourcing
For task finisher,the main steps for using a crowdsourcing platform include selecting tasks of interest,putting forward the own solution for this task and submitting a proposal.
1.3 Knowledge fusion
Knowledge fusion refers to the effective combination of different sources. The fusion process of knowledge graph can be divided into two parts: ontology alignment and entity matching,which respectively correspond to the conceptual layer and instance layer of knowledge graph. Lietal.[10]proposed an ontology alignment framework,which can achieve good results in the ontology alignment process with poor similarity. Jeanmaryetal.[11]proposed an ontology alignment algorithm based on semantic features,and calculated the semantic similarity based on the content and structural features of the ontology,thereby verifying the consistency of semantics between the ontology. Wangetal.[12]proposed an effective scoring algorithm for aligning the attributes of different physical cards.Songetal.[13]proposed a similarity calculation method for Chinese short text based on hybrid strategy,and proved through experiments that the method improved the efficiency of Chinese short text similarity calculation,which was more in line with people’s subjective judgment. The above knowledge fusion algorithms can achieve good accuracy on Chinese text,but they do not consider the association weight in the knowledge graph.
2 Knowledge Extension Model Based on Crowdsourcing
2.1 Related concepts
Concept1Knowledge point refers to the relatively independent and indivisible minimum knowledge unit with complete meaning[14]. Each node in the network structure of the knowledge graph can be used as a knowledge point.
Concept2Crowdsourcing task is a crowdsourcing task related to a knowledge graph published by the task requester,and is usually defined in the form of the following quadruples,recorded as
Concept3Worker is the crowdsourcing participant,combined with the research content of this article. A worker is an individual who participates in constructing an individual knowledge graph and completing the crowdsourcing task.

2.2 Knowledge update framework
Connectivism emphasizes that learning is no longer an individual activity,and that learning is the process of connecting nodes and information sources. Under the guidance of this theory,the idea of updating the knowledge graph is shown in Fig. 2. By pooling a lot of knowledge that contains individual wisdom,the subgraph is fused into a group knowledge graph containing group wisdom and integrated into the original knowledge graph to achieve the dynamic extension and update of the knowledge graph.

Fig. 2 Idea of updating the knowledge graph
The extension process is divided into three important steps as shown in Fig. 3.

Fig. 3 Extension process
The first step of knowledge update is the acquisition of individual knowledge subgraph. First,select a number of keywords in the field as the initial crowdsourcing task. Then,the workers perform the crowdsourcing task and construct individual knowledge subgraph based on the keywords and individual understanding. Finally,before the end of the task,the knowledge subgraph is improved and the constructing process of the knowledge subgraph is iterated.
The second step is the fusion of knowledge subgraph. First,preprocess the data of the acquired knowledge subgraph set to remove noise. Then,perform entity matching based on the semantic information of the nodes,fuse the same nodes. Finally,calculate the knowledge correlation weightiness based on the adjacency matrix and subgraph weightiness,construct a knowledge correlation weightiness matrix,realize the fusion of knowledge subgraph through matrix operations,and generate a group knowledge graph.
The third step is to import the group knowledge graph into the graph database,and use D3.js visualization technology to visualize the knowledge graph and provide knowledge services.
2.3 Knowledge subgraph acquisition
This research group has constructed a data acquisition prototype system in the field of textiles and clothing. Using crowdsourcing,the task publisher releases time-bound tasks within a specific range in the system. Workers build knowledge subgraph within the specific range based on the knowledge they have acquired and added their own understanding. In the process of constructing the subgraph in stages,as workers deepen their understanding and cognition of domain knowledge,workers complete and update the knowledge subgraph,and iterate the knowledge subgraph construction process until the end of the mission. Finally,the individual knowledge subgraph setGwas obtained. By crowdsourcing,the Internet was used to obtain a large number of original knowledge resources containing individual wisdom.
The acquisition of crowdsourced knowledge subgraph mainly includes two steps.
(1) Crowdsourcing task release. Select the number ofnmeta-knowledge points from the defined domain knowledge system and publish them to the crowdsourcing platform as a crowdsourcing task,where meta-knowledge points are data such as concepts,terms,instances in the knowledge system.
(2) Crowdsourcing task execution. A crowdsourcing participant selects one of the knowledge points for knowledge association,and adds node information associated with the knowledge point,including structural information and semantic information. The structural information indicates the connection between nodes,semantic information represents the node description text carried on each node. Crowdsourcing participants can organize their knowledge into a structural computer-understandable knowledge subgraph.
Multiple crowdsourcing participants continue to iterate the above two steps,and finally multiple knowledge subgraph can be obtained,which collectively form an individual knowledge subgraph setG={G1,G2,…,Gi}.
2.4 Knowledge subgraph fusion
Knowledge subgraph fusion refers to the process of integrating inaccurate and incomplete knowledge subgraph autonomously constructed by workers into a completer and more standard knowledge graph through preprocessing. The knowledge subgraph constructed by the majority of workers is obtained through crowdsourcing. After that,the original knowledge resources are refined and fused into a group knowledge graph. The main steps include: data preprocessing,entity matching,and adjacency matrix fusion.
2.4.1Datapreprocessing
In the original knowledge subgraph obtained through the crowdsourcing mode,problems such as spoken language and irregular expression may occur. These data are noisy to the fused group knowledge graph. Therefore,we need to preprocess the subgraph before the knowledge subgraph is fused.
Knowledge subgraph setG={G1,G2,…,Gi}. includes node setV={V1,V2,…,Vm}. and node description text setT={T1,T2,…,Tm},where the elements in the setsVandTare one-to-one correspondence. First,perform word frequency statistics on each node in the node setV,filter the nodes with low word frequency,and obtain the node setV′ and text setT′. Then,the nodes setV′ is compared with a large-scale lexicon,and the intersection with a large-scale lexicon was taken. Since large-scale lexicons are usually more authoritative in the industry,and their vocabulary is more comprehensive,this operation can filter out noisy words in the node set. Finally,after the above series of operations,the simplified node set is obtainedV″={V1,V2,…,Vn},and text setT″={T1,T2,…,Tn}.
2.4.2Entitymatchingbasedonshorttextsimilaritycalculation
Entity matching is the process of determining whether two entities in the same or different knowledge subgraph point to the same object in the natural world[15]. Due to the knowledge differences between workers,for the same noun,different descriptions may appear in the knowledge subgraph set. It is necessary to calculate the similarity of description texts between the nodes and to achieve entity matching between knowledge subgraph.
Vectorize the node’s description text and use term frequency - inverse document frequency (TF-IDF) which is a word frequency statistics technology to calculate the text similarity. The core idea is that a word appears more frequently in a text,while fewer in all texts,the better it can represent the text,that is,TF-IDF can extract the keywords that can represent the text information. Specifically,given a description text datam,the calculation formula of the TF-IDF of the wordwiis
Twi,m=twi,m×iwi,m,
(1)
where,twi,mrepresents the ratio of the frequencyXwofwiinmand the ratio of the frequencyXmof the most frequent words,namely as
(2)
whereiwi,mrepresents the inverse document frequency,reflecting the importance of the word in this article,and its expression is
(3)
whereMrepresents the total number of description texts,Mwrepresents the number of description texts with the wordwi,andMw+1 is to prevent the situation where the denominator is 0.
Through TF-IDF,we can know the key information that most represents the descriptive text,and can reflect the relevance of the text. The word frequency extraction can construct each descriptive text vector,namelyX(w1),X(w2),…,X(wn). After vectorizing the description text of each node,the cosine similarity is used to calculate the similarity between the texts. The cosine similarity calculation formula is as follows:
(4)
where vectorAi={X(wi1),X(wi2),…,X(win)},vectorBi={X(wi1),X(wi2),…,X(win)}。 The greater the value of similarity,the more similar the entity information described by the text is
With the above methods,the similarity between entities can be calculated according to the description text information of the entities,thereby establishing a semantic connection relationship between nodes.
2.4.3Knowledgeassociationadjacencymatrixfusionmethod
After the data preprocessing,an effective knowledge subgraph set is obtained; and after entity matching,a more accurate knowledge subgraph set is obtained through the semantic information of the nodes; quantification is realized through knowledge point association. This paper uses the adjacency matrix to fuse the structural information of the nodes. The matrix fusion process specifically includes the following steps.
(1) Convert knowledge subgraph to adjacency matrix formMk,and the calculation formula is

(5)
where,if there is edgeei,jin graphGk, the adjacency matrixMkinMk,i,jis 1 and vice versa is 0.
(2) Calculate the semantic relevance of nodes to get the semantic correlation matrixA,the calculation formula is as follows
Ai,j=Si,j.
(6)
(3) Calculate the weightiness of knowledge association. The weightiness of knowledge association reflects the degree of correlation between nodes,and calculate the edge weightiness of knowledge points by counting whether two nodes exist in multiple knowledge subgraph and the weight of the subgraph.
(7)
where,MW,Gk,vi,vjrepresented the weightiness of the association between nodeviand nodevjin the knowledge subgraphGk,and can be calculated,based on the adjacency matrixMk;MW,vi,vjrepresents the magnitude of the correlation weightiness between nodeviand nodevjafter the fusion of knowledge subgraph;WGkrepresents weightiness of knowledge subgraphGk. The matrix fusion method can be expressed by the pseudocode as shown in Fig.4.

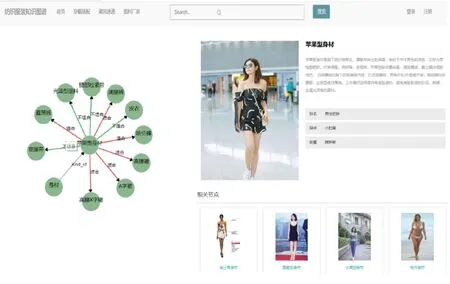
Input:knowledge subgraph G1, knowledge subgraph G2Output:fused matrix MFInitialize parameter:i, j, n1: for (i←0;i Fig. 4 Matrix fusion algorithm Figures 5 and 6 are obtained through crowdsourcing knowledge subgraph constructed by two different users and preprocessed with data. Fig. 5 Knowledge subgraph 1 Fig. 6 Knowledge subgraph 2 Knowledge subgraph 1 and knowledge subgraph 2 are converted into the form of adjacency matrix after entity matching,such asM1andM2. The correspondence between symbols and entities is thatv1means cotton,v2means jute,v3means fabric,v4means corduroy,v5means flax,v6means hemp,v7means raw material,v8means wire,v9means kenaf,v10means cotton blend. Calculate semantic correlation matrixAby Eq.(5),perform weighted summation the matricesM1andM2according to Eq.(7). Assuming the initial weightiness of the two subgraphs are 0.5 respectively,we can get From the calculation,adjacency matrixMWis derived. The edge weightiness of the knowledge graph generated by the fusion of the knowledge subgraph 1 and the knowledge subgraph 2 can be obtained. Adjust the value ofMWaccordingAto getMF,And the topological structure of the fused knowledge graph can be drawn according toMF,as shown in Fig. 7. Fig. 7 Fusion knowledge graph This chapter presented a knowledge extension model and elaborated on it in detail. Afterwards,this chapter applied the proposed knowledge extension model,explained the detailed steps of acquiring and subscribing knowledge subgraph using fabric as an example,and demonstrated the knowledge extension effect of the model. In order to verify the rationality of the triples contained in the knowledge graph,this paper uses the following methods to evaluate and analyze the constructed domain knowledge graph. In terms of the degree of knowledge node association,the knowledge correlation weight results obtained in the knowledge graph are compared with the large-scale knowledge base How-Net. How-Net is a knowledge base that uses the concepts represented by Chinese and English words as description objects,and reveals the relationships between concepts and the attributes of concepts as the basic content[16]. How-Net is an important resource in the field of natural language processing,which contains rich semantic relationships and is constantly being improved and updated. Through the knowledge fusion strategy proposed in this paper,the knowledge association weightiness among the knowledge points in the group knowledge graph are calculated. In order to evaluate the constructed group knowledge graph,this section compares some knowledge association weightiness with the semantic calculation based on How-Net as shown in Table 1. Table 1 Comparison results with How-Net It can be seen from Table 1 that the knowledge association weights calculated by the method in this paper is in line with people’s intuitive feelings and professional characteristics. Among them,for knowledge points with large weights of knowledge association,such as “身材”and “体型”,the importance of knowledge association means that when constructing a knowledge subgraph,the constructor can easily associate these two knowledge points together. When it comes to “身材”,the concept of “体型”is often mentioned. For knowledge points with relatively low weight of knowledge association,such as “棉”and “丝”,the weightiness of knowledge association is 0.4,indicating that in the knowledge system of scholars in the field of textile and clothing,the two concepts of “棉”and “丝”are not high in semantic similarity. For knowledge points with a knowledge association weightiness of 0,such as “面料”and “材质”,it means that there is no direct connection between these two concepts in the field of textile and clothing. For the calculated knowledge association weightiness and the vocabulary semantic similarity results based on How-Net,we can find that the knowledge correlation weightiness are basically consistent with the results of How-Net,indicating that these knowledge points are similar to the conceptual semantics in the field of textile and clothing. However,some knowledge related weights are inconsistent with the results of How-Net,such as “纽扣”,“拉链”,“风格”and “设计”. In the knowledge base of How-Net,“纽扣”and “拉链”belong to the same knowledge “衣物部件”,so the similarity is high. But in the field of clothing design,“纽扣”and “拉链”belong to different style concepts,so the similarity is low. For “风格”and “设计”,the two words have different parts-of-speech. One is a noun and the other is a verb. Therefore,the similarity calculation result in the How-Net knowledge base is very low,but the correlation between these two concepts is relatively high in the field of textile and clothing. In summary,after comparing with the calculation results of How-Net,it can be found that the knowledge association weightiness calculated by this method is reasonable. The knowledge subgraph setSobtained through crowdsourcing is preprocessed,instance matched,and knowledge subgraph fused according to the above methods to obtain the logical structure of the group knowledge graph. This section uses a Neo4j graphical database to store the acquired data. The back-end system uses cypher statements to interact with the database,then uses D3.js to draw the corresponding knowledge graph on the front-end page,and provides the knowledge service retrieved by users on this basis. Figure 8 shows the content of the knowledge graph in the field of textile and clothing. The nodes represent the acquired knowledge points,and the edges between the nodes represent the associations between the knowledge points. Fig. 8 Knowledge graph in the field of textile and clothing Figure 9 shows the search results for “ apple shape figure ”in this system. Fig. 9 Search results of “apple shape figure” This chapter analyzes the constructed knowledge graph. By comparing the similarity calculation results based on How-Net,the knowledge fusion algorithm proposed in this paper is evaluated. This paper proposes a method of knowledge graph extension using crowdsourcing technology,which is elaborated in detail and applied to the construction of knowledge graph in the field of textile and clothing. By comparing the word similarity to How-Net,we found that this method can effectively calculate word similarity. In this method,first different knowledge subgraphs are obtained through crowdsourcing,and the short text vector of the node is constructed with the TF-IDF word frequency statistics technology. Then,the entity matching between knowledge subgraph is achieved by calculating the remaining cosine similarity. Finally,the final fusion of knowledge subgraph is achieved based on the knowledge association weightiness matrix operation.



3 Analysis and Application
3.1 Knowledge graph analysis

3.2 Graph visualization

4 Conclusions
猜你喜欢
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Recent Progress for Gallium-Based Liquid Metal in Smart Wearable Textiles
- Accident Analysis and Emergency Response Effect Research of the Deep Foundation Pit in Taiyuan Metro
- Effect of Elastane on Physical Properties of 1×1 Knit Rib Fabrics
- Analysis on the Application of Image Processing Technology in Clothing Pattern Recognition
- Clothes Keypoints Detection with Cascaded Pyramid Network
- Encryption and Decryption of Color Images through Random Disruption of Rows and Columns