基于主题挖掘和情感分析的“新冠肺炎疫情”舆情分析研究
2020-09-15杨秀璋武帅夏换于小民
杨秀璋 武帅 夏换 于小民
摘要:针对“新冠肺炎疫情”热点新闻和话题,提出一种基于主题挖掘和情感分析的舆情分析方法。通过Python抓取2020年1月20日至3月22日期间共计1389篇人民网的疫情新闻,利用数据预处理、特征词提取、词云可视化展现与“新冠肺炎疫情”相关的热点主题,再采用共词分析、LDA模型、知识图谱和情感分析算法挖掘舆情演化趋势。实验结果表明,此次肺炎疫情的情感呈现积极状态,热点主题包括疫情、防控、医院、工作、服务等。该方法能有效挖掘舆情事件的主题,具有一定的应用前景和使用价值。
关键词:主题挖掘;情感分析;新冠肺炎疫情;知识图谱
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2020)08-31-06
0 引言
2019年12月,湖北省武汉市开始出现多起不明原因引发的肺炎病例,后证实是由一种新型冠状病毒(2019-novel coronavirus,2019-nCoV)感染所致,以下简称新冠肺炎[1-2]。2020年2月ll日,世界卫生组织宣布将新冠肺炎命名为“COVID-19”[2]。
新冠肺炎疫情的不断扩散,给全国社会经济发展带来了巨大挑战,同时以网络平台为主的新闻报道及社交论坛引发了社会的广泛关注。随着感染人数和疑似人数不断增加,互联网中相关的热点新闻及话题呈爆炸式增长。如何利用计算机方法和数据分析算法准确地识别热点新闻和疫情主题,分析群众的情感动态,挖掘民众关注的话题,已成为数据分析人员的重要研究议题[4]。本文提出一种基于主题挖掘和情感分析的“新冠肺炎疫情”舆情分析方法。 近些年,国内外学者致力于舆情分析研究,并提出了相关分析方法。赵雪等[5]使用词共现网络的方法对中国乡村之声官方微博信息进行舆情分析,识别出热点话题主要为农业经济信息和农民民生。李建新[6]通过构建BPOAS-MSW模型,建立系统的言论模式。何梦娇等[7]借助SVM模型对交通舆情主题进行分类,基于Apriori算法分析关键词隐含的交通规则,再利用共现网络分析交通问题与时间的变化规律。王心瑶等[8]通过内容分析法对微博信息进行归类、情感值计算以及转发路径分析。谢修娟等[9]提出一种基于密度的K-Means初始聚类中心算法,解决初始聚类中心选取到孤立点易导致聚类结果局部最优的不足。武帅等[10]运用数据可视化及情感分析的方法对巴黎圣母院火灾事件的舆情信息进行分析。张翼鹏等[11]提出一种改进的细菌觅食算法,将网页相关数值作为测量网页热度的度量,从而建立热度评价模型,得到了更好的聚类效果。陈兴蜀等[13]对“新冠肺炎疫情”相关的话题展开舆情分析,可视化地展现本次疫情事件中网络舆情的时空演化过程。林永明[13]踟提出了一种舆情文本的动态主题情感模型,能够有效刻画公众所关注的话题及其情感变化,且效果显著。
针对“新型肺炎疫情”热点新闻和舆情话题的主题及情感难以辨别的问题,本文提出了一种结合主题挖掘和情感分析的舆情分析方法。本文的实验数据集为2020年1月20日至3月22日期间在人民网发布的疫情相关新闻,共计1389篇。利用数据预处理、特征提取、词云可视化技术挖掘目标数据的热点主题,再采用共词分析、LDA主题模型、知识图谱和情感分析算法对目标数据进行分析,挖掘舆情主题演化趋势。最终得出该时间段的疫情相关新闻数据的总体情感趋向,各时间段的核心主题,以及随时间变迁的主题演化过程和知识图谱。
1 研究方法
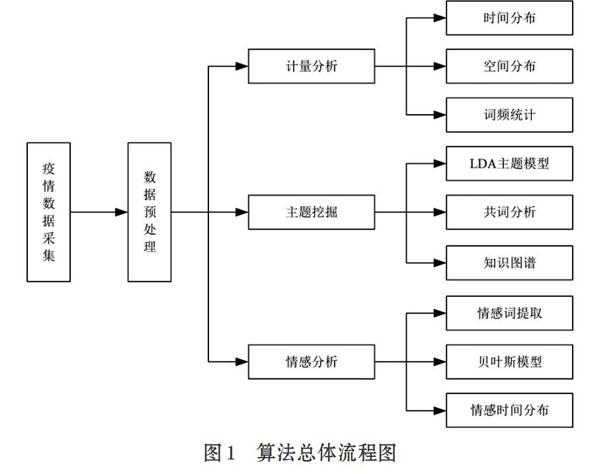
1.1 算法总体流程
本文旨在分析“新冠肺炎疫情”的热点主题和情感态势,其算法的总体流程如图l所示。
(1)通过Python和Selenium技术自定义爬虫抓取人民网“新冠肺炎疫情”相关的新闻,包括新闻标题、新闻内容、发布时间、新闻来源等信息。
(2)对所抓取的语料进行数据预处理,包括中文分词、停用词过滤、特征提取、数据清洗等,再将预处理之后文本存入数据库中。
(3)舆情分析包括三个核心模块,计量分析涉及时间分布分析、空间分布分析、词频统计;主题挖掘涉及LDA主题模型分析、共词分析、知识图谱构建;情感分析涉及情感词提取、贝叶斯模型和情感时间分布分析,最终得出实验结果。
1.2 数据采集及预处理
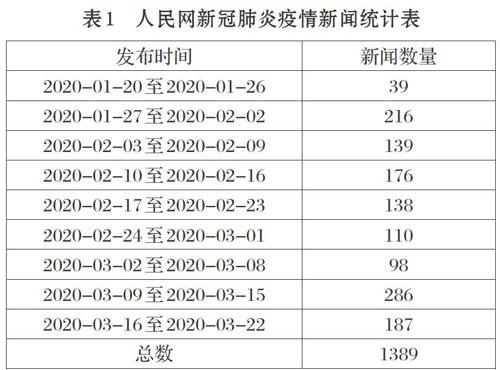
本文采集人民网关于“新冠肺炎疫情”相关的新闻1389篇,时间跨度为2020年1月20日至3月22日,从武汉市封城前到全国疫情基本控制共计9周的新闻数据,详细信息如表1所示。其中,八方支援专题125篇,各地动态专题500篇,抗疫英雄专题127篇,权威解读专题50篇,人民网评专题87篇,实况武汉专题200篇,一线守护专题200篇,疫情快讯专题100篇。
新闻数据采集完成之后,紧接着实施数据预处理操作。首先进行缺失值处理、重复值删除;再通过Python调用Jieba库进行中文分词,并导入关键词和停用词字典完成停用词过滤和数据清洗;最后进行情感词提取、TF-IDF计算、共词分析等处理。通过数据预处理,实验能得到质量更高、数据更完整的文本,从而为后续的实验提供有效支撑。
1.3 主题挖掘
主题挖掘(Topic Mining)旨在从海量文本信息中识别出关鍵词、核心主题、情感分数等,进而实施文本挖掘、舆情分析和情感计算,其是数据挖掘、舆情分析领域的重要知识点[14]。主题模型通过计算概率来挖掘文本主题,常见的算法包括LSA和LDA,广泛应用于自然语言处理、引文文献挖掘、情感倾向分析、社交网络分析等领域[15]。
LDA(Latent Dirichlet Allocation)'16]是一种无监督学习的主题概率生成模型,也被称作三层贝叶斯概率模型,其是在pLSA模型的基础上增加贝叶斯架构模块所形成的。
1.4 情感分析
情感分析是舆情研究中极为重要的部分,旨在从文本内容中识别、抽取、分析及推理带有情感色彩的主观性文本。首先通过Jieba库进行中文分词和数据预处理操作,调用自定义情感词典进行特征提取,并计算每个情感词出现的频数。接着采用已分好类的正面文本pos.txt和负面文本neg.txt进行模型训练,并利用SnowNLP库进行情感分析,其核心算法是贝叶斯模型。最后按照时间顺序加权平均每天的情感分数,采用PyEcharts库绘制情感时间分布图。
2 实证分析
2.1 计量分析
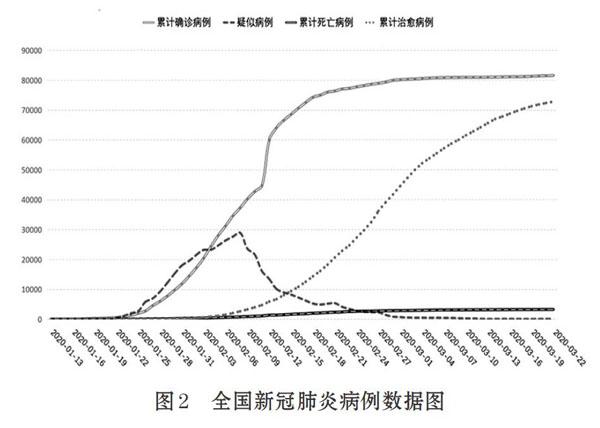
本文从时间维度和空间维度分析新冠肺炎疫情的影响。采用Python从人民网“众志成城,抗击疫情”专题抓取了全国新冠肺炎的病例数据(如图2),详细展示了截止2020年3月22日全国累计确诊病例、疑似病例、累计治愈病例和累计死亡病例的情况。
图3为2020年3月22日全国各地区新冠肺炎累计确诊病例的可视化地图。由图可知,全国疫情最严重的的省份为湖北,疫情较严重的省份包括广东、河南、浙江、湖南等,疫情较轻的省份包括青海、新疆、宁夏、吉林等,疫情最轻的省份为西藏。
2.2 主题挖掘
(1)词云主题演化分析
词云旨在凸显文本中出现频率较高的关键词,在视觉上直观呈现。本文采用WordCloud对“新冠肺炎疫情”新闻进行词云主题演化分析,以周为时间单位绘制图4所示的“疫情”新闻主题演化图。
由图4可知,各时间段的核心主题词均包括“疫情”,随着时间的推移,“防控”也逐渐成为热点话题。在前三周2020年1月20日至2月9日期间,新闻报道主要以疫情的蔓延情况为主,包括“疫情”、“感染”、“防控”、“病例”、“确诊”、“新增”等主题词,从侧面说明该段时间为“疫情”的扩散期,初期还未能做到有效控制。在中间三周2020年2月10日至3月1日期间,新闻报道已由之前的“疫情”蔓延情况开始向“疫情”救治转变,“防控”也成为重要的热点话题,“医院”、“医疗”、“支援”、“物资”、“武汉”、“社区”、“企业”等主题词也清晰地呈现,体现了我们国家“一方有难,八方支援”的精神,“众志成城,共抗疫情”的决心,从侧面说明这段时期主要为“疫情”控制阶段。在后三周2020年3月2日至3月22日期间,新闻报道逐渐开始向“疫情”稳定控制进行转变,企业复工、社区服务、党员活动等主题渐现,涉及的主题词包括“社区”、“工作”、“企业”、“复工”、“党员”、“党建”“复产”等,从侧面推测“疫情”得到稳定控制,人民的日常生活逐渐向正常恢复。
(2) LDA-模型i题聚类
在基于LDA模型的主题聚类实验中,采用TFIDF技术计算特征词的权重。该技术采用统计方法,根据特征词在文本中出现的次数和在整个语料中出现的文档频率,来计算一个特征词在整个语料中的重要程度。其优点是能够过滤掉一些常见的却无关紧要的词语,同时保留影响整个文本的重要特征词。计算方法如下。
本文通过LDA模型主题挖掘实验,发现其主题数设置为3效果最佳。接着调用LDA模型训练得到每个模型内的主题词及对应权重,最终聚类生成的效果图如图5所示,分别对应新型肺炎及疫情扩散、疫情防控及八方支援、企业复工及社区服务三个主题。
(3)共现知识图谱分析
针对“新冠肺炎疫情”新闻主题关键词的分析,本文提出一种基于共现矩阵和知识图谱的分析方法,构建各主题词的关联关系,从而更好地挖掘本次疫情的主题演化关系。采用Gephi构建“新冠肺炎疫情”新闻的关键词共现知识图谱如图6所示,共构建了319个核心主题关键词和1753条关系,其平均路径长度为2.257,最低共现权重为9,网络直径为5。通过知识图谱将“新冠肺炎疫情”新闻相关的主题聚焦在一起,居于中心位置的是“疫情”和“防控”,其他的主题词逐渐向边缘分布扩散。图中左边紫色区域为疫情防控相关的主题词及关系,右边中心绿色区域为医院治疗相关的主题词及关系,右边蓝色区域为肺炎病例相关的主题词及关系,右上红色区域为湖北省各市县相关的主题词及关系。其中“肺炎”和“确诊”、“疫情”和“党员”、“疫情”和“武汉”、“肺炎”和“防控”、“医院”和“患者”、“肺炎”和“冠状病毒”、“企业”和“复工”、“防控”和“党建”等关键词共现明显,其连线较粗。
2.3 情感分析
本文通过自定义情感词典提取疫情文本的情感特征词,表2展示了排名前15的正面情感特征词和负面情感特征词。其中,正面情感特征词出现的频率及TFIDF值更高,“新冠肺炎疫情”新聞的整体情绪呈现积极态势。正面情感特征词包括“落实”、“健康”、“有效”、“重要”、“稳定”等,负面情感特征词包括“严重”、“紧缺”、“重大”、“贫困”、“紧张”、“严峻”等。
接着采用SnowNLP库和贝叶斯模型进行情感时间分布分析。当结果为正数时,情感表现为积极正面,值越高则情感积极性越高;当结果为负数时,情感表现为消极负面,值越低则情感消极性越高。
图7为人民网“新冠肺炎疫情”新闻的情感时间分布结果,时间跨度为2020年1月20日至3月22日。该时段,新闻及群众的态度趋于正面,共有55天情感分数呈积极状态,有8天情感分数呈消极状态。新闻的整体情绪符合国家“一方有难,八方支援”的精神,体现中华民族“众志成城,共抗疫情”的决心。
3 结束语
针对“新型肺炎疫情”热点新闻和舆情话题的主题及情感难以辨别的问题,本文提出了一种结合主题挖掘和情感分析的舆情分析方法。首先采用Python和Selenium抓取人民网2020年1月20日至3月22日期间共计1389篇“新冠肺炎疫情”相关的新闻,接着利用数据预处理、特征词提取、词云可视化展现与“新冠肺炎疫情”相关的热点主题,再采用共词分析、LDA模型、知识图谱和情感分析算法挖掘舆情演化趋势。
实验结果表明,本文提出的方法能有效地识别出疫情新闻的主题关键词,挖掘疫情的主题演化规律,形成以“疫情”和“防控”为中心,其他关键词扩散的共现知识图谱。同时,此次疫情的情感呈现积极状态,九个时间段涉及疫情、防控、医院、工作、服务等热点主题。本文的方法能有效挖掘舆情事件的主题,归纳热点新闻的演化规律和共现知识图谱,为未来的灾害应对、突发事件和舆情分析提供思路。
参考文献(References):
