自助式劳务众包平台的定价模型
2020-09-12何丹
何丹


摘 要:近些年,在移动互联网时代,自助式劳务众包平台发展非常快,它为企业提供多种多样的信息,同时大大降低了调查成本。其基本模式是:用户在APP上领取需要完成的任务,赚取APP对任务所标定的酬金。由于定价规则关系到任务是否能被完成,同时影响企业付出的成本,因此至关重要。本文根据不同任务的分布情况,结合任务周围的会员情况,分别提出了单个任务定价模型和打包任务的定价模型。经检验、采用这两种定价模型的任务完成率较高,且总价格较低,具有普遍推广的价值。
关键词:自助式劳务;众包平台;定价规则;聚类算法
中图分类号:F23 文献标识码:Adoi:10.19311/j.cnki.1672-3198.2020.30.049
1 背景介绍
首先以“拍照赚钱”的形式来说明自助式劳务众包的含义。“拍照赚钱”是近几年来兴起的一种建立在移动互联网基础上的自助式服务模式。其具体模式是用户下载APP并注册成为的会员,通过APP领取需要拍照的任务,并赚取APP对任务所标定的酬金。传统的市场调查需要大量的人力和物力,消耗大量成本,相比之下,移动互联网下的自助式劳务众包平台,可以为企业提供各种商业检查和信息搜集方式,也可以节省不少调查成本。与此同时,适当地缩短了调查的周期,也有效地确保了调查数据的可靠性。因此,APP成为该平台运行的核心,而APP中的任务定价又是其核心要素,这就使得定价的合理性显得尤为重要。如果劳务众包定价过低,就会出现没有人接单的问题,从而导致任务无法完成。
2 单个任务的定价模型
首先采集一批成功完成的任务的经纬度坐标和价格,以及其周围的会员的信息,包括会员的经纬度坐标、信誉值、参考其信誉值给出的任务开始预定时间和预定限额,以便从中学习合理的定价规则。
对于每个任务,需要充分利用其周围的会员信息。因此,首先通过对不同距离范围内会员人数和价格的相关系数分析,得出需要考虑的距离范围。当距离范围在某一固定值时,会员个数和任务价格的相关系数绝对值达到最大,也就可以把这个距离作为需要考虑的范围半径,利用MATLAB作图,结果如图1。
当考虑距离范围为4.5km时相关系数绝对值达到最大值0.6。因此,以4.5km为界线,为每个任务计算在这个范围内的会员个数、会员信誉值和、开始预订时间和、预定限额和。对这些变量进行标准化处理,再用多元拟合的方法得到下式:
定价=-0.929*会员个数-0.618*会员信誉值和+0.665*开始预订时间和+0.410*预订限额和
至此得到了这四个参数和定价的关系。但无法用它们来进行预测,因为多项式拟合的自变量、因变量都进行了标准化处理,无法恢复到原始值。因此,采用神经网络模型来学习四个参数和价格的关系,从而进行预测,神经网络的基本单元神经元的示意图如图2。
该神经元是一个以x1,x2,x3及截距+1为输入值的运算单元,其输出为:
hW,b(x)=f(WTx)=f(z)=f(3i=1Wixi+b)
其中函数f被称为“激活函数”,W为权重,z为x经过线性变换的结果。本模型选用sigmoid函数作为激活函数。
而神经网络模型就是将许多个单一神经元联结在一起。使用圆圈来表示神经网络的输入,标上“+1”的圆圈被称为偏置节点。神经网络最左边的一层叫作输入层,最右的一层叫作输出层。中间所有节点组成的一层叫作隐藏层。按如下公式得到整个神经网络的输出:
z(2)=W(1)x+b(1)
a(2)=f(z(2))
z(3)=W(2)a(2)+b(2)
hw,b(x)=a(3)=f(z(3))
其中,上标代表层数,a为每个神经元的输出值。在本模型中,输入是每个任务周围的会员数、会员信誉值和、开始预订时间和、预定限额和,输出是每个任务的价格。通过训练神经元的各项参数,使得预测得到的输出和实际价格尽可能的相近。
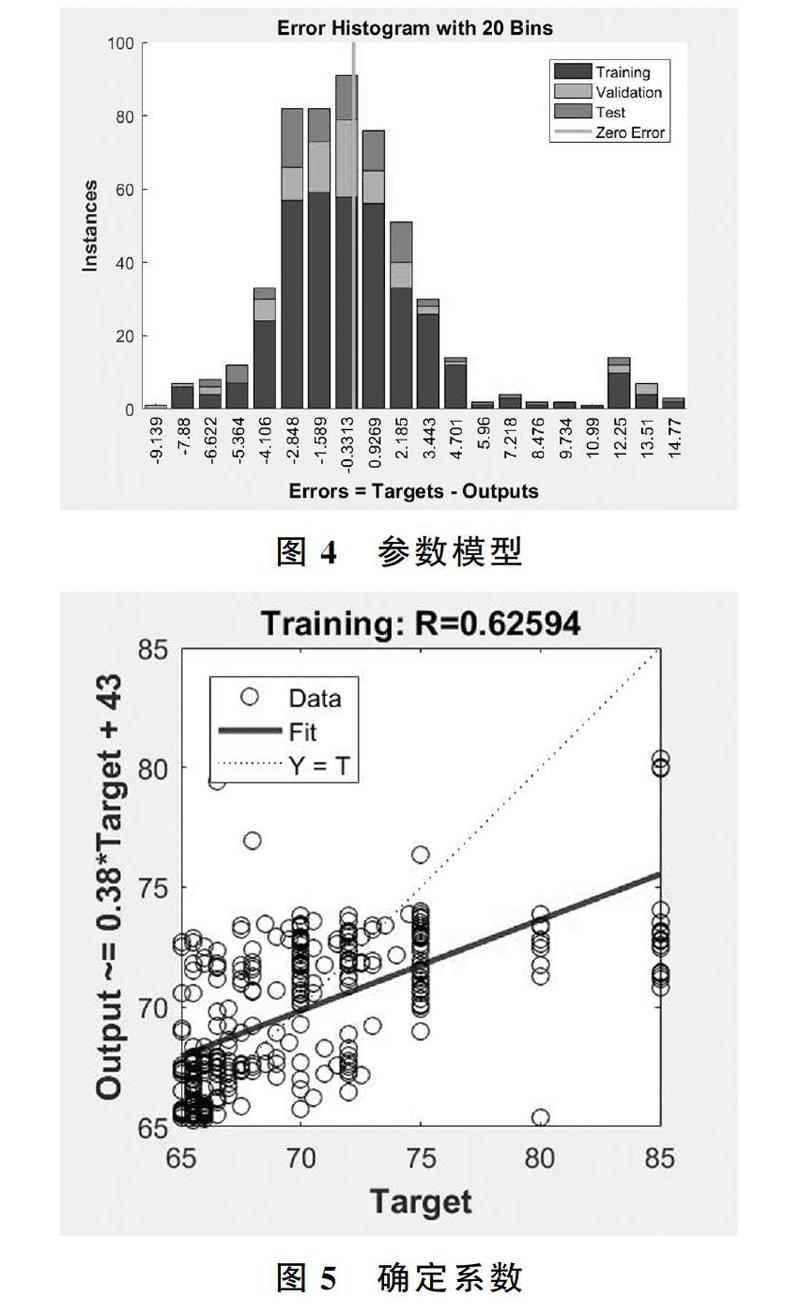
检验训练得到的模型,结果如图4、图5所示。
可以看到,误差主要集中在标准线附近,且确定系数R较接近1。因此可以认为该模型能较为准确的拟合数据。用训练好的模型为任务重新定价,并重新用四个参数多项式拟合新定价。发现新得到的参数和原参数相近,证明单个任务模型的价格制定合理,任务完成率较高。
3 打包任务的定价模型
考虑到多个任务如果位置太过密集,会发生用户对任务进行争抢的现象,于是我们选择将这些任务联合在一起打包发布。如果定价足够高,那么会员理所当然的会选择完成这些打包任务。但是,从企业角度出发,需要尽可能的降低定价从而节约成本。因此,如何在这两者之间取得平衡成了问题的关键。具体定价方法如下:
首先采用基于密度的DBSCAN空间聚类算法,将分布集中的任务打包成一类。DBSCAN是一个比较典型的基于密度的聚类算法。其聚类定义简单地说是根据密度可达关系得到最大密度相连的样本的集合,它可以将较高密度的区域划分为簇,并可将任意形状的稠密数据集进行聚类。事实上,DBSCAN与划分和层次聚类方法是不同的。该算法的伪代码如下:
输入:包含n个对象的数据库,半径e,最少数目MinPts。
输出:所有生成的簇,达到密度要求。
(1)Repeat。
(2)从数据库中选取一个没有处理的点。
(3)IF選取的点是核心对象THEN找出所有从该点密度可达的对象,形成一个簇。
(4)ELSE选取的点是边缘点(非核心对象),跳出本次循环,寻找下一个点。
(5)UNTIL所有的点都被处理。
分类之后,借用重心的概念,设定每一类任务的中心。设某个打包任务里有N个任务,其中心的经纬度计算公式如下:
中心纬度=Ni=1LatitudeiN(1)
中心纬度=Ni=1LongitudeiN(2)
之后,在打包任务之外的单个任务中搜索到距离最近的N个任务J1-N,它们的价格为PJ1-N,并计算它们离重心的距离dJ1-N。而打包任务距离重心的距离为d1-N。通过查阅路费、心理学相关的资料,我们把1km行程的成本定为两元(1.2元的汽油费和0.8元的时间成本)。打包任务的价格公式如下:
P打包=Ni=1PJi-(Ni=1dJi)(3)
该公式很容易理解,聚类范围内的会员如果舍近求远,则需要花费更多的路费、时间成本、机会成本等。而如果会员选择距离他较近的打包任务,则成本就会小得多。假设这些成本之差大于打包任务和单个任务的价格之差,也就是会员舍近求远多赚到的钱不足以抵消他来回的成本,那么会员更愿意选择打包的任务。
带入实验数据,应用打包定价模型,得到图6。
可见,打包后的任务价格下降明显。同时,由于一个打包任务只能由一个用户完成,而之前这些任务可能由很多用户分别完成。那么这些没有抢到打包任务的用户很大可能去选择别的任务去完成,这样又进一步提高了任务完成率。
最后,和第二节中的方法相同,我们通过观察多项式拟合的系数来判别任务完成度。和已完成任务的多项式参数相比,四项系数均比较相近。即:打包任务价格的制定和已完成任务的定价规则相近,完成度较高。
4 模型的评价与推广
本文通过学习已完成任务的定价规律,提出了两种新的定价模型,分别是来为单个任务定价,和将多个集中的任务打包发布的定价模型。通过将两种模型预测出的定价和实际价格作比较,证明了它们具有良好的完成率,同时节约了企业的成本。另外,对于如何将任务进行打包,采用了聚类方法,检验结果表明该模型可以成功将分布集中的任务归到一类。
移动互联网经济飞速发展的形势下,自助式劳务众包平台逐渐增多,使得企业能够方便快捷地进行各种商业检查和信息收集,大大节省了企业的调研成本。此外,共享经济飞速发展,拼车、拼团等商业模式也需要类似的定价方式。因此,本文中的定價模型具有广泛的应用前景。
参考文献
[1]刘严.多元线性回归的数学模型 [J ].沈阳工程学院学报:自然科学版,2005,(Z1):128-129.
[2 ]张景阳,潘光友.多元线性回归与BP神经网络预测模型对比与运用研究 [J ].昆明理工大学学报(自然科学版),2013,38(6):61-67.
[3 ]周水庚,范晔,周傲英,等.基于数据取样的DBSCAN算法 [J ].小型微型计算机系统,2010,21(12):1270-1273.
