基于数据挖掘与机器学习的恶意代码检测技术研究
2020-09-10付大亮


摘要:信息化技术是当前社会发展的标志产物,也是推动信息化社会建设的标杆。而在信息化发展过程中,信息安全是影响其发展的瓶颈之一,如计算机病毒的侵入、钓鱼网站的设立、木马盗号等。对用户个人隐私、企业业务信息安全、国家信息安全等造成严重影响。由于在信息技术发展的进程中,离不开软件的使用,而软件目前更加注重人工编写,这种业态是缺陷代码、恶意代码产生的根本原因,因此有效的检测及防范恶意代码生成成为当前信息安全检测技术发展方向之一。本文结合传统检测技术,重点对检测技术的速度及效率等问题进行分析,实现快速、智能化检测,研究中基于数据挖掘与机器学习的恶意代码检测技术理论,为解决相关技术的实际应用提供一定理论参考。
关键词:数据挖掘;机器学习;恶意代码;检测技术
引言
现代社会快速发展进程中,信息技术发展迅速,伴随着计算机技术和互联网技术的发展,信息技术已经深深的融入到人们的日常生活中,同时信息技术的发展,也提升了人们日常工作、休闲和娱乐的氛围,为互联网技术的快速发展奠定了坚实的基础。但是,计算机技术与互联网技术的快速发展,也为恶意代码的滋生提供了良好的传播空间和环境,恶意代码数量的增加,使其传播速度逐步的加快。依据互联网应急管理中心发布的《2018年中国互联网安全报告》显示,2018年全年恶意程序传播事件达46,578,698次,其中恶意程序下载链接778,388个。恶意代码的传播数量逐步增加,不仅会导致系统中的相关网络结构受到一定的影响,同时恶意代码可能泄露数据,甚至会损坏硬件结构,导致企业和个人的正常生产生活受到影响,甚至带来较大的经济损失。因此,要充分结合恶意代码的检测与处理技术,智能化检测恶意代码,降低恶意代码带来的危害,防止造成信息技术的干扰。恶意代码检查技术已成为当前信息安全技术研究和发展的重要热点话题。
1恶意代码相关分析与检测技术理论
1.1恶意代码的定义与分类
1.1.1木马
木马是安全威胁的最多的恶意代码类型之一。从名字上看,它是一种非法入侵计算机,并获得远程控制权限的一种恶意代码,其往往伪装成正常的程序,诱导用户进行下载,一旦用户下载了装有木马的程序,木马就会在计算机上运行,收集信息、接受黑客指令等。
1.1.2孺虫
孺虫是一种不断的自我修复、复制病毒,它能利用电子邮件等网络手段实现恶意代码的传播。蠕虫类型很多,有的恶意消耗资源、有的收集信息等。
1.2.3病毒
当前,大部分人都习惯性的将恶意代码统称为病毒,其实严格意义上,病毒只是恶意代码的一个类型,病毒从名称来看,只是来源于对应的科幻小说,并通过一段时间的修复和修改技术,增加自身的副本,并将相应的程序感染到对应的程序代码中。
1.2恶意代码的检测技术
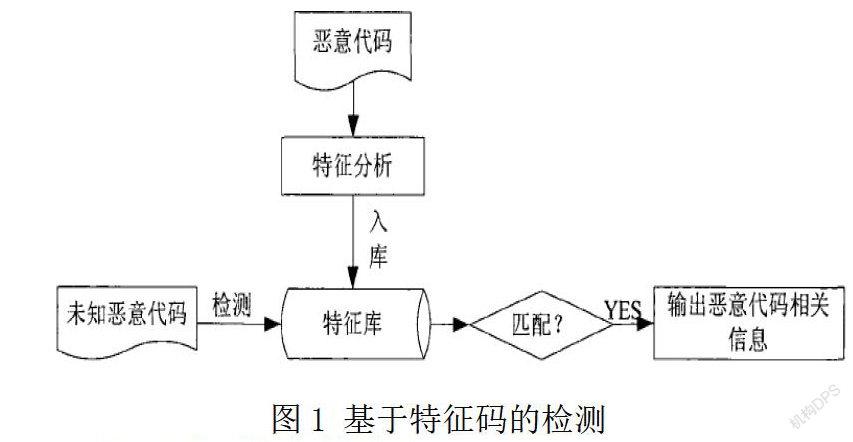
1.2.1基于特征码的检测技术
基于特征码的检测技术主要利用恶意代码的静态分析,获取恶意代码的特征信息,并结合十六进制的字节序列,按照字符串序列结构,对该特征体系下的恶意代码进行有效的检测。检测流程如下图1所示。
1.2.2基于启发式的检测技术
基于启发式的检测技术主要是通过对恶意代码的分析,从而获取恶意代码中所通用的操作序列或者结构形式,并依据一般性操作的存在形式(如修改某个文件的结构、删除相关系统性文件等),对每一个的行为操作序列或者结构的模式按照危险性程序的排序,实现不同危险程序的加权值,在检测实施的过程中,将对应操作行为中相关序列及结构模式的加权值进行总和分析,如果超过了某个特定的阈值,则可判定其为恶意代码。
1.2.3基于检验和的检测技术
检验和是一种信息保护技术,如Hash值、循环冗余码等。只要文件发生标动,校验和就会改变。通过定期性的文件检查,对文件的完整性检测分析,来发现异常改变的文件。
2基于数据挖掘与机器学习的检测技术
恶意代码在信息技术应用的过程中,呈现出数量不断增多,出现的周期逐步缩短的特征,加上一定迷惑性技术的应用,导致检测的难度越来越大,因此如何有效的获取智能化的恶意代码检测技术,是当前恶意代码检测领域中发展的重点内容。在数据挖掘与机器学习技术的应用中,都可通过样本的特征进行分析,通过自动学习病毒融合规律性的发展模式,将学习到的基础性模式运用到病毒分类检测与分析,实现监测的自动化与智能化。其检测原理如图2所示。
2.1样本的选择与划分
数据挖掘与机器学习的恶意代码的检测技术中,主要包含有训练与测试两个步骤,因此在获取数据集合的过程中,应对数据进行有效的划分,主要可划分为训练集和数据集。主要的划分方式有:
一种是k重交叉验证的方式,k重交叉验证即将实验数据集划分为k等份,其中k-1份作为训练集,剩下的1份作为测试集,然后从训练集中再取出1分作为测试集,将前面的1份测试集再加入训练集之中,如此重复k次。
另外一种,利用固定性质的比例模式,将即将数据集按照一定的比例,如3:1的方式进行有效划分,主要可区分为训练集与测试集,并通过两种模式的划分,对其应用过程中的划分方式进行分析。其中,采用k重交叉验证的方式能够获取均值,并采用k重取均值的方式,实现分类精度的进一步提高。
2.2特征表示与提取
在挖掘与学习算法的应用中,应基于恶意代码的基本特征,融合特征的表现形式等,对特征的提取方法进行精度和使用性能的对比分析,融合学习算法的有效应用,提升算法应用的精度的实现。
在常用性的特征表示方案中,主要包含文件的结构特征、序列特征及统计特征的合理应用,不过特征性的表达方式并没有绝对的好坏之分,不同的特征反映出的只是惡意代码不同层面的信息,其侧重点是不同的。
2.3特征降维与约简
相关研究表明,冗余与不相关的特征的存在对学习算法的性能影响非常巨大,最终会导致分类器的使用性能降低,分类的准确性也会降低,可实现的泛化功能逐步的下降等,因此对于以高维矢量为基础的恶意代码在其特征应用上尤为明显,因此在分类学习的过程中,应充分的结合高维恶意代码的特征,实现降维数据信息的合理化构建。降维的过程中排除与类别无关的特征负面影响,并选择性的利用分类对比的方法,将最优的特征子集进行选择,并通过进一步的提高分类的利用效果,提高分类器的泛化使用功能等,以减少学习算法过程中的学习时间。
3基于多维特征与选择性集成学习的恶意代码检测技术
3.1检测基本框架
本文所提出的检测算法相关的框架体系,如图3中,检测过程中主要可分为两个重要的阶段,分别为训练阶段和测试阶段,训练阶段通过测试集训练模型,测试阶段验证模型。监测过程包含样本的静态反汇编、特征的提取与选择,集成分类器构建等3个基本流程。其中静态反汇编主要完成判断恶意代码是否加壳并依据壳的类型选择相应的脱壳程序正确脱壳。在特征提取的过程中,将基本的字节序列、指令序列和基于语义的静态API调用的序列特征进行合理的提取,供后续算法使用。对于不同维度的特征化分析过程,主要应包含特征约简,促进集成分类器的合理构建,并结合集成过程,实现测试阶段中的主要样本信息的测试的完善。
3.2实验样本的选择与划分
实验样本的选择要点要依据操作系统平台、语言类型、特征进行选择。
实验样本的划分。传统模式下的机器学习与数据挖掘的检测方法中,主要以实验数据的应用为主,在实验数据的划分过程中,应对实验数据的平衡性进行管理,达到最终的检验检测效果,因此如何有效设定测试集中区域中的恶意代码与正常代码的类别比例的合理的应用,使得分类的过程能够以最佳的接近实际分布的相关情况进行合理分析。
3.3多维特征的提取
结合当前特征性的描述能力,根据指定的多特征的方式,融合新的特征对信息补充,以更加全面的刻画恶意性的代码特征,提升恶意代码的检验检测能力,一般推荐利用恶意代码的多特征检构建科学合理监测技术。为了综合考虑效率与成本之间的关系,在特征性的提取过程中,主要采取使用静态的特征指标方案,采用多种工具结合,更加全面的描述恶意代码特征,充分的发挥静态特征的优势,本文以恶意代码的多个静态层次为基础,实现多维特征的有效描述,并结合文件的结构层次,字节的层次性等,将语义层、序列的基本特征进行合理化的构建。
由于当前很多的恶意代码都选择使用了加壳技术,进而导致自我保护的力度不断的加大,使得程序中的相关运行机制不断发生变化,应精确实施反汇编,在反汇编的结果基础上,应根据基础性的各个静态层次的特征提取方式,按照一定的静态特征,无须运行恶意代码,通过相对的动态信息获取调用的序列结构等,系统性的开销相对较小,但是其安全性相对较高。
3.4文件结构层特征
文件结构层的特征,更关注于静态结构信息,将恶意代码的重新定位、文件搜索功能等进行有效的防范,并对反病毒的软件进行查杀,通常能够达到修改文件结构的目的。
3.5高维特征的降维与约简
降维的方案有多种,如信息的增补、互动信息的应用及文档的翻转频率等,其中应用最多的为信息增益,应按照降维的思路,计算各个特征环境及信息增益值下的降序排列,然后按照信息的增益值,实现某一阈值特征下的特征值的有效应用。在特征提取的过程中,应对文件的结构特征进行分析,利用滑动窗口获取有效的字节层、指令层和语义层,然后运用降维方案进行合理的降维。
3.6选择性集成学习与决策融合
第一步,基于不同的特征训练模式,按照多个不同类型的分类器,选择合理的分类器装置,实现多个分类精度高、差异性大的分类器装置的合理化应用及选择,并通过选择最优的分类器装置,合理的利用分类器组合实现最优配置。
第二步,对于第一步的不同特征下的选择性的集成分类结果,应对采用的加权多数投票的方式进行融合,达到实现最终的分类信息的有效应用的目标。针对选择性的集成信息,每一个特征下的少数最优的分类器装置进行组合,从而减低分类器的存储空间等,提高分类器的分类速度,保障多特征模式下的分类结果、分类体系及投票方式的决策性融合分析。提高分类器的精度与泛化能力。
4结论及展望
基于数据挖掘和机器学习的恶意代码的检测技术应用是当前信息技术恶意代码检测领域中的研究热点,因此在本文的研究中,主要基于数据挖掘与机器学习,按照一种或者多维的特征体系,选择性的集成恶意代码检测技术,利用多维特征、从多个层次中实现恶意代码的特征集描述能力的全面应用,以保障集成学习过程中的每个特征性分类器的优势互补。最终实现检测精度与单个分类器检测方式特征下的选择性的集成学习的恶意代码检测技术的充分应用,并对机器学习过程中恶意代码的检测技术的优势进行价值分析。
参考文献
[1]廖国辉,刘嘉勇.基于数据挖掘和机器学习的恶意代码检测方法[J].信息安全研究,2016,2(01):74-79.
[2]施宇.基于数据挖掘和机器学习的木马检测系统设计与实现[D].电子科技大学,2014.
[3]冯本慧.基于数据挖掘与机器学习的恶意代码检测技术研究[D].中南大学,2013.
[4]张福勇.面向恶意代码检测的人工免疫算法研究[D].华南理工大学,2012.
[5]孔德光.结合语义的统计机器学习方法在代码安全中应用研究[D].中国科学技术大学,2010.
[6]张小康. 基于数据挖掘和机器学习的恶意代码检测技术研究[D].中国科学技术大学,2009.
作者简介:付大亮(1981.03-),男,辽宁沈阳人,硕士在讀,国家软考系统分析师,主要研究方向:概率论与数理统计。
