融合神经网络与电力领域知识的智能客服对话系统研究
2020-09-08吕诗宁胡若云江俊军欧智坚
吕诗宁,张 毅,胡若云,沈 然,江俊军,欧智坚
(1.国网浙江省电力有限公司电力科学研究院,杭州 310000;2.清华大学 电子工程系,北京 100084;3.国网浙江玉环县供电有限公司,浙江 台州 318000)
0 引言
客服系统是电力营销的重要组成部分,是电力部门对外的重要窗口[1]。为了提高客服质量和效率,电力部门持续推动电力客服系统的信息化建设[2]。随着人工智能技术的发展,智能化成为电力客服系统建设的机遇和挑战,智能客服受到了越来越多的关注和研究[3-5]。用智能客服代替人工客服回答高频简单的问题,可以减少人工客服的工作量,使其可以更专注于解决复杂的问题。同时,智能客服机器人可以以较低成本实现24 h全天候即时服务客户。另外,人工客服的业务水平参差不齐,智能客服的服务质量则相对稳定和可控。基于这些优势,智能客服有助于提高电力企业客服效率,减轻客服人员工作压力,提升客户满意度。
智能客服是对话系统的一个应用场景。对话系统从功能上可以分为三类[6]:任务型、问答型、闲聊型。任务型对话系统通过与用户的多轮交互完成一项特定领域的任务;问答型对话系统对于用户的问题给予一个直接且简洁的回复;闲聊型对话系统与用户进行自然的多轮对话,主要起到娱乐或陪伴用户的作用。其中,任务型和问答型对话系统更适合用做智能客服。
任务型对话可通过模块化的方式实现[7-9]。模块化对话系统主要由自然语言理解、对话状态跟踪、策略选择、自然语言生成等模块组成,如图1 所示。
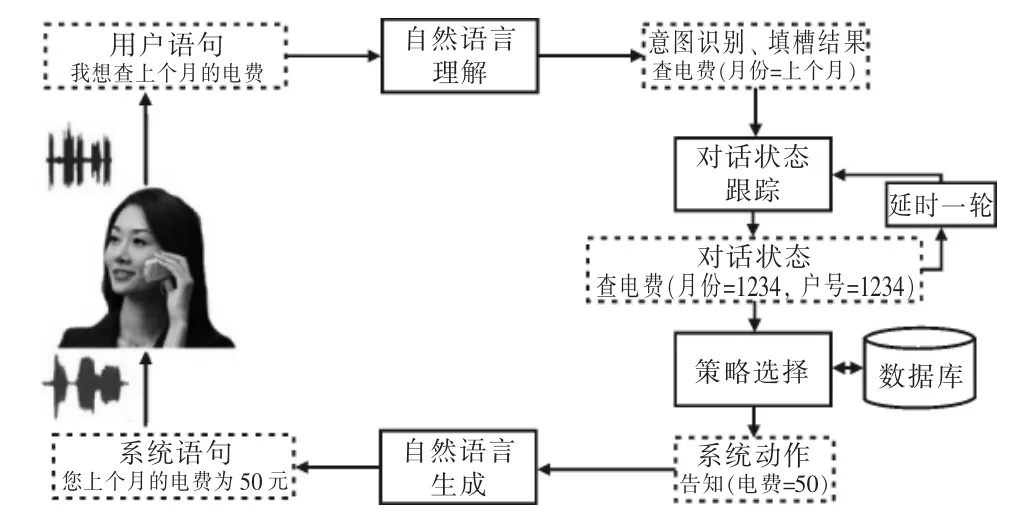
图1 模块化任务型对话系统
问答型对话系统[10-12]为了答案的正确性,需要根据知识库或自然语言文本资料进行回答。
电力领域智能客服对话系统相比于通用领域的对话系统有着很强的专业性。电力领域经过多年的积累,总结出了大量业务知识,包括客户服务流程、客服数据库和标准问答对等等。目前电力领域智能客服[3-5]主要利用了标准问答对,从知识库中找到与客户说的话意思最相近的标准问题,然后将对应答案回复给客户,主要实现了问答型对话系统功能。如何充分利用电力客服业务流程,实现更为智能的电力领域智能客服对话系统,需要新的探索。
为了构建面向电力领域智能客服的对话系统,本文提出融合神经网络学习和电力领域知识的对话系统。具体来说,首先利用对话流配置框架将电力领域知识融入对话系统,从而指导对话系统做出正确的回答;接着利用基于神经网络的自然语言理解模块让对话系统理解用户说的话;最后通过智能坐席和智能外呼两个智能客服应用表明了新方法的有效性。
1 融入电力领域知识的对话系统
本文利用对话流配置框架和知识图谱将电力领域客户服务流程、电力客服数据库和标准问答等电力领域知识融入对话系统。
1.1 利用对话流配置框架融入电力客服流程
为了保证服务质量,电力公司对业务进行了细致的梳理,并针对每个业务的服务流程和话术制定了规范,通常可以用流程图的形式展现,如图2 所示。这些业务流程和话术是客服人员培训材料的重要内容。为了实现智能客服代替人工客服完成客服工作,需要解决三个问题:机器如何读流程图;机器如何按照流程执行;机器如何判断执行哪个流程。为了解决这三个问题,本章节对流程图进行抽象,提出了一个对话流配置框架。

图2 电力客服业务流程
对话流配置框架主要包括五项内容:对话流、意图、全局变量、实体、函数。通过配置对话流,使对话系统能够读懂业务流程并按流程执行;通过配置意图,使对话系统能够判断应执行哪个流程;通过配置其他三项内容来支持对话流和意图的配置。
1.1.1 对话流
对话流配置用以解决机器如何按照流程图执行的问题。
在节点配置方面,本文共归纳出三大类8 种不同类型的节点,具体如下。
1.1.1.1 信息获取类
服务客户时,客服需要得到用户的信息,信息主要来源于客户、数据库和业务知识。
(1)填槽节点:对话系统有时需要从客户那里获取必要信息。比如客户身份验证时,需要知道客户的用电户号和姓名等信息,此时对话系统需要向用户发问,并从客户的回答中提取信息。填槽节点需要配置待填的槽以及对话系统向用户询问该槽的话术。填槽节点主要用来与客户交互。
(2)函数节点:对话系统有时需要从数据库等外部服务获取必要信息。比如客户询问剩余电费的时候,对话系统需要调用一个函数从客服数据库中获取信息。对话系统会根据配置的函数名调用相应函数。函数节点主要用来和机器交互。
(3)赋值节点:对话系统有时可以根据业务知识推理出一些信息。比如客户身份验证失败时,需要问用户的供电单位。但如果客户身份验证成功,就不需要询问用户的供电单位,直接将供电单位赋值成提供服务的电力公司即可。赋值节点需要配置待赋值的全局变量(1.1.3 节介绍)和赋给它的值。
1.1.1.2 流程控制类
(1)子流程节点:电力客服业务中有一些通用的流程,比如几乎所有业务都需要询问用户的户号,因此配置每个业务的时候都要把询问用户户号的部分重复配置一遍。为避免重复,可以把每个流程中的询问用户户号这部分提取成子流程。把父流程中的子流程节点的流程名配置成待跳转的子流程的名称即可完成跳转。这样可以减少配置对话系统的工作量。同时,修改子流程时只需改动一个地方,使得对话系统更易维护。
(2)分支节点:进行逻辑判断的节点。完成类似编程语言中的if-else 语句的功能。
(3)返回节点:返回节点位于一个流程的最后,用来从子流程返回父流程。返回节点不需要配置任何信息。
(4)结束节点:结束节点用来结束本次对话。结束节点需要配置结束对话的具体原因,比如挂机或转人工。
1.1.1.3 信息输出类
回复节点配置了业务文档中规定的话术之后,对话系统可按配置的话术来回复用户。
每一个节点完成自身功能后,根据业务逻辑应跳转至下一节点,称为目标节点。每一个目标节点对应一个条件,每个条件由操作符和元素数组组成,比如“电费余额<0”这个条件的操作符是“<”,元素数组是[电费余额,0]。存在多个条件时,依次判断各条件是否为真。
1.1.2 意图
意图帮助对话系统判断应该执行哪个流程。电力客服每一个业务流程解决用户的一个问题,因此对话系统只要知道客户想解决什么问题,就可以用相应的流程来服务客户。比如,“查电费”“修改服务密码”等都是用户的意图。为了理解客户说的话,在配置意图时,需要配置表达该意图的自然语言。另外,为了根据流程帮助用户完成意图,还需要配置与该意图相关的槽。比如对于“查电价”这个意图,用户需要填“用电电压”这个槽。
1.1.3 全局变量
全局变量可以在多轮对话过程中维护服务用户所需的信息,跟踪对话状态,使得对话系统和客户保持信息的同步。对话状态可以表示成一组键值对的形式。比如“户号=1234,姓名=张三”就是对话系统询问完客户户号和姓名之后的对话状态。这里的“姓名”和“户号”就是全局变量。
1.1.4 实体
实体是一个槽可取值的范围。比如“查电价”这个业务流程,有“用电类型”和“供电电压”这两个槽。“用电类型”可取值的范围为[居民生活用电,大工业用电,一般工商业用电,农业生产],这个范围就是“用电类型”这个槽的实体。配置了该实体之后,在填槽节点中对话系统才可以从用户说的话中找出“用电类型”的信息。
1.1.5 函数
函数可以是一段代码,又或是一个API 接口,供对话流中的函数节点调用,从而获取必要信息或执行某个指令。本文提出对话流配置框架的一个很重要的目的是减少搭建对话系统所需要的代码量,对话流配置文件解释器完成各类节点功能的底层实现,使不会编程的业务人员也可以按照配置框架和业务流程用配置的方式搭建出一个对话系统。但有些功能,比如查询数据库,需要自定义函数来实现。通过自定义函数,同时实现了减少代码量和保留定制性这两个目的。
1.2 利用知识图谱融入电力客服数据库和标准问答对
电力客户服务流程主要内容是客服专业知识,而电力客服数据库和标准问答对的主要内容是电力专业知识。
电力客服数据库的结构包含了很多电力领域的知识,比如“抄表”查询接口返回的内容包含“本次示数”“抄表日期”“上次示数”等。可以将客户在数据库中的信息存储在知识图谱中,把数据库的查询接口作为知识图谱中的实体,接口返回的内容作为对应实体的属性。当收到客户的消息时,对话系统把客户说的话在图谱中进行文本相似度匹配,既可以查询到与这句话相关的实体,也可以在一个实体下查询到与这句话相关的属性。比如用户问“电费明细”时,如果没有配置跟“电费明细”有关的意图,对话系统无法根据业务流程服务客户,但通过在图谱中搜索,对话系统找到了“电费”这个实体以及该实体下“明细”这个属性,对话系统就可以将属性值回复给用户。再比如,用户如果问“煤改电补贴多少钱”,对话系统不仅可以回复客户补贴金额,因为“煤改电”这个实体下还有“办理方式”和“营业网点”这两个属性,对话系统可以进行智能推荐,询问客户是否还想问“办理方式”和“营业网点”的信息。
电力客服关于业务类问题有大量的标准问和对应的标准答。知识图谱可以抽取出标准问句中的实体和实体间的关系,从而把大量的标准问存储在结构化分层次的知识图谱中,然后利用文本相似度算法在图谱中找到与用户问题最接近的标准问,最后将标准答案回复给客户。
2 基于神经网络的自然语言理解
对话系统利用对话流配置文件解释器来读取对话流配置文件,并按照配置文件中的对话流服务客户,从而实现了经典模块化任务型系统中的对话状态跟踪,策略选择和自然语言生成这三个模块的功能。下面介绍基于神经网络的自然语言理解模块的实现方法。
本节用基于神经网络的自然语言理解模块实现意图识别功能。意图识别的输入是一句客户说的话,输出是这句话表达的意图。本质上是一个文本分类问题。类别标签的集合是对话系统已配置的所有意图。
在预训练模型和迁移学习在图像识别领域取得成功后,近年来,以openAI 的GPT[13]和谷歌的BERT[14]为代表的预训练模型在十多个自然语言处理任务上取得了最优的效果,甚至在某些数据集上的表现超过人类,证明了预训练和迁移学习在自然语言处理领域也是有效的。本文采用预训练模型BERT 进行意图识别。
2.1 Transformer 编码器
BERT 由多层的Transformer 编码器构成。Transformer 编码器由两部分组成:注意力层和前馈神经网络层。Transformer 的输入是一个序列,输出也是一个序列,输出序列与输入序列等长,序列中的每一个元素都是向量,将这些向量拼接在一起可以得到一个矩阵,因此Transformer 的输入输出可用矩阵表示。
2.1.1 注意力层
注意力层采用MHA(多头注意力机制),具体如下:

式中:Hh∈Rl×dv为每个注意力头的计算结果,将Hh拼接在一起得到注意力层的输出结果;Qh∈Rl×datt,Kh∈Rl×datt,Vh∈Rl×dv分别为各个注意力头的查询矩阵、键矩阵、值矩阵,通过对输入矩阵X 分别进行线性变换得到;W*h,b*h为线性变换的参数。
2.1.2 前馈神经网络层
前馈神经网络层由两层前馈神经网构成,对输入序列每个位置的向量做相同的计算。激活函数选择GeLU[15],公式如下:

式中:W1,b1,W2,b2分别为两层前馈神经网的参数。
2.1.3 整体结构
Transformer 编码器的注意力层和前馈神经网络层均使用残差连接和层归一化[16]。
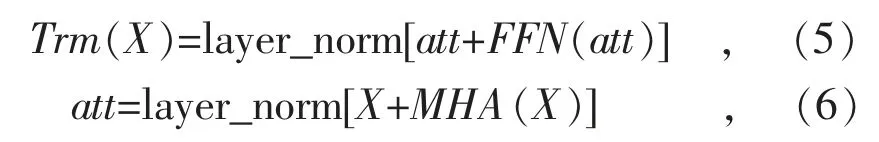
式中:att 为注意力层的输出以及前馈神经网络层的输入。
2.2 BERT
BERT 的输入是一句话,输出是对这句话每个字的包含上下文信息的编码结果。BERT 首先对句子中的字进行向量化表示。

式中:Ei为字符向量ET、段向量ES和位置向量EP的和。字符向量用来区分每个字;段向量用来区分来自不同句子的向量,由于意图识别任务的输入只有一句话,所以每个字的段向量均相同;位置向量用来区分一句话中不同位置的词。这3个向量都是可训练的参数。
得到句子的向量化表示后,BERT 通过多层Transformer 对句子进行编码得到编码结果。
为了将BERT 用于意图识别模型,需要BERT 输出一个定长的向量而不是一个向量序列。为此在每句话的前面添加一个占位符[CLS],把[CLS]的编码结果作为BERT 的输出。
2.3 基于BERT 的意图识别模型
基于BERT 的意图识别模型是在BERT 预训练网络的基础上增加一层前馈神经网络。预训练阶段需要大量的计算资源和时间,因此本文直接使用谷歌开源的训练好的中文BERT 预训练网络。微调阶段在意图识别数据集上训练,对预训练网络和前馈神经网络组成的整体意图识别模型的参数进行微调。
BERT 的输出包含了这句话的语义信息,把[CLS]的编码结果输入一层前馈神经网中,可得到每个意图的概率分布,模型将概率最高的意图作为识别结果。模型的整体结构如图3 所示。图中E表示每个字的向量;Trm表示Transformer 编码器;C 和T 分别表示BERT 模型对占位符[CLS]和句子中每个字的编码结果。
2.4 基于ALBERT 的意图识别模型
基于BERT 的意图识别模型参数量较大,Lan Z 等提出了ALBERT[17]以减少模型参数量。ALBERT 相对BERT 主要有三点改进:
(1)将字符向量组成的矩阵分解成两个矩阵乘积,减少字符向量的参数量。

图3 BERT 意图识别模型
(2)通过共享BERT 中各层Transformer 的参数,减少模型整体参数量。
(3)将预训练阶段的预测两个句子是否相邻这个任务换成相对更难的任务:预测两个相邻句子的先后顺序,增强模型的语义编码能力,使得模型参数量减少后模型性能不下降太多。
3 实验结果
通过融合神经网络和电力领域知识,本文实现了两个智能客服对话系统,分别为智能坐席和智能外呼。
3.1 对话流程配置
首先按照业务流程和对话流配置框架配置对话系统。智能坐席系统能够回答客户与电费电价相关的问题。智能坐席配置了“查电费”“电价标准”“查询抄表数据”等12 个意图。智能外呼系统在客户没有按规定日期缴费时主动给客户打电话提醒客户。智能外呼系统配置了“已知晓”“已还清”“查询欠费”等48 个意图。针对每个意图配置了相对应的流程。图4 举例说明了智能坐席系统的“查电费”流程和智能外呼系统的“已知晓”流程的配置方式。
3.2 模型超参数
BERT 中Transformer 层 数 为12 层,Transformer 的输入和输出向量均为768,注意力层的注意力头数为12,前馈神经网络层的隐藏层的维度为3072。句子的最大长度为64,每个训练批次的大小为32,优化器为Adam,学习率为2e-5,验证集的loss(损失函数)经过5 轮不下降时停止训练。训练ALBERT 模型的超参数与BERT 模型一致。

图4 对话流配置
3.3 实验结果
为了训练智能坐席系统和智能外呼系统,通过标注线上客服聊天记录,分别得到1 447 条和21 483 条数据,其中的80%作为训练集,10%作为验证集,10%作为测试集。表1 列出了BERT模型和ALBERT 模型的参数规模以及在两个数据集上的测试准确率。

表1 BERT 和ALBERT 的模型规模及性能
对比BERT 和ALBERT,可以看出BERT 相对ALBERT 准确率更高,而ALBERT 的模型参数量更少,实际使用中可根据实际业务需求和硬件资源选择合适的模型。本文进行系统测试时选择BERT 进行意图识别。
系统测试效果如图5 和图6 所示。对照图4和图5 简单解释一下智能坐席系统根据业务流程服务客户的过程。系统说出开场白后,客户说“查一下电费”,系统识别出“查电费”意图,进入“查电费”流程。由于客户信息未知,进入图4 右侧所示的“获取客户信息”子流程。根据“获取客户信息”流程,系统先询问客户编号,客户提供编号后,系统用函数节点验证客户姓名,验证通过后系统从数据库中获得客户信息,返回“查电费”流程,继续查询数据库获得电费信息并回复客户。接下来客户问“电价多少钱”,系统识别出“查电价”意图,进入“查电价”流程。“查电价”流程与“查电费”类似,但因为已经得到了客户信息,因此直接查询数据库得到电价信息回复给客户。综上所述,系统通过识别客户意图并执行相应流程服务客户。

图5 智能坐席

图6 智能外呼
4 结语
电力公司的客服业务是服务客户的重要窗口,有着话务量大、坐席业务繁重的特点。随着自然语言处理技术的进步,用智能客服分流人工坐席业务,是减轻坐席客服压力、降低服务成本的一个可行方案。本文探讨了如何搭建一个面向电力领域的智能客服对话系统,提出了融合神经网络和电力领域知识的方法:利用神经网络实现自然语言理解模块,对客服的话进行意图识别;利用对话流配置框架和知识图谱将电力领域知识融入对话系统,保证电力领域智能客服对话系统的专业性。同时开发了智能坐席和智能外呼两个智能客服机器人,针对这两个场景的线上客服进行数据标注,实验得到的智能客服的意图识别准确率分别为91.61%和90.78%,系统能够按照电力领域知识回复客户,验证了方法的有效性。
电力客服领域已经梳理出了比较规范的服务流程和话术,可以根据这些业务文档配置出智能客服机器人,回答常见的标准问题。另一方面,通过对线上聊天记录进行分析后发现,对于用户的一些问题业务流程中并没有规定处理方式,需要人工客服根据经验回答。如何让智能客服从海量的客户聊天历史数据中学习到这些经验,提升服务能力,是有价值的研究方向。
