多重CCA算法的柬汉双语词向量构建方法
2020-09-04蒋亚芳李思远徐广义
蒋亚芳,严 馨,李思远,徐广义,周 枫
1.昆明理工大学 信息工程与自动化学院,昆明 650504
2.云南南天电子信息产业股份有限公司,昆明 650051
1 引言
在自然语言处理领域,目前构建单语词向量模型的方法已经较为成熟,对于跨语言词向量模型的构建也取得了一些进展。如何将单语之间的词向量转换进而形成跨语言词向量是该模型构建过程中的一个重要因素。
双语词向量构建一般是两类方式:第一是基于第三方中间语言构建双语词向量,借助某种流行语言(一般采用英语)当作中间语言,利用当前源语言-中间语言-目标语言来实现源语言-目标语言的双语词向量[1]。例如Tanaka等[2]指出使用英语当作第三方中间语言,实现日文-法文双语词向量构建,具体思想为当使用第三方语言来构造双语词向量时,根据计算双语词典中词义匹配相似度,通过中间语言为桥梁得到的一个新的源语言词到目标语言词的双语词典,进而对双语词典中的词分别进行词向量训练得到双语词向量。与之相似的,Bond等[3]采用日文-英文双语词向量以及英文-马来西亚文双语词向量使用英语作为中间语言实现日文-马来西亚文双语词向量,Bond 提出的方法主要是在Tanaka 的基础上对中间语言匹配的规范化方面进行了优化;基于第三方中间语言构建双语词向量中较为典型的思想方法是由Ruder[4]提出,该方法通过机器翻译实现双语词向量的构建,且不需要实际翻译样本,将其样本投影到一个子空间中,最终训练学习一个共享的嵌入空间,该模型适用于训练所有种类的词向量。
另一类方式为借助源语言以及目标语言的平行语料库,根据词语之间的语义和上下文信息提取意义接近的词语实现双语词向量表征[5-8]。Klementiev等[9]研究学者率先关注跨语言词向量问题,将跨语言词向量构建视为一个多任务学习问题,通过平行句对的共现统计使多任务之间产生相关性,实现跨语言词向量的构建。Mikolov 等[10]采用单语各自训练,然后直接进行转换的方式构建双语词向量模型。根据词语语义间的关联性对平行文本进行线性转换,源语言的词向量可以直接转换为目标语言的词向量,但是该研究在模型训练中需要使用资源丰富的双语词典或双语平行文本资源。Faruqui等[11]提出了一种利用典型相关性分析的方法,获取双语词向量。但是该模型在构建初始需要在大量的双语平行语料库中去寻找互译或者对齐的双语词汇,然而对于柬-汉双语而言,双语平行语料资源极为缺乏,因此采用该类模型将会面临这个关键问题。
典型相关分析CCA 算法在自然语言处理中也应用广泛,尤其在机器翻译中得到很好的实用效果。Haghighi 等[12]使用CCA 在两种不同语言的单词之间绘制翻译词汇,仅仅使用的是单语语料库。Paramveer等[13]提出了一种新的基于CCA的多视角学习方法LR-MVL,通过相关的词向量来构建单语词表示,这些词向量捕获了词义的各个方面以及词的不同类型的分布概况。Li等[14]提出一种基于KCCA(Kernel Canonical Correlation Analysis)的机器学习算法,利用了非线性相关映射将该算法应用于日英跨语言信息检索和文档分类,取得了较好的效果,但是该方法计算复杂度比较高,不适用于大型数据集,因此,本文使用CCA 算法得出双语词向量,它能很好地衡量汉柬词汇之间的语义相关性,减少了计算的复杂度。
当前现有的跨语言词向量模型研究中,以第三方语言为中间语言进行研究的方法只考虑到多种语言词语之间的对应关系,而忽略了词语本身的上下文语义关系以及多种语言词语间的相关关系;在根据词语之间的语义和上下文信息提取意义接近的词语实现双语词向量模型构建方法中,虽然更多地考虑到了词语之间的相关信息,但在模型构建初始需要使用到大量的平行文本或丰富的双语词典互译语料,然而目前柬汉双语平行资源稀缺,且获取难度较大,因此该类方法只适用于使用人数较多、平行文本资源丰富的语种,不适用于平行语料稀缺的柬埔寨语语言处理工作中。
本文将以上两种方法相结合,并在Faruqui 等[11]提出的经典跨语言词向量模型上针对柬埔寨语语料稀缺的问题做出进一步改进,加入中间语言作为桥梁,以英语作为中间语言,利用汉英以及柬英的语料资源丰富性,将其和现有的跨语言词向量模型相结合,可以更好地解决小语种语言平行语料缺乏的问题。因此本文对文献[11]中提出的双语词向量模型进行改进后得到了以英语作为中间语言基于多重典型相关分析算法的柬汉双语词向量模型构建方法。该方法对词语之间的相关关联有了更深的考虑,同时通过加入第三方中间语言英语以及部分实验室构建的柬汉双语电子词典在一定程度上解决了柬汉平行文本资源不足的问题。
2 基于多重CCA的柬汉双语词向量模型构建
在基于多重典型相关分析算法(CCA)且以英语作为桥梁语言的双语词向量模型构建方法中,以大量英、柬、汉三语单语语料为基础进行训练,得到三种语言的单语词向量,其次将英语、汉语词向量投影至英汉向量空间(该向量空间为第三方向量空间,投影后该向量空间中只包含英语词向量以及汉语词向量),将英语、柬语词向量投影至英柬特征向量空间(该向量空间为一个新的第三方向量空间,投影后该向量空间中只包含英语词向量以及柬语词向量),根据CCA算法分别得到英-汉、英-柬双语词向量;然后以英语作为中间词并结合部分实验室构建的柬汉双语电子词典将上一步得到的英-柬、英-汉双语词向量投影至第三方同一向量空间中(该向量空间依然是一个全新的第三方向量空间,投影后该向量空间中包含英语词向量、汉语词向量以及柬语词向量),再次根据CCA 算法得到柬语和汉语在新向量空间中的投影转换矩阵;最后得到柬汉双语词向量。
2.1 典型相关分析
典型相关分析的实质就是在两组随机变量中选取若干个有代表性的综合指标(变量的线性组合),用这些指标的相关关系来表示原来的两组变量的相关关系[15-17]。这在两组变量的相关性分析中,可以起到合理的简化变量的作用。CCA 使用的方法是将多维的X和Y都用线性变换为一维的X′和Y′,然后再使用相关系数来看X′和Y′的相关性。将数据从多维变到一位,也可以理解为CCA是在进行降维,将高维数据降到一维,然后再用相关系数进行相关性的分析。
给定两组变量X和Y,X为n1×m的样本矩阵,Y为n2×m的样本矩阵。其中m为样本个数,而n1,n2分别为X和Y的特征维度。对于X矩阵,将其投影到一维,对应的投影向量为a,对于Y矩阵,将其投影到一维,对应的投影向量为b,这样X,Y投影后得到的一维向量分别为X',Y',且:

CCA算法的优化目标是最大化ρ(X′Y′),得到对应的投影向量a,b,即:

式中,C为协方差,D为方差。
通过对上式求解得到投影矩阵X′,Y′,但会获得若干个结果,即有若干个特征向量。事实上,存在min(m,n)种结果,但对应最大的相关系数有一组相应的a和b。所以在应用中只取最大的相关系数,由此便可获得所要求的两组变量的相关系数。
2.2 柬汉双语词向量模型构建方法
由于可直接获得的柬汉双语语料资源稀缺,导致通过以大量双语平行文本为基础的词向量构建模型所获得的词向量效果其实是不佳的,但由于汉英以及柬英语料资源丰富,所以在这里提出了以英语作为中间语言的基于典型相关分析双语词向量构建模型,能够解决现有的语料缺乏问题,同时利用典型相关分析算法将三种语言有效地联系在一起,使得到的双语词向量更有效,同时该模型不仅适用于双语,也能扩展到多语任务中。因此本文提出的以英语作为中间语言的基于多重典型相关分析双语词向量构建模型能够对可获取到的柬汉语料进行向量化。本文的框架图如图1所示。

图1 双语词向量模型流程图
图1 的主要步骤如下:首先应用现有的成熟技术Word2vec 对英、柬、汉三种单语语料进行词向量训练,得到三种语料对应的单语词向量;其次将柬、英词向量投影至柬英向量空间,将汉、英词向量投影至汉英向量空间,根据CCA 算法分别得到各自的投影转换矩阵后计算得到对应双语词向量;然后以英语作为中间词并结合部分实验室构建的柬汉双语电子词典将上一步得到的英-柬、英-汉双语词向量投影至第三方同一向量空间中,再次根据CCA 算法得到柬语和汉语在新向量空间中的投影转换矩阵,最后计算得到柬英汉多语词向量,多语词向量中包含有柬汉双语词向量。该模型主要可分为三个步骤进行,具体过程如下:
收集相同领域柬语、英语、汉语单语语料,对收集到的三种语言的单语语料进行分词处理,并将三种单语语料通过Word2vec进行词向量训练,分别获得柬语、英语以及汉语的词向量。
将柬语和英语词向量投影至英柬特征向量空间中,对应得到英语词向量和柬语词向量在该向量空间中的投影转换矩阵及英柬双语词向量;将汉语和英语词向量投影至英汉向量空间,对应得到英语词向量和汉语词向量在该向量空间中的投影转换矩阵及柬汉双语词向量。英-汉双语词向量模型结构如图2所示。

图2 英-汉双语词向量模型
由于所收集到的单语语料规模不同,因此经过第一步后得到的英语、汉语、柬语词向量规模大小并不相同,将其分别记为Σ、Ω以及Φ,Σ为英语词向量集,Ω为汉语词向量集,Φ为柬语词向量集;且Σ∈Rd1×n1,Ω∈Rd1×n2,Φ∈Rd1×n3,其中d1为三种语言词向量集矩阵的行数,表示词向量的维度,三种语言词向量的维度相同;n1,n2,n3分别为英语、汉语、柬语词向量集矩阵的列数,n1表示英语词汇集单词的数量,n2表示汉语词汇集单词的数量,n3表示柬语词汇集单词的数量,由于初始单语语料规模的不同,因此在Ω中可能不存在Σ中每个词的对应翻译词,同理,在Φ中可能也不存在Σ中每个词的对应翻译词,因此首先令Σ′⊆Σ,Ω′⊆Ω,根据英汉双语词典使英语词向量空间Σ′中的每一个英语词都能在汉语词向量空间Ω′中找到具有互译关系的中文词,令x和y分别为Σ′和Ω′中的互为翻译词的词向量,并将x和y投影到英汉特征向量空间后得到投影词向量x'和y'分别为:

其中,v和w是Σ′和Ω′的投影向量。
将英语词向量x和与其词义对应的汉语词向量y映射至英汉特征向量空间后,根据CCA 算法对含有x'和y'之间的相关关系进行计算:

其中,ρ(x',y')为相关系数,cov[x',y']为x'和y'的协方差,Var[x']和Var[y']分别为x'和y'的方差。
CCA 算法将映射至该向量空间的英语和汉语词向量之间的相关系数ρ最大化,并输出投影向量v和w,表示为:

得到Σ'和Ω'的投影向量v和w的表示之后,根据以上方法获取英语词向量Σ与汉语词向量Ω两种语言的全部词汇词向量映射至汉英同一向量空间后所得到的英语、汉语投影转换矩阵分别为V、W,以及对应双语词向量,表示为:

其中,V∈Rd×d,W∈Rd×d,Σ∗、Ω∗为具有相关关系的英汉双语词向量。d的取值为投影转换矩阵V与W的秩中的较小值,由于根据相关性投影向量所得到d取值较大,因此仅通过对前d1个相关维度进行原始单词词向量的投影进行工作,且令d=d1,d1的可设置范围值100~300。
同理,令Σ″⊂Σ,Φ′⊂Φ,根据柬英双语词典使英语词向量空间Σ″中的每一个英语词都能在柬语词向量空间Φ′中找到具有互译关系的柬语词,与以上过程类似,得到Σ″和Φ′的投影向量P、Z以及对应英柬双语词向量,表示为:

其中,P∈Rd×d,Z∈Rd×d,Σ∗∗、Φ∗为具有相关关系的英柬双语词向量。
通过上一步的工作可以获取英汉、英柬双语词向量,所获得英汉双语词向量个数为n4,n4=n1+n2,英柬双语词向量个数为n5,n5=n1+n3;分别构建包含英汉双语词向量的向量集Γ以及包含英柬双语词向量的向量集Π,令Γ′⊆Γ,Π′⊆Π,Γ'与Π'分别为向量集Γ和Π的子集,Γ'与Π'中存在相同的英语词所对应的词向量,数量为n1,此外Γ'中还包含部分实验室构建的柬汉双语电子词典中汉语词的词向量,数量为n6;Π'中还包含部分实验室构建的柬汉双语电子词典中柬语词的词向量,数量为n6;Γ'与Π'中相同英语词之间具有互译关系,部分由实验室构建的柬汉双语电子词典中的柬汉词对同样具有互译关系,因此向量集Γ'与向量集Π'中的词向量所代表的词之间满足互译对应关系;Γ∈Rd×n4,Π∈Rd×n5;d为向量集的行数,表示词向量的维度,n4、n5分别为向量集Γ和向量集Π的列数。然后再次根据CCA 算法将Γ和Π映射至第三方同一向量空间中,该过程的模型如图3所示。
在第三方向量空间中得到Γ和Π投影转换矩阵M和N,根据进一步计算得到包含柬英汉三种语言的多语词向量,表示为:

其中,M∈Rd×d,N∈Rd×d,Γ*、Π*为具有相关关系的多语词向量。

图3 柬、英、汉多语言词向量模型
3 实验结果及分析
3.1 实验语料
本文所采用的实验语料为柬汉英三种语言单语语料,其中主要来源为分别从柬语语言网站、汉语语言网站、英语语言网站中爬取获得,例如从中国新闻网(https://www.chinanews.com/)、中国日报网(http://www.chinadaily.com.cn/)、柬埔寨日报网(http://www.cambodiadailykhmer.com/)等网站进行爬取得到三种语言的新闻语料,并根据新闻主题的不同,将爬取到的语料进行标记分类,获得三种语言的语料;此外实验所使用的语料中还包括一些网络上可以直接下载得到的中文语料库以及汉语语料库。目前,通过以上方法获取到的三种语言的单语语料库覆盖了经济、政治、旅游、体育等多个领域,包含1 016 455个英文单词、927 496个汉语词以及752 895 个柬语词,本文中所使用的英汉词典为郭世英[18]编著的现代英汉词典(https://www.xiaobd.net/t/4162315/),收录了42 000 词条;所使用的英柬词典为SBBIC英柬词典,包含27 500词条。
3.2 实验设计及评价标准
本文中所介绍的双语词向量模型以典型相关分析算法为核心,根据不同语言的词向量之间的相关关系进行分析计算,实现双语词向量的构建。因此使用斯皮尔曼等级相关系数来评测通过本文所提出双语词向量模型得到的双语词向量所对应的双语词之间的相关度与人工标注词对之间相关度的一致程度。
斯皮尔曼等级相关系数由Spearman根据积差相关的概念推导而来,是积差相关的特殊形式。它是一个非参数性质的秩统计参数,用来衡量两个变量之间关联关系的大小。斯皮尔曼等级相关系数用ρ表示,可由下式计算得到:

其中,n代表等级个数,即测试集中包含的词语对的数量。d代表二列成对变量的等级差数,di表示第i个元素的等级差,即所使用模型对第i个词语对的相关度评价结果和人工标注结果在各自的排序列表中排序位置的差。
在自然语言处理任务中,WS-353 测试集常被用来训练和测试计算机实现的语义相关度算法。其包含两个英文数据集,第一组数据集包含13个主题共153个词语对和由13 个评价者对词语对做出的相似度的评价;第二组数据集包含16个主题共200个词语对和由16个评价者对词语对做出的相似度的评价,并给出一个0~10 的评分,0 表示两个词语完全不相关,10 表示两个词语很相关或者是同义词。本文根据需求把WS-353测试集进行人工翻译,构建了英-汉测试集Ten-ch,英-柬测试集Ten-kh,汉-柬测试集Tch-kh。并且用这三个测试集分别对本文所改进的模型与Faruqui等[11]所提出的多语言典型相关分析模型进行测试,作为对比实验。
3.3 实验结果及分析
在本节实验中,设置词向量维度d为200 进行计算。通过Word2vec工具包对三种语言语料进行单语词向量训练,分别得到52 947 个英语单语词向量、44 805个汉语单语词向量以及39 054 个柬语单语词向量。以文献[8]中多语言典型相关分析模型作为baseline,将单语词向量分别放入多语言典型相关分析模型和本章所提出模型中进行训练,得到双语词向量,并将通过多语言典型相关分析模型训练得到的英-汉、英-柬、汉-柬双语词向量所表示的词对与英-汉测试集Ten-ch、英-柬测试集Ten-kh、汉-柬测试集Tch-kh进行分析比较;而后将通过本章模型训练得到的多语词向量所表示的词对与英-汉测试集Ten-ch、英-柬测试集Ten-kh、汉-柬测试集Tch-kh进行分析比较,得到词对之间的相关系数,将本章所提模型的实验结果与基准实验的结果进行对比分析。CCA 算法通过Matlab 工具实现,斯皮尔曼相关系数越大,所测试的模型得到的双语词向量对应的双语词对相关度越高,实验结果如表1所示。
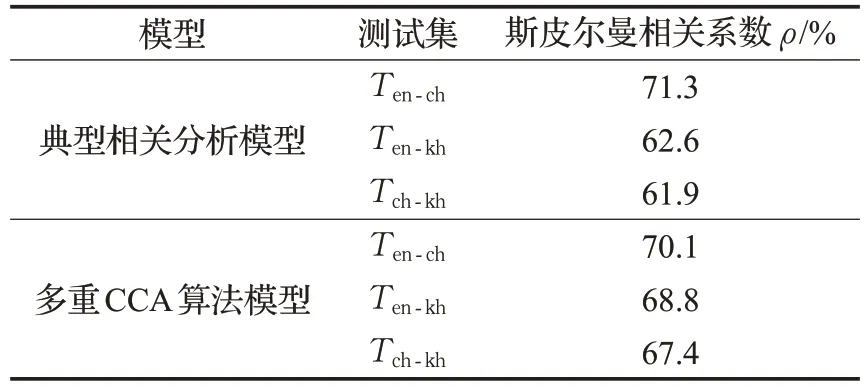
表1 测试集在不同模型上的训练结果
由表1中可以看出,与多语言典型相关分析模型相对比,本文在其模型基础上针对柬汉双语语料稀缺问题进行改进之后,提出了以英语为中间语言的基于多重CCA 算法的双语词向量构建模型,通过该模型得到的英汉双语词向量所对应的双语词对在语义相关度方面与原模型虽有差距但相差甚微,但在英-柬以及汉-柬双语词向量所对应的双语词对语义相关度方面有较为明显的提升,分别提升了6.2 个百分点以及5.5 个百分点。实验结果表明,经过改进之后的多重CCA 算法模型在针对包含柬语词向量的任务处理中效果优于原模型。
4 结束语
本文介绍了一种以英语为中间语言基于多重CCA算法的双语词向量模型,该模型改进了当前大多数模型针对柬语等小语种语言获取双语词向量质量较低、需要大量平行初始语料进行训练的缺点。首先对典型相关分析算法做出简单阐述,然后介绍本文所提出模型的改进方法及模型构建过程,最后与Faruqui 所提出的多语言关联模型进行对比实验,分别用多个测试集对模型所获取双语词向量进行测试,选择斯皮尔曼相关系统作为评价标注对实验结果进行分析。实验结果表明本文提出的模型对于含有柬语的双语词向量在语义相关度方面有较为明显的提升。下一步的工作,对于双语词向量模型的构建方法中,以英语作为桥梁语言连接汉语与柬语,存在一词多义的情况,即一个英文单词包含多个词义,例如英文单词bank,包含银行与河岸两个词义,然而该单词训练得到的词向量却只有一个表征,可能会出现其中一个词义对应相关中文词向量,另一个词义对应相关柬文单词词向量的情况,这样会将两个并不相关的汉语词与柬语词汇联系在一起,从而影响到双语词向量的质量,由于使用的初始语料为可比语料,具有相关主题性,因此该情况出现的可能性已经大大减小,但依然会存在一小部分,因此需要对此做出进一步改进,例如加入双语词典等方法。
