基于长短期记忆神经网络进行评论文本分析
2020-09-04张益茗朱振宇刘恩彤张潇予
张益茗 朱振宇 刘恩彤 张潇予
(1、东北电力大学 计算机学院,吉林 吉林132012 2、哈尔滨商业大学 计算机与信息工程学院,黑龙江 哈尔滨150000 3、中央财经大学 金融学院,北京100081)
1 Word2vec 词嵌入技术原理
自然语言指的是自然地随文化演化的语言,并形成了一个能够表达复杂含义的系统。在这个系统中,词或子是语义的基本单元。在NLP 领域,人们使用词向量来表征词的特征向量,而词嵌入技术即是将词映射到实数域向量的技术。
假设一套自然语言系统中不同词的数量为N,则每一个词都和一个0~N-1 之间的整数一一对应,记为词的索引。为构建词的独热编码向量,我们构建一个长度为N 的全0 向量,并将索引为i 的词的第i 位置1(i 是0~N-1 之间的整数),使得每个词和一个长度为N 的向量一一对应。
训练词嵌入模型的目标是获取目标本文中的周围单词的有用的单词表示。即给定一系列训练单词w1,w2......,wT,其目标函数如公式(1)所示。

其中c 表示训练上下文的大小,一般而言,c 越大训练效果越好,但是相应的训练时间越长。
2 长短期记忆神经网络原理
长短期神经网络(LSTM):
长短期神经网络(LSTM)是递归神经网络(RNN)的一种,它能够从之前的阶段中记住值以供未来使用。在深入了解LSTM以前,我们需要先简单讨论一下神经网络的概况。
(1)人工神经网络
一个神经网络至少包含三层,分别为:输入层、隐藏层和输出层。数据集中特征的数量决定了输入层中的维度或者节点数量,这些节点通过叫做“突触”的链接和隐藏层中创建的节点相连。对于每个输入层的节点,每个链接都带着一些权重。这些权重主要是用来决定哪些输入或信号可能通过或不通过,同时这些权重也体现了隐藏层的强度或程度。一个神经网络主要是通过调整各个突触的权重来进行学习。
(2)递归神经网络(Recurrent Neural Network,RNN)
递归神经网络是神经网络的一个特例,其目标是预测下一步相对于序列中观察到的先前步骤,背后的思想是利用连续观测并从早期阶段学习来预测未来趋势。因此,在猜测下一步时,需要记住早期阶段的数据。
递归神经网络的另一大特点是权重值共享。在RNNs 中,隐藏层充当内部存储器,用于存储在读取顺序数据的早期阶段捕获的信息。而称之为“递归”(Recurrent)是因为它们对序列的每个元素执行相同的任务,并具有利用先前捕获的信息预测未来看不见的连续数据的特征。具体的向前传播公式如下:

其中,W1,W2,W3 是神经网络的三组参数,分别表示输入层和隐藏层间的连接权重、上一时刻隐藏层与下一时刻隐藏层间的连接权重,以及隐藏层和输出层之间的连接权重。a 则表示汇集计算的值,b 表示激活函数计算出来的值,w 是节点间的连接权重,t 表示时刻,h 下标表示隐藏层,k 下标表述输入层。公式(2)表示隐藏层神经元的汇集计算,其中其意项是输入层传入的数据,第二项则表示上一时刻的隐藏层的输出对当前时刻造成的影响。这一个公式是递归神经网络的核心,在其训练的算法中也有体现。公式(3)表示隐藏层向输出层传送的值,公式(4)表示输出层的汇集计算,这两部分和传统神经网络没有差异。
总之,递归神经网络可以通过反向传回权重信息来进一步训练网络,从而获得更好的模型。但是,一般的RNN 网络只记得序列中的几个早期步骤,而不适合记忆更长的数据序列,这个问题会在下面介绍长期短期记忆循环网络时,使用“存储线”进行解决。
(3)长短期记忆网络(Long Short-Term Memory,LSTM)
长短期记忆网络是一种特殊的神经网络,具有记忆数据序列的功能。它可以通过一些伴随着一条记忆线的门来实现对数据早期趋势的记忆。
每个LSTM都是一套单元或系统模块,并捕获其中经过的数据流。这些单元类似于一条输送线,从一个模块连接到另一个模块,传送过去的数据并收集当前的数据。由于在每个单元中都使用的了一些门,所以可以对每个单元中的数据进行处理、过滤或添加到下一个单元。因此,这些门基于sigmoid 函数的神经网络层,可以使得这些单元能够选择性地允许数据通过或处理数据。
3 实验
【数据来源】本文使用斯坦福大学提供的大规模电影评论数据集(Stanford's Large Movie Review Dataset,IMDb)[3],它包含了电影评论网站IMDB 中的50000 余条评论,其中每部电影下的评论不超过30 条,且标记为“正面情感”和“负面情感”的评论数相等。因此,对评论进行随机情感分析,准确率被为50%。该数据集排除了中性评价,即其中的评论全部是情感高度两极化的。总分为10 分,负面评价的分数小于等于4 分,正面评价的分数大于等于7 分。实验中,我们取其中一半为训练集,另一半为测试集。
【构建LSTM训练网络】本文利用Keras 扩展库搭建LSTM结构。Keras 是一个Python 深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型,且具有用户友好的API,可以快速开发深度学习模型的原型。Keras 的主要模型是Sequential(),用户可以通过调用add()去便捷地堆叠自己需要的网络层,进而构成一个整体的模型。
具体的结构如下:
第一层:利用word2vec 技术将词语映射成128 维向量,进行特征提取。
第二层:LSTM模块。具体步骤为:首先,将提取的特征放入输入单元,再将数据流从输入单元送入隐藏单元,同时将另一条数据流从隐藏单元送到输出单元。隐藏单元即神经网络的记忆单元。对一个隐藏单元,使用xt表示第t 步的输入,则目前单元的激活值s=f(Uxt+Wst-1)。其中,f 表示激活函数,本实验中使用ReLU。第t 步的输出经softmax 层计算得到。
本文的模型训练过程以及预测过程可以概括为:
(1)提取相关数据的特征向量,获得训练数据。
(2)将训练集中的数据分批次输入到设定好的模型中,不断更新网络机构中各个节点之间的连接权重,以最小化损失函数的值为目标来尽可能降低真实值和拟合值之间的误差,从而学习到输入变量和输出变量间的非线性特征。
(3)保存训练好的模型参数,将测试集中的数据输入到完成训练的模型中,得出相应的预测值,并于测试集中真实标注的结果进行比对,得到准确率。
具体的参数如表1 所示:

表1 LSTM 电影评论文本LSTM 情感分析模型的参数
【实验结果】本文按照上一章所述流程搭建了评估电影评论文本数据的LSTM模型,共迭代600 次,实验结果如下表2 所示:
表2 给出了本文实验结果,以及在特定迭代步骤下的LSTM 模型训练损失值、训练准确率和测试准确率,可以看出。LSTM模型在600 次迭代内的最高准确率为86.97%,且训练损失和训练准确率始终保持在正常值,说明LSTM模型有效避免了过拟合和梯度消失的问题。
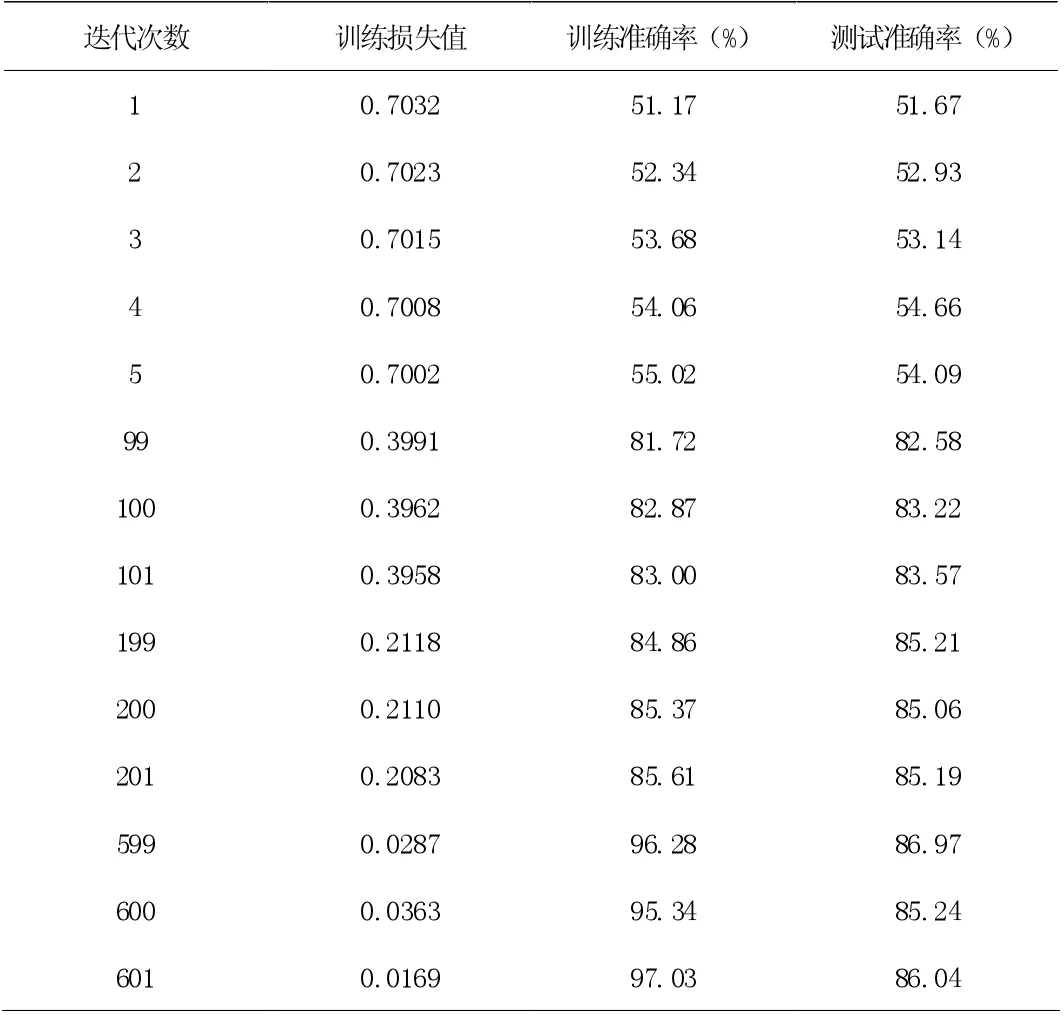
表2
4 结论
本文首先介绍了文本分析研究的背景以及相关的研究,接着介绍了词嵌入技术和LSTM的原理,接下来基于大规模电影评论文本进行基于LSTM模型的情感分析实验,从实证的角度体现了LSTM网络在情感分析问题中的可行性和有效性,对未来深入文本分析研究和情感评估具有一定的指导意义。
