基于特征提取和随机森林的风机故障诊断
2020-09-04梁川
梁川
(江中药业股份有限公司,江西 南昌330000)
随着全球变暖引起的气候问题越来越严重,各国都越来越重视环境和气候问题,首先是化石能源的使用带来的负面影响
[1],因此,可再生能源的发展备受关注。
其中,风力发电是最成熟、经济可行、应用最广泛的新能源发电技术之一[2],风能是利用气流做功和提供能源。在海拔1000米以下的地区,每升高100 米风速增加0.1 米/秒[3],同时,低温地区空气密度增加,风能利用率提高10%,因此在高寒地区安装了大量的风力发电机[4]。在这些高海拔地区,叶片容易结冰,影响风机的性能和安全。因此,对风机叶片结冰预报的研究具有较高的应用价值。
国内外都十分重视风机叶片结冰故障诊断的研究。Simani等[5]提出了数据驱动方法对风机的早期故障进行检测,主要运用了模糊系统和神经网络来描述测量和故障之间的强非线性关系。叶春霖等[6]采用处理不平衡学习算法和随机森林实现风机结冰故障诊断。李大中[7]等提出利用极端梯度提升XGBoost 算法对风机叶片结冰状态进行评估,在风机叶片结冰状态诊断中具有良好的性能。
目前,对于风机叶片故障诊断的研究很多,但准确度还有待提高。本文提出了一种基于ReliefF 特征提取和随机森林的风机结冰故障诊断模型,可以提高故障诊断的准确率,保证故障能够及时发现并处理,确保风机的安全运行。
1 ReliefF 特征选择
Relief 算法是Kira 于1992 年首次提出的一种经典的特征选择算法[8],ReliefF 算法是Relief 算法的扩展,ReliefF 算法是一种常用的过滤式特征权重算法,根据各个特征和类别的相关性赋予特征不同的权重,权重小于某个阈值的特征将被移除,该方法设定了一个“相关统计量”来表达特征的重要性。ReliefF 通常用于多类别标签的特征选择,是根据每个特征和类别的相关性,赋予特征不同的权重[9]。
给出l 类的类标签,ReliefF 算法从训练集中随机抽取一个样本Ri,然后从同一类别中找到K 个Ri的近样本,用Hj(j=1,2,…,K)表示,并从不同类别中找到K 个Ri的近样本,用Mj(c)(j=1,2,…,K)[10]。ReliefF 算法在每个特征维上重复上述过程,得到每个特征的权重如下:
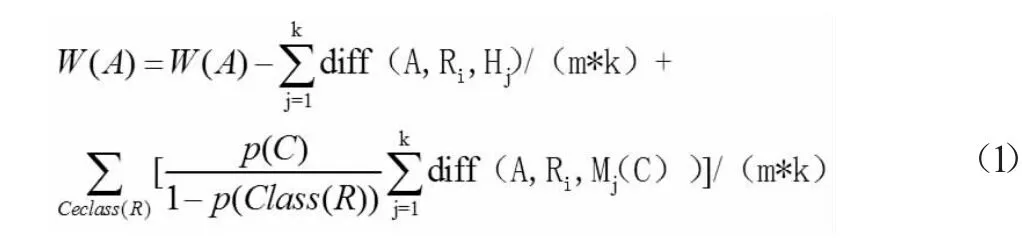
其中m 是迭代次数,p(c)是c 类的概率,diff(A,R1,R2)表示关于特征A 的样本R1和R2之间的差异,其定义为
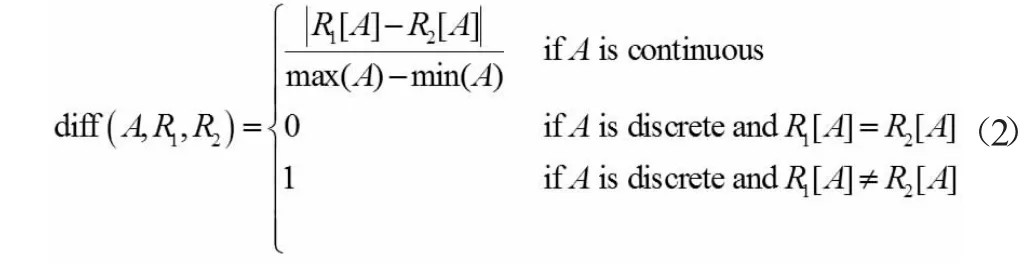
2 随机森林
随机森林(Random Forests,RF)算法最早是由美国科学家Leo 于2001 年提出的一种机器学习算法[11],该算法结合了Bagging 集成学习算法与随机子空间思想,通过有放回的随机采样构造完各个决策树后,综合多个决策树的分类结果来作为最终输出。随机森林算法是由决策树(Decision Forests)算法一步一步发展而来的,发展经过如图1 所示。

图1 决策树发展经过
决策树是一种常用的分类算法,属于有监督学习(Supervised Learning),他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,每个分叉路径则代表某个可能的属性值。对于机器学习中的分类问题,将样本特征输入到决策树模型后,通过一层层的决策,最终得到模型对该特征的预测结果,即样本标签。决策树一般模型如图2 所示。

图2 决策树的一般模型
随机森林是以K 个决策树为基本分类器,进行集成学习后得到一个组合分类器,将样本输入训练好的随机森林模型之后,随机森林模型根据每个决策树的分类结果投票决定出最终的输出[12]。
由于随机森林中各个决策树的训练都是相互独立的,因此在具体使用随机森林算法时可采用并行处理,这将极大的提高随机森林模型的训练速度。随机森林中单个决策树的训练过程如图3 所示。
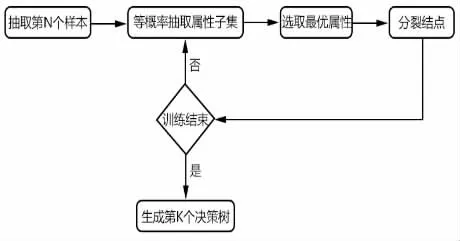
图3 随机森林中单个决策树训练过程
随机森林的特点决定了即便是处理大样本、多维的数据也能有较快的速度,并且还可以根据每个特征在不同的决策树中所做的贡献来进行特征权重分析,同时随机森林是一种非参数分类方法,只需要根据训练样本中特征与标签的对应关系学习分类规则,而不需要分类的先验知识。
3 实例分析
本文采用的数据来自国内某风机组15 号单机运行状态下SCADA 部分数据,有28 个连续数值型变量,除去时间列和没有任何意义的“group”列外,共有26 个连续型数值变量,覆盖了风机的工况、运行环境、状态等多个维度的参数,如功率、叶片转速、叶片角度、风速、风向、温度等,共计393886*28 组数据。
3.1 数据预处理
训练数据集中包含了正常数据、故障数据以及无效数据,分别将其对应的训练样本label 标记为0,1,2。其中,对于无效数据,我们无法将其分成正常数据或是故障数据,因此在实际训练中将其删除。
3.2 特征选择
原始数据有26 个有效特征参数,作为模型的输入维度偏高,训练会耗用过多的时间。因此,本文运用ReliefF 方法可以明确各特征对分类和故障诊断贡献率。其特征权重相关度如图4所示。
图中各个颜色分别表示原始数据进行了10 次迭代的效果,提升贡献率的准确性。
由图可知,wind_direction_mean、yaw_speed、acc_x 等6 个特征的特征权重基本为0,与结果之间基本无关系,可以将26 维数据减少至20 维特征,提升了模型的训练速度。
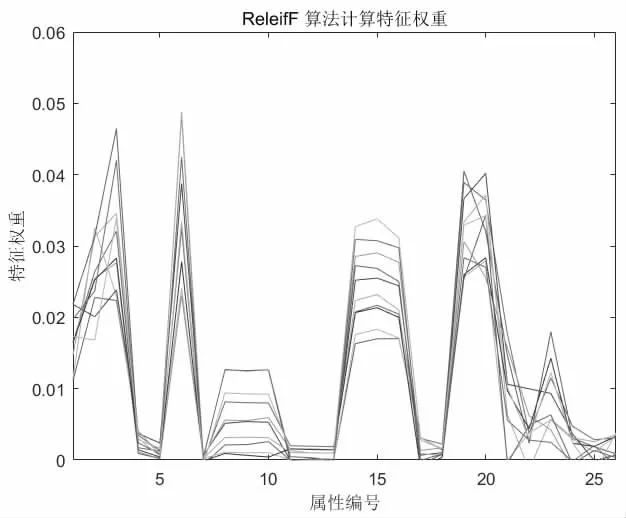
图4 ReliefF 算法特征权重相关度
3.3 故障诊断验证
原始数据经过“去噪”以及基于ReliefF 特征选择之后,数据集具备了一定的完整性。将15 机组风机机组数据按7:3 划分为训练集和测试集。运用训练集对随机森林模型进行训练,测试集带入模型之后获得状态输出,将输出的结果与测试集实际situation 及逆行对比,来评估模型的效果,其流程图如图5 所示。

图5 随机森林模型训练的流程
为判定算法的性能,本文采用了准确率(ACC)、精确率(PRE)、召回率(REC)和F1 Score。各个指标的定义为:

其中,FN/TP/FP/TN 的含义参数如表1。准确率表示诊断正确的结果占总样本的百分比;精确率表示在所有诊断为正的样本中实际为正样本的概率;召回率表示在实际为正的样本中被诊断为正样本的概率;F1 Score 是综合考虑精确率和召回率的一个评价指标。

表1 FN/TP/FP/TN 的含义
将原始数据按照以上步骤“去噪”、特征选择后,将数据划分为训练集和测试集,运用训练集对随机森林模型进行训练,测试集带入模型中验证模型效果,如表2 所示。再分别采用传统的决策树,KNN 和SVM算法实现风机结冰故障诊断,可以得到4 个算法的效果对比,如表3 所示。通过比较,能够发现本文采取的方法的优势。

表2 基于特征选择以及随机森林的风机故障诊断

表3 4 种分类器模型的效果对比
4 结论
本文提出了一种基于ReliefF 特征提取和随机森林算法的风机结冰故障诊断方法,经过实验对比验证,得出该方法在准确度上提升至97%左右,可以有效诊断出风机结冰的故障,及时警报除冰,减少风机因结冰而导致的效率降低和损坏。
本文还采用了适用于不平衡数据的评价指标F1 Score 参数,可以减少因数据不平很而影响模型的评判。
