基于多阶段生成对抗网络的单幅图像阴影去除方法
2020-09-04张淑萍
张淑萍,吴 文,万 毅
(1. 新疆理工学院信息工程系,新疆阿克苏843100; 2. 温州大学电气与电子工程学院,浙江温州325035)
0 引言
阴影广泛存在于图像中,它可以为图像深度预估等计算机视觉研究工作提供诸多重要信息,但也会大幅度增加物体检测、目标跟踪等任务的难度。因此,图像阴影去除一直是图像处理领域的一个研究热点。阴影具有较多形状与类型,而其类型可分为全影和半影:全影位于阴影内部,其光源被全部遮挡,仅在环境光的影响下,其亮度较低,颜色偏黑;半影位于全影至非阴影区域之间,其光源照射逐渐恢复正常,在环境光和光源的综合影响下,其亮度逐渐变强,颜色逐渐恢复正常。
阴影去除方法通常先后需要进行阴影定位和阴影去除。在阴影定位过程中,文献[1-3]中使用的是阴影检测的方法:其中文献[1]的方法是基于统计学习的方法,但该方法过度依赖自定义的阴影特征;文献[2]中基于卷积神经网络(Convolutional Neural Network,CNN)进行阴影检测,但因受到数据集规模的限制与块处理机制的影响,该方法一方面不具有较好的泛化能力,另一方面还需要额外的全局优化步骤以保证图像的全局连贯性。文献[4-6]中使用的人工标记方法虽能准确地定位阴影,但需要大量的额外标注工作。在阴影去除过程中,传统的阴影去除方法可分为光照迁移法[4-6]、梯度域去除法[7-10]以及颜色域去除法[1-2,4,11-12]。文献[4-6]中基于光照迁移法为阴影区域中的图像块找到最佳匹配的非阴影块后进行光照信息填充,但因为需要进行图像分割、聚类等一系列预处理,效率有待提高;文献[8-9]中基于梯度域去除法仅仅只改变半影的梯度变量,因此对于全影的光照变量并不适用;颜色域去除法[2,12]中,文献[2]中使用贝叶斯公式提取蒙版图像以去除图像中的阴影,而文献[12]中使用强度表面恢复法去除阴影。
近年来,端到端的阴影去除方法[13-17]以其运算效率迅速成为主流,该类方法可分为本征分解法[13]和深度学习法[14-17]。文献[13]中基于本征分解绕开了阴影检测环节,但该方法会改变非阴影区域的颜色,违背了阴影去除的初衷。基于深度学习的诸多阴影去除方法[14-17]中:文献[14]中基于CNN,结合图像中阴影的外表与语义信息为阴影图像生成蒙版以得到阴影去除结果;文献[15]中使用两个条件生成对抗网络(conditional Generative Adversarial Networks,cGANs)分别进行阴影检测和阴影去除;文献[16]中基于cGANs 构建阴影图像衰减器以生成多样的图像样本从而提高模型的泛化能力。其中文献[14-16]均使用阴影图像和对应的无阴影图像作监督学习训练,而数据采集的过程是使用相机先拍摄阴影图像,然后撤去不同形状的遮挡物拍摄对应的无阴影图像。此类方法构建的数据集存在一个较大的问题:在拍摄阴影图像和对应的无阴影图像时,由于摄像机曝光和姿势以及环境光照已经发生改变,导致阴影图像和对应无阴影图像组成的图像对在颜色信息、光照信息或空间位置上不一致。这将造成模型无法精确地学习阴影和非阴影之间的内在联系,从而形成阴影恢复区域与非阴影区域的颜色、光照信息不连贯的现象。
为了得到更好阴影去除结果,本文首先结合多任务学习方法对阴影图像进行阴影检测和蒙版生成,其中阴影检测任务旨在标识出不同类型阴影的位置,而蒙版生成任务则是模拟阴影像素和非阴影像素之间的内在联系。在此基础上,分别为不同类型的阴影设计不同的模块分阶段地去除全影和半影,以得到边界过渡自然的去阴影结果。
1 多阶段生成对抗网络
生成对抗网络(Generative Adversarial Network,GAN)[18]中的生成器可以生成一幅逼真的图像,而判别器旨在判断该图像的真假。在训练过程中,生成器G 的目标是尽量生成真实的图像欺骗判别器D,而D旨在把G生成的图片和真实的图片区分开来,二者构成一个动态的“博弈过程”。cGANs[19]进一步拓展了GAN[18],它允许在生成器和判别器中引入额外的条件信息,该信息常常为类别信息。文献[20]中基于cGANs[19]使用图像作为条件信息,训练生成器生成另一幅图像;而文献[21]中将蒙版图像作为条件信息,较为简单地将cGANs应用到阴影去除领域,该方法旨在让生成器生成蒙版,然后使用式(1)计算得到无阴影图像。

根据文献[12,14,22]的研究可知,若阴影图像为x ∈ [0,1]p×q×3,无阴 影 图像为 y ∈ [0,1]p×q×3,则存在蒙 版s ∈ [0,1]p×q×3满足式(1),其中s表示阴影尺度因子。通过大量的实验,笔者发现文献[21]中的方法并不能为阴影图像生成一幅合理的蒙版图像。相较于生成一幅普通的图像,为一幅阴影图像生成一幅逼真且能详细反映光照衰减效应的蒙版图像将更加具有挑战性。原因在于训练样本中同一场景的阴影图像与无阴影图像,因可用数据集中缺乏固定拍摄装置、阴影图像与真实无阴影图像拍摄间隔过久等原因,会导致训练样本产生较大的误差,从而影响文献[21]方法的处理结果。展示两幅不同场景下文献[21]方法的结果如图1 所示,其中:图1(a)为阴影图像;图1(b)为标签(Ground Truth,GT)蒙版;图1(c)为文献[21]方法生成的蒙版;图1(d)为文献[21]方法的阴影去除结果;图1(e)为图1(d)中矩形区域的放大细节。文献[21]方法直接使用生成器为阴影图像生成蒙版图像,然后使用式(1)完成阴影去除。该类方法存在以下两个问题:1)受到训练集误差的诸多限制,生成的蒙版图像在全局范围内均存在值(见图1(c)),这将导致最终的阴影去除图像在非阴影区域也会发生改变(见图1(d)),这违背了阴影去除的初衷;2)阴影存在不同的类型,采用统一的去除策略将会使结果存在明显的阴影边界(见图1(e))。
对于第1)个问题,本文使用阴影检测结果正确地引导蒙版的作用范围,从而减小其对非阴影区域的影响;对于第2)个问题,本文将设计不同的模块应对不同类型的阴影。为了准确地标识全影、半影以及非阴影区域,本文方法不再使用阴影二值掩膜[15-17]简单地标记阴影和非阴影区域。文献[1]中基于阴影检测的结果对阴影图像运用抠图的思路来区分不同的阴影类型,本文则将该思路迁移到深度神经网络中,提出使用Alpha matting 技术[23]预先处理训练样本以得到相应的阴影掩膜M。训练样本中M 的元素Mi的值存在三种情况:Mi= 1用于标识阴影掩膜中第i个元素为全影像素;Mi= 0标识非阴影像素,Mi∈ (0,1)标识半影像素。

图1 文献[21]方法的阴影去除结果Fig.1 Shadow removal results of method in literature[21]
图2 详细展示了本文方法的生成器内部结构:阴影检测子网生成阴影掩膜M^,蒙版生成子网生成蒙版s^。两个不同的模块用于处理不同类型的阴影。全影模块根据阴影掩膜和蒙版之间的约束关系仅仅只修复全影,得到全影去除结果y′;半影模块基于小规模图像复原的构想生成边界复原结果r。最后,使用式(2)结合y′与r 就能得到过渡自然的阴影去除结果y^。

1.1 多任务驱动的生成器
多任务驱动的生成器包含阴影检测任务和蒙版生成任务。其中阴影检测子网为输入图像生成阴影掩膜M^,通过M^的值可以标识不同的阴影类型;而蒙版生成子网试图学习阴影图像到非阴影图像之间的内在联系,从而生成蒙版s^。对于整个生成器而言,这两个部分的功能相对独立,为了避免因网络复杂导致训练无法收敛,对两个子网进行预训练,可以大幅度减少训练时间。阴影检测子网和蒙版生成子网的预训练损失函数分别如式(3)、(4)所示:
其中:N 表示训练样本图像的个数;M 是真实的阴影掩膜,而M^ 表示网络生成的阴影掩膜;s是真实的蒙版,而s^表示网络生成的蒙版。
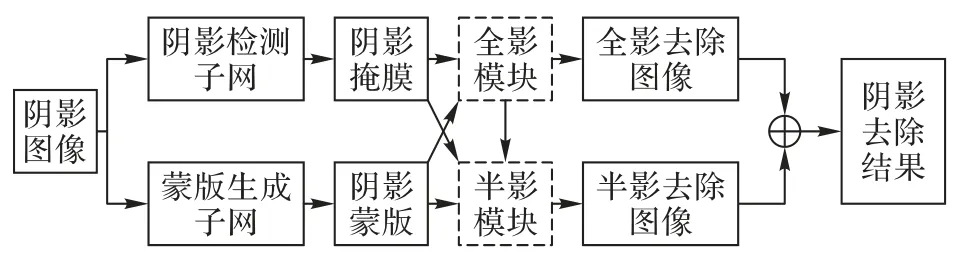
图2 生成器结构Fig. 2 Architecture of generator
1.1.1 全影模块
阴影检测任务和蒙版生成任务完成之后,根据检测结果对蒙版进行切分。面对大面积的全阴影区域,全影模块旨在去除内部阴影而不更改非阴影区域的像素,所以仅需要在阴影掩膜中Mi= 1 的区域提取相应的全影蒙版s^ u = M^ · s^;面对小面积的半阴影区域,为了得到更自然的边界过渡结果,在半阴影模块的处理过程中将不再使用蒙版辅助完成去除任务,而是使用图像修复的思路修复阴影边界。理论上,仅仅只需要提取阴影掩膜中Mi∈(0,1)的区域作为图像的待修复区域;对于Mi= 0的非阴影区域,在与对应区域的蒙版进行像素级乘法运算之后,便不会对非阴影区域产生影响。
但在实际网络推算过程中,阴影检测子网无法100%确定某个像素是否属于阴影。经过超参数分析实验(见2.4 小节),设置 0.25 < Mi< 0.85、Mi≤ 0.25、Mi≥ 0.85 分别作为半影、非阴影以及全影区域的判定标准。
全影模块的内部逻辑如图3 所示,其输入为阴影掩膜M^、蒙版s^ 以及阴影图像x。根据全影模块的需求,提取掩膜中Mi≥0.85 的区域相应的全影蒙版s^u,将其与阴影图像x 进行运算得到全影去除图像y′。而对于Mi≤0.25的非阴影区域和0.25 <Mi<0.85的半阴影区域,暂时保留其像素不进行处理,具体见式(5)。

其中:M^i、s^ui、xi、y^i为M^、s^u、x、y′对应矩阵中的第 i个元素。
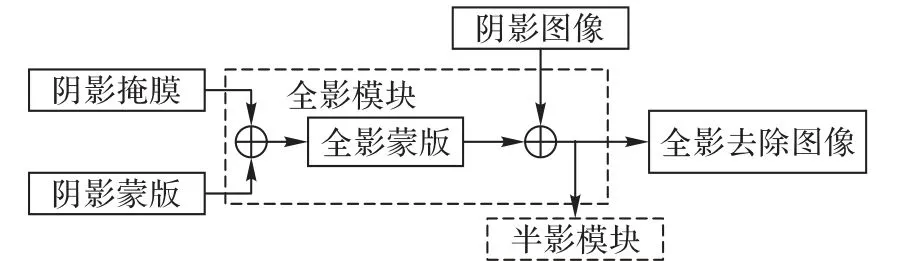
图3 全影模块Fig. 3 Umbra module
1.1.2 半影模块
若不区分阴影的类型,采用一致性的策略处理所有类型的阴影将导致最终结果存在明显的阴影边界[14-17,21],这会极大地影响图像的观赏性与机器理解过程。为此,半影模块结合感知损失,以高层语义信息为引导,在小范围修复阴影边界区域的同时实现阴影边界处的友好过渡。半影模块受到式(2)与最终目标函数的约束,旨在修复半影掩膜M^p对应的图像区域,其内部结构如图4所示。
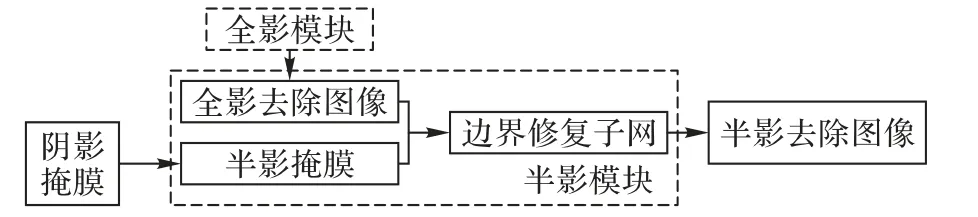
图4 半影模块Fig. 4 Penumbra module
图4 中半影模块的输入为阴影掩膜M^ 以及全影去除图像y′。根据半影模块的需求,提取半影掩膜M^p,基于图像修复的思想,将M^p作为图像y′的待修复区域。与阴影检测子网和蒙版生成子网一样,其功能相对独立,对其进行预训练以使得最终的整体网络在训练时可以较好地达到收敛。其网络输入为三通道的y′以及单通道的M^p构成的四通道图像;其输出为三通道的阴影去除图像。边界复原子网预训练目标函数如式(6)所示。
其中:N为训练样本的个数;y为真实无阴影图像的标签数据;R(·)为边界复原子网的输出。边界修复子网旨在缩小修复区域与GT图像在边界半阴影区域M^p上的像素差异。
受到文献[22]方法的启发,若模型仅仅使用式(6)中的像素差异作为优化目标,这种基于像素的优化方式会忽略图像的全局相似性,导致阴影边界修复的半阴影区域视觉效果较差。本文结合感知损失函数[22]最小化阴影去除图像与真实无阴影图像在图像语义层面的差异,见式(7)。不同的是,本文不再使用预先训练好的深度网络提取GT 图像和阴影去除图像y^ 的特征,而使用后续的判别器提取二者的高级语义特征,同时大大降低了模型的复杂度。
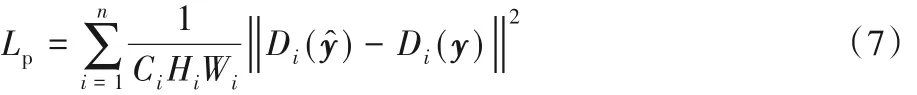
其中:n 为判别器的总层数,y^ 为前后经历两个模块处理得到的无阴影结果,y 为真实的无阴影图像;Di是判别器的第i 层,Ci是第i层对应的通道数,Hi和Wi是第i层特征图的长和宽。
1.1.3 判别器
本文网络中的判别器与文献[20]中类似,本文的判别器旨在判断生成器为阴影图像生成的阴影去除图像是否为真,本质上该阶段为一个图像二分类问题。判别器包含多个卷积块,每个卷积块中,卷积层都紧跟着批标准化[24]和泄露修正线性单元(Leaky Rectified Linear Unit,LReLU)。判别器的最后一层为一个Sigmoid函数,其输出为某对图像为真的概率值。
1.2 组合损失函数
本文网络的损失函数由最小均方损失为主导,辅以平均绝对误差损失和复原损失组合而成,其加权形式如式(8),其作用是在多个子网预训练之后,朝着额外的约束进行最后的优化,因此其构成不包含预训练的损失函数项。

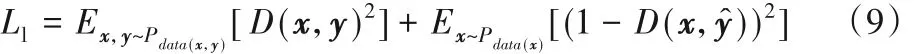
其中:E表示求期望运算;x,y~Pdata(x,y)表示x和y均源自于真实的训练数据集,属于同一数据分布。而x表示输入的阴影图像,y表示真实无阴影图像,y^ 为全影去除图像,D(·)为判别器,例如D(x,y^ )旨在判断生成器生成的阴影去除图像是否为真,其输出为一个0到1的概率值。
此外,式(10)中的平均绝对误差损失则鼓励生成的结果与真实无阴影图像更为贴近。

其中,N表示训练样本的个数。式(10)旨在求得一个平均误差。
2 实验与结果分析
2.1 数据集
将客观数据集 SRD[14]和 ISTD[15]合并为综合数据集。其中,SRD[14]包含 3 088 组阴影和无阴影图像,ISTD[15]包含 1 870组阴影、阴影二值掩膜和无阴影图像。受到文献[16]的启发,使用像素的均方根误差(Root Mean Square Error,RMSE)计算综合数据集中阴影图像和真实无阴影图像在非阴影区域的误差,选取误差较少且场景多样的1 500 组图像。然后,将这1 500组图像中的阴影图像和无阴影图像相减,在三个通道上设置阈值为20,再进行形态学滤波和人工调整错误的阴影像素标签,为数据集得到相应的阴影二值掩膜。
如图5 所示,基于综合筛选数据集中的阴影二值掩膜(图5(b)),使用文献[23]中的抠图方法得到阴影Alpha 掩膜,如图5(b)所示;使用式(1)将图5(d)除以图5(a)得到图5(c)中的样本蒙版;图5(a)和图5(b)用于预训练阴影检测子网,图 5(a)和图 5(c)用于预训练蒙版生成子网,而图 5(a)和图5(d)用于训练本文网络中的生成器与判别器。最后,抽取综合筛选数据集中80%的数据用于本文网络的训练,剩余的20%用于可行性检验。
2.2 训练过程与网络结构
基于 Tensorflow[26]使用 Python 在 Ubuntu 18.04 下完成编程实验,硬件内存为16 GB,八核Inter CPU I7,图像处理器(GPU)采用 NVIDIA GTX 1080Ti。网络中,LReLU 的斜率设置为0.25,使用Adam 作为目标函数的梯度下降方法。与传统的cGANs[19]一样,训练时,生成器与判别器交替更新参数,在600 个循环后停止训练,其中卷积层和反卷积层的权重按均值为0、方差为0.2的正态分布进行初始化。数据增大方法采用常规的剪切、翻转和旋转等方法至256 × 256大小。设置超参数λ1= 0.5,λ2= 0.3,λ3= 0.2。本文网络的生成器采用文献[15]中的UNet结构,UNet结构由一个收缩通道和一个扩张通道组成,其中收缩通道用于提取语境特征,而与其对称的扩张通道则用于图像上采样以得到一幅生成图像。判别器的结构同样与文献[15]一致,包含多个卷积块,每个卷积块中,卷积层都紧跟着批标准化[24]和激活函数LReLU。判别器的最后一层为一个Sigmoid 函数,其输出为某对图像为真的概率值。
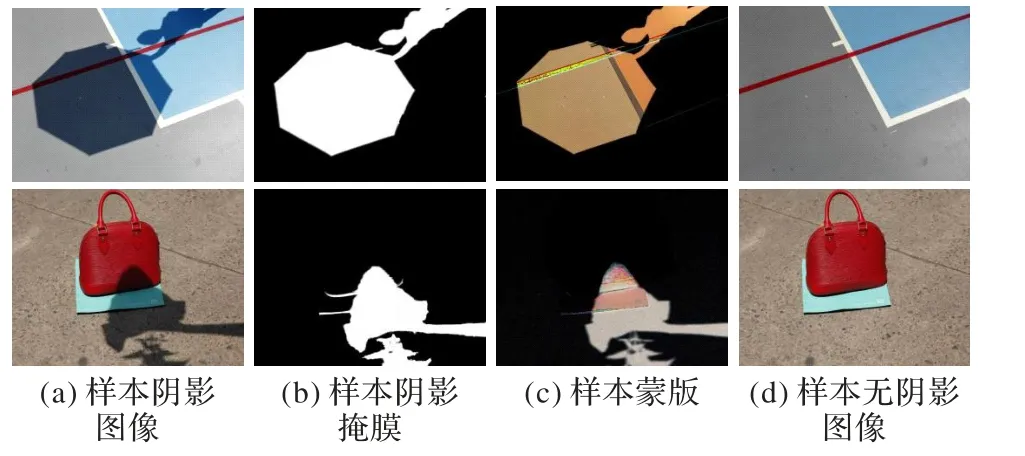
图5 综合筛选数据集示例Fig. 5 Samples of comprehensively filtered dataset
2.3 客观评价指标
使用平衡误差率(Balanced Error Rate,BER)作为阴影检测的衡量指标,计算方法如式(11)所示。
1.6 旺树养分回流引起萎蔫 根据调查,果实萎蔫的树普遍偏旺,立秋后甲口愈合养分回流萎蔫多。这是由于甲口愈合后,根系为了满足恢复生长,调运大量养分,果实营养不足引起萎蔫。
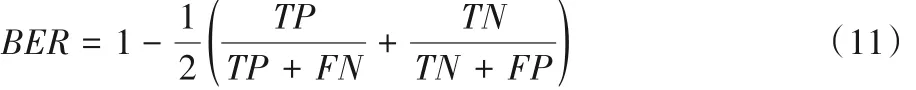
其中:TP、TN、FP和FN分别表示正确生成的阴影像素、正确生成的非阴影像素、错误生成的阴影像素以及错误生成的非阴影像素。
使用RMSE(式(12))和结构相似性(Structural SIMilarity index,SSIM)(式(13))作为阴影去除衡量指标。其中RMSE衡量阴影去除图像和真实无阴影图像之间的误差,而SSIM 反映了结构信息,更符合人类视觉对图像的感知。

其中:I和I′分别代表阴影去除之前和之后的图像,由R、G、B三通道组成;n为输入图像的像素点个数。
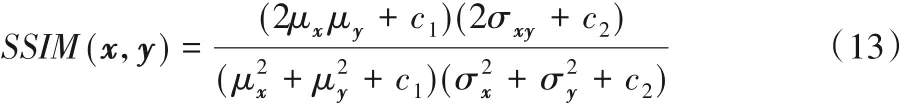
其中:μx是x的平均值,μy是μx的平均值;是x的方差是y的方差,σxy是x和y的协方差;c1=(k1L)2,c2=(k2L)2是用来稳定的常数,其中L是像素值的动态范围,而k1= 0.01,k2=0.03。结构相似性的范围是0 到1,当两张图像一模一样时,SSIM的值等于1。
2.4 可行性分析
在可行性分析环节,本文先后针对不同阴影类型概率阈值的选取以及不同种类损失函数的组合进行分析。首先,在筛选数据集上使用网格搜索参数调优法进行阴影检测的BER分析。划分参数范围区间,设置多组不同的阈值后,将M^ 对比标签阴影检测图像M,分析不同阈值带来的平衡误差率。如表1所示,选取几组参数及其对应各区域的BER作为展示。

表1 超参数分析Tab. 1 Analysis of hyperparameters
通过先验知识非阴影区域和阴影区域中的像素为阴影的概率往往趋向0和1,结合表1中的参数网格分析,设置0.25 <Mi< 0.85 可以很好地覆盖半阴影区域M^p,而Mi≤ 0.25、Mi≥0.85分别作为非阴影和全阴影区域的判定标准。而继续扩大半阴影区域的取值范围会增大待修复边界的面积,从而导致阴影去除结果失真,评估误差增大。
其次,选取不同组合方式的损失函数,对其结果进行RMSE 和SSIM 分析,如表2 所示。实验结果表明,与常规的对抗损失函数La[19]不一样,使用最小均方损失Ll[25]为主导可以得到更好的结果。此外,感知损失Lp与平均绝对误差损失Lm均可以进一步提高去阴影效果。
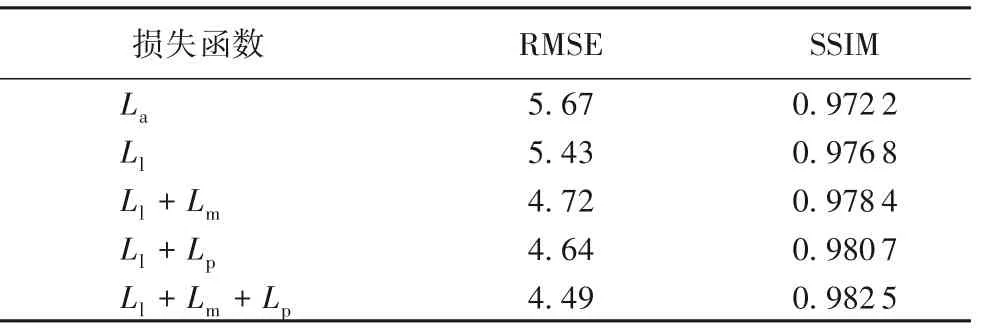
表2 不同种类的损失函数的量化评估Tab. 2 Quantitative evaluation of effects of different loss functions
2.5 结果量化分析
因阴影检测和阴影去除同属图像处理领域中较为热门的研究方向,又因诸多方法无法兼顾阴影检测和蒙版生成,本文从阴影检测、蒙版生成以及最终的阴影去除结果三个角度采用不同场景的图像进行实验对比。
首先,从阴影检测角度对本文方法、文献[1]方法与文献[15]方法进行分析。如图6 所示,在测试集中选取四幅不同场景的图像,其包括跨纹理阴影、软阴影和硬阴影等多种类型的阴影以综合测试不同方法的检测性能。其中:文献[1]方法使用支持向量机(Support Vector Machine,SVM)完成阴影的检测,然后基于物理光照模型去除阴影;文献[15]方法基于cGANs 同时进行阴影检测和阴影去除任务,阴影检测和阴影去除相互学习、相互促进。
图6(a)为待处理的阴影图像;图6(b)为真实阴影二值掩膜;图6(c)为文献[1]方法的阴影检测结果;图6(d)为文献[15]方法的阴影检测结果;图6(f)为本文方法的结果。比较图6(b)和图6(c),因为缺乏鲁棒的阴影特征,传统特征提取的机器学习方法无法准确地检测出较浅的阴影,如第二行水泥地面上伞的阴影和第四行草地上人物阴影。相较于传统的机器学习方法,基于cGANs 的文献[15]方法和本文方法在这个方面表现得相对较好。比较图6(d)和图6(e),因本文使用文献[23]预处理的Alpha Matting 结果作为训练样本,使得本文方法在阴影边界处的检测细节更加丰富。

图6 本文方法与文献[1,15]方法在筛选数据集上的阴影检测结果Fig. 6 Shadow detection results on filtered dataset by the proposed method and the methods in reference[1,15]
其次,从蒙版生成的角度对本文方法和文献[14]方法进行比较。如图7 所示,在测试集中选取四幅不同场景的图像,其包括跨纹理阴影、软阴影和硬阴影等多种类型的阴影以综合测试不同方法的蒙版生成性能。文献[14]方法基于卷积神经网络VGG-16 构建多语境结构,为阴影图像生成蒙版,其初次将深度学习与蒙版生成结合到一起,得到了不错的阴影去除结果。图7(a)为待处理的阴影图像;图7(b)为真实的蒙版图像;图7(c)为文献[14]方法的蒙版结果;图7(d)本文方法的蒙版结果;图7(e)、图7(f)、图7(g)分别为真实无阴影图像、文献[14]方法的无阴影结果以及本文的无阴影结果。对比图7(c)和图7(d),因全影模块的特殊设计,阴影掩膜对阴影蒙版进行了区域限制,使得阴影蒙版几乎不会对非阴影区域产生影响,从而得到更加合理的结果。如图7(g)所示,因专门设计半影模块处理阴影边界区域,本文方法的阴影边界相较于文献[14]方法,过渡更加自然。
如图8 所示,选取三幅场景多样的图像,从阴影去除的角度,将本文方法与文献[1]方法和文献[15]方法进行比较。图8(a)为待处理的阴影图像;图8(b)为真实无阴影图像;图8(c)为文献[1]方法的阴影去除结果;图8(d)为文献[15]方法的阴影去除结果;图8(e)本文方法的阴影去除结果。图8(c)中文献[1]方法因阴影检测不精准导致无法得到满意的阴影去除结果。图8(d)中,文献[15]方法使用深度学习的特征提取能力,相较于文献[1]方法有了较大的提升。但本文方法无论是筛选后的低误差训练数据,还是多任务、多模块驱动的阴影去除框架都能够协助生成器获得更好的阴影去除结果。如图8(e)所示,第一行到第四行中,阴影区域还原更加准确,阴影边界过渡更为自然,非阴影区域几乎没有发生改变。

图7 本文方法与文献[14]方法在筛选数据集上的蒙版生成与阴影去除结果Fig. 7 Shadow matte generation and shadow removal results on filtered dataset by the proposed method and the method in reference[14]

图8 本文方法与文献[1,15]方法在筛选数据集上的阴影去除结果Fig. 8 Shadow removal results on filtered dataset by the proposed method and the methods in reference[1,15]
如图9 所示,选取三幅场景多样的图像,将本文方法与文献[14]的改进方法[21]在SRD[14]数据集上进行了对比以提高实验的公平性。与文献[14]中基于VGG16 完成阴影蒙版的生成方法不一样的是,文献[21]方法额外增加了判别器以端到端的形式生成阴影蒙版;但它与文献[14]方法存在共同的问题是因使用误差较大的训练集而导致生成的阴影蒙版并不准确,进而没有对非阴影区域的阴影蒙版进行约束导致阴影去除图像在全局范围都产生了变化,最后因采用一致性的方法处理不同的阴影类型,导致结果仍然存在清晰的阴影边界。
同理,如图10 所示,将本文方法与文献[15]方法在ISTD[15]数据集上进行了对比。可以清晰地观察得到,第二行中的图(a)和图(b)的阴影图像和相应的真实无阴影图像在非阴影区域存在明显的亮度差异。与现有的大多阴影去除方法一样,文献[15]方法仍然在数据集和阴影去除方法上存在不足,导致如图(c)中的阴影去除区域与非阴影区域存在明显的明暗差异。
在筛选数据集[14-15]上,将本文方法与文献[1]方法、文献[14]方法、文献[15]方法进行量化评估,结果如表3 所示;在SRD[14]数据集和 ISTD[15]数据集上,分别将本文方法与文献[21]方法、文献[15]方法进行量化评估,如表4、5 所示。本文将图像从阴影区域、非阴影区域以及整体区域进行量化分析。首先,针对阴影检测性能,表3 中的平衡误差率越低表示阴影检测越准确,相较于文献[15]方法,本文方法可以将图像整体误差率进一步降低4.39%。其次,RMSE 越小说明阴影去除图像与真实无阴影图像之间的误差越小,SSIM 越大说明阴影去除图像从结构上与真实无阴影图像之间更为相似。根据表3,在筛选数据集[14-15]上,相较于文献[15]方法,本文方法在RMSE 上降低了13.32%,在结构相似性上提高了0.44%;根据表4,在SRD[14]数据集上,相较于文献[21]方法,本文方法在RMSE 上降低了18.07%,在结构相似性上提高了0.65%;根据表5,在ISTD[15]数据集上,相较于文献[15]方法,本文方法在RMSE 上降低了10.57%,在结构相似性上提高了0.21%。纵向比较表 3 与表 5 中文献[15]方法的 RMSE 和SSIM 的值,同样可以发现通过筛选数据集降低数据集的误差可以小幅度提升阴影去除的性能。

图9 本文方法与文献[21]方法在SRD数据集上的蒙版生成和阴影去除效果Fig. 9 Shadow matte generation and shadow removal results on SRD dataset by the proposed method and the method in reference[21]

图10 本文方法与文献[15]方法在ISTD数据集上的阴影去除结果Fig. 10 Shadow removal results on ISTD dataset by the proposed method and the method in reference[15]

表3 本文方法与文献[1,14,15]方法在筛选数据集上的评价指标对比Tab. 3 Comparison of evaluation indicators on filtered dataset by the proposed method and the methods in reference[1,14,15]

表4 本文方法与文献[21]方法在SRD数据集上的像素均方根误差与结构相似性Tab. 4 RMSE and SSIM on SRD dataset by the proposed method and the methods in reference[21]
3 结语
为了得到阴影边界过渡自然的阴影去除图像,基于生成对抗网络提出一种新颖的多阶段去除方法。该网络中的生成器兼具阴影检测与阴影去除的能力,阴影检测子网与蒙版生成子网为全影模块、半影模块提供准确的待处理区域。基于小区域的图像复原思路,辅以感知损失降低生成结果在图像语义的差异,阴影边界的过渡将更为自然。未来将研究深度学习方法在面临新数据集时性能下降的问题,实现阴影去除的域迁移(Domain Shift)方法。
