基于双流非局部残差网络的行为识别方法
2020-09-04陈淑荣
周 云,陈淑荣
(上海海事大学信息工程学院,上海201306)
0 引言
行为识别是对视频图像中的人体行为动作进行特征提取、分析,并自动识别出其类别,在日常生活中有着广泛应用。如智能监控中行人的异常行为检测、人机交互、运动分析等。
传统的行为识别方法通常由人工提取特征,再进行特征编码和分类器训练,最后完成行为识别,耗时长且泛化性差。随着深度学习的发展,卷积神经网络(Convolutional Neural Nets,CNN)针对人体运动行为提取的特征更加多样,鲁棒性更好,在行为识别中得到了广泛应用。Ji等[2]通过引入时间信息结合空间维度构成三维CNN,从空间和时间维度提取特征,进行3D 卷积,以捕捉多个连续帧中的运动信息,最后通过支持向量机(Support Vector Machine,SVM)进行行为分类得到最终识别结果;该方法速度较快,但精度低。Simonyan 等[3]提出了双流卷积神经网络(Two-Stream Convolutional neural Network,Two-Stream ConvNet),利用视频的RGB(Red-Green-Blue)图像和密集光流图像分别训练CNN模型,并将两个分支网络的Softmax 输出进行融合,得到的最终行为识别精度有所提高。Wang 等[4]提出了更深的 Two-Stream ConvNet 结构,解决了较小数据集过度训练的问题,改善了识别精度。
为进一步提高人体行为识别的准确率,增强网络的特征表达能力,本文结合残差网络和非局部神经网络的思想,提出了一种基于双流非局部残差网络(Non-local Residual Network,NL-ResNet)的行为识别模型。首先对视频数据集进行预处理,利用角落裁剪和多尺度裁剪方法进行数据增强和归一化,避免模型训练中出现过拟合现象;然后通过两组NL-ResNet分别提取视频的空间和时间特征,该网络能充分利用所有残差块的局部特征,并传递到非局部特征提取模块(Non-Local block,NL block)[6]中获取局部特征的全局信息,以增强整张特征图的语义信息,弥补特征图逐层传递时的信息丢失;同时网络中采用A-softmax 损失函数[7]以角度约束类别分类,提高行为动作的分类精度;最后将两路输出加权融合得到最终的识别结果。
1 双流卷积神经网络模型
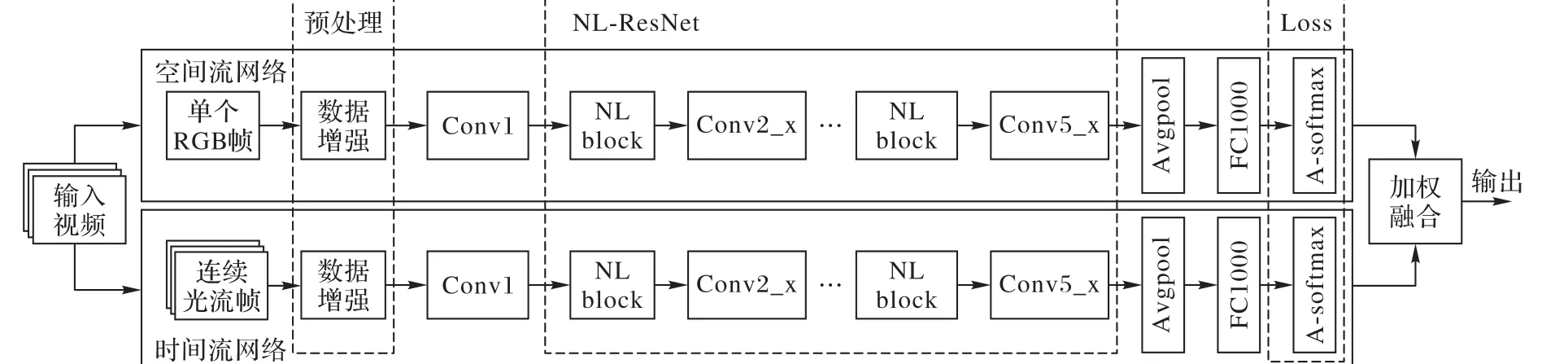
图1 双流NL-ResNet模型结构Fig. 1 Structure of the two-stream NL-ResNet model
传统双流CNN 包含卷积、池化、全连接层,利用卷积核仅能提取样本的局部特征,易导致人体行为的部分信息丢失而影响最终的识别效果。本文以残差网络为基础网络,通过引入NL block,更好地融合局部特征全局信息,模型结构如图1所示,主要包括数据预处理、NL-ResNet 特征提取、A-softmax loss 三部分。首先对待输入视频进行预处理,提取RGB 帧和密集光流图进行数据增强及归一化,分别输入到NL-ResNet中进行级联的卷积、池化、非局部计算以提取视频的表观信息和运动信息;同时,在两路分类层采用A-softmax 损失函数,使相似动作类间距离更大、类内距离更小,提升模型分类效果;最后将两路的A-softmax 分类结果加权融合,得出行为识别的最终结果。
1.1 数据预处理
为避免深度双流卷积网络模型训练出现过度拟合,实验中采用了角落裁剪和多尺度裁剪的预处理方法,对RGB 图像和光流图像进行数据集扩充和增强处理。首先将输入图像大小固定为256 × 340,从{256,224,192,168}中随机选取裁剪宽度和高度,裁剪图像的4个角和1个中心如图2所示的a、b、c、d 和e,实现对数据集的扩充,以及对输入图像的多尺度和差异性增强,并将裁剪后的图像归一化为224 × 224,作为双路网络的输入,从而解决了因随机裁剪导致的裁剪区域中间化而使训练损失下降很快,进而产生过度拟合的问题。
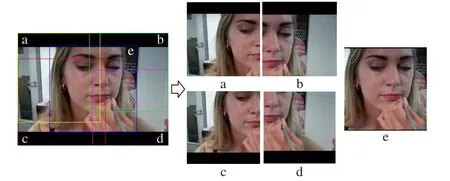
图2 裁剪效果示意图Fig. 2 Schematic diagram of cropping effect
1.2 NL-ResNet特征提取模块
传统的双流卷积神经网络常采用CNN 分别提取时间域运动信息和空间域表观信息,网络越深提取的特征越抽象,语义信息越丰富,但网络深度达到一定程度时会导致梯度爆炸或梯度消失。此外,传统CNN 网络主要是靠级联卷积层提取局部特征,在全连接层整合得到全局信息,因此,一些局部重要信息会在逐层提取中损失,且给全连接层带来大量参数。本文采用图1中的NL-ResNet对行为特征进行提取,通过引入批量归一化(Batch Normalization,BN)和NL block 解决了梯度爆炸问题,弥补了特征信息的丢失,能够较好地提取视频的表观信息和运动信息,提升识别效果。具体原理如图3 所示,对一组RGB 和光流输入图像,首先分别用卷积核为7× 7、步长为2的Conv1卷积层进行浅层特征提取,为防止深度网络梯度爆炸,在每一个卷积层后都加入BN 层进行批量归一化,使网络优化不受初始化、学习率的影响,加快网络训练的收敛。之后经最大池化处理后,特征图大小减半,并产生64 维特征图,接着采用两组并联的NL-Res2、NL-Res3、NL-Res4 和NL-Res5进行非局部运算、卷积操作和BN 处理,提取图像的全局信息和局部特征,经平均池化在全连接层将行为特征整合为具有高层语义的特征向量。

图3 NL-ResNet结构Fig. 3 Structure of NL-ResNet
BN 层的本质是对网络的每一层输出作归一化处理(归一化至:均值为0,方差为1),然后再进入网络的下一层。归一化公式如式(1)、(2)所示。
假设一层有d维输入:

每一维的归一化为:

其中E[x(k)]和Var[x(k)]分别指各神经元输入值的平均值和方差。
若仅仅使用上面的归一化公式,对网络某一层A 的输出数据作归一化,然后送入网络下一层B,这样会影响本层网络A 所学习到的特征。比如网络中间某一层学习到的特征数据本身就分布在S 型激活函数的两侧,若强制将它作归一化处理,把数据变换成分布于S 函数的中间部分,如此就相当于这一层网络所学习到的特征分布被破坏了。为了恢复出原始的某一层所学到的特征,对x^(k)进行变换重构,引入可学习重构参数γ和β,如式(3)所示:
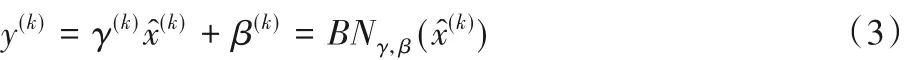
网络训练时每一个神经元x(k)都会产生一对参数γ 和β,通过反向传播不断更新,当网络便可以学习恢复出原始网络所要学习的特征分布。BN层的最终输出为y(k)。
为了更好地融合局部特征的全局信息,NL block 通过对经过卷积、BN 处理、最大池化后得到的特征图进行非局部计算,获得特征图全部像素点之间的相关性信息,进而提取行为特征的全局信息,之后再输入到下一级残差块中继续提取局部特征。NL block对特征点的信息补偿,使得NL-ResNet提取的行为特征更丰富。以图3的NL-Res2中的NL block为例,处理过程如图4所示。
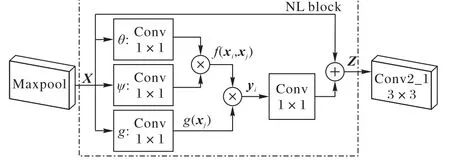
图4 NL-Res2中的NL block处理过程Fig. 4 NL block processing in NL-Res2
最大池化后产生112×112 大小的特征图X,通道数为64,经过 θ、φ、g 三个 1*1 卷积通道得到 Wθxi、Wφxj、Wgxj,其中 Wθ、Wφ、Wg均为 1*1 卷积的待学习权值参数,i 和 j 为像素坐标,xi和xj表示位置i 和j 的特征图像。通过f(xi,xj)函数计算特征图位置i 与其他所有位置j 之间的相关性权重,一元函数g(xj)计算输入信号在位置j 的表征,具体计算公式如式(4)、(5)所示:

将f(xi,xj)与g(xj)作矩阵乘法运算,即计算所有的xj加权后的结果,并将结果通过响应因子C(x)进行标准化得到最终的响应值yi,此时,yi便包含了xi与周围所有像素点之间相关性的信息。这就是非局部计算,公式如式(6)所示:

NL block 是一个残差结构,非局部计算结果yi经过一个1*1 卷积通道得到Wzyi,将Wzyi与原输入xi相加得出最终的输出信号zi,如式(7)所示:

此时zi包含特征图xi中所有像素点的相关性信息,将带有全局信息的新特征图Z输入到NL-Res2的Conv2_1中,如图3 所示,经过两组并联的卷积、BN 和ReLU 激活处理得到的特征图与特征图Z 相加,依次输入到级联的NL-Res3、NL-Res4、NL-Res5 中继续进行特征提取,得到包含较丰富的全局信息和局部信息的特征图。
1.3 A-softmax损失函数
通常,CNN 多采用softmax 损失函数进行多分类任务,原始的softmax损失是一个交叉熵损失,如式(8)所示:
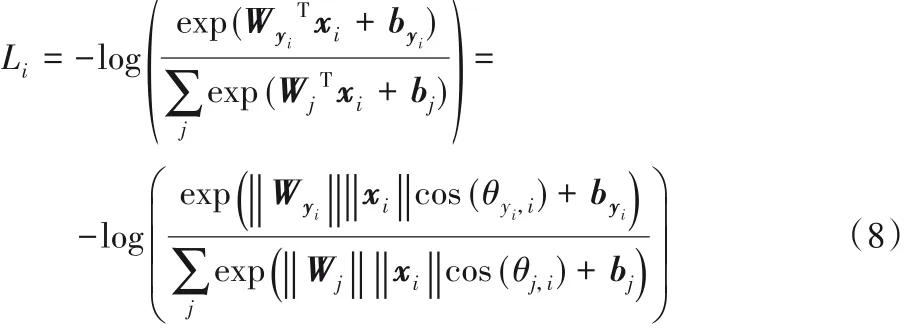
式中:xi表示第 i 个特征向量;yi表示类别标签;W 表示权重;b为 偏 置 项 ;θyi,i表 示 行 为 特 征 xi与 权 重 Wyi之 间 的 夹 角 ;j ∈ [1,K],K为类别总数。
由于原始softmax 损失函数在进行分类时,类间距小且对类内距离的控制不够易导致分类准确率低,因此本文在归一化权值和角度间距上对传统softmax 损失函数进行了改进,利用分类角度进行更精细的学习和分类误差抑制,使类内距离更小,类间距离更大,从而实现最大类内距离小于最小类间距离的识别标准,完成本文行为动作的分类任务,提升行为分类的准确率。改进后的损失函数为A-softmax 损失函数[7],如式(9)所示:

A-softmax 损失函数将式(8)中全连接层的权值W 和偏置b 设置为,使分类决策边界仅取决于W 和x之间的角度,若θyi,i比其他所有类的角度都小,则输入特征xi属于 yi类。另外,在 ψ(θyi,i)中对分类角度 θyi,i添加了 m 倍数限制,从而产生一个决策余量,使分类决策函数更加精细。m取值越大,学习到的特征区分性越强,但学习难度也更大,本文选取m = 4,经多次实验验证能取得较好的分类识别效果。
2 实验结果与分析
2.1 实验环境与数据
本文实验在Windows 10 系统下进行,计算机显卡为NVIDIA GeForce GTX 1050Ti,采用PyTorch深度学习框架。
实验选用UCF101 视频数据集,共13 320 段视频样本,包含101个视频类别,其中每类动作由25个人分别完成,每人做4~7 组,视频分辨率为320 × 240。实验中将数据集划分成训练集和测试集两部分,其中9 537 个视频作为训练集,3 783 个视频作为测试集。为满足双流卷积神经网络的训练需求,分别提取视频集的RGB 图像和光流图像,对光流图的提取采用OpenCV 视觉库中稠密光流帧提取方法中的TVL1(Total Variation-L1)光流算法[10],分别提取水平方向和垂直方向的光流序列。
2.2 模型训练过程
用ImageNet 预训练好的ResNet18 卷积神经网络初始化特征并提取网络卷积层权重,采用随机梯度下降算法优化整个网络模型。将数据预处理后的RGB 图和光流图归一化为224 × 224,空间流输入单个 RGB 帧,而时间流输入L个连续的光流图,将光流图在时间域上的长度设置为L= 10[3]。网络训练的初始学习率设为0.001,空间流网络每经过150 个epoch 学习率降为原来的10%,共训练250 个epoch;时间流网络每经过200 个epoch 学习率降为原来的10%,共训练350 个epoch,动量为0.9,批次大小为4。根据UCF101 数据库的行为类别数,将双流NL-ResNet 网络模型的全连接层的参数设置为101。
空间流和时间流网络融合采用加权线性组合各自预测分数的方法,经多次实验验证,将时间网络的权重设置为2,空间网络的权重设置为1,得到的最终分类结果效果最好。
2.3 实验结果分析
实验中采用训练损失loss 和准确率acc(accuracy)曲线判断模型训练是否过拟合,以验证本文角落裁剪和多尺度裁剪相结合的数据预处理方法的有效性。利用传统双流卷积神经网络,在原始和增强后的UCF101 数据集上分别实验,图5 给出了原始和增强后的UCF101数据集loss和acc曲线比较:图5(a)原始数据集训练损失值小、准确率高,测试损失值大、准确率低,出现了过度拟合;而图5(b)增强后的数据集训练损失值小、准确率高,测试损失值小、准确率高,有效解决了模型过度拟合的问题,表明了本文数据预处理方法的有效性。
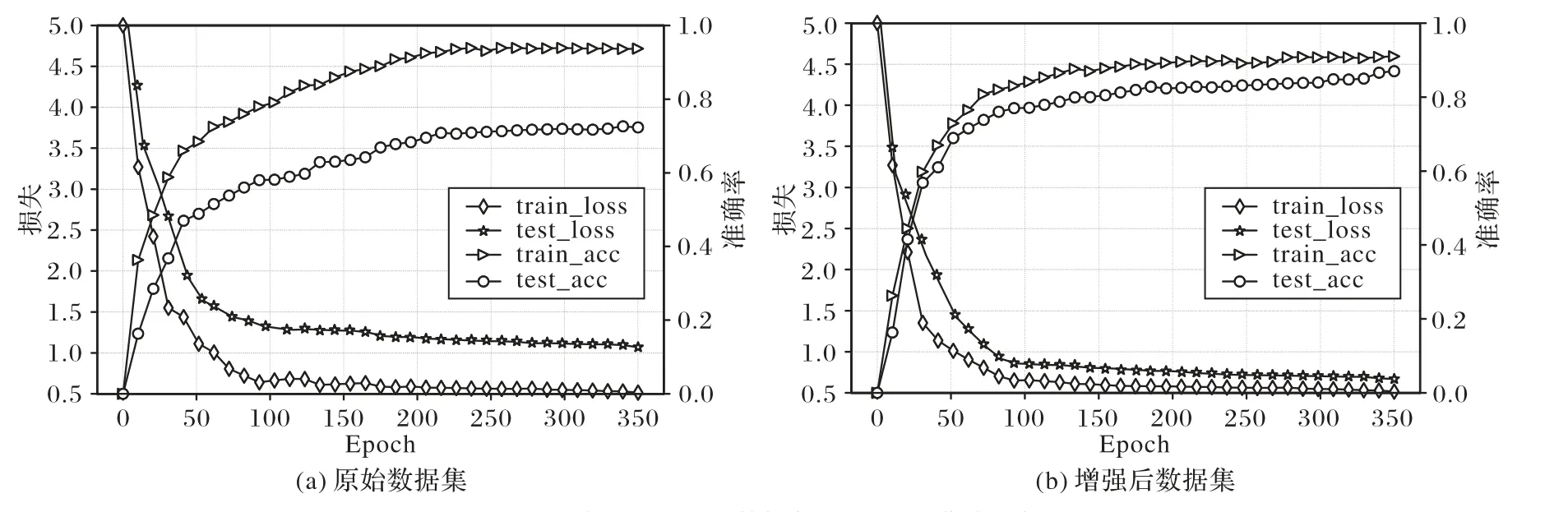
图5 原始和增强后的数据集loss和acc曲线比较Fig.5 Comparison of loss and acc curves of original and enhanced datasets
接下来,为验证本文方法提出的引入NL block 对网络模型的作用,在UCF101 数据集上对比了双流网络以ResNet18为基础,加入不同数量NL block 的设计方案对网络性能的影响,结果如表1 所示。实验表明更多的NL block 通常有更好的结果,能够捕获更多的依赖信息。

表1 加入不同数量NL block对网络的影响Tab. 1 Impact of adding different numbers of NL blocks on the network
最后,为验证本文A-softmax 损失函数的有效性以及模型的总体性能,首先选择VGG16的双流CNN结构模型和softmax损失函数,输入大小为224 × 224 的单帧RGB 和10 对堆叠光流图,本文将其称之为模型1;其次,以相同输入,选择以ResNet18 为基础网络的双流CNN 模型进行实验,称之为模型2;在模型2 的基础上损失层采用A-softmax 损失函数进行实验,称之为模型3;之后,以模型3 为基础,在网络的每个卷积层后添加一个BN 层进行实验,称之为模型4;而本文模型在模型4 的基础上在ResNet18 中加入8 个NL block 进行实验。五种模型设置如表2所示。
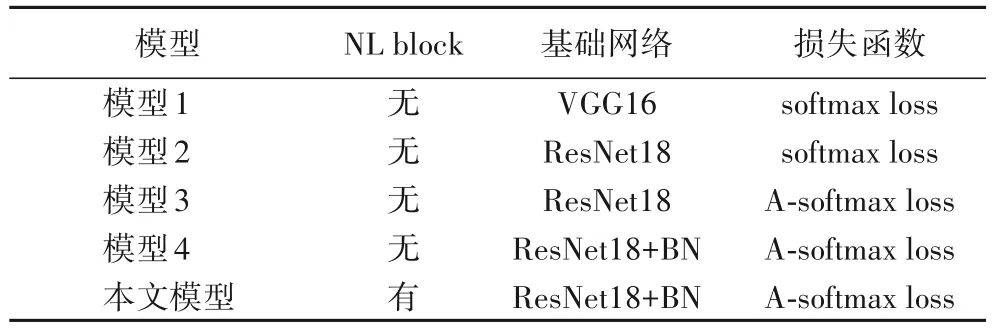
表2 五种不同模型的设置Tab. 2 Settings of five different models
实验结果对比如图6 所示,在输入相同的情况下,模型3相较于模型2 在数据集UCF101 上的测试准确率提升了0.9个百分点,表明模型分类层采用A-softmax 损失函数能够使不同类别之间的距离更大,相同类别之间的距离更小,得到更精细的分类结果,进而有效提高行为识别的准确率。而本文模型相较于模型2的测试准确率又提升了1.3个百分点,表明在ResNet 每一个残差块之前加入Non-local 特征提取模块能更好地融合特征图的全局信息,提高模型识别的准确率。
将本文模型与传统双流卷积神经网络(Two-Stream ConvNet)[3]模 型 、3D 卷 积 神 经 网 络( Convolutional neural network based on 3D-gradients,C3D)[2]模型、非常深的双流卷积神经网络(Very Deep Two-Stream ConvNets)[4]模型和隐藏式双流卷积神经网络(Hidden Two-Stream ConvNets)[9]模型等现有方法在相同的实验环境和数据集上进行实验对比,结果如表3 所示,可以看出,本文方法比其他方法在行为识别的识别准确率上有所提高。
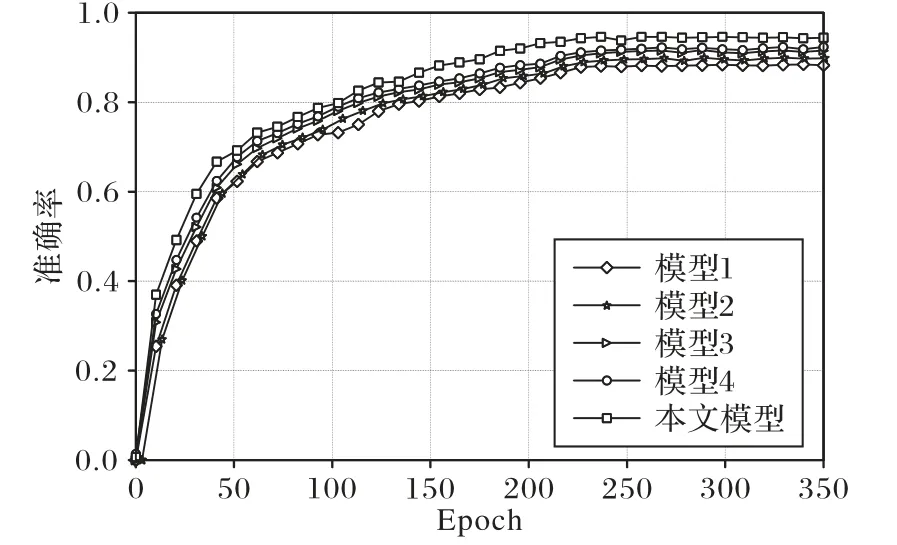
图6 不同模型的准确率曲线Fig. 6 Accuracy curves of different models

表3 本文方法与现有方法的行为识别准确率比较Tab. 3 Comparison of behavior recognition accuracy between the proposed method and existing methods
3 结语
本文建立了一种基于非局部残差双流卷积神经网络的人体行为识别方法:首先利用空间流和时间流网络分别提取视频的空间表观信息和运动信息,再采用角落裁剪策略和多尺度裁剪方法对输入数据作增强处理;然后通过NL block 和残差块卷积分别提取图像的非局部信息和局部信息;最后用A-softmax 通过角度学习对各行为样本进行更精细化分类,得出相应的概率矢量,将空间流网络和时间流网络的A-softmax输出进行加权融合,在UCF101 数据集上得到最终行为识别准确率为93.5%,验证了本文方法的有效性。
