面向中文词汇语义相关性计算的ConceptNet与HowNet对比分析
2020-09-03曹静雯王铁鑫杨志斌李文心
曹静雯,王铁鑫,2,杨志斌,2,李文心
1(南京航空航天大学 计算机科学与技术学院,南京 211106)
2(高安全系统的软件开发与验证技术-工信部重点实验室,南京 211106)E-mail:tiexin.wang@nuaa.edu.cn
1 引 言
在大数据时代,数据和信息处理成为众多领域的共同关注点.大量的文本信息,如新闻,需求文档等,由相关人员使用自然语言撰写;由于自然语言的二义性,文本信息在传递过程中存在由于理解上的差异导致被错误理解、传达的可能性.对文本信息进行语义分析,语义消歧等处理是有必要的.
自然语言使用词语作为基本单位;词语形成句子,句子组成文本.文本的语义由所包含的所有句子的语义构成,而句子的语义由词语的语义及语法规则共同决定.作为自然语言最基本的语义单元,词语(词汇)具有特定的语义和内涵.对于自然人,在特定的场景使用语言一般不会引起歧义[1].计算机处理的语言具有多源性、语境异构等特点,计算机没有自主辨别语言歧义的能力.因而需要人工辅助消除文本信息的歧义,其中涉及到的语义知识及推理,需要应用自然语言处理NLP(Natural Language Processing)技术[2]完成.
NLP有众多研究方向,其中语义分析是将文本转换成可计算知识的过程.语义分析在NLP、信息检索、信息过滤、信息分类和语义挖掘中具有广泛的应用.
为了提高语义分析的准确性,需要搜集、创建大规模的语义知识资源,包括机器可处理的语义字典等.语义知识库是语义字典的一种具体实现形式[3].
目前已有的语义知识库包括:WordNet、ConceptNet[4]、HowNet[5]、DBpedia、FrameNet等;大部分语义知识库以英文词汇为构建基础,而HowNet是针对中文词汇建立的,ConceptNet也提供对中文词汇语义计算的支持.
语义具有领域性,即同一词汇在不同语境下的解释存在差异.不同的语义知识库,对词汇有不同的解释并在词汇间定义了特定的语义关系;基于不同的语义知识库(或语料库),科研人员提出了不同的语义相关性计算方法.
面向中文词汇语义相关性计算问题,本文以两种支持中文语义的知识库“HowNet”及“ConceptNet”为基础,提出中文词汇语义相关性的具体计算理论与方法.
本文主要贡献如下:
1)分析、比较HowNet与ConceptNet语义知识库的结构、特征及应用案例;
2)面向两种知识库各提出一种检测中文词汇语义关系的方法,并通过实验案例比较,得出HowNet适用于语义相似度检测而ConceptNet适用于语义相关度检测的结论;
3)探索性地提出结合两种知识库的语义检测算法,以期提高检测结果的准确性,扩展语义检测的适用范围.
本文结构如下:第二节主要分析HowNet和ConceptNet的结构及特点;第三节介绍关于两种知识库已有的研究工作;第四节面向两种知识库分别提出语义相关性计算方法;第五节通过案例对第四节提出的计算方法进行综合比较;最后一节为总结和展望.
2 语义知识库
2.1 HowNet
HowNet是动态维护、持续更新的语义知识库;本文中使用的HowNet是官网于 2000年发布的(免费)版本,其中语义词典中的总记录数超过120,000条(仍在持续扩充).
HowNet中定义了两个基本概念“义原”和“义项”[5].
定义1.义原
义原是无法分割的最小意义单位.判断增加新义原的首要原则是现有的义原集合是否能够描述所有的概念.
定义2.义项
义项是一组义原的集合,描述了某个词语的一项意思.义项中的第一个义原为主义原,是义项最基本的意义.
定义3.概念
概念是词语的义项集合,一个词语在不同的语境有不同的意思,每个意思对应一个义项.
HowNet中定义了1618个义原,分为以下9类:
1)Event|事件
2)entity|实体
3)attribute|属性
4)aValue|属性值
5)AttributeValue|属性和属性值
6)syntax|语法
7)qValue|数量值
8)SecondaryFeature|二特(二级特征)
9)EventRoleAndFeatures|动态角色与特征
每个类型的义原构成一棵义原分类树;对于同一棵分类树,可以计算其上任意两个义原之间的义原距离.
定义4.义原和祖先的距离
义原所在层数和祖先所在层数的数值之差.
定义5.义原距离
即两个义原距离他们最近公共祖先的距离之和.
义原分类树是HowNet定义、维护语义关系的一个基础文件.图1是义原分类树的示意.
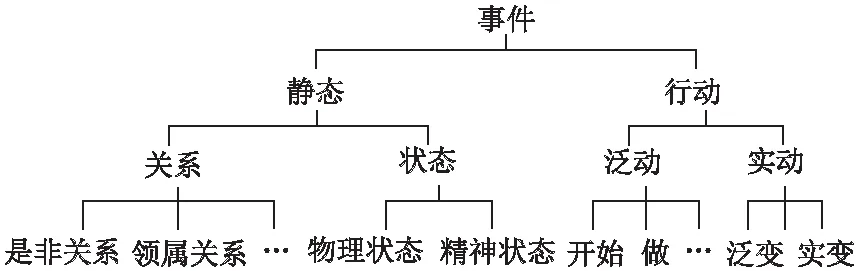
图1 义原分类树示意
在一棵义原分类树上,两个义原的义原距离越小,则它们之间的相似性越高.义原位于的子树(以最近公共祖先为根节点的树)越低,则义原的分类越细致.在同一棵树、同等义原距离下,接近叶子节点的义原之间的相似度要高于接近树根的义原之间的相似度.
语义词典是HowNet定义语义关系的另一个基础文件,由多行记录组成,每条记录包括:一个中文词语、对应的英文单词,两个词的词性和词的义项(在同一条记录中,中英文词语拥有相同的义项)等.语义词典的记录结构如图2所示.
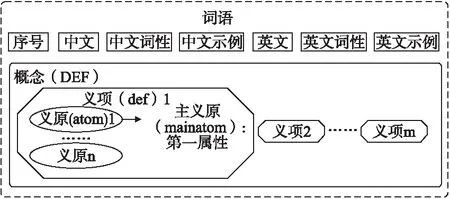
图2 HowNet语义词典中的记录结构
以词“偶然性”为例,图3是其在HowNet语义词典中的存储示例.
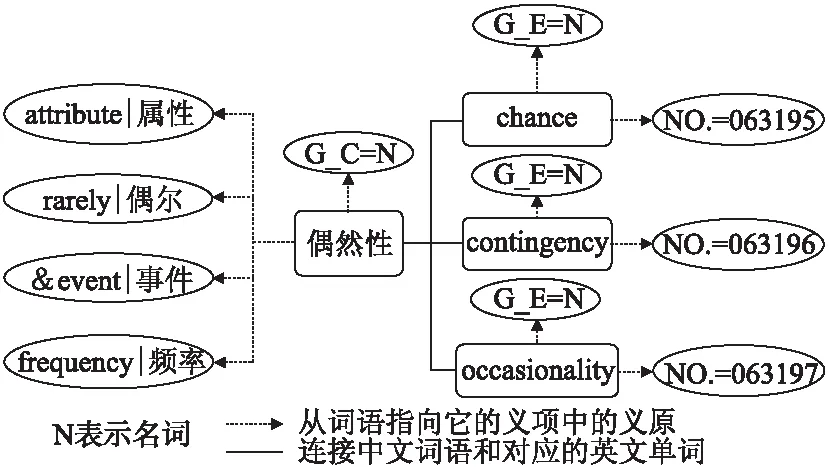
图3 HowNet语义词典中关于“偶然性”词的定义
“偶然性”代表一个中文词汇.左边是由四个义原组成的该词的义项.“G_C =”和“G_E =”指明中文词语的词性和英语单词的词性.“NO.=”指明词在字典中的序号.一个中文词汇往往可被翻译成多个英语单词,例如“偶然性”到三个英语单词“chance”、“contingency”、“occasionality”.
本文中基于HowNet的中文词汇语义相关性计算所用到的相关知识及推理基础来自于“义原分类树”和“语义词典”两个基本文件.
2.2 ConceptNet
ConceptNet是基于OMCS(Open Mind Common Sense)数据库构建的语义网络[4].它以有向网的形式存储信息,包括以下几个结构:
定义6.节点
节点存储概念,概念代表一组密切相关的自然语言短语,可以是名词短语、动词短语、形容词短语或从句.节点拥有自然语言标签,例如“en”表示英语;“zh”表示中文.
节点分为头节点和尾节点:头节点是关系的发出方,例如“车”和“工具”具有“IsA”关系,其中“车”为关系发出方:“车是工具”.尾节点是关系的接收方,如“工具”.
定义7.边(断言)
边代表一般知识的事实,是具有主谓宾的RDF(Resource Description Framework:资源描述框架)语句,如“车是工具”.
边用于指明关系,ConceptNet使用固定的关系集合,如“RelatedTo”等.边上有权重,表示断言可信度的强弱.
定义8.关系
关系分为单向关系和双向关系:
单向(有向)关系,如“PartOf”,一个节点是另一个节点的一部分等:“轮胎”和“车”,“轮胎是车的一部分”.
双向关系,例如“Synonym”,两个节点上的概念互为同义词:“human”和“人”,human是人的英文单词.
图4是ConceptNet中词汇“車”节点及连接到该节点的边,此处仅显示其中10条边.边(断言)上标明关系名和权重;权重(weight)表示断言的可信度,由断言的来源决定.最新版本的ConceptNet定义了34种语义关系.两个概念间可同时具有多个语义关系(一种语义关系也可能有多条边).在计算语义关系时,通常选择权重≥1的边作为参考.
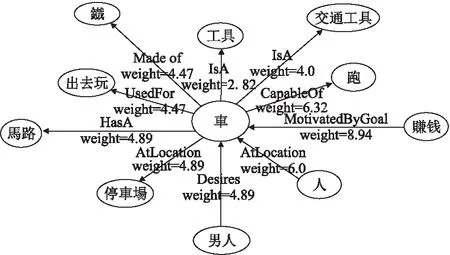
图4 关于概念节点“車”的语义结构图
3 相关工作
3.1 HowNet与ConceptNet
HowNet自2000年发布以来,受到许多学者的关注;基于HowNet提出的中文词汇语义相关性检测方法相继发表.
张沪寅等人提出了一种基于HowNet改进的语义相似度计算方法,使用主义原替换概念义项表达式中出现的具体词,并且限制义原层次深度对相似度的影响[6].
朱新华等人提出了一种综合HowNet与同义词词林的词语语义相似度计算方法[7],根据义原层次结构的特征,改进了现有的义原相似度算法并且根据词林的特征改进了它的词语相似度算法.最后,综合考虑HowNet与同义词林的动态加权策略计算出最终的词语语义相似度.
马永起等人提出的改进方法建立在义原轴上,考虑义原节点所处的深度、义原节点间的距离以及义原节点兄弟数目,在义原相似度基础上,给出词语语义相似度算法[8].
表1列出了上述相关工作的简要特点.

表1 HowNet的已有工作
以上工作是通过HowNet基本文件内单词定义中的义原和义项实现词对之间的语义相关性检测的,检测出的主要是词对间的语义相似度.
ConceptNet知识库中的语义关系来源于断言,断言由一句话构成;在ConceptNet中,没有单词的明确定义,而是通过与单词所在节点连接的边以及边上另一个节点来理解单词的概念.
Ming-Hung Hsu等人提出了一种在拓展查询(QE,Query Expansion)中基于ConceptNet的扩展项权重自动分配的方法[9].其基本思想为:将候选扩展项分类为不同的离散权重类,例如:非常重要(heavy weight)、次重要(light weight)和不重要(no weight)等.该方法中使用了分类学习算法,支持向量机(SVM),从而自动组合从多个来源(WordNet和ConceptNet)中提取各种类型的特征.此外,他们还在文献[10]中比较了ConceptNet和WordNet在拓展查询中的应用,实验表明,两个数据库是互补的,其中前者具有更高的识别能力,而后者具有更高的概念多样性.
Alexander Kotov等人展示了利用ConceptNet进行拓展查询的方法的系统研究结果[11].首先通过仿真实验证明,使用ConceptNet中的相关概念拓展查询具有改进难以查询的搜索结果的巨大潜力.其次,提出并研究了几种有监督和无监督的方法,用于从ConceptNet中选择概念以进行自动查询扩展.
Robyn Speer等人介绍了“多语言和跨语言语义相似性”,以及基于ConceptNet的支持系统[12].该系统的最新版本(动态维护、持续更新),添加了多种回退方法,用于将向量分配给词汇表外单词.
Mehdi Keshavarz等人基于ConceptNet开发了新的词汇和语义相似性度量方法用于处理本体匹配[13].所提出的策略使用新的词汇和语义匹配来寻找对应实体.在语义方法中,作者使用ConceptNet来识别相似实体并根据它创建相似性矩阵,并使用标准精确度和召回方法评估所提出的测量方法,实验表明了所提出算法的有效性.
表2是对上述相关工作的简要总结.

表2 关于ConceptNet的已有工作分析表
3.2 小结
HowNet中包含中文和英文词汇,维护16种语义关系,以概念的定义为主;由单独的专业团队创建并维护,如表3所示.

表3 两种知识库的比较
ConceptNet主要依靠互联网众包、专家创建和游戏内容提取,3种方式来构建;数据来源多而广,包含304种语言、维护34种语义关系.ConceptNet以节点间边上的关系为语义检测、判断的基础.
4 语义计算方法
4.1 基于HowNet的语义检测方法
HowNet定义并维护义原分类树,义原的相似性可以通过义原分类树上的义原距离来计算[14].
首先,定位两个比较义原的最近共同祖先,然后应用向上递归算法找到两个义原到共同祖先之间的距离,求和获得两个义原之间的相对距离.如果两个义原不在同一棵分类树上,则默认它们之间的义原距离为100.
公式(1)用于计算义原距离.在公式(1)中:
com(a,b)表示atom(义原)a和atom b最近的共同祖先,通过向上递归查找到.
Distance(a,com(a,b))表示atom a到义原ab最近共同祖先之间的距离.
AtomDistance(a,b)表示atom a和atom b之间的义原距离.如果两个义原不在同一棵树上,则该值取100.
公式(1)是一个普遍定义的计算公式.
公式(2)用于计算两个义原的相似度.在公式(2)中:
TreeHighi表示分类树的高度,其中i是分类树的序号;由于义原分类树共9棵,所以i的范围为1-9,仅考虑atom a和atom b同时位于i树的情况.
根据文献[8]等,在计算义原的相似度时,在义原距离相同情况下,需要考虑义原所在深度和义原分支的疏密程度对结果值的影响.一般情况下,随着深度的增加,义原越密,所以公式中需引入Deep.
Deep表示atom a和atom b的最近共同祖先距离根节点的层数,因为深度越大,划分得越细;随着Deep的增大,整个公式的值增大.假设两个义原的义原距离为4,义原在树上的最大距离为12,则两个义原的义原相似性随两个义原的最近共同祖先深度的增加而增加,如图5所示.
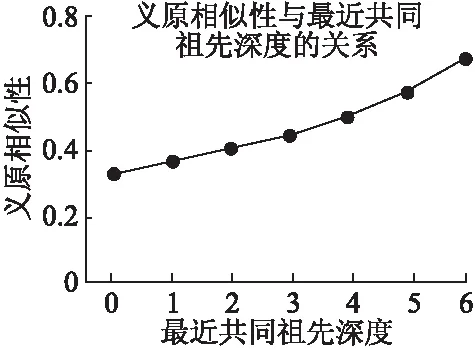
图5 义原相似度随因子“Deep”增加而变化的曲线图
2×TreeHighi是两个义原在该树上可能有的最大距离.
AtomSim(a,b)表示atom a和atom b之间的相似性.
对于分支节点,其第一个子节点与来自同一层的其他子节点的所有节点等距,因此,两个节点的最远距离可粗略估计为树高的两倍.不同的义原分类树具有不同的TreeHigh,应用公式计算的前提是确定义原所在的具体分类树.
在计算义原相似度的基础上,计算具体词语的相似度:
1)应用公式(3)、公式(4)比较词汇Word1和词汇Word2的义项集合相似度,在公式(3)、公式(4)中:
comdef表示DEF1(Word1的义项集合)和DEF2(Word2的义项集合)中相同def(义项)组成的集合.
|comdef|表示集合的势,即集合中元素个数.
defRatio表示DEF1和DEF2中相同def的占比率,即DEF1和DEF2的相似度.
AtomDistance(a,b)=Distance(a,com(a,b))+Distance(b,com(a,b))
(1)
(2)
comdef={def|def∈DEF1∧def∈DEF2}
(3)
(4)
(5)
diffatomsim(def1,def2)=(1-sameatomRatio(def1,def2))
(6)
WordSim(Word1,Word2)=defRatio+(1-defRatio)×
(7)
如果defRatio为1,则表示DEF1和DEF2的相似度为1,则Word1和Word2的语义相似度为1,计算结束;否则,继续计算两个词语之间的相似度,并分别删除两个DEF集合中相同的def,只在两个词语的不同def之间进行相似度计算.
2)对两个词语的每对def中的atom进行分析.
去除相同def后,从DEF1和DEF2中各选出一个def(定义为def1和def2)进行比较,对于每一对def,首先需要比较两个def的主属性mainatom,相同为1,不同则求义原相似度.
公式(5)比较剩余的atom,如果存在相同的atom,则将其放入集合commonatom(def1,def2)中,并计算相同义原占所有义原的比率.在公式(5)中:
def1来自集合DEF1,def2来自集合DEF2.|def1|-1表示去除mainatom之外集合def包含atom的个数.
sameatomRatio(def1,def2)表示def1和def2中相同atom占所有atom比率.
然后再去除相同的atom,公式(6)对剩余的atom进行义原相似度计算,并求出所有atom之间的总相似度.在公式(6)中:
参数1-sameatomRatio(def1,def2)是不同atom之间相似度之和的权重,如果相同atom比率越高,则剩余atom的相似度计算权重下降;反之如果atom相似度过低,则剩余atom之间的相似度计算权重上升,这样保证def之间的相似度结果差距不会太大.
∑AtomSim(a,b)表示计算所有对atom a和atom b的相似度之和,atom a属于集合def1,atom b属于集合def2.
|def|-1-|comatom|表示去除第一个atom和共同atom之后的集合def的势,即def中剩余atom的个数.
diffatomsim(def1,def2)表示def1和def2中不同atom之间的总相似度.
3)公式(7)将所有def配对,迭代计算出相似度,通过求和计算出Word1和Word2的相似度,在公式(7)中:
参数1-defRatio是不同def的相似度之和的权重,保证总相似度不超过1,并且权衡词语相似度的结果.
参数α是主属性的权重,默认为0.6,参数β是其余atom的相似度的权重,默认为0.4,这一设置保证每一对def的相似度不会超过1,参数的设置由用户决定,用户根据使用场景自主决定主属性的比重.
|DEF|-|comdef|表示DEF集合中不同def的个数.
WordSim(Word1,Word2)表示Word1和Word2的相似度,即DEF1和DEF2的相似度,其取值范围在 0-1之间.
已有工作通常选取两个词的义项之间的最大相似度为词语的语义相似度.但是在词汇没有上下文背景的情况下,不能确定两个词汇展现的是特定的某意义,而应该综合考虑该词汇所有的意义.本文提出的计算方法相较之前的已有工作,在考虑了义原分类树深度对义原相似度影响的基础上,结合考虑词语的所有义项,综合比较两个词语的语义相似度,并且仅设置了一对可变参数,降低人为参与,使实验结果更为客观.
计算流程的整体说明如图6所示,自顶向下的分析方法:首先分析义项,对不同的义项进行义原分析;在分析所有义原之间相似度的基础上,把结果值向上传递,加权计算出两个词汇的相似度.对于一对词汇的所有义项以及来自两个词汇的一对义项的所有义原,均以二分图的形式进行所有点之间的交叉匹配计算.
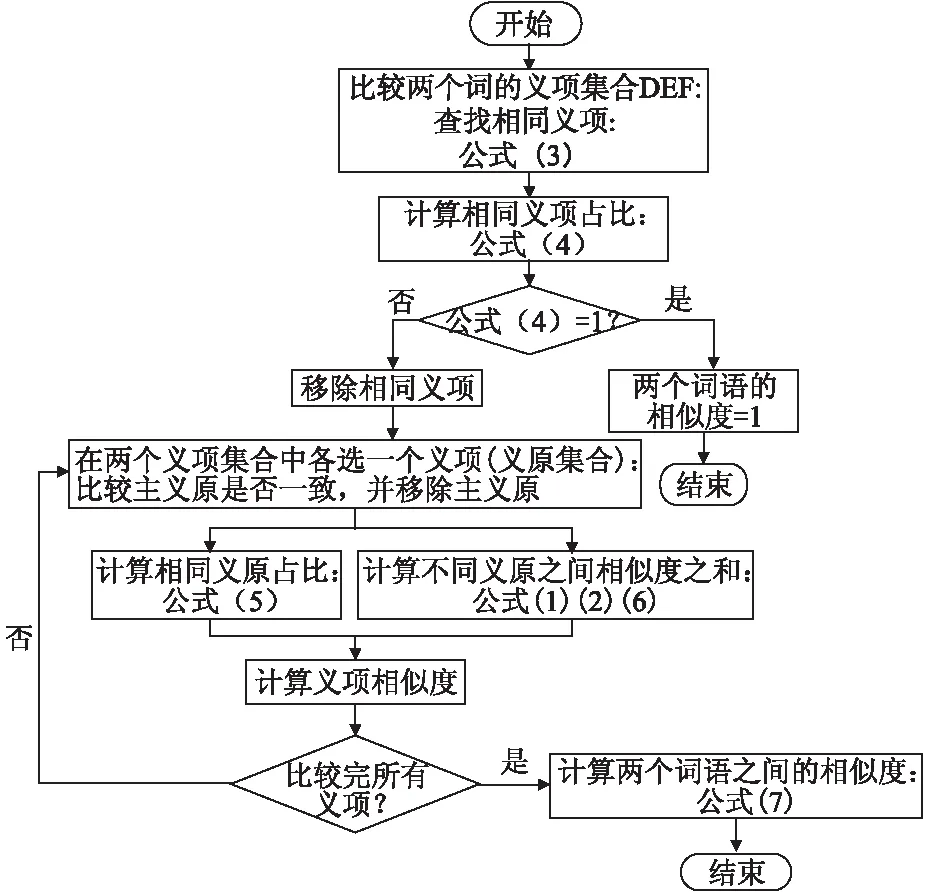
图6 计算词语相似度的流程图
4.2 基于ConceptNet的语义检测方法
考虑语义相似性,在ConceptNet中选择如表4中16个语义关系(16/34)进行检测,并赋相对(相似)值.本文所使用的是官网目前可下载的最新版ConceptNet5.7.0知识库.
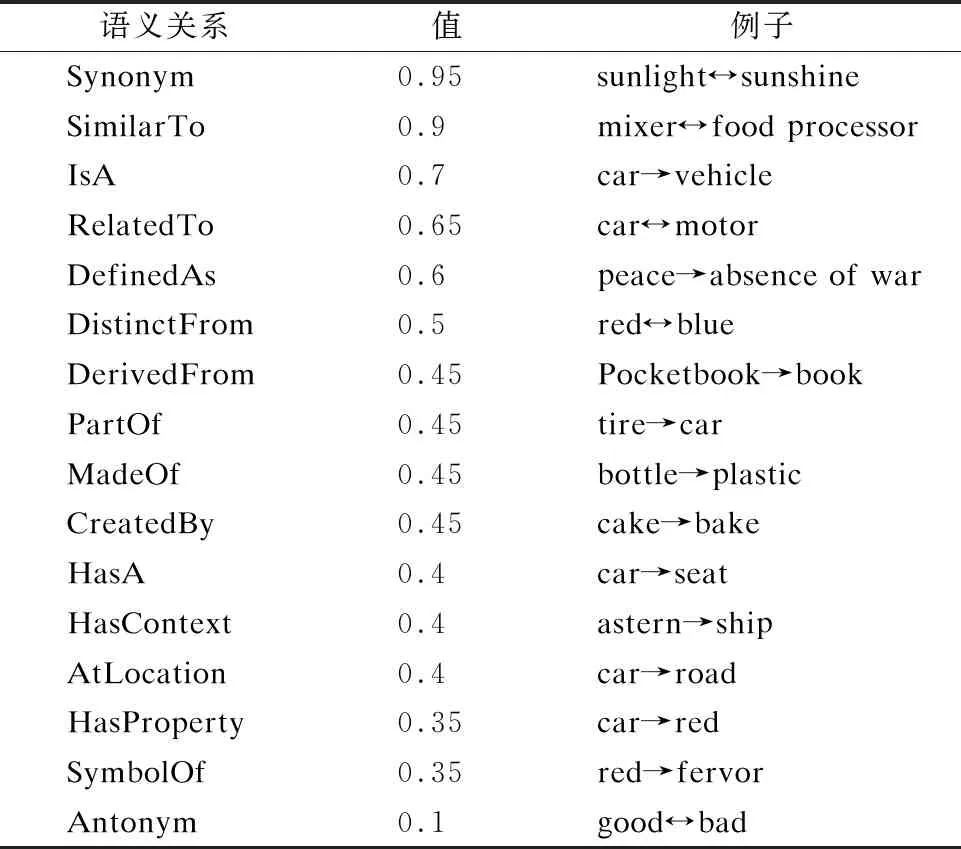
表4 ConceptNet中语义关系及赋值
典型的语义相关性计算技术评价方法可分为两种:
1)对比使用特定技术计算的词汇语义关系值与人为对词汇相关性的赋值(黄金标准数据集),通常采用Pearson相关系数和Spearman相关系数公式计算;
2)对于一个应用的特定任务,测量所提出的方法对改进特定任务的性能的影响程度[15].
由于在已有工作中较少提及基于中文的黄金标准数据集,所以本文对语义关系的赋值主要参考了被广泛作为参考标准的RG-65数据集[16],以英文单词之间的语义关系值结果进行调整的,最终使计算结果与RG-65 的Pearson相关系数结果值为0.9.
词对间的语义相似度由它们在语义网中的关联路径决定;路径上所有边(关系)相似值的乘积(取所有路径中的最大值),作为词对间的最终相似值.本文所提方法仅考虑二重迭代的语义关系,词对间超过3条边的路径不予考虑.
ConceptNet中部分语义关系,如“Synonym”“SimilarTo”“IsA”“InstanceOf”和“Antonym”,体现语义相似度关系;而如“DefinedAs”“HasContext”“HasProperty”等体现语义相关度.HowNet的设计人和开发者董振东曾说过:词语的语义相关性是两个词语的相互关联的程度,可以用词语在同一个语境出现的可能性来衡量;而词语的语义相似性反映的是词语之间的聚合特点.
设定关系值的阈值为0.81(0.9*0.9),即二重迭代的SimilarTo关系值.高于此阈值时,判定为语义相似度,低于此阈值时,判定为语义相关度.
ConceptNet中存储的中文词语包括简体和繁体,它们以“Synonym”的方式建立关联,但由于简体和繁体的一一对应特性,相似值附为“1”.在语义检测时,同时检测中文简体和中文繁体,结果取其最大值.
5 实 验
5.1 实验环境及数据集
案例实验环境如表5所示.

表5 实验环境
MongoDB是面向文档的非关系型数据库,基于分布式文件存储,与传统关系型数据库相比,更适用于大规模数据的存储.本文通过MongoDB建立本地化的数据集,以调用查询.
5.2 实验案例与运行结果
表6展示了作为实验案例的20组词对,以及基于HowNet知识库的实验测试结果.
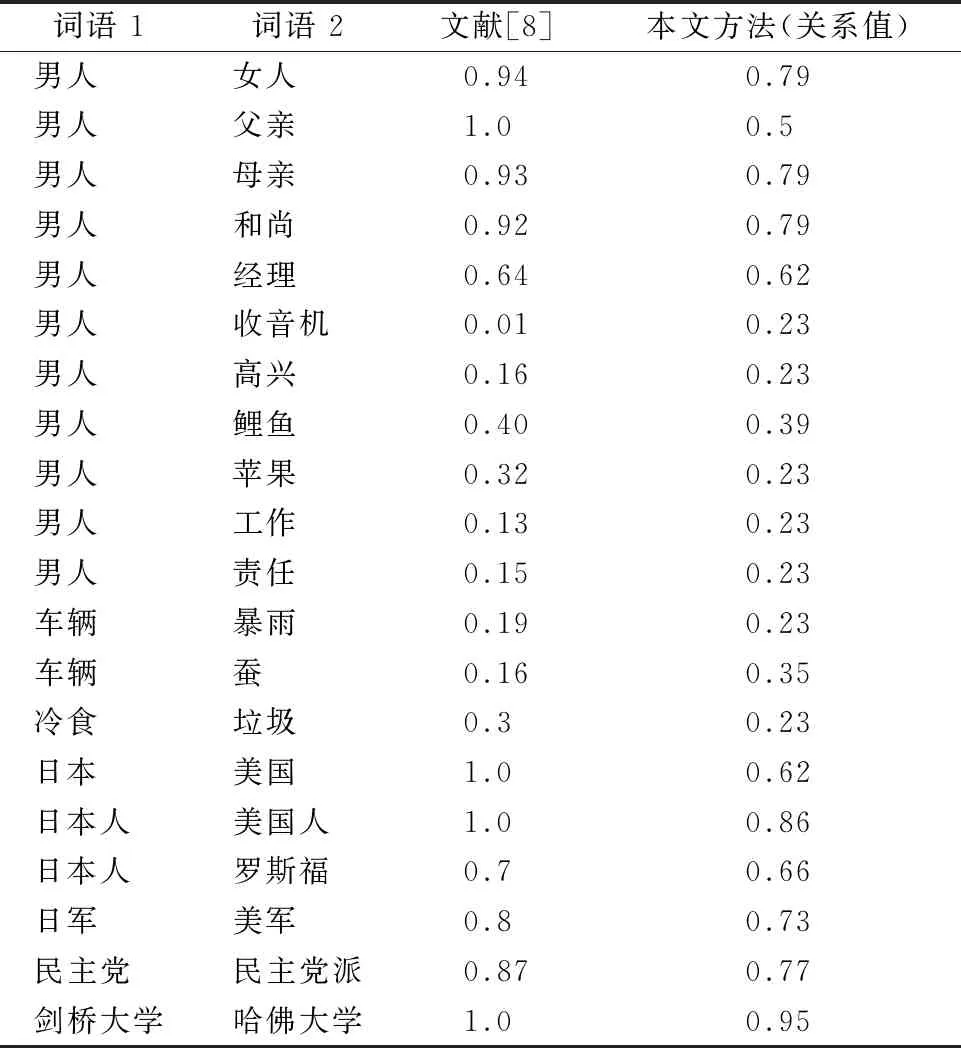
表6 语义相似度计算结果比较
与文献[8]中的计算方法相比,本文中提出的计算方法得出的值具有更好的区分性,分析如下:
1)观察“男人”和“父亲”,在文献[8]中比较的3个方法结果值均为1,然而“父亲”一定是“男人”,“男人”却不一定是“父亲”,所以判断结果为1,即语义相同是不够合理的,与常理存在偏差.
2)观察“日本”和“美国”、“日本人”和“美国人”、“剑桥大学”和“哈佛大学”这几对的实验结果,主属性是相同义原,但语义并不完全相同,结果值为1不贴近事实.
综合表中所有数据,可以看出本实验的结果变化趋势更加缓和,但也存在结果值数据集中的现象.
本实验案例应用基于ConceptNet的相关语义检测方法得到的测试结果如表7所示.
如表7所示,计算结果小于阈值(0.81),即检测出来的关系是语义相关度.以“男人”和“责任”为例,其相关度为0.36,且是迭代语义关系.
5.3 实验结果分析
着眼于语义相关性检测方法,基于HowNet的算法通过义原、义项等,实现了基于词对信息量(information content)的计算规则;基于ConceptNet的算法是在图(graph based)及边权重[15]等相关算法的基础上,扩展得到的.
综合对比表6、表7的测试结果,可以得出如下结论:
1)HowNet可以检测出其语义词典中所有词汇之间的语义关系,结果取值为:0-1.义项完全不同的两个词对的语义关系值为0;义项完全相同的词对间的语义关系值为1.
2)ConceptNet只能检测出其语义网络中存在一条以上有向路径的词对间的语义关系,结果取值为:0-1.没有路径连接词对间语义关系默认值为0;语义关系为“synonym”(仅中文简体和繁体)的语义关系结果为1.
3)以词对“男人”、“女人”为例,两个词汇都是以“人”为第一义原,而义原“男”和“女”又是义原“性别”下的两个直接分类,义原距离为2,在基于HowNet的计算方法中,得出语义相似性的值为0.79.基于ConceptNet的语义计算方法中,两个词汇在ConceptNet上存在迭代语义关系,故得到结果0.81.
4)在HowNet中“男人”和“责任”的语义相似性为0;在ConceptNet中可以存在迭代的语义关系.
5)从表中结果可以得出ConceptNet检测出来的语义关系更丰富,更适用于补充两个词在语义相关度上的语义关系,且ConceptNet所包含的数据量更庞大,可扩充语义检测的单词检索范围.
对于结合两个数据库的语义检测方法,算法如下:
Knowledgebase HowNet;
Knowledgebase ConceptNet;
SR( Word A,Word B )
{
IF( Find( A,HowNet )&& Find( B,HowNet ))
RETURNCountSR( A,B,HowNet );
ELSEIF( Find( A,HowNet )&&( ! Find( B,HowNet ))){
FOR( Word C=FindNeighbor( A,ConceptNet))
IF( Find( C,HowNet ))
CountSR( C,B,HowNet );
RETURNMAX( CountSR( A,C,ConceptNet)*CountSR( C,B,HowNet )) }
ELSEIF( Find( B,HowNet )&&( ! Find( A,HowNet ))){
FOR( Word C=FindNeighbor( B,ConceptNet))
IF( Find( C,HowNet ))
CountSR( A,C,HowNet );
RETURNMAX( CountSR( C,B,ConceptNet)*CountSR( A,C,HowNet )) }
ELSE
RETURNCountSR( A,B,ConceptNet);
}
对于两个词A和B,计算语义关系方法可分为以下几种情况:
1)若在HowNet语义词典中能够定位两个比较词,直接以HowNet为知识库计算相似度;
2)如果词A不能在HowNet语义词典中找到,则在ConceptNet中依次遍历词A的所有语义邻居-词C,并在HowNet中计算词C和词B的语义相似度,并将结果值乘以词C和词A在ConceptNet中的语义关系值,最终取乘积最大的作为词A和词B的语义相似度.词B不在HowNet语义词典中时同理.
3)如果词A和词B都不在HowNet语义词典中,则检测词A和词B在ConceptNet上的语义关系值,并作为结果返回.
6 总结与展望
本文对中文词汇语义相关知识库HowNet和ConceptNet进行了系统的分析和比较.
HowNet通过定义义原、义项等,提供基于信息含量的词对间语义相似度(similarity)的计算基础;ConceptNet是以词为节点、关系为边的有向网,支持词对间的基于图与加权边的语义相关度(relatedness)计算.
在以上分析对比结果的基础上,结合现有基于二者的科研工作,本文提出如下以HowNet为主,ConceptNet为辅,结合两个语义知识库实现语义检测的理论.
该理论的核心思想是:结合使用基于“信息含量”与“图所搜”的语义相关性计算方法.通过使用ConceptNet中定义的语义网络,扩充比较词对的范围(找出与原比较词具有“Synonym”“SimilarTo”等强相似性的词,组成相似词向量组);再利用HowNet提供的义原、义项定义,将词对间语义计算扩展成词向量组间的语义计算.最终的语义计算值取匹配对中的最大值.
该理论的优点是扩充搜索范围,最大限度的发现潜在语义关联;但由此会造成更多资源的消耗,并引入低效计算结果.在未来的工作中,要借助更多标准匹配数据集,如MC-30等,通过有针对性的实验,逐步完善构建词向量组的规则并优化匹配过程,最终实现匹配效率与资源消耗的最佳平衡.
