基于阈值的英语语音自动识别系统研究
2020-09-02邓丽君王涛
邓丽君 王涛
摘要:
语音识别系统的关键在于噪声的处理,主要包含两个阶段,即基于阈值的噪声检测和降噪处理,主要用于英语等语言的自动识别处理。在噪声检测阶段,系统基于所收集的语音的信噪比(SNR)值自动确定何时提高语音质量;在降噪处理阶段,采用独立分量分析(ICA)和子空间语音增强(SSE)来降低噪声。通过实验证明增强语音的SNR值超过接收到的噪声语音的SNR值约20dB至25dB,降噪程序将语音识别率提高了约15%至25%,因此该系统能够降低噪声对多种噪声环境的影响,提高语音质量,达到英语语音识别的目的。
关键词:
语音识别系统; 噪声检测; 降噪处理; 独立分量分析; 语音增强
中图分类号: TP 393
文献标志码: A
Research on English Speech Automatic Recognition System Based on Threshold
DENG Lijun1, WANG Tao2
(1. School of Aviation Management Department, Xian Aeronautical Polytechnic Institute,Xian, Shanxi 710089, China;
2. Internet Information Center, Xian Aeronautical University,Xian, Shanxi 710089, China)
Abstract:
The key to speech recognition system lies in the processing of noise. It mainly consists of two stages, namely thresholdbased noise detection and noise reduction processing for automatic recognition processing in English and other languages. During the noise detection phase, the system automatically determines the time to improve speech quality based on the signaltonoise ratio (SNR) value of the collected speech; in the noise reduction processing phase, independent component analysis (ICA) and subspace speech enhancement (SSE) are used to reduce noise. It is proved by experiments that the SNR value of the enhanced speech exceeds the SNR value of the received noise speech by about 20dB to 25dB, and the noise reduction program increases the speech recognition rate by about 15% to 25%, so the system can reduce noise for various noise environments. The impact of improving voice quality achieves the purpose of English speech recognition.
Key words:
speech recognition system; noise detection; noise reduction processing; independent component analysis; speechenhancement
0引言
自动语音识别(Automatic Speech Recognition,ASR)提供了用户友好的交互方式,有效地将命令或请求传送到人机界面的设备。这些设备可以自动分析接收到的数据,并采用识别结果一致的方式反馈用户。近年来,对ASR的研究考虑了许多场景和应用,许多文献都涉及智能人机交互的ASR[1],当ASR系统用于真实环境中,特别是噪声环境时,环境噪声会严重影响语音质量,同时环境噪声会影响语音的信号分量,并对识别结果产生较大表示。为了解决噪声问题,学者们已经开发了许多减轻噪声对ASR发展影响的方法[2]。
为了使ASR系统在嘈杂环境中更加稳健,近年来人工神经网络(ANN),特别是深度神经网络(DNN)的方法已广泛应用于ASR的语音增强。 DNN的目标是实现复杂的非线性数值函数,用于将嘈杂语音的对数似然谱特征直接映射到相应的干净语音中。 在DNN模型训练中,一些研究开发了混合语音和噪声数据的多风格训练策略。 尽管基于DNN的方法可以实现ASR的高精度改进,但DNN模型需要更多的训练数据来进行综合,训练数据的数量甚至超过基于HMM的系统[34]。
针对当前业界研究的ASR方法,本文主要考虑两个方面:第一个是降噪方法,第二个是训练数据的方式。在降噪方法中,这项工作试图开发一种基于盲源分离(Blind Source Separation,BSS)的方法来消除环境噪声。由于环境噪声在许多环境中是未知的和变化的,因此不需要噪声信息的降噪方法足以将噪声与有噪声的语音分离。为了提高语音质量以进行识别,将另一种语音增强方法与基于BSS的方法相结合。密切调查不同的噪声情况,当噪声信号间歇性时,噪声信号在几个时间间隔内可能不明显。在这种情况下,不能使用降噪,因为过滤语音可能导致語音失真并降低语音识别率。为了防止语音过度过滤的情况,本文提出了一种称为基于阈值的噪声检测的预处理方案。所提出的方案可以根据噪声的大小自动确定何时应该消除噪声,关于训练数据,由于训练数据量和训练时间的原因,在这项工作中使用基于HMM的训练系统,使用隐马尔可夫模型工具包(HTK)实现了基于HMM的训练系统[5]。
因此本文提出了一种基于HMM的语音识别系统,用于在嘈杂环境中进行人机交互。 该系统可分为两个程序,第一个是基于阈值的噪声检测,第二个是组合降噪。该系统具有以下四个属性:训练数据仅需要干净的语音数据,建议的预处理方案以防止过滤语音,降低噪声而没有预测的噪声信息,以及对降低环境噪声和提高语音质量的有效效果。
1系统设计
本节主要对系统实现过程中所涉及的方案进行详细介绍,包含噪声检测与噪声处理过程相关的算法。
(1)基于阈值的噪声检测
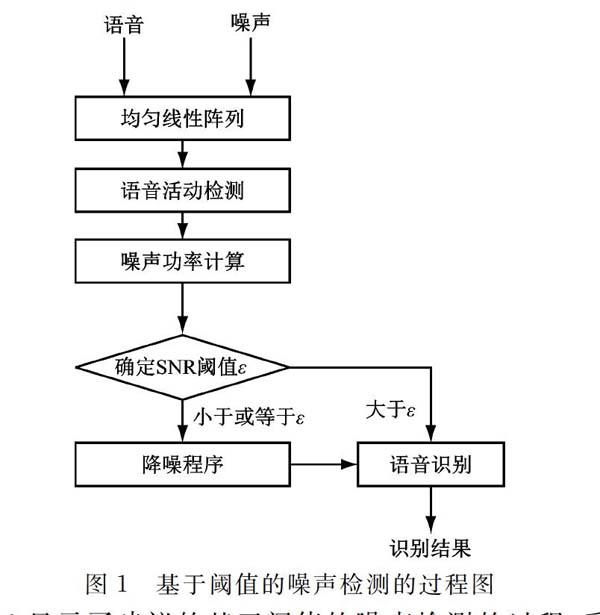
如图1所示。
图1显示了建议的基于阈值的噪声检测的过程,采用线性阵列在嘈杂的环境中收集语音信号。在时域中,
观测信号x1(t)和x2(t)分别建模如公式(1)和(2)中的矩阵和向量,其中y(t)和n(t)分别表示纯净的语音信号和噪声信号。由于观测信号x1(t)类似于x2(t),因此在随后的VAD,噪声功率计算和SNR确定中将信号x1(t)作为主信号如式(1)、式(2)。
VAD的目的是定位接收信号的语音信号分量,在VAD中执行两个称为短时能量和过零率(ZCR)的特征。短时能量表示为公式(3),其中w(n)是选定的窗函数,L是窗的长度,在系统中,默认窗口函数是汉明窗口,其在公式(4)中定义,可以找到具有高振幅的信号并将其视为语音信号,如式(3)、式(4)。
公式(5)表示ZCR,如果观测信号x1(t)的幅度为正,则z(t)等于1,否则为零。ZCR可用于发现有声信号,其具有比无声信号或噪声更低的ZCR。在VAD中,具有较低短时能量和较高ZCR的非语音信号可被视为噪声信號并用于噪声功率计算,如式(5)。
(2) 综合降噪过程
综合降噪程序依托ICA完成BSS过程。对公式(1)和公式(2)中观察到的信号使用未知的混合矩阵A表示,入宫时(6)所示,其中语音信号y(t)和噪声信号n(t)被认为是原始源信号如式(6)。
与公式(6)一致,为了从接收信号x1(t)和x2(t)获得单独的源信号,估计去混合矩阵。公式(7)表示去混合矩阵,其中s1(t)和S2(t)是分离的信号,矩阵W是去混合矩阵,分离的信号类似于原始源信号如式(7)。
为了计算解混矩阵,ICA利用高阶统计量和信息理论来测量属性的非高斯特征,可以使用非高斯特性的分析来获得去混合矩阵。在ICA过程中,两个源信号必须相互独立,为了解决相互独立的情况,在ICA中使用了两种称为信号中心和信号白化的方法。这些方法确保源信号可以变得不相关,如公式(8)表示执行信号中心,其中X是接收信号,E[X]是接收信号的平均值如式(8)。
(3) 语音识别过程
系统利用HTK作为语音识别中的语音识别器,关于语音语料库的选择,该系统采用普通话语音数据库来训练声学模型,在HTK识别器中训练了许多声学模型。对于语音的特征提取,HTK使用Mel频率倒谱系数(MFCC)作为语音识别中的语音特征。在识别过程中,基于HTK的语音识别器分析语音特征并选择最合适的语音内容作为识别结果。
2实验分析
为了验证所提算法的有效性,采用16DOF RobotinnoTM的人形机器人。对于线性阵列,在人形机器人的肩部上放置两个间隔为0.1m的全向麦克风,测试环境的布局图,如图2所示。
实验室的长度和宽度分别为7米和6米;线性阵列以8 kHz的采样率收集测试语音信号;从机器人到扬声器的距离为1.5米,从机器人到噪声源的距离为2米。SNR阈值ε设置为10。在实验中,三个测试方向(30°,60°和90°)用于收集语音信号,三个方向(45°,90°和135°)用于记录噪声信号。
在测试语音记录中,系统记录噪声语音,SNR值为0 dB,5 dB和10 dB。为了比较增强语音的质量和带噪声的语音,从实验结果估计两个客观语音质量测量,SNR和分段SNR。其中公式(9)和(10)分别表示SNR和分段SNR,其中y(t),y0(t),N,M和m分别是带噪语音,增强语音,语音信号的长度 ,帧数和帧索引如式(9)、式(10)。
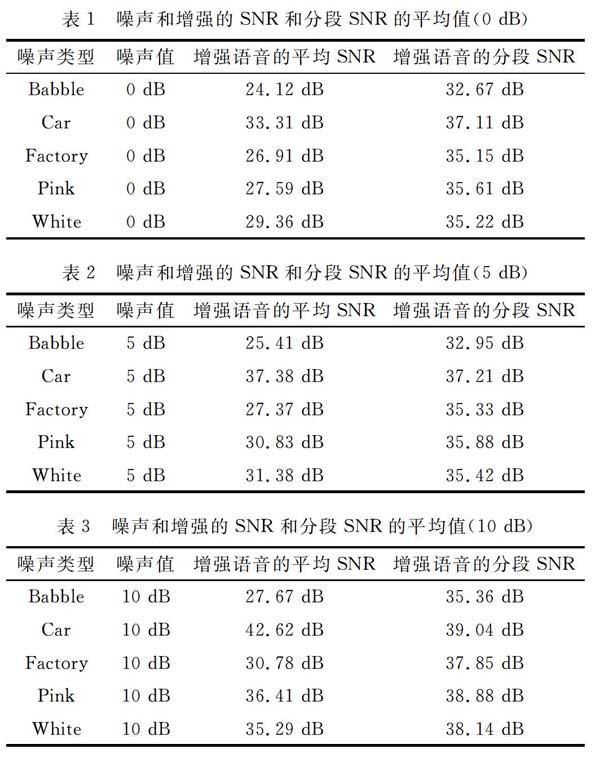
使用所提出的方法比较有噪声语音和增强语音的平均SNR和分段SNR值,如表1—表3所示。
在实验中使用具有三个SNR值(0 dB,5 dB和10 dB)和五种类型噪声的语音。增强语音的平均SNR值超过有噪声的语音约20 dB至25 dB;增强语音的分段SNR值也优于有
噪声语音。两个实验结果表明,所提出的系统改善了各种嘈杂环境中的语音质量。
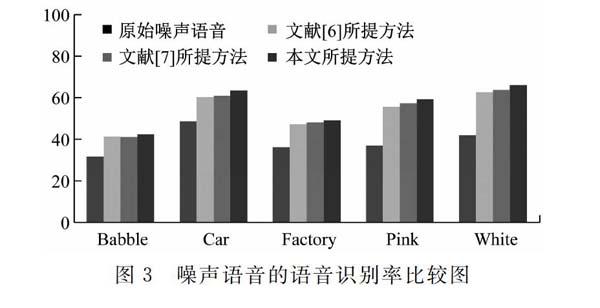
有噪声语音的语音识别率,如图3所示。
与文献[67]的研究方法与所提出的基于HMM的系统进行比较。在实验中检查了具有0 dB,5 dB和10 dB的有噪声语音的三个SNR值。 结果表明,该方法可以比噪声语音提高识别率约15%至25%,证明所提出的采用组合噪声分离和语音增强方法的系统可以有效地去除多种类型的噪声,提高语音识别过程的语音质量。
3总结
本文开发了一种语音识别系统,可以嵌入交互式机器人的设备中,以识别嘈杂环境中的语音内容。该系统可分为两个程序:第一个是提议的预处理,称为基于阈值的噪声检测,第二个是组合降噪。所提出的预处理方案可以评估噪声的大小,以防止在背景噪声很小时过度过滤语音的情况。实验结果表明,该系统能够消除环境噪声,提高语音识别率。与噪声语音相比,所提出的方法产生更高的SNR值和语音识别率。
参考文献
[1]
Mohamad S N A, Jamaludin A A, Isa K. Speech semantic recognition system for an assistive robotic application[C]. IEEE International Conference on Automatic Control & Intelligent Systems. Negeri Sabah Malaysia, 21 October, 2017, IEEE, 2017:9095.
[2]Vu T T, Bigot B, Chng E S. Combining nonnegative matrix factorization and deep neural networks for speech enhancement and automatic speech recognition[C]. 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Shanghai, China, 2025 March 2016, IEEE, 2016:499503.
[3]张敏,杜丹阳,李洪海.智能语音控制系统设计[J].工业控制计算机,2019,32(1):144145.
[4]侯强,侯瑞丽.机器翻译方法研究与发展综述[J].计算机工程与应用,2019,55(10):3035.
[5]程建军,胡立志.关于深度学习的语音识别应用研究[J].科技经济导刊,2019,27(12):189.
[6]Betkowska A, Shinoda K, Furui S. Speech Recognition using FHMMS Robust Against Nonstationary Noise[C]. IEEE International Conference on Acoustics. Hongoluli, HI, USA, 04 June 2007. IEEE, 2007:10291032.
[7]Hong J, Cho K, Hahn M, et al. Multichannel noise reduction with beamforming and maskingbased Wiener filtering for humanrobot interface[C]. The 5th International Conference on Automation, Robotics and Applications, ICARA 2011, Wellington, New Zealand, December 68, 2011. IEEE, 2011:39383941.
(收稿日期: 2019.06.26)
基金項目:
2018陕西教育科学“十三五”规划课题(SGH18H434);
2018西安航空职业技术学院教改课题(18XHJG022)
作者简介:
邓丽君(1985),女,硕士,讲师,研究方向:英语信息化教学和英语语言文学。
王涛(1984),男,硕士,讲师,研究方向:图形图像处理、单片机和U3D游戏开发,项目管理,网络、数据库和大数据。
文章编号:1007757X(2020)08004803
