基于在线教育数据挖掘的个性化学习策略研究
2020-09-02李艳红樊同科
李艳红 樊同科
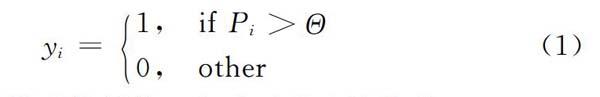
摘要:
近年来,随着移动互联网的快速发展,各种新型的在线学习平台开始涌现,越来越多的人参与其中。在线平台中课程丰富,种类繁多,如何选择课程进行高效学习学习仍然是开放性的问题。通过对在线教育数据进行分析挖掘,构建用户个性化学习策略的模型。首先通过情感分析模型对课程评分进行打分,形成用户的喜好矩阵,然后利用推荐算法,给新用户推荐个性化的课程。实践结果表明,该方法能在某种程度上帮助用户进行个性化高效学习。
关键词:
在线教育; 情感分析; 个性化推荐; 数据挖掘
中图分类号: G 643
文献标志码: A
Research on Personalized Learning Strategies Based on
Online Education Data Mining
LI Yanhong, FAN Tongke
(Institute of Technology, Xian International University, Xian, Shanxi 710077, China)
Abstract:
With the rapid development of mobile Internet, various new online learning platforms have emerged, and more and more people are participating. There are a wide variety of courses on the online platform, but how to choose courses for efficient learning is still an open question. This paper builds a model of user personalized learning strategies by analyzing and mining online education data. First, the course scores are scored through the sentiment analysis model to form the user's preference matrix, and then the recommendation algorithm is used to recommend personalized courses to new users. The practical results show that this method can help users to learn personalized and efficient to some extent.
Key words:
online education; sentiment analysis; personalized recommendation; data mining
0引言
随着移动互联网的快速发展,涌现了多种多样的在线学习平台,类似网易公开课、Coursera等平台,为人们提供了丰富的教学资源,也吸引了更多了用户。但由于在线教学平台丰富多样,课程资源呈井喷式涌现,这就使人们面临有效选择课程资源的问题。同时,由于网络的开放性和包容性,课程教学质量参差不齐,充斥着各种低质量,内容完全相同的教学资源[1]。并且,人们都有自己的学习进度,如何在已有的学习进度基础上,有效的“因材施教”式推荐学习资源,从而可以帮助用户更加高效的学习。基于此,本文通过对在线教育数据进行分析挖掘,构建用户个性化学习策略的模型。首先通过情感分析模型对课程评分进行打分,形成用户的喜好矩阵,然后利用推荐算法,给新用户推荐个性化的课程。研究结果表明,该方法能一定程度上帮助用户进行个性化高效学习。
在线教育数据挖掘研究,属于交叉学科研究,内容研究相对开放,国内外很多学者进行了探索。但是较少有将用户行为数据、课程质量数据和个性化学习策略等信息联合建模。基于此,本文通过对在线教育数据进行分析挖掘,构建用户个性化学习策略的模型。首先通过情感分析模型对课程评分进行打分,形成用户的喜好矩阵,然后利用推薦算法,给新用户推荐个性化的课程。研究结果表明,该方法能一定程度上帮助用户进行个性化高效学习。
1数据挖掘和在线教育
数据挖掘经常被人们称作数据信息勘探、采矿等,主要以数据信息为对象,将现代信息技术手段、模式识别技术、在线统计分析技术、处理技术和和机器学习技术等相互融合实现数据信息更深层次的开发、探究、整合、分析以及处理的过程[2]。在线教育数据挖掘就是数据挖掘在教育领域的应用,指从人们教育及学习过程所产生的数据中自动提取出有价值信息的技巧、工具和研究,这些信息可以为教育者、学习者、管理者和教育研究者等所利用。
在线教育数据的类型,从来源上分类,主要分为用户信息、课程信息、习题信息、论坛信息、用户行为信息以及知识图谱。用户信息是指用户个人信息、用户的成绩等信息;课程信息是指课程介绍、课程内容、课程时长等课程本身的信息;习题信息和课程信息类似;论坛信息包含用户对课程的评价和帖子本身的内容;用户行为信息是指用户对课程的评论、用户选择的课程、用户观看的课程时间等用户在线教学平台中产生的行为;知识图谱是知识点的集合,由自动化和人工标注产生[34]。
基于数据挖掘的在线教育的应用,主要包括以下几个方面:
(1) 知识图谱的应用研究。从学生学习与教师教学的角度出发,将学生学习与教师教学的知识点进行总结汇总,从而构建知识框架,并对每门课程的知识模块进行构建,便于学习与授课。
(2) 在线教育平台中的个性化研究。为了更好地为用户提供服务,从多个数据维度研究个性化推荐服务。
(3) 智能化习题训练研究。通过借助知识图谱及习题库阶段性地对知识进行巩固,并根据学生答题的情况挑选出相关知识点,并从习题库中智能地进行习题提取,便于学生巩固和加强练习。
(4) 学生的多方位评价模型研究。通过利用学生观看视频、完成习题及课程讨论等行为数据的挖掘整理,能够对学生的学习状况进行评价,同时,能够主动发现学生学习的弱点,从而给教师提供更多的辅助信息,帮助教师有效优化课程,甚至有效改进线下教学流程。
2在线教育个性化推荐模型
用户对于课程的评论能一定程度上反映用户对课程的喜好程度。所以本文通过收集用户和课程对应的评论信息,利用文本分类模型,对课程评论进行打分,以此来构建用户的喜好矩阵,在此基础上利用经典的推荐算法,对用户进行个性化课程的推荐。本文先描述评论打分模型,然后介绍推荐算法,最后在数据集上说明算法的效果。
2.1评论打分模型
用户对课程评论的结果对于后期个性化推荐具有重要的影响。课程评论,具有文本短小,有效信息较少,传统的文本分类模型,一般效果不太好[56]。本文通过利用深度学习的算法对评论进行打分,通过借助Word2vector,将短文本信息表示成低维的向量,在此基础上利用神经网络模型进行训练,该方法相对于传统的方法,可以有效的提高打分模型的准确度和召回率。本文对于评论的打分分为1/1,1表示不喜欢该课程(实际采用0表示不喜欢该课程),1表示喜欢该课程。问题的定义具体如下。
R={r1,r2,…,rn}表示课程评论数据集合,每条课程评论样本的特征集合用X表示,相应的类别标签用Y表示:{正面评论,负面评论}。P表示正负面评论的可能概率。P∈[0, 1]。F表示n*m的特征矩阵,n表示样本的总数,m表示特征的总数|X|,yi表示第i条样本的预测结果如式(1)。
其中Θ表示分类模型的阈值。实验过程中该值是0.45。
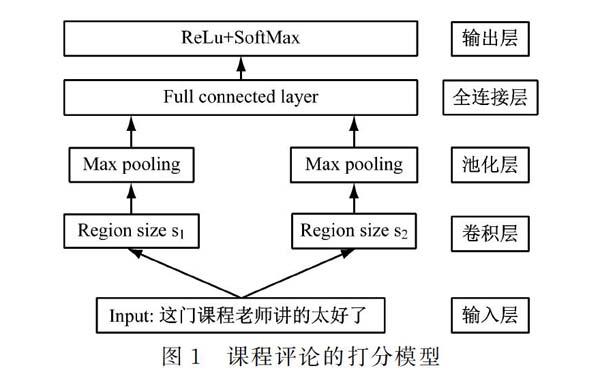
在问题定义的基础上,通过设计具体的神经网络模型来对课程评论进行打分。课程评论打分的深度学习模型,如图1所示。
该神经网络,主要分为5个模块。依次是输入层、卷积层、池化层、全连接层和输出层。输入层是对评论文本进行切词,利用onehot对文本进行表示。卷积层是在将输入层的onehot特征,利用embedding方法转换为低维向量表示,
然后利用不同大小的卷积抽取文本特征[7]。池化层对卷积
层的数据进行归一化处理,将不同维度的卷积核转换为相同
维度。全连接层,对池化层的输出进行线性关系学习,学习更多的文本特征表示。输出层主要是对样本进行预测,首先利用ReLu函数对全连接层的线性关系进行非线性变换,然后利用SoftMax函数具体进行分类打分。该网络结构能够有效学习短文本的潜在的语义空间,从而有效学习用户对课程的打分预测。
2.2课程推荐模型
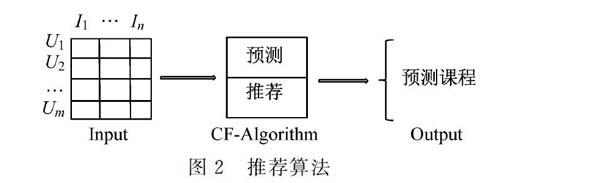
在用户对课程打分的基础上,通过收集用户、课程以及对应评论的关系,来构建用户的喜好矩阵,在此基础上利用推荐算法训练在线课程的个性化学习模型。文本采用协同过滤的推荐算法进行模型训练和预测。算法的具体流程,如图2所示。
在协同过滤推荐算法中,用m × n的喜好矩阵表示用户对课程的喜好程度,一般打分越高表示用户越喜欢这个课程。0表示没有选择该课程。图2中喜好矩阵的行表示拥护,列表示一门课程,Uij表示用i对课程j的喜好程度。CF算法分为两个流程:预测和推荐。预测过程主要是预测用户对没有选择课程的可能打分,推荐过程是根据预测阶段的结果,推荐用户最可能喜欢的TopN个课程。
3实验结果与分析
为使得研究结果具有真实意义,本实验采用案例分析法,以西安外事学院网络综合教学平台上开展的网络教学课程为数据来源,采集了自2015年9月到2018年9月平台可到的用户信息数据,其中包括55 688名学习者,992门课程。
3.1实验设置
在实验中为了与标准数据格式相统一,筛选了记录数大于20条的用户,数据源是从随机筛选出的5500名用户及992门课程中进行选取,在选取的数据集中,对用户学习过的课程的进度进行统计,并根据课程学习进度的百分比映射为相应的等级表示用户对课程的真实反馈。从而对用户的基本信息进行处理和提取,作为模型输入的一部分,我们将按照用户的性别、所属专业总共提取了25個用户属性类别,包括计算机科学与技术、会计、工商管理、电子商务等。从课程信息中,按照网络综合平台对课程的分类,一共选取了45个课程类别。
通过爬虫程序+人工标注的方法收集数据来进行实验,其主要包含两份数据集:课程评论数据集和推荐课程Top 5数据集。DataSet1数据集包含18 121条课程评论信息,通过人工筛选和校准的方式进行标注,课程评论可能存在无效重复的评论信息,为了消除重复的内容,需要进行文本去重,本文认为信息有超过90%的 bigram 匹配,则认为数据是重复的。通过特征选择,从数据集的多门课程中得到相关的推荐课程数据集DataSet2,其数据集包含1 031个学生的Top 5推荐课程。
3.2评价指标
实验采用评估分类性能方面的常用评价指标:召回率、准确率[8]。召回率和准确率是分类任务借鉴信息检索任务中的评价指标。在信息检索中,通常采用精准率(Precision)和召回率(Recall)来衡量检索出来的信息的质量。一般将相关文档称为为正例(Positive),不相关文档称为负例(Negative)。在整个信息检索过程中[9],一般会产生四种结果:TP、TN、FP和FN。TP是指搜索引擎正确地检索到相关文档;TN是指正确地未检索到不相关文档,即将不相关的文档正确进行过滤了;FP是错误地检索到相关文档,即将不相关的文档认为是相关文档了;FN是错误地未检索到相关文档,也就是相关文档没有被检索到。对应关系如表1所示。
3.3实验结果与分析
在训练数据集 DataSet1采用传统词特征+SVM和深度学习改进算法的对比实验所获得的效果,如下表2所示:
从上表可以看出,传统词特征+SVM算法的分类效果,比本文提出的深度学习方法的分类效果表现稍差,本文通过利用Word2vec的词向量表示,极大丰富了短文本的语义信息,在此基础上利用深度网络结构进行学习,能够极大提高打分模型的精准度和召回率。
将采用多次随机分隔数据集,选取学校网络综合平台课程其中的80%打分数据作为训练集,其它的作为测试集,实验通过对数据多次计算得到的平均值作为最终结果。
在學生课程评论的喜好矩阵的前提下,推荐算法在DataSet2中的实验结果如表3所示:
从上表中可以看出,基于课程评论的喜好矩阵基础上,利用推荐算法构建在线课程的个性化学习模型效果较好,能够满足实际需要,从而帮助学生进行个性化高效学习。
4总结
文本首先分析了在线教育存在的问题,并具体介绍了数据挖掘对于在线教育的助益,在此基础上上提出了基于在线教育数据挖掘的个性化学习模型。首先利用深度学习算法预测用户对课程的喜好程度,以此来构建用户的喜好矩阵,然后在此基础上利用协同过滤算法学习个性化推荐模型,实验结果表明,基于深度学习的课程评分模型,相较于传统文本处理模型,有较大提升,同时实验结果表明,本文提出的个性化学习策略能够满足实际需要,能够有效改进用户的学习体验和效率。
参考文献
[1]
West Darrell M. Big Data for Education: Data Mining, Data Analytics, and Web Dashboards.
Governance Studiesat Brookings [R].Washington: Brookings Institution, 2012:110.
[2]Ensan F, Du WC. A semantic metrics suite for evaluating modular ontologies[J].Information System, 2013,38(5): 745770.
[3]W. Feng and Jie Tang and Tracy Xiao Liu.Understanding Dropauts in MOOCs[C].The ThirtyThird AAAI Conference on Artifical Intelligence (AAAI19), pages 517524, Hilton Hawaiian Village, Honolulu, Hawaii, USA, January 27February 1,2019.
[4]Maeve Duggan, Nicole B Ellison.Social Media Update 2014[R].Washington: Pew Research Center, 2015.
[5]Tair M M A, ElHalees A M. Mining educational data to improve students' performance: a case study[J].International Journal of Information, 2012, 2(2): 140146.
[6]Iyyer M, Manjunatha V, BoydGraber J, et al. Deep unordered composition rivals syntactic methods for text classification[C].Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing:papes 1681—1691, Beijing, China, July 2631, 2015.
[7]Shen T, Zhou T, Long G, et al. Disan: Directional selfattention network for rnn/cnnfree language understanding[C].The ThirtySecond AAAI Conference on Artificial Intelligence:(AAAI—18), pages 5446—5455, New Orleans, Louisiana USA, February 27, 2018.
[8]Wang M, Zheng X, Yang Y, et al. Collaborative filtering with social exposure: A modular approach to social recommendation[C].The ThirtySecond AAAI Conference on Artificial Intelligence (AAAI18), pages 2516—2523, New Orleans, Louisiana USA, February 27, 2018.
[9]Mansour Y, Mohri M, Rostamizadeh A. Domain Adaptation with Multiple Sources.[J].Nips, 2008(2):10411048.
(收稿日期: 2019.05.21)
基金项目:
陕西省教科所十三五规划项目(SGH18H535);
陕西省2019年重点研发计划项目(2019NY055)
作者简介:
李艳红(1978),女,硕士,讲师,研究方向:大数据、教育技术。
樊同科(1979),男,硕士,副教授,研究方向:数据挖掘。
文章编号:1007757X(2020)08004503
