基于M/M/c排队模型的云计算中心能耗管理策略
2020-09-02张书豪张延华王倩雯王朱伟
张书豪,张延华,王倩雯,王朱伟,李 萌
(北京工业大学 电子信息与控制工程学院,北京 100124)
0 引言
云计算作为一种新兴的技术,以能够提供弹性的计算资源和按需付费的方式,在信息与通信技术领域引起了新的革命[1]。云计算是由分布式计算、网格计算和并行处理等技术逐步发展而来[2],它将大量存储、软件和计算等资源集中调度,构成超大规模、高性能且可扩充的虚拟IT资源池,再通过面向云用户的服务接口,提供按需计费的服务模式[3]。但是在云计算中,云端服务器集群能耗极高,如何快速响应和解决用户任务请求和云端服务器能耗之间的矛盾,对用户体验、云服务提供商的服务质量、运营成本控制等都有着重大的影响[4]。分析用户访问云计算中心的排队过程并研究云计算中心服务器的休眠策略,能够有效地提升云计算中心运行效率。
目前,有许多文献针对数据中心能耗管理以及资源分配问题开展研究,G.Huang,S.Wang等人曾研究了云计算平台中的资源分配问题,通过建立模型预测了每个客户的到达时间,从而计算满足资源需求的最小资源量并提出自动扩展虚拟机的算法,进而减少资源的使用[5],但他们在对虚拟机的调节上使用的是基于阈值的策略,而设置阈值又是一项艰巨的任务,一旦阈值设置不当,策略效果将受到极大影响。文献[6]从客户的服务需求入手,进行了预测,以便服务提供商避免为满足服务水平协议(service layer agreement,SLA)而过度配置资源,但客户请求是随机变动的,通过预测值动态配置计算资源来满足SLA和的同时达到资源的最佳利用是困难的;文献[7]使用M/G/m模型分析了平均队长、平均响应时间和服务单元数量之间的关系,但是没有获得响应时间概率分布函数的精确表达式。文献[8]通过对云数据中心的测试和分析,提出一种降低“等待能耗”的思路,并使用了DPS(Dynamic Powering On/off)技术,但无法应对大量关闭服务器时访问量骤增的情况;文献[9]则通过对云计算中心建模从而对其服务性能进行分析,得出了用户请求的平均等待时间以及其他性能指标,给出了影响云计算中心性能的各种因素。文献[10]中提出了基于突发感知的云计算服务器资源预留机制,有效的解决了任务请求突然骤增情况下,休眠状态服务器无法及时被唤醒的问题,但是这会在一定程度上造成空闲资源的浪费。文献[11]中使用了双状态马尔可夫链对云计算虚拟机的资源需求进行建模,并且提出了基于静态分布的算法来调节虚拟机数量,但是对于现有的云计算中心而言,其虚拟机数量和任务到达量都是十分庞大的,而求解马尔可夫过程的计算量会随着基数的增加而指数增长。
本文提出一种基于M/M/c过程的云计算访问排队模型,通过对模型中的等待时间、队列长度等指标进行分析,获得了该模型响应时间的概率分布函数,在此基础上引入基于预留机制的DPS技术,并且嵌入以ERP为反馈量的闭环反馈策略,从而动态均衡系统能耗与QoS之间的关系。
1 系统结构及原理模型描述
1.1 云计算中心的工作机制
在云计算中心系统中,通常有大批任务请求进入数据中心。一旦有客户任务请求,云计算中心将根据客户的不同需求自适应提供不同类型的服务,云计算中心的工作机制如图1所示[12]。
图1 云计算中心的工作机制
典型的云计算环境可分为4层结构,分别是物理资源层、虚拟化资源层、管理中间件层和SOA服务层。云计算资源池属于资源虚拟化层,它屏蔽了物理资源层在分布上的细节,为其上层的管理中间件层提供服务支持。
1.2 云计算中心的任务队列模型
假设云计算资源池中有c台服务器(即c个计算单元),每个服务器都是独立运行的,服务器完成任务时不互相影响。客户请求到达的时间间隔服从参数为λ的泊松分布,并且每个服务器的服务速率服从参数为μ的指数分布。将这种系统称为具有多服务窗口的排队模型,简称M/M/c模型,M/M/c排队模型运行方式如图2所示。

图2 M/M/c排队模型
将所有用户每一次访问云服务器的动作,都当成一次顾客到达过程,并设到达的访问具有马尔可夫性,则可以将马尔可夫链引入云计算资源池中,预测分析未来时刻云计算资源池的状态[13]。由于访问过程服从参数为λ的泊松分布,且每次到来的任务所使用的资源量都是随机的,即可认为每个服务器的平均服务率遵循参数为μ的指数分布。除此之外,云服务器资源中物理机(PM)一般会被抽象为多个虚拟机(VM),客户实际分配到的是虚拟机资源,为简化起见本文将为每一个为客户服务的服务器都认为是一台虚拟机服务器VM,则可以假设共有c台服务器。在不同时刻到达的用户服务请求中,服务顺序按先到先服务的规则。因此,客户访问云服务资源池的过程属于M/M/c排队过程。
1.3 随机任务模型
由于服务请求符合参数为λ的泊松分布,每个服务器的平均服务率遵循参数为μ的指数分布,且有c台服务器,则云服务资源池的平均服务率为cμ,1/λ为平均到达间隔,1/μ为每个服务器的平均服务时间。设ρ为服务强度,ρ=λ/cμ,当ρ趋近于0时,用户任务的等待时间短,服务器节点有大量的空闲时间;反之当ρ趋近于1时,节点的空闲时间少,用户的等待时间长。cμ应当大于等于λ即ρ≤1,此时排队模型存在平稳分布。假设云计算资源池不限制任务数量,故云计算资源池中随机任务的可能状态集应为Φ={0,1,2… }。由此可以得出云计算资源池随机任务的状态流图,如图3所示。
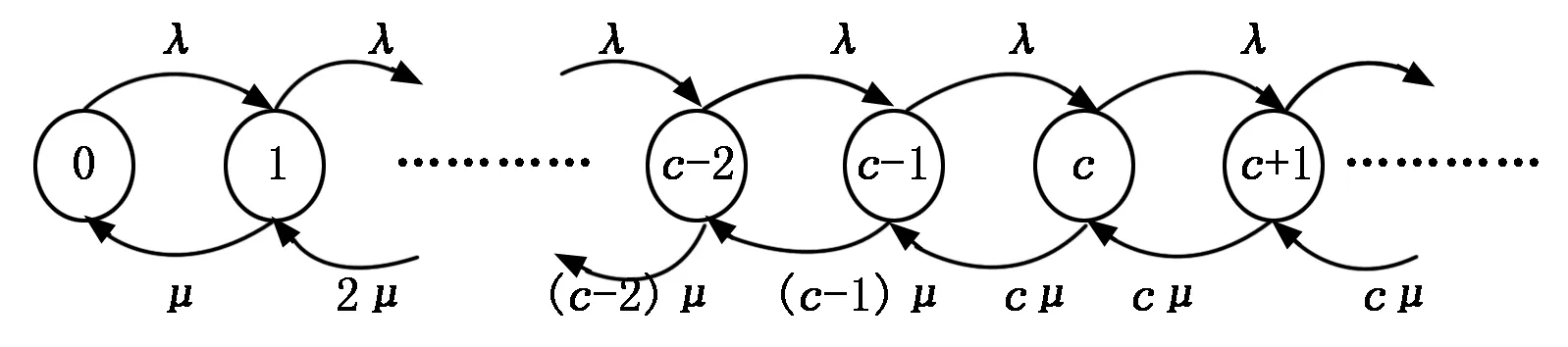
图3 云计算资源池状态流图
其中:状态圆圈内的数字代表系统中服务进程数设为n,当0≤n≤c时,表示云计算资源池内有n个服务器单元正在被任务使用,其余c-n个服务器单元空闲;当状态n>c时(即达到云计算资源池的任务n超过c时),c个进程都在被任务占用,而余下的任务排队等待服务。根据图3,可得到系统状态之间的概率转移如下:
λn=λforalln
(1)
(2)
由此可得概率系统状态转移矩阵:

(3)
由于n为目前系统中的任务数,设pn为此时系统中共有n个任务的概率,由此可知:

(4)

(5)
(6)
定义系统空闲概率为:

(7)
由于请求云计算资源池服务的作业最终都会完成服务,故丢失概率Pl=0。因此可知随机访问处于稳态时的各项系统指标,其计算公式如下:
排队队列中的平均客户数量:
(8)
系统中总的平均客户数量:
(9)
排队队列中的预期平均等待时间:
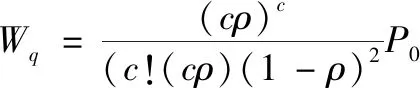
(10)
系统中总的预期平均等待时间:

(11)
1.4 建立实际场景模型
在云计算任务排队过程中,客户请求的任务量是随机变化的,若在大量服务器单元处于休眠状态时突遇用户任务请求骤增,由于唤醒服务器需要花费一定的时间,则可能无法及时地、有效地应付云用户的请求。基于带预留机制的DPS(dynamic powering onoff)策略,将所有服务器分为两组,其中永久运行的服务器构成服务主模块(base line module,BLM),等待启动的服务器构成服务预留模块(reserved line module,RLM)。系统共设置有n2个服务器,BLM中有n1个服务器,RLM中有n2-n1个服务器。其中BLM中服务器永久开启,RLM中服务器可以在工作状态与休眠之间转变,当它的某个服务器处于休眠状态时,则该服务器仅消耗极少的维持休眠状态的能量。将缓冲区(Buffer)的设置为无限大,设置任务队列在缓冲区中也要消耗能量,但能量消耗较少。
从能耗方面考虑,RLM中的服务器可以在服务器响应较快即缓冲区中作业数量较少时休眠一部分;同时为了保证用户体验即QOS值,RLM服务器应在系统响应时间过长即缓冲区中作业较多时,重新开启一部分。一般地,由于云服务器数量足够多,且服务器唤醒——睡眠状态转化足够快,所以服务器的状态转换时间可忽略不计。需要注意的是,在对RLM中服务器进行休眠操作时,休眠策略是在RLM的控制器接收到指令后,休眠已经完成任务的服务器,对于RLM中正在服务却未完成服务的服务器则需要等待其完成当前工作后休眠,不能休眠正在为顾客服务的服务器。
为了符合实际场景,本文设置相同情况下,BLM中服务器正常工作时的平均能耗等于RLM服务器,在请求到来时优先访问BLM中的服务器,避免 BLM服务器资源的浪费。排队过程系统流程如图4所示。
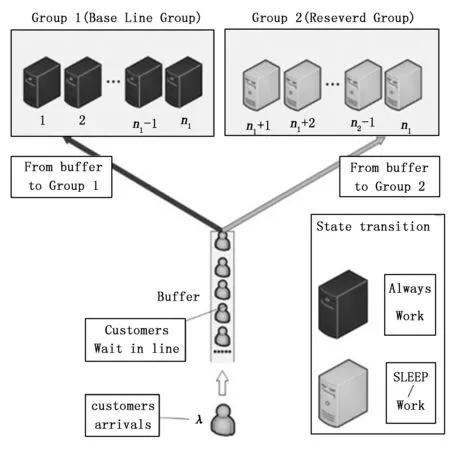
图4 实际访问排队过程模型
1.5 建立系统能耗模型
考虑到实际问题,某些云服务器是不能够随意关闭的,关闭后可能会导致数据丢失或者重新配置数据库等一系列问题。所以设定BLM中服务器始终保持工作状态并保持能耗W1;为了简化起见,将RLM服务器的状态设置为两种:第一种是休眠状态,此时服务器功耗是W21,第二种是工作状态,服务器功耗是W22,W22要远大于W21,其总能耗记为W2;由于顾客请求在缓冲器中排队时也消耗能量,所以设置在缓冲器Buffer中的等待能耗为W3;由于前文中将RLM中服务器唤醒与休眠态之间的转化设置为瞬时的,所以转换状态的能耗W4也可忽略不计。设BLM共有n1台服务器,其中n1台正在运行;BLM共有n2-n1台服务器,其中G台正在运行则n2-n1-G台处于休眠状态;设缓冲器队列中共有D个请求,故此系统的总能耗为:
WA=W1×n1+W22×G+
W21×(n2-n1-G)+D×W3
(12)
2 算法描述
能量响应时间乘积ERP(energy-response time product),被认为是寻找能量性能权衡的合适度量。它被定义为:ERPπ=E[Pπ]×E[Tπ][14]。其中E[Pπ]是控制策略π下的长期平均功耗,E[Tπ]是策略π下的平均客户响应时间。最小化ERP可被视为最大化"每瓦特性能",此处性能被定义为平均响应时间的倒数。在控制领域,反馈算法作为闭环控制系统的核心,对系统各个节点状态的控制、调节起到了至关重要的作用。本文提出一种带预留机制的基于ERP标准的反馈算法,实现对系统的全局控制和优化。
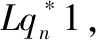
W*=Lq*×W3+(c*-n1)×W22+
(n2-c*)×W21+n1×W1
(13)
而此时系统的实际消耗功率为:
Wa=Lat×W3+(cat-n1)×W22+
(n2-cat)×W21+n1×W1
(14)
其中:Lat为此时Buffer中实际队列长度,cat是此时实际运行服务器台数。
具体算法如Alg.1所示,系统框图如图5所示。
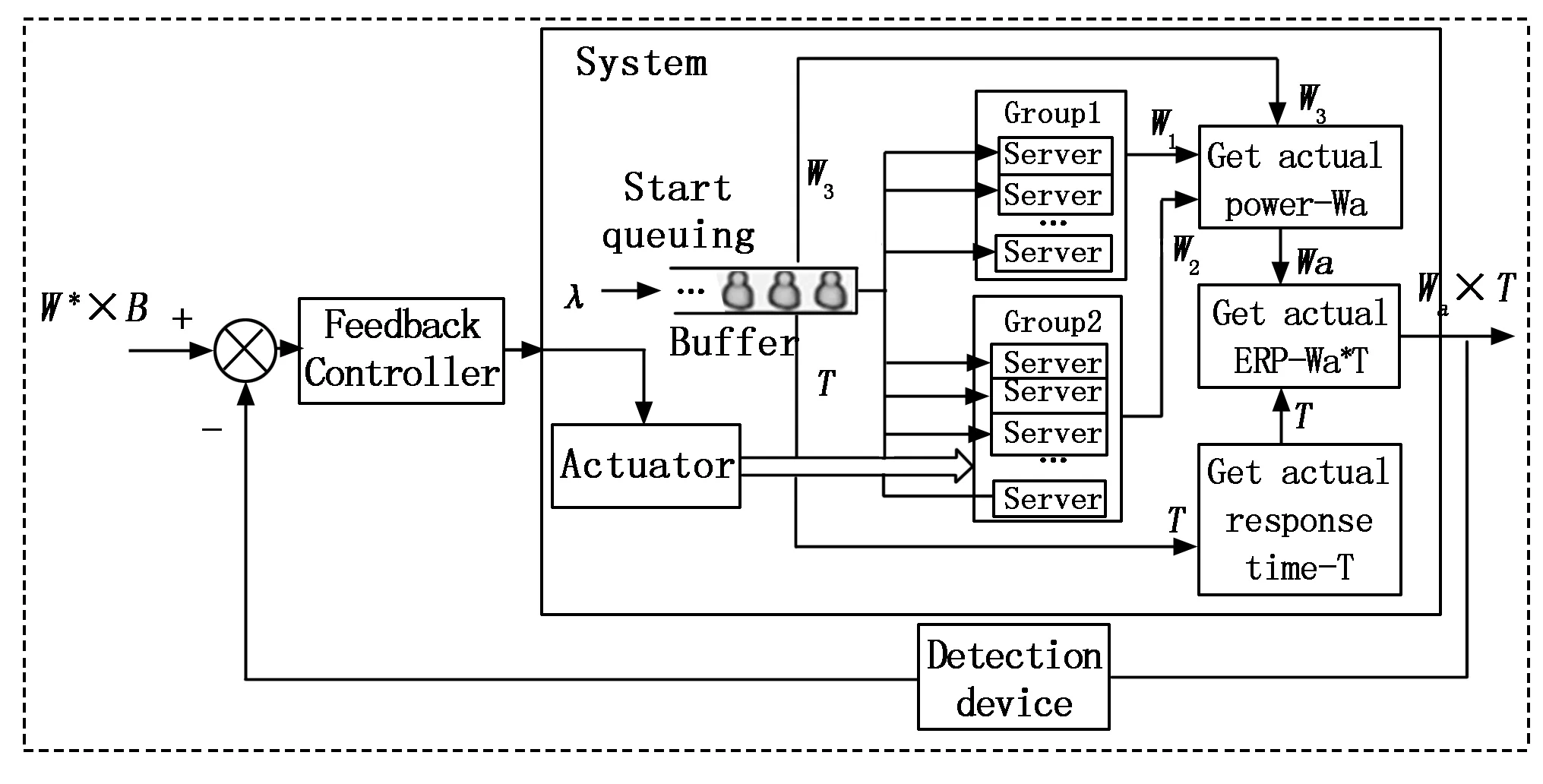
图5 基于反馈控制调节的系统框图
Algorithm 1 Feedback algorithm based on ERP
Input:λ,μ,B,Q,n1,Tc,Tmax;
Output: Number of servers to adjust;
1 set User satisfaction response time B
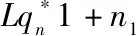
4 computeW*by Equs.(13)
5 get the Feedback system inputW*×B
6 detect the actual power consumptionWaand actual response timeTinTc
7 get the Feedback system inputWa×T
8 compute △W=Wa×T-W*×B
9 If △W>0 then
10 wake up some servers by Linear programming Alg.
11 else if △W<0
12 dormancy some servers by Linear programming Alg.
13 else
14 Dormancy all servers in RLM
15 End if
16Tc=Tc+10
17 End while
18 return
3 实验结果与分析
3.1 参数设置及实验背景
在Matlab 2019a环境下,进行实验仿真,对本文提出的基于ERP的带预留机制的反馈算法进行仿真,从任务的响应时间和能耗两个方面进行仿真来评估算法。实验建立了一个由100个服务器组成的数据中心,其中50个BLM服务器,50个等待启动的RLM服务器。排队规则设置为服从M/M/c排队模型,在任务排队的过程中,根据实时ERP的值,来决定是否开启RLM中服务器以及开启多少数量的RLM服务器。计算出系统在仿真时长内的能耗,以及系统平均响应时间,与never-off算法与静态阈值算法进行比较,仿真时长到达后,实验结束。


表1 实验参数设置
3.2 实验结果及比较
首先,仿真完成了在上述参数及规则下的基于 ERP的带预留机制的反馈算法,其次比较了never- off算法、静态阈值算法、本文算法的任务平均响应时间和系统执行任务的功耗。设λ=700后,可得到任务到达符合泊松分布的数据,如图6所示。仿真实验比较了在总仿真时间为100 s时,3种算法的平均响应时间,如图7所示,never-off算法的平均响应时间最短,静态阈值算法最长,而本文算法的平均响应时间介于上述两种算法之间。这是由于在 never-off算法中,云计算中心开启的服务器数量是根据排队理论预测出来的,云数据中心的服务器不能动态唤醒或休眠,所有任务都可以尽快地分配到服务器;在静态阈值算法中,虽然服务器可以动态唤醒休眠,但开启服务器的数量在每个阶段都有固定值,在该阶段内即使任务数增加,服务器数量也不会增加,此时便会导致平均响应时间增长,无法较好地满足云用户任务响应时间需求;而在本文算法中,云计算中心的运行服务器数量能够根据ERP变动动态改变,能够较好地满足云用户任务响应时间需求。

图6 泊松分布下任务请求数量到达变化
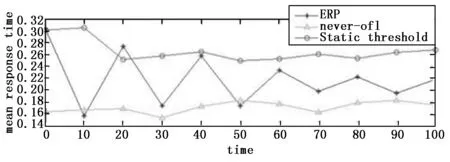
图7 3种算法响应时间比较
由图8可知,在相同条件下,本文算法的消耗的能耗最小,never-off算法的消耗的能耗最大,静态阈值算法消耗的能耗介于上述两个算法之间。这是由于在never-off算法中,云计算中心的服务器总数量是根据排队论预测值计算得出的,并始终全部开启,在任务到来较少时产生了大量无用能耗,因此其节能效果最差;在静态阈值算法中,只有当队列中的任务超过设定的阈值时,部分服务器才开启并提供服务,这在一定程度上避免了大量空闲能耗的产生,相对never-off算法也有一定的改进,然而该算法需要设置阈值,阈值设置本身就困难,阈值设置不当很可能会导致系统性能不佳。在本文算法中,可以根据ERP值动态调整并决策出相对较优的运行服务器数量,避免开启过多RLM中的服务器,有利于降低云数据中心空闲能耗。通过结果对3种算法进行对比,可知never-off算法能提供最优的系统性能,但其消耗的总能耗最多,不能满足云计算中心的利益;静态阈值算法在一定程度上节约了能耗,照顾到了云计算中心的利益,但一旦系统中任务数过多,就会使任务的平均等待时间上升,降低了QOS值;而本文提出的策略能够兼顾云计算中心和用户的利益,相对较优。图9中,actualERP是实际ERP的变化,ERP*是期望。
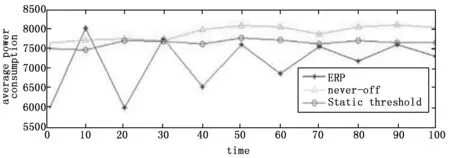
图8 3种算法功率消耗比较

图9 ERP变化比较图
从图9可以看出,本文的算法得出的实际ERP值始终在预估值的附近波动,而且越来越趋近于预期ERP,故可知仿真结果符合预期。值得注意的是,在图6和图7中,本文算法的初期波动较大,图8中实际ERP值也呈现出折线状波动,这是由于本文算法在初期调整时为了轻量化计算量选用了反馈算法而造成的现象。但经过短暂的波动期后,数据指标便会趋于稳定。
4 结束语
针对现有云计算中心能耗浪费问题,对云计算中心的工作机制进行了分析,得出了云计算中心的工作特点,利用M/M/c排队模型对云计算中心用户访问过程进行了建模,并得出各项重要指标。引入了动态开关策略(DPS),在此基础上提出了基于ERP标准的带预留机制的反馈控制策略。基于Markov过程的状态空间及其状态转换关系的控制策略会随着服务器数量的增加导致策略计算指数型增加,本文提出的轻量级算法在云服务器中心服务器计算单元巨大的实际情况下,具有快速得出策略控制结果的优势。以ERP为衡量标准,均衡考虑了能耗与响应时间两项重要指标,最大化“每瓦特性能”,寻找最佳的能耗绩效权衡。实验证明,该策略能够在保证QoS的情况下,有效降低系统能耗。但是也存在得出的控制结果不够精确,仿真初期震荡较大的缺点。下一步将重点考虑引入参数随时间变化的泊松分布,在不过多增加计算量的前提下,研究更加精确的控制方法,提出本算法的补充算法,进一步对云计算中心的服务质量和能耗进行优化管理。
