改进的分类器分类性能评价指标研究
2020-08-31谭章禄陈孝慈
谭章禄,陈孝慈
(中国矿业大学(北京) 管理学院,北京 100083)
一、引 言
数据中蕴含着大量信息,信息的价值需要经过缜密的分析获取,分类(classification)是指通过对离散型变量的建模,预测其属性或类别,它既是数据分析的一种重要形式,同时也是机器学习的一个重要任务[1]。分类的目的是从人工标注的分类训练样本(训练集)中,学习出一个分类函数或分类模型,基于此建立分类器,当有新数据时,即可根据已有的函数或模型进行预测,从而将新数据(测试集)映射到给定类别的某一个类中[2-3]。这种分析能够帮助研究者快速、全面地理解数据。
采用什么样的分类器能够更好地解决问题,离不开对分类器性能的评价。作为分类的最后一步,分类器的性能评价是分类过程中不可或缺的环节。对于待分类数据分类效果的好坏决定了分类器的性能,基于这一思想,Van Rijsbergen于1979年首先提出精确率(Precision)和召回率(Recall)等评价指标并获得诸多研究者的广泛认同[4]。之后,国内外研究者又针对不同的情境提出了新的分类评价指标,如接收者操作特征曲线(Receiver operating characteristic,ROC)能够在样本正负变换时保持形状基本不变,准确率(Accuracy)能够在部分环境下判断分类器是否有效,这些研究成果丰富了研究人员评价分类器分类效果的手段,对于分类器评价标准的建立贡献良多[5-8]。分类技术发展至今,所面临的数据环境越来越复杂多变,如何判别分类器有效与否显得尤为重要,当面对大规模、不平衡数据集时,现有的评价指标体系越来越难以满足需求,分类器评价指标相关研究有必要继续深入[9]。设计合理的分类器评价指标,不论是对于分类任务的良性进行,还是评价指标的推广应用,都具有深刻的理论意义和广泛的现实意义。
二、分类器性能评价指标
(一)传统评价指标
现阶段,分类器性能的评价指标中,以精确率、召回率和F1-score这三种指标的应用范围最为广泛[10]。为了更清楚地理解这些评价标准,用表1所示的混淆矩阵表示分类的最终结果。

表1 分类结果混淆矩阵
表1中相关名词解析如下:
真正例(True Positive,TP):被模型辨识为正的正样本,即分类器判定样本属于某一类而样本实际上也属于该类;
真负例(True Negative,TN):被模型辨识为负的负样本,即分类器判定样本不属于某一类而样本实际上也不属于该类;
假正例(False Positive,FP):被模型辨识为正的负样本,即分类器判定样本属于某一类但样本实际上不属于该类;
假负例(False Negative,FN):被模型辨识为负的正样本,即分类器判定样本不属于某一类但样本实际上属于该类。
基于表1,精确率的计算公式为:
(1)
召回率的计算公式为:
(2)
F1-score计算公式为:
(3)
三种指标中,精确率用于衡量分类器的查准率,表示辨识为正的正样本占所有辩识为正的样本比重,精确率越大,表明分类器准确率越高;召回率用于衡量分类器的查全率,表示辨识为正的正样本占所有正样本的比重,召回率越高,表明分类器的查全率越高;F1-score是一种综合考虑查准与查全的评价指标,F1-score的值越大,表示分类器越有效。
上述三种指标具有较好的独立性、时间无关性、可扩展性和较低的计算复杂度,因而在众多研究和实践中获得广泛应用。但是,不少学者经研究发现,上述指标并未考虑到分类结果的稳定性以及当前广泛存在的数据不平衡问题[11-14]。在现实的应用中,分类结果不稳定以及样本数据不平衡的现象普遍存在,人们或强调整体性能,认为每一类结果的准确与否同样重要,或对于某一类或几类样本的分类效果的要求更高,而对样本的整体分类效果具备一定的容忍。例如,多个类别的数据样本中,人们可能认为局部分类效果较差不可接受;人们也可能认为样本数量较多的类别比较重要,因为这些类别上即使较低的错误率也意味着较高的错误数量;又可能认为样本数量较少的类别更加重要,因为即使少量错误也会使得该类别样本错误率较高。上述情境在现实中普遍存在且较早即引起研究者关注,但目前尚未取得公认的突破性进展[15]。
为了解决这一问题,研究者提出了两种不同的解决思路,其一是通过多种数据预处理方法,使得不平衡数据集趋于平衡,如Wang[16]等设计了一种多策略集成特征的分类器,在分类之前对不平衡数据集进行下采样,使得多数类与少数类样本数量达成平衡,Li等[17]对数据进行预先打分,提取出每类得分最高的部分数据进行实验,从而实现了不平衡数据集转化为平衡数据集,但这类方法大大增加了数据分析的复杂度,对计算机性能提出更高的要求。另一种解决方法即是从评判标准层面出发,设计全新的分类器分类性能评价指标。
(二)新评价指标
精确率、召回率和F1-score这三类评价指标在实际应用中已经证明其价值,因此,新指标在这三类指标的基础上加以改进。新指标着重关注分类结果的稳定性,同时,新指标必须能够根据样本的数量分布来调节类别的重要性。对于分类结果的稳定性,可以用单个类别的分类效果与总体效果差异来表示;对于样本的重要程度,可以用单个类别样本与样本总量的比例来表示。基于这一思想,假设待分类的样本共有n类,待分类样本的总数为C,第i类待分类样本的数量为ci。
设定平衡精确度(Stable Precision,SP)的计算公式为:
(4)
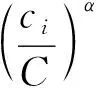
设定平衡召回度(Stable Recall,SR)的计算公式为:
(5)
式(5)中,Ri表示第i类样本的分类召回率,R表示所有样本分类召回率的宏平均。
设定平衡F1-score(Stable F1-score,SF)的计算公式为:
(6)
式(6)中,Fi表示第i类样本的分类F1-score,F表示所有样本分类F1-score的宏平均。
上述三类指标,SP衡量分类器的查准率,SR衡量分类器的查全率,SF是一种综合性指标,它们最终取值范围均在区间[0,1],指标的值越大代表分类器的性能越好。与现有指标相比,新指标在不大幅增加计算复杂度的前提下,通过单一类别指标与指标平均值的差值体现平稳性,通过调节系数α来体现人们对于类别的样本数量的重视程度。
三、实验与分析
(一)实验设计
为了验证上述评价指标对分类器的评价效果,分别使用卷积神经网络(Convolutional Neural Networks,CNN)与循环神经网络(Recurrent Neural Network,RNN)建立文本分类器,进行文本分类对比实验,利用新旧指标评价最终的分类效果[18-19]。相关实验流程如图1所示。
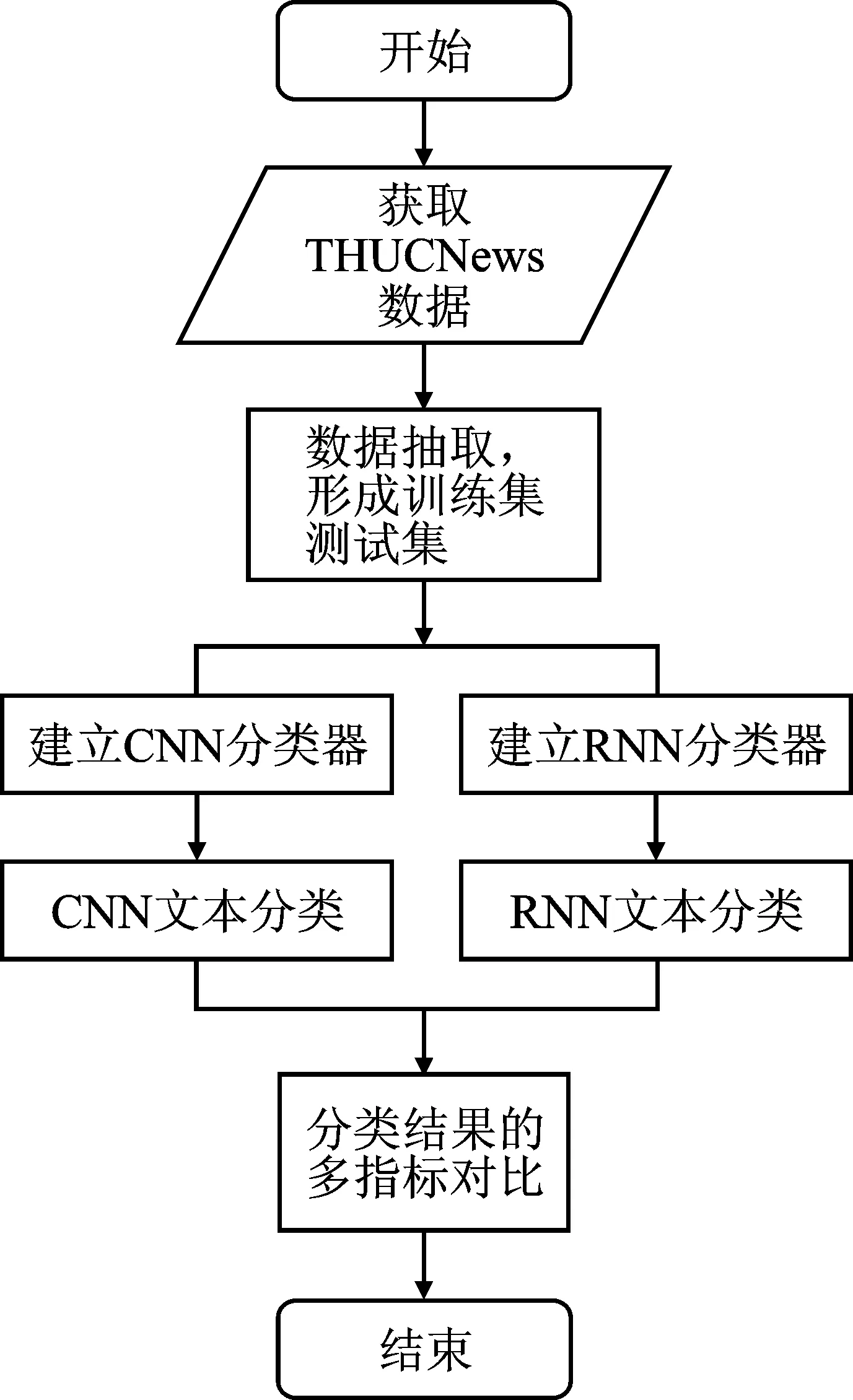
图1 实验流程图
(二)数据选取
数据源自清华大学自然语言处理实验室提供的THUCNews中文文本数据集,分别利用两种分类器进行10次对比实验[20]。两类分类器在全部实验中仅改变训练集数据,不改变测试集、分词表、停词表、分类器参数等设置。数据集的类别分布情况如表2所示,实验中训练集各类文本数据量呈等差数列增加,通过调节训练集文本数量改变实验结果。每次实验中两分类器的训练集数据保持一致,数据从数据源中随机抽取。所有实验的测试集数据均相同,但每类文本数量不一致。
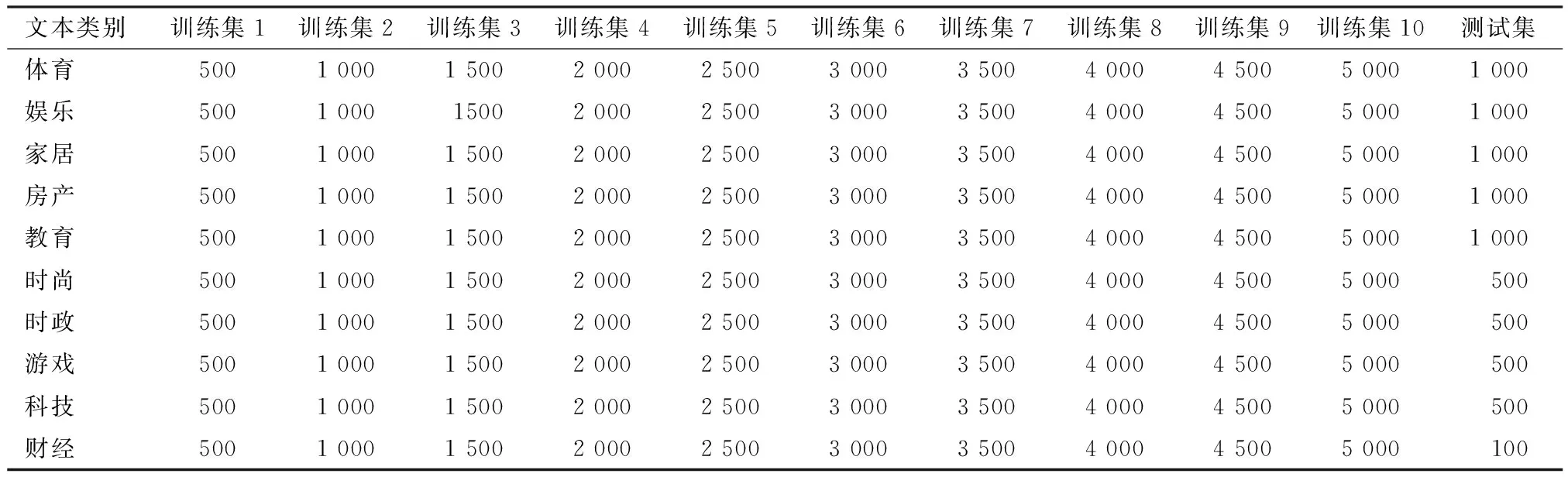
表2 数据集概况表
(三)实验结果及评估
分别利用CNN与RNN分类器进行实验,设计开展10组对照实验,实验最终结果如表3及图2所示。
图2中,横坐标表示训练集中每类样本的数量,纵坐标分别代表精确率、召回率和F1-score,所有图像的横纵坐标范围均相同。从表3及图2可以初步发现,CNN分类器在所有情境下的表现均好于RNN分类器。但是,在训练集每类样本数量为 2 500、3 000和3 500的实验中,两种分类器的表现十分接近。进一步观察表3中数据后发现,三次实验中,CNN分类器稳定性表现不佳,在“财经”这一类别文本的分类中,其最终分类效果不仅与其它类别的分类效果有一定差距,而且较RNN分类器明显不如,这一现象从三种现有评价指标中并未体现出来。在这三次实验中,如果仍然认为CNN分类器的分类效果更好,则显得缺乏依据。
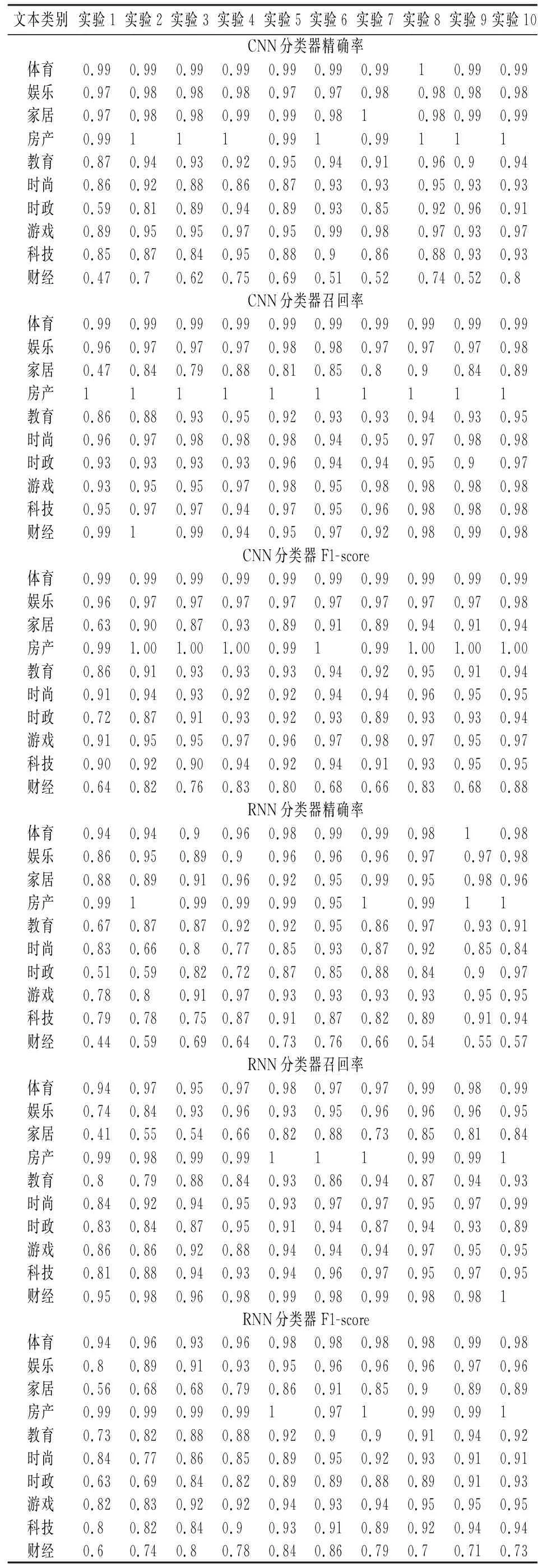
表3 分类实验详细结果
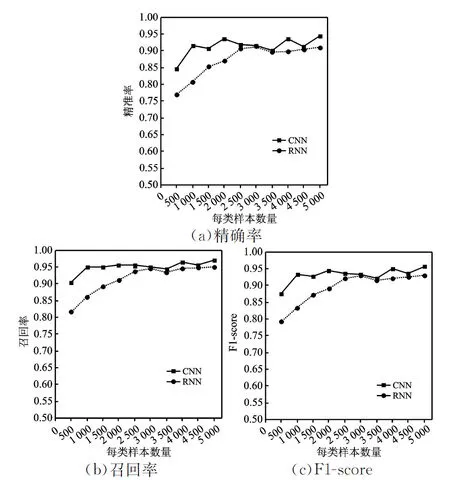
图2 现有评价指标评判结果
对照实验的目的是为了验证改进的分类器分类性能评价指标对分类结果稳定性的评判是否有效,以及调节系数是否发挥预期之内调节重要性的作用。分别设定α=0及α=1,利用改进的评价指标评判各分类器(图3)。
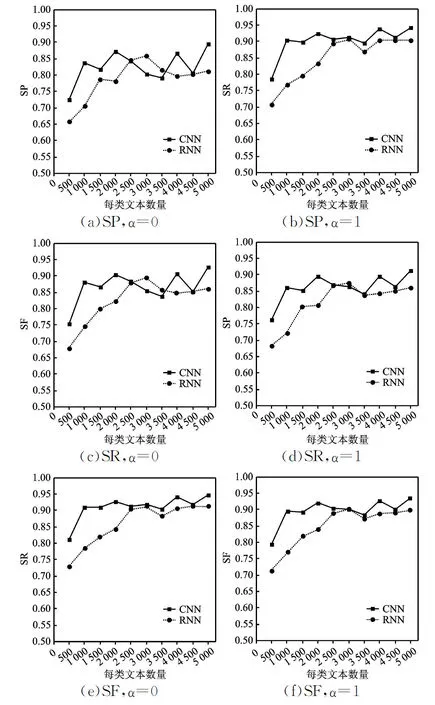
图3 改进评价指标的评判结果
图3中,横坐标表示训练集中每类样本的数量,纵坐标分别代表SP、SR和SF,所有图像的横纵坐标范围均相同。
实验中,当α=0时,其含义为不考虑各个类别中待分类样本的数量多少,视每类样本的分类结果对总体结果而言同样重要。在此条件下,当训练集每类样本数量为3 000或3 500时,CNN分类器在SP和SF两指标上表现明显不如RNN分类器,结合表3发现,这是因为在“财经”这一类别中,CNN分类器的精确率明显偏低,进而降低了分类精确率的总体稳定性,这一因素同时也影响了SF。
当α=1时,各个类别的分类结果对总体结果的影响与各个类别中待分类样本数量正相关,每一类别待分类样本数量越多,则其分类结果对总体结果越重要。在此条件下,仅当训练集每类样本数量为3 000时,RNN分类器在SP和SF两指标上表现略微优于CNN分类器,与α=0时的差异明显。结合表3发现,由于“财经”类文本数量较少,当α=1时,这一类别分类结果对总体的影响较低,虽然CNN分类器对于“财经”类别的分类效果不佳,但这一差距被淡化。
虽然造成CNN分类器在部分情境中表现较差的根本原因都是对于“财经”类文本的分类效果不好,但是,由于调节系数α的取值不同,使得两种情境下对于分类器的最终评判结果并不相同。当α=1,训练集每类样本数量为2 500和3 500时,CNN分类器在三种新指标上的表现均比RNN分类器优秀,这是由于前者在其它类别上的表现存在明显优势,相较于α=0的情况,α=1加强了这种优势。上述情况说明α能够控制某些类别样本重要程度。总体来看,实验结果表明改进的分类器分类性能评价指标能够较好地衡量分类结果的稳定性、调节样本的重要性,实现了预期目标。但是,一方面,由于调节系数范围的限制,改进的指标中,实际上处于与样本量“完全无关”到与样本量“正相关”的范围内,这掣肘了改进的指标的进一步推广应用。未来,对于样本重要程度的调节,应当实现按样本数量调节以及按实际需求调节两种形式。另一方面,改进的指标仍然增加了计算复杂度,如果样本类别多、数量大,对运算速度会产生较大的负面作用。因此,分类器分类性能评价指标仍然有待进一步发展完善。
四、结 语
针对现有的分类评价指标无法很好地评判不均衡数据的分类效果问题,因此,在精确率、召回率和F1-score这三种指标的基础上,提出了综合分类结果平稳性的SP、SR和SF评判指标,并以THUCNews数据集为基础实验设计开展研究。
实验结果表明,新指标能够更好地体现分类器分类结果稳定性。同时,通过引入调节系数,分类器能够根据样本数量实现对于类别重要性的划分,这显著增加了新指标应用的灵活性。实际应用时,调节系数还可以设定为与其它因素相关的函数,以期根据研究者需要,实现更精确的权重调节。下一步的研究工作,需实现稳定性重要性调节,同时实现研究人员对稳定性的调控需求,进一步增强指标的实用价值。
