基于改进自顶向下的行人运动预测方法
2020-08-31王淑青刘逸凡
王淑青,刘逸凡
(湖北工业大学电气与电子工程学院,湖北 武汉 430068)
行人检测技术广泛应用于先进辅助驾驶领域,在该领域中,行人检测往往在环境条件好,行人之间没有重合的情况下检测效果明显,对复数情况下的行人检测一直以来是重要的研究内容[1],本文提出了一种基于改进后的自顶向下法的多人姿势检测的算法并应用于一种实时的人体运动的预测。
识别图片中的单人姿态检测要比多人姿态检测容易得多[2],而且识别图片中的行人姿态要比识别复杂环境中的人体姿态容易[3-4]。目前有两种主流的多人姿态检测方法:自顶向下法(Two-step framework)[5-7]和自底向上法(Part-based framework)[7-8],自顶向下法是先检测环境中的每一个人体检测框,然后独立地去检测每一个人体边界的姿态,但这种方法极度依赖于姿态检测准确度,并且由于冗余的检测框也可能重复估计单人的边界框;自顶向上法则是首先检测出环境中的所有肢体节点,然后进行拼接得到多人的骨架,但由于这种方法取决于人的肢体节点,在两人离得非常近时容易出现错误连接。
为了克服这些错误,Toshev等人提出的DeepPose[9]、W. Ouyang等人提出的基于深度神经网络[10]以及A. Jain等提出的基于卷积神经网络的人体识别算法可以简单地检测人体姿势[2-11],J. Dong等人还同时考虑了人体解析与姿势检测[12],但上述算法极易出现错误的边界框,而且冗余的边界框会产生冗余的姿态,但在定位和认知方面的小误差是不可避免的,这些误差会导致姿态检查的错误,尤其是仅依赖于人体检测结果的方法,不能满足当下辅助驾驶系统的要求。X. Chen等人针对行人被遮挡的情况提出一种将行人看作不同身体部位组合的模型[7]。G. Gkioxari等人使用K-poselets检测行人并预测行人姿势的位置,计算所有姿势的加权平均值来预测最终姿势定位[5]。L. Pishchulin等人提出先检测行人所有身体部件,再利用深度学习依次分割各个部件,通过积分线性编程对这些部件进行标记和组装[11-13]。E. Insafutdinov等人提出一种基于ResNet的更强行人身体部位检测方法和更好的增量优化策略[6-8],但只适用于较小的局部范围,应用性不强。
本文研究一种基于改进自顶向下法的多人姿势检测并应用于行人姿势预测方法。首先,将输入的视频提取一帧图片做人体边界检测处理得到不准确的人体边界框;然后,利用改进后的自顶向下法提取精确的骨点、人体边界框以及人体姿势;最后采用光流处理后经长短期记忆神经网络训练出0.5 s之后的行人运动姿势。
1 自顶向下法
Zhang等[14]提出的自顶向下法又称两步法(Two-step framework),第一步,对目标人体的多个关节点进行检测,利用一个新的梯形仿射不变量,推导出相关的平行四边形具有这种仿射不变量。第二步,将第一步得到的结果作为迭代过程的初始值,利用高斯—牛顿法对初始值进行修正,通过深度估计产生的7个误差函数和4个特征点的共平面性,建立了误差矩阵。
两步法改进了线性法对噪声的敏感程度、给出了第二步迭代的一个较好的初值并且该算法对每一帧图像分别进行处理,从而使图像的精度达到了预期的水平,消除了计算误差的相关性。
1.1 姿势识别
基于自顶向下法的行人姿势识别质量取决于人体边界框判定的精确程度,为保证姿势识别在计算高精确的人体边界判定框的同时具有高质量的姿势定位,本文采用一种基于双空间网络变换并单人姿势识别的改进自顶向下法来提高人体边界判定框的精度与姿势定位的质量。
1.1.1 人体边界判定框预处理人体边界判定框是姿势识别的基石,是决定姿势识别质量的一个重要因素。在一定范围内,人体边界判定框越小,人体定位就越精确,但是,现有的算法为了避免人体关节的丢失,对判定框的计算都比较保守。为了减小人体边界判定框大小的同时也能保留易丢失的人体关节,本文采用Liu等[15]提出的基于回归法的判定物体的类别和位置,其计算过程为:
其中:d=(dcx,dcy,dw,dh)表示先验框的位置,其对应边界框的位置用b表示;(cx,cy)表示边界框的中心坐标;w,h分别表示边界框的宽与高;l表示边界框的预测值,其中:
1.1.2 双空间网络变换并单人姿势识别前文中使用的回归法以及现有的人体边界判定框算法中,为了提高判定框的准确率,过多地增加了判定框的数量,造成了大量冗杂的判定框的产生。空间网络变换(STN)可以通过变换输入的图片,降低受到数据在空间上多样性的影响,来提高卷积网络模型的分类准确率,而不是通过改变网络结构。为了避免人体边界判定框普遍存在的冗杂问题,本文采用双空间网络变换并单人姿势识别(SPPE)的自顶向下法来过滤冗杂问题,其计算过程为:

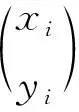
其中:dj1、dj2分别为两个骨点的位置;Lc为两骨点组成的线段,p(u)=(1-u)dj1+udj2为两个骨点dj1、dj2之间的插值。
为了避免精确度较高的CNN单人姿势检测算法以及现有的单人检测算法存在的冗杂骨点数量过多的问题,本文对冗杂骨点进行第二步置信处理:选取最大置信度的骨点Emax作为参考,定义η为标准的阈值,对其消除离得比较近且相似的的骨点(dj1、dj2),则:
若E(di,dj)输出为1,则表示骨点di是冗杂的,应被消除;若E(di,dj)输出为0,则表示骨点dj是冗杂的,应被消除。
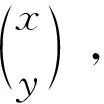
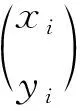
[γ1γ2]=[θ1θ2]-1
γ3=-1×[γ1γ2]θ3
其中,[θ1θ2]的计算方法为:
θ3的计算方法为:
1.2 光流处理
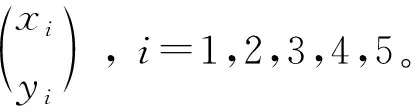
本文对这5张图片进行光流处理,得到各个骨点的位移向量ε(d),计算过程为:
ε(d)=ε(dx,dy)=
v=u+d=[ux+dxuy+dy]T
其中v为该骨点在下一帧的新位置,u表示该骨点所在的位置。
由于LSTM神经网络适合于处理和预测时间序列中间隔和延迟非常长的重要事件[18],本文将上述五个连续帧E(di)以及光流处理后的骨点位移偏移量ε(d)传输到长短期记忆神经网络(LSTM)进行训练模型,每进行6次训练即每30帧中提前0.5 s生成一次骨骼框图Ef,所述Ef即为实时的行人运动预测框架(图1)。
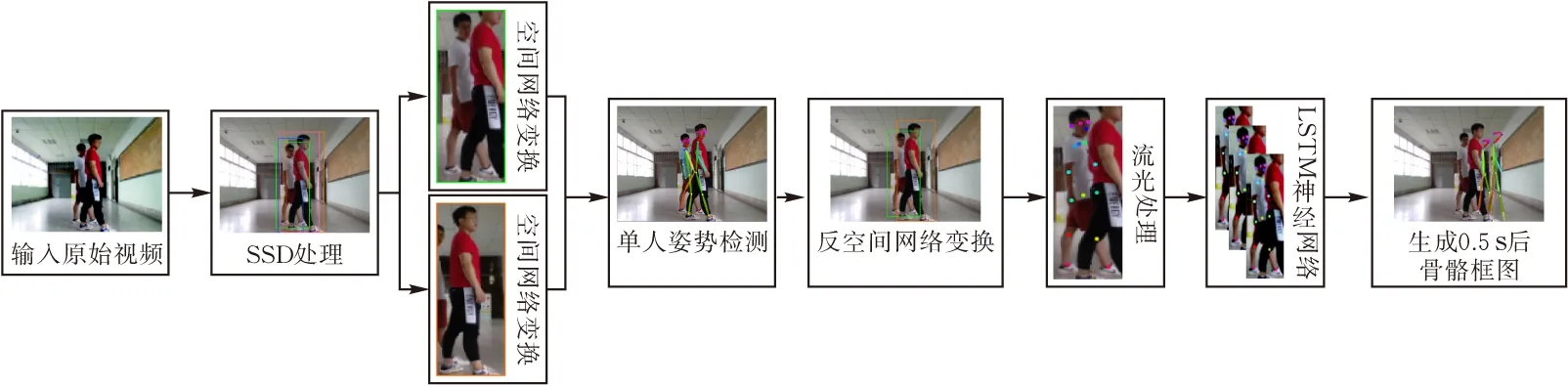
图1 算法流程图
2 实验结果与分析
2.1 仿真平台
所有对比方法以及本文方法均基于Ubuntu 16.04 LTS操作系统,依赖环境Python 3.6.5、Pytorch 0.4.1以及OpenCV 3.4.4,所用计算机处理器为Intel(R) Core i7-7700HQ (2.80GHz, 64bit),内存为8GB。将本文算法与Iqbal等[19]、DeeperCut[8]、Levinkov等[20]、Insafutdinov等[6]、Cao等[21]、Newell等[22]提出的方法基于MPII多人数据集[23]进行对比分析。本文算法取值η=90%。
2.2 结果分析
MPII多人数据集由3844个训练组和1758个测试组组成,这些测试组中既有遮挡的人,也有重叠的人。此外,它还包含超过28 000个单人姿势估计训练样本。本文使用单人数据集中的所有训练数据、多人数据集中的90%用来确定单人姿势检测的调整,剩下10%用于验证。
采用MPII多人数据集[23]所提供的精度计算公式,计算方法为:
其中:AP(Average Precision)为平均精确度;mAP值(Mean Average Precision)为平均AP值,是判断行人识别精度质量情况,该评价模型的图像质量值区间为[0,100],值越大,表示人体姿势检测质量越好。
在MPII多人数据集上测试了本文方法。表1给出了完整数据集的定量结果。本文所述方法在识别手腕、肘部、脚踝和膝盖等不同关节方面的平均准确度达到72 mAP,比之前的最新结果高出3.3 mAP。手腕的最终精度为76.3 mAP,膝盖的最终精度为79.8 mAP,本文所述方法在整体人体检测中进一步实现82.0 mAP,比目前最佳结果高出4.5 mAP。结果表明,该方法能准确预测多人图像中的姿态(表1),其中加黑数值表示当前最大值,结果可以发现,在大多数多人姿势检测中,本文方法优于其他方法,即本文方法能获得更精确的人体姿势。本测试部分结果如图2所示。
为了验证双空间网络变换并单人姿势识别的重要性,进行了两个对照实验。第一个实验中,从方法中移除了双空间网络变换并单人姿势识别。第二个实验中,只移除了单人姿势识别步骤,保持了双空间网络变换。这两个结果对照见表2。在移除了单人姿势识别步骤的实验中,可以观察到多人姿势检测性能下降,证明了带有单人姿势识别的双空间网络变换很大程度使空间网络变换提取高质量的单人姿势,以最大限度地减少总冗杂。
如图3所示,笔者对步行动作进行了0.5 s的预测,可以证明本方法预测行走动作效果较好。
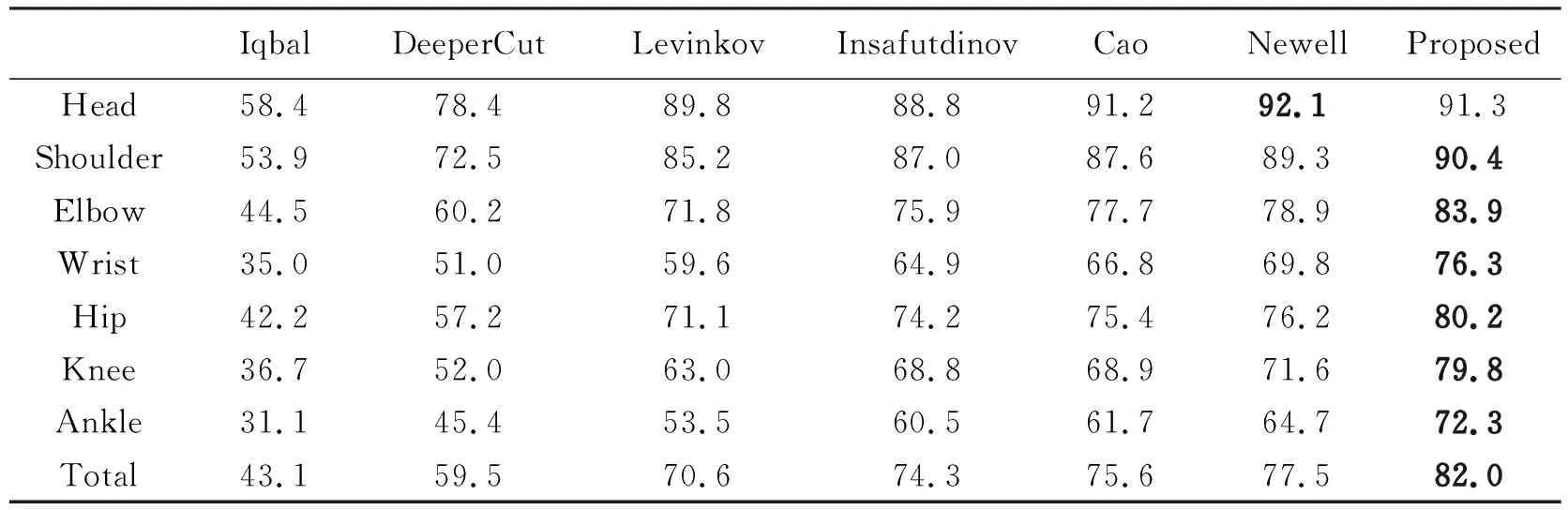
表1 7种方法的质量评价

图2 部分测试结果
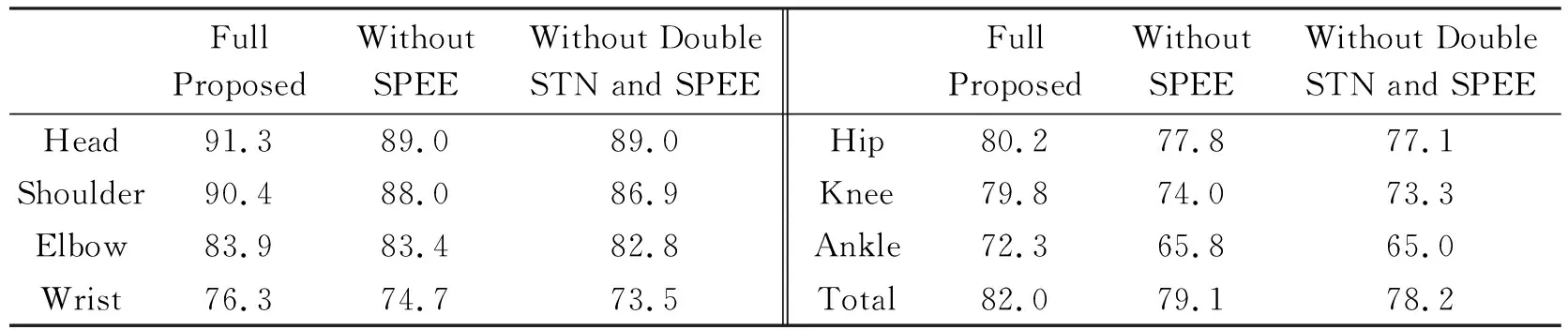
表2 对照实验结果

图3 0.5 s后动作预测结果
3 结论
提出了一种基于改进自顶向下法多人姿态检测的行人运动预测方法,将对输入的视频提取一帧图片做人体边界检测处理得到不准确的人体边界框,利用改进后的自顶向下法提取精确的骨点、人体边界框以及人体姿势,采用光流处理后经长短期记忆神经网络训练出0.5 s之后的行人运动姿势。实验验证结果表明本文方法对多人姿态检测的精度准确,并且实现了对行走动作的预测。
