基于公交运行数据的到站时间填充方法
2020-08-27张可朱远祺沈洁杨子帆钱慧敏王贝贝
张可,朱远祺,沈洁,杨子帆,钱慧敏,王贝贝
(1.北京市运输管理技术支持中心,北京 100073;2. 北京交通大学 轨道交通控制与安全国家重点实验室,北京 100044;3. 北京市交通运行监测调度中心,北京 100073)
近年来,随着我国经济的飞速发展,城市化进程加快,机动车出行比例提高,为了缓解制约城市扩张和经济发展的交通拥堵问题,政府大力发展公共交通[1-4]。为全面贯彻城市公交优先的政策,交通管理者需要掌握动态公交数据,深入了解公交运行特征,才能把握居民的公交出行行为规律,评估公交运行状态,制定科学的管理规划政策。目前的公共交通大数据主要包括交通基础路网数据、公交线网数据、车辆动态运行数据、用户刷卡数据、公交运营调度数据等几大类,这些数据是分析公交客流行为的基础,尤其是通过公交实时到站数据,可以实现对乘客的刷卡行为分析[5-9],从而有效地鉴别和处理客流数据。
由于每天产生的公交数据众多,数据缺失的现象并不少见。公交数据缺失直接影响对车辆的有效控制和对客流的细化分析,对规划管理和科学决策造成极大的影响,但是目前对于公交缺失数据的填充和处理方法研究仍处于较不成熟阶段,因此对公交缺失数据填充方法的进一步探究是有必要的。公交数据的缺失主要由GPS数据的不稳定性、GPS设备损坏、车辆状态和信号的不稳定性导致鉴于此,本文提出通过分析交通状态的类型以及驾驶员和车辆的特点,以车辆拥堵具有传播效应为前提假设[10-11],用其他路段、其他车辆的信息来模拟当前车辆的方法来填充缺失的公交数据。该方法充分考虑缺失站点数据的影响因素,使填充数据可靠性提高。
1 公交到站数据与影响因素
1.1 数据格式
公交到站数据是客流分析的底层数据,主要包括基础信息(数据记录日期、到站时间、线路总车站数)、站点信息(线路号、线路方向、站名、站序号)、车辆信息(车辆编号、车辆状态),详见表1。
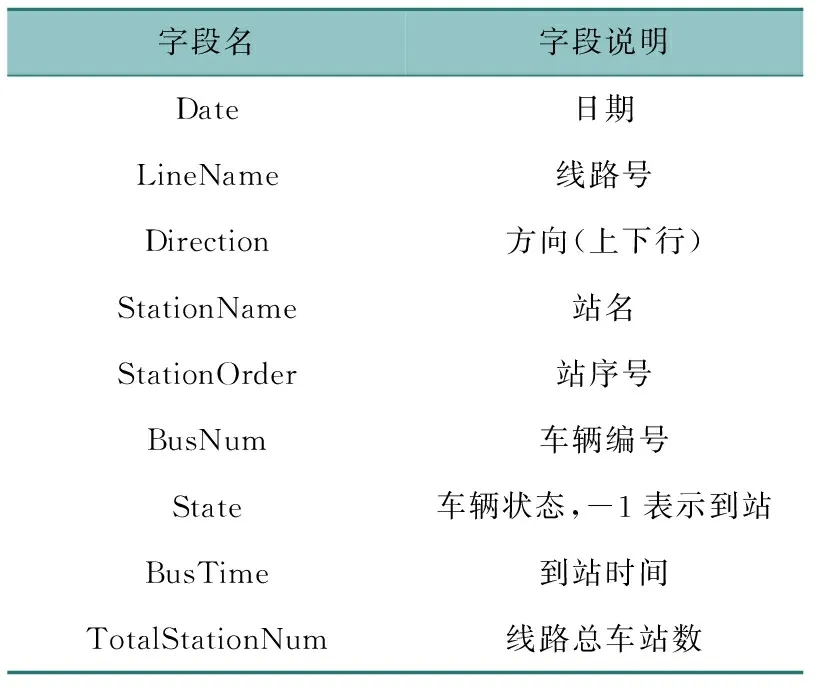
表1 公交到站数据说明Table 1 Bus arrival data description
1.2 影响因素
公交车辆在道路网络的运行状态会受到车辆、道路、驾驶员、乘客、实时路况等各类因素的影响[5],具体可分为:(1)车辆因素。车辆的大小、能源动力类型、车辆自身特性、GPS设备状态等会对车辆的行驶产生影响。(2)道路因素。路面状况、车道数、道路的等级和通行能力等都会对公交车运行情况产生影响。(3)驾驶员因素。公交司机的驾驶习惯、驾驶熟练程度、加减速特性等原因可能对车辆的驾驶时间产生影响。(4)乘客因素。上下车乘客的数量及类型比例会影响公交的运行。乘客数量较多时,公交停站时间会大大增加;乘客数量较少时,公交停站时间则会略少。当上下车乘客中老年人居多时,公交停站时间也会有所上升。(5)实时路况因素。在同一天的不同时段,公交的运行情况会产生较明显的规律性差异。例如在一天的早高峰和晚高峰时段,道路交通的拥堵将会导致运行时间增加;工作日与非工作日,道路状况也会发生动态的变化,从而影响车辆运行时间。
1.3 存在问题
每日产生的公交数据数量大,且未经处理的原始数据中存在一定的数据质量问题,公交 IC 卡刷卡和公交 GPS 数据在传回的过程中,由于设备故障、信号中断等问题,传回的数据存在一定的质量缺陷。另外,原始数据中的噪声数据、离群数据、重复数据等问题会对数据分析的结果造成影响。公交数据存在的主要问题有数据缺失、数据重复等。
1.3.1 数据部分缺失
由于GPS 信号的接收容易受到高大建筑物、山体的影响,在隧道时还会出现信号中断的情况,加之车辆状态的不稳定,易导致部分站点或乘客刷卡数据的缺失。部分数据的缺失可以依靠缺失部分前后的交通状态、前后车辆及路段和历史运行时刻表等进行填充。
1.3.2 数据大量缺失
部分车辆的GPS设备故障或数据导入过程中的数据丢失会导致该车数据的大量缺失。与数据部分缺失不同,数据大量缺失难以依靠后期填充,所以需要重新根据GPS或者AFC(automatic fare collection system)补全。
1.3.3 数据重复
数据重复问题主要由机械原因和人为原因导致。机械原因是由于机械因素导致的数据收集或保存的失败造成的数据缺失,比如数据存储的失败、存储器损坏、GPS设备故障导致某段时间数据未能收集(对于定时数据采集而言)。人为原因是由于人的主观失误、历史局限或有意隐瞒造成的数据缺失。
2 公交实时到站数据的填充方法
2.1 数据预处理
由于公交实时到站数据由每辆车的按时间排序的到站数据组成,其中不包含班次信息以及车辆运营信息。此外,数据中可能还存在不完整、噪声、不一致等问题。为了获取车辆的班次,以及各个站点的到发时间,需要对原始的到站数据进行数据预处理、数据清理、数据筛选、数据生成等步骤。
(1)数据清理。删除明显不合理的运营数据。研究发现,本研究所删除的不合理的公交实时到站数据中,冗余的数据量约占1.2%;公交运行数据中总运营时间小于平均时间的1/10,或者大于平均时间的10倍的数据,约占0.4%。删除的数据量较小,不影响后续的数据分析。
(2) 数据筛选。去除车辆长时间停站,以及重复的到站数据,保证处理后的数据具有唯一性,用于后续的公交实时到站数据处理。
(3) 数据生成。将不同类型的文件集成到统一的数据库,并按照到站时间和方向的时间和空间逻辑关系,设定合理规则生成车辆运营的班次,以及初始化的车辆运行时刻表。对于到站时间不满足前后时间逻辑的数据进行剔除。这里,前后时间逻辑是指对于某辆公交车,第i个站的到达时间必须大于第i-1个站的到达时间,小于第i+1个站的到达时间。
2.2 实时到站数据填充
针对公交实时到站缺失数据的补充方法,主要以近邻填充法、线性插值法和均值常量填充法为主。近邻填充法主要是通过选定缺失点相邻的3个或多个站点,根据这些相邻站点所提供的相关信息,对缺失点进行估算。该方法简单易操作,但当数据量较大时,所得的填充结果准确度会大幅下降。均值常量填充法是采用均值或众数对缺失点进行填充,所得结果粗糙,且有时甚至会对最终结果产生负面影响。
线性插值是指采用一次多项式(线性函数)的插值方法,如式(1)所示,通过连接两个已知量来确定未知量的方法。与其他非线性插值方法相比,线性插值具有简单、易实现的特点。但是,线性插值后的公交实时到站数据可能存在一定的逻辑问题,如车辆运行速度、区间运行时间相互关联关系等。
(1)
为了解决传统方法出现的问题,本文提出的公交实时到站数据填充方法考虑了与公交数据联系密切的三项因素:前后车的影响、前后路段的影响、多天的车辆运行时刻表,使填充的数据更具可靠性与真实性。该方法的主要步骤如下:
(1)查找当日所有运营车辆,循环查找每一辆车的到站数据,并按照时间排序。
(2)对于每辆车,按照运行方向的发生变化的情况,生成不同的车次。车次从0开始累计编号。
(3)对于每个车次,记录第一个和最后一个有到站数据的站序号start_station_index和end_station_index。确定车辆运行站间数量N=(end_station_index - start_station_index + 1),如果20%L≤N≤50%L(L为线路车站总数量),则确定为区间车;如果N< 20%L,则定义为无效车(需要根据实际进行调整)。
(4)对于首尾数据缺失的区间,对于前后车数据不足的区间,按照自由流速度v=25 km/h和站间距计算时间进行补全;对于前后车数据充足的区间,按照前车和后车的运行时间进行统计分析,采取多项式插值拟合的方法对缺失区间的数据进行补全。
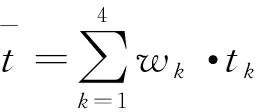
(2)
3 案例分析
3.1 数据说明
以北京市连接城区与北部郊区某大型居住区的公交骨干线路(线路A)为例研究,2019年1月1日—31日运营时段内,线路A的上行和下行的实时到站数据,该线路总长度约21 km。2019年1月工作日最高运营车辆数40辆,工作日平均实际运营车辆数为36辆,日均运行220车次,其中出城方向109车次,进城方向111车次,工作日日均运行237车次,非工作日均运行179车次。实时到站数据日均4412条,存在一定的缺失问题。
3.2 填补结果
根据本文提出的方法对公交实时到站数据进行填补,得到了线路A上行、下行方向的实时公交到站信息以及时刻表,其中上下行未进行修正补全的时刻表如图1(a)和图1(c)所示,修正补全后的时刻表如图1(b)和图1(d)所示。图1中各图的横坐标为时间,纵坐标为车辆位置到上行始发站的距离。从运行图可以看出,线路A的车辆运行时间基本稳定,单程运行时间约为70 min。在14:00—17:00,12 km附近出现了局部的拥堵。在图1(a)和图1(c)中未补全的时刻表存在时刻表车辆轨迹交叉、数据缺失等问题,尤其是在首末站处问题较为严重。通过本文提出的方法进行数据处理与补全后,如图1(b)和图1(d)中以上问题得到处理。

图1 线路A修正前后时刻表Fig.1 Modifed bus timetable of Line A
根据修正补全的实时到站数据,可以对公交车辆的大间隔区间进行有效分析。图2为车站B填充前后的车辆到站数据,橙色线为原始数据,蓝色线为补全数据。由图可知,原始数据只记录了34条,表明某些车辆到站时间数据缺失,导致计算到站时间间隔变大。将每辆车到站时间补全后(蓝色线),数据计算到站时间间隔明显减小,表明补全结果可信度较高。由于近邻填充法仅考虑该辆车周围相邻站点的运行时间,计算得到运行图仅考虑了当前车的运行情况,很容易产生车辆密集或者大间隔的情况。由本文提出的方法得到的运行图考虑了车辆之间的相互影响,因此能够得到较为稳定的运行间隔。
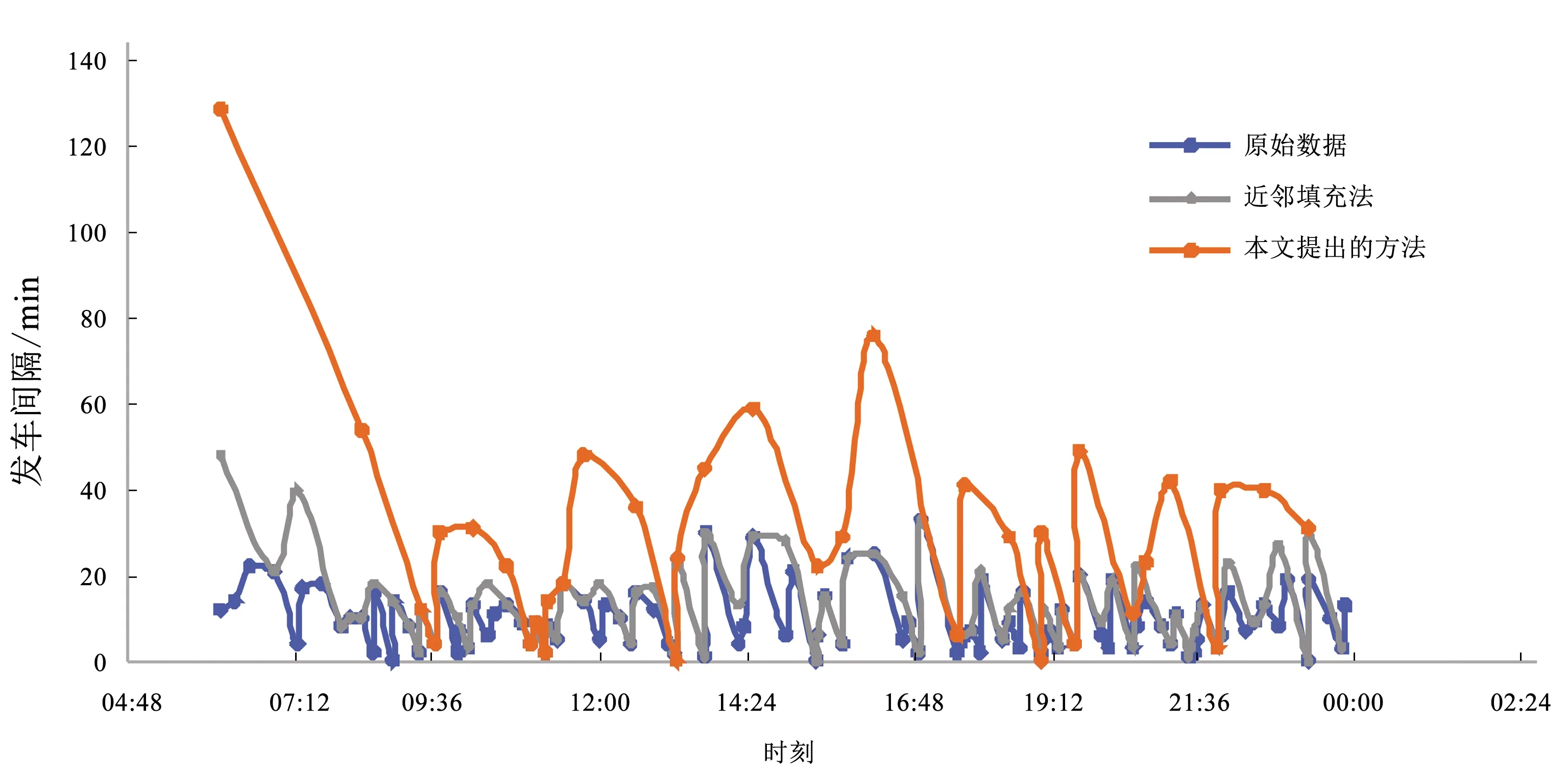
图2 车站B发车时间间隔Fig.2 Bus departure time interval at Station B
3.3 运行间隔与串车分析
图3为线路A下行(进城方向)的跟踪间隔大于15 min到站时间时空分布图(站名已省略)。由图可知,城区路段易出现大间隔,且大间隔时间较长,公交运行可靠性较低;大间隔多发生在平峰时段;平峰时段中12:00—15:00之间发生大间隔变大,导致大间隔次数增多。
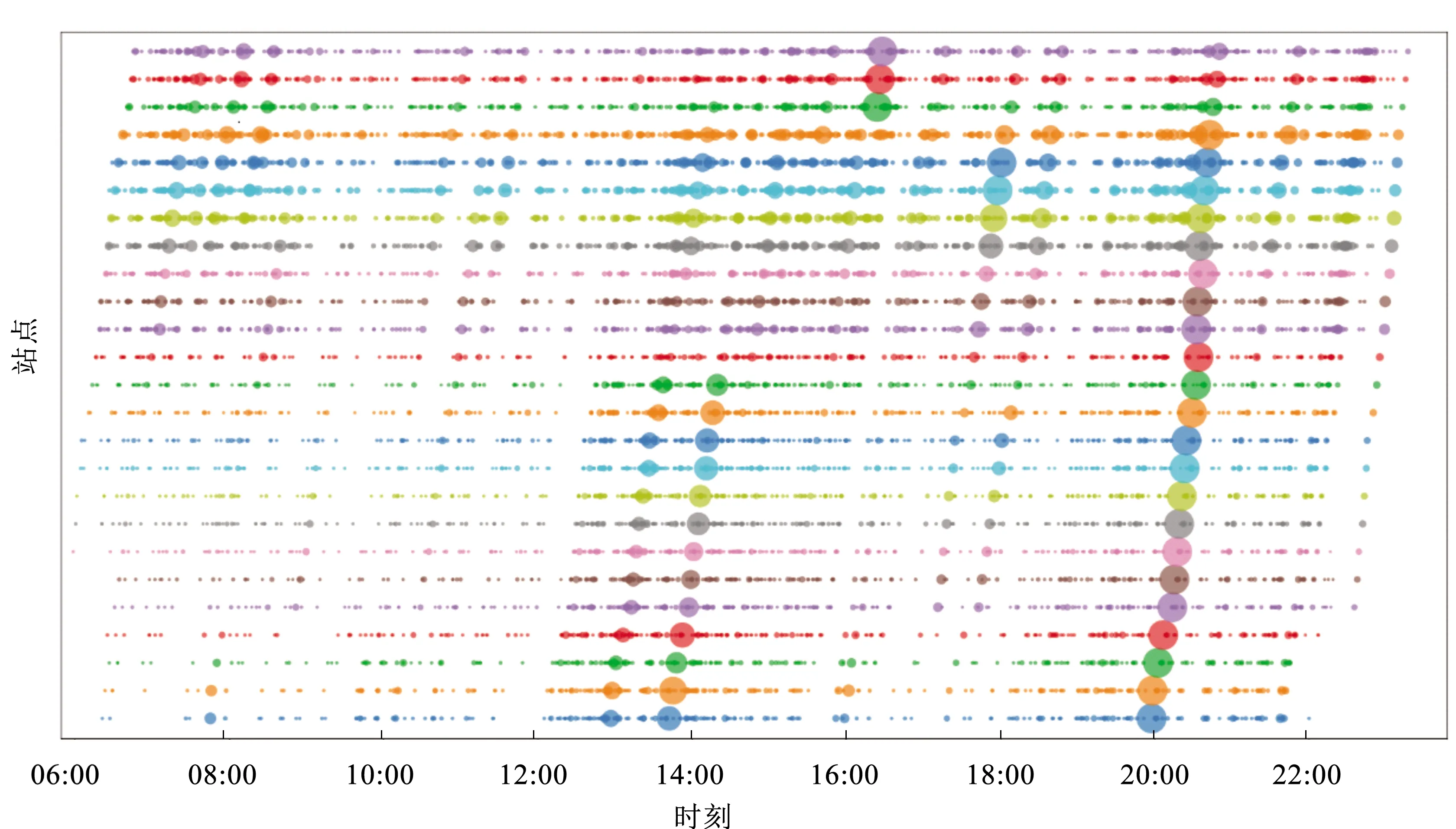
图3 线路A下行运行间隔分析Fig.3 Analysis of the bus running time interval of Line A in the downward direction
图4为线路A上行(出城方向)的跟踪间隔大于15 min到站时间时空分布图。由图可知,相较进城方向出现大间隔现象的高频率,出城方向出现大间隔现象明显较少。其中,大羊坊公交站以北路段发生大间隔的频率较高,公交运行可靠性较低。

图4 线路A上行运行间隔分析Fig.4 Analysis of the bus running time interval of Line A in upward direction
图5分别为线路A下行(进城方向)与上行(出城方向)跟踪间隔小于1 min的到站时间时空分布图。
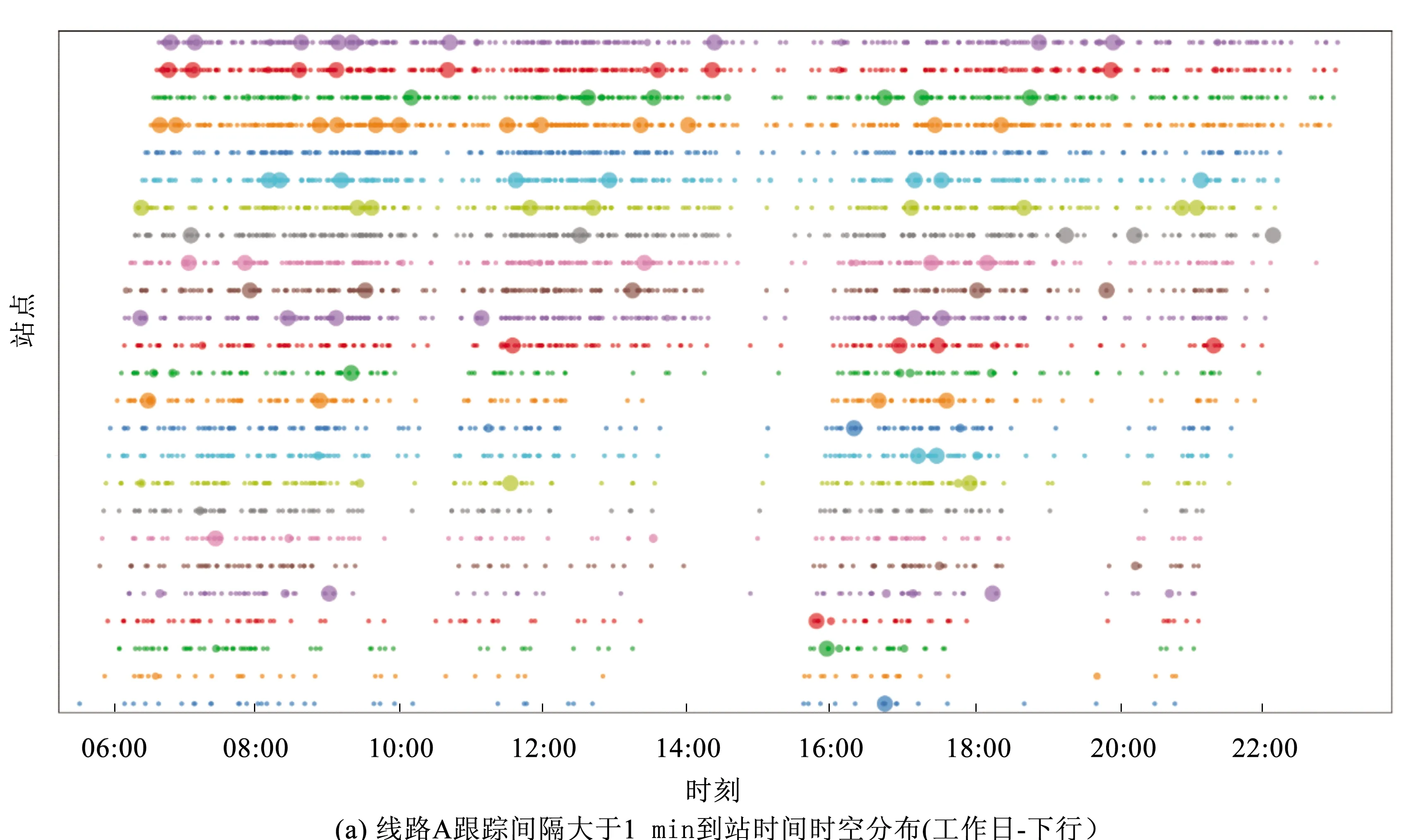
图5 到站时间间隔分布Fig.5 Distribution of the arrival time interval
总体而言,进城方向的串车情况易发生在早晚高峰及后半段路段。14:00—18:00时间段内和22:00之后,公交串车现象减少。早晚高峰的串车现象均是从和平西桥北站开始加剧,说明该路段在高峰时段较为拥堵,站点延误较大。自地铁立水桥之后,道路拥堵缓解,串车现象开始减少。
表2分别为线路A上行、下行各运行区间的车辆平均行驶速度。进城方向的低效运行区间明显多于出城方向,进城方向的区间4、11、24及出城方向的区间3和8为运行效率较低的站点区间。
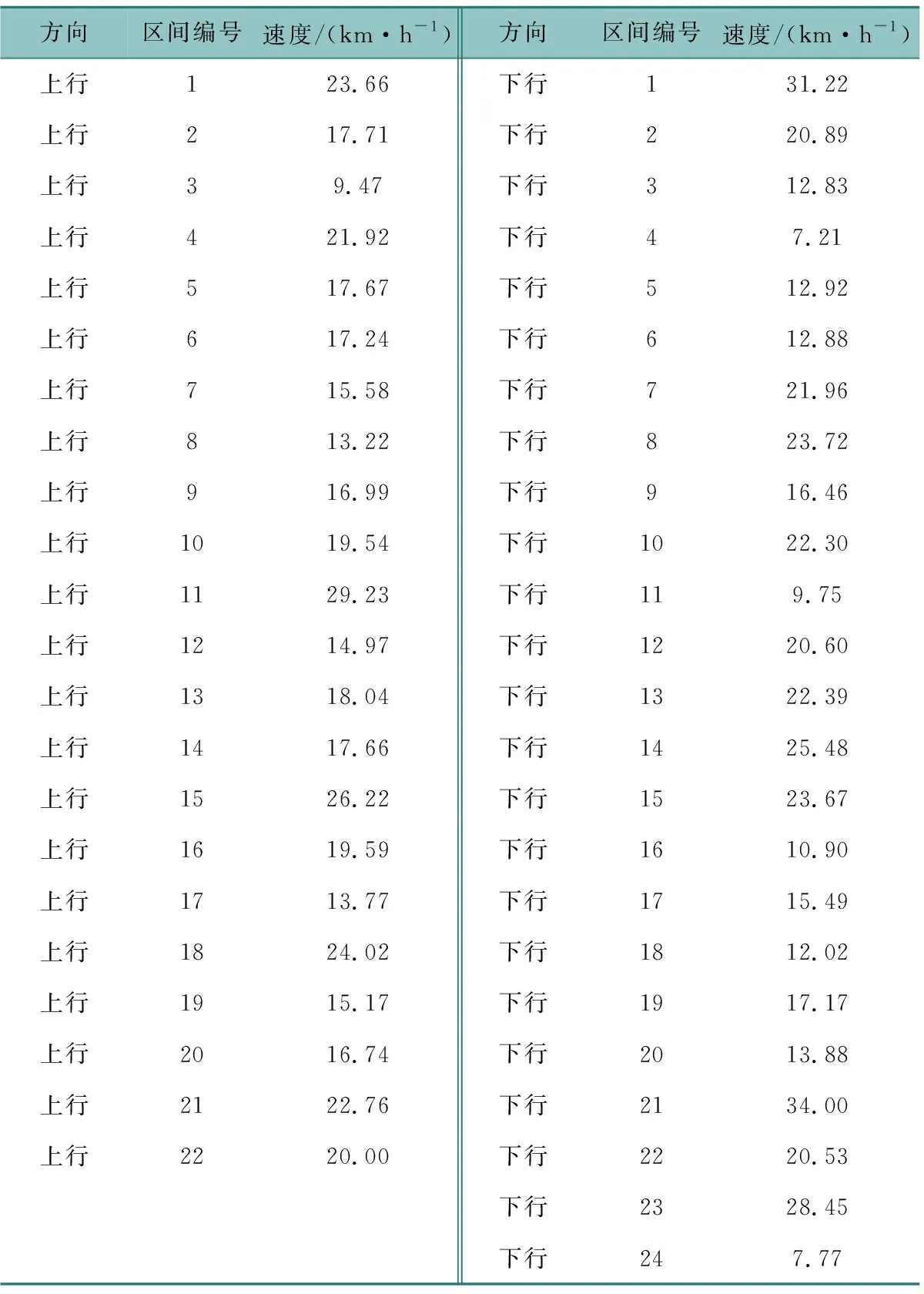
表2 区间平均运行时间分析Table 2 Intersection average travel time analysis
4 结论
针对国内对公交缺失数据的填充方法研究较少,且现存填充方法精准度与可靠性低的问题,本文提出一种在车辆拥堵具有传播效应的前提下,综合考虑前后车辆、路段状态模拟当前车辆的方法来填充缺失的公交数据。该方法充分考虑缺失段周围的影响因素,对缺失数据进行有效填充,数据计算到站时间间隔明显减小,使补全数据的可靠性更高。最后,以北京某条公交线路的实时到站数据进行算例计算和分析,结果表明,填充后的数据质量较原始数据大幅提升,各到站时间间隔均处于一个较为合理的范围内,数据分布更为密集,且可靠性更高,有效证明了该填充方法对公交数据分析的实用性。
