基于硬件资源的加权轮询算法研究
2020-08-21陈震廖涛
陈震 廖涛

摘要:随着互联网应用技术的快速发展,各大型网站的用户规模也在急剧增长。由此带来的集中式访问,高并发等问题是Web服务器所面临的一项巨大挑战。使用负载均衡技术可以有效解决这一问题,但传统负载均衡算法中的加权轮询算法(Round-Robin,RR)是一种静态算法,无法在服务运行中动态调整集群的负载情况。为解决这一问题,文章将RR算法加以改进,提出了一种新的算法:基于硬件资源的加权轮询算法(Round-Robin Based on Hardware Resources.RRBHR)。该算法调用云监控EMS接口采集参数,在服务器间硬件异构性的基础上,设立动态调整机制分配权重,最终达到可动态调整服务器集群负载的效果。对该算法进行了相关实验,实验结果得出,改造后的RRBHR算法在响应时间和吞吐量上都要优于之前的静态算法。
关键词:负载均衡;服务器集群;加权轮询算法;高并发;动态分配权重
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2020)21-0072-04
开放科学(资源服务)标识码( OSID):
1 背景
伴随着互联网应用技术的发展与完善,人们大多日常的办公、通讯、出行、购物等都可以通过访问网站来完成。这方便人们活动的同时也给网站服务器带来了一个问题:随着大批量用户的请求量增多,网站服务器处理请求时的压力也在不断增大。在某些特殊的活动期间,如:节假日期间、商品的秒杀活动、双十一购物节等,用户短时间内对网站访问量会骤然激增。在这种高并发、高集中式的访问情况下,网站服务器需要在短时间内集中处理大批量请求,这会导致服务器的负载不断增大。其中,硬件性能较差的服务器处理请求效率低,可能会造成大量的请求积压,服务器负载会逐渐增大。在达到一定的阈值后,该服务器的性能可能会受到严重影响甚至崩溃,造成用户请求超时失效。而其他性能好的服务器由于处理请求效率高,接收的请求会很快地处理掉,处于相对空闲状态。为解决这一问题,增加服务器机器的数量,构建更多的集群来平均服务器的请求数是一种可行的办法。但这种方法花费金额巨大并且会增加网站后期运维成本,并不经济实用。此时,软件层面上的负载均衡(LoadBalance)技术成为人们的突破点[1]。这种搭建在服务网络架构上的负载均衡技术,可以有效地平摊高并发等问题带来的压力,均衡每台服务器的负载。从而能够维持各自服务器的性能,保障整个集群的运行稳定,是一种透明且廉价的方式,相比增加服务器集群数目更加灵活和经济实用[2]。
传统负载均衡算法可分为静态算法(static algorithm)和动态算法(dynamic algorithm)两大类。静态负载均衡算法常见的有加权随机算法,一致性哈希算法,轮询算法和加权轮询算法等。動态负载均衡算法常见的有最快响应算法,最小活跃数算法等。不同的负载均衡算法方案选择,对服务器集群的影响也不相同。对此,一些相关研究和各种负载均衡优化方案被提了出来。文婷婷等人提出了一种弹性算法,根据概率分布和资源需求,设计了一种弹性虚拟机迁移的负载均衡算法[3]。汪佳文等人提出了动态自适应权重算法,结合改进后的Pick-k算法,能够始终保证性能最优的节点提供服务[4]。王宇耕等人提出了基于负载预测的自适应算法,根据AR算法得出预测值的结果,调整服务器的权值[5]。张慧芳分析了加权最小连接数算法和IP隧道负载均衡技术,提出了一种可以根据动态反馈调整的算法[6]。王东提出了DWA算法,将Http请求分为事务性和发布性请求,对两种状态进行了分析后,根据DWA算法合理调整节点的任务调度进行负载[7]。
这些算法的研究,多数都是倾向于动态算法,在多数情况下,动态算法相对于静态算法,在性能和灵活性等方面都要优于后者[8]。静态负载均衡算法不考虑服务器的运行状态[9],其参数值是一开始就设定好的,以固定的权重分配任务。在程序运行过程中不会发生更改,即使运行过程中有服务器出现负载失衡,程序也会按照预先设定好的参数运行。动态负载均衡算法的参数值会根据程序运行时的环境不同,动态的调整更改参数信息,从而保障各个服务器的负载情况相似。
2 几种静态算法介绍与比较
普通轮询算法[10]的算法思想是将收到的请求以轮流分配的方式分给各个服务器,其算法简单,适用于服务器性能相近的情况。在实际的生产环境中,Weh集群的各个服务器的配置并不都是相同的,加权轮询算法是对普通轮询算法加以改进后的算法。在服务部署在服务器之前,开发人员会预先根据各个服务器配置性能不同,评估赋予不同的权值,使性能较好的服务器分配的权重大,性能弱的服务器分配的权重较小。通过权重调整各服务器处理的请求数,最终使得每个服务器总体处理的请求数大致等于预先分配的权重比,从而达到负载均衡的效果。加权随机算法思想基于古典概率分布,加权随机算法在服务启动前,事先为每个服务器提供了相应的权值,使各台服务运行中处理的请求数近似于它们权重的比例。加权随机算法简单高效,但在请求数较少时,其中多数请求会分配给权重较大的服务,可能出现请求倾斜的情况。一致性哈希算法是将服务器的IP地址或者其他信息作为依据,生成一个hash值投射到一定长度的hash环上。每当有新的请求时,根据算法,为其生成一个hash值,然后在hash环上查找出第一个大于或者等于该hash值的服务器节点,该请求会被投射在这个节点的服务器处理。以此分散服务器的请求,达到负载均衡的效果。
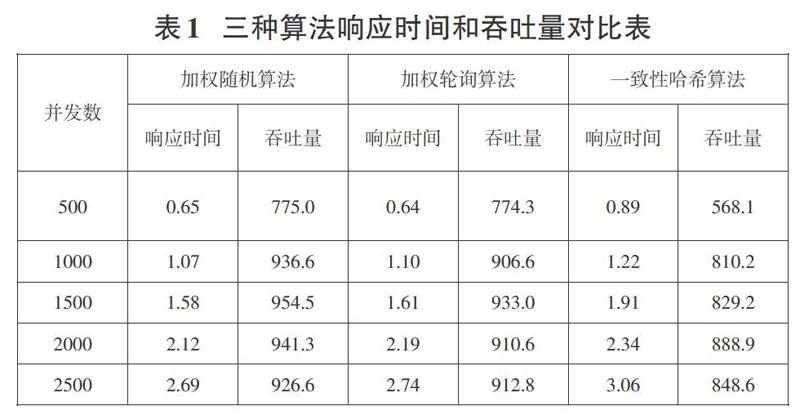
常见的衡量负载均衡算法的指标有响应时间和吞吐量。响应时间是指接受和处理一定数目请求所耗费的时间,本文中默认为单位为秒。吞吐量是单位时间内处理的请求数量。比较上述几种静态算法的性能,使用Postjson分别对加权随机,加权轮询,一致性哈希算法模拟进行500、1000、1500、2000、2500并发数的用户请求,去除最大值和最小值后取平均值进行数据统计,如表1所示。
从表1中可以看出,随着并发数的增加,三种算法的响应时间也逐渐增加,吞吐量趋于稳定。一致性哈希算法的响应时间高于另外两种算法,可能是因为请求处理过程中,大量的时间消耗在哈希计算中之中,也导致吞吐量低于其他两种算法。加权随机算法和加权轮询算法在响应时间和吞吐量上十分相似。由于加权轮询算法的特性,不会出现少请求量的数据倾斜问题,且服务器硬件的异构性更契合于加权轮询算法。将原本的静态算法改进为动态算法会有更大的提升空间,文章提出了基于硬件资源的加权轮询算法改进。
3 基于硬件资源的加权轮询算法
3.1 算法思想
服务器处理请求的能力与它们当前硬件使用率息息相关,以这些硬件使用率作为负载因子,如:CPU利用率,内存使用率,磁盘使用率,网络带宽使用率等[11],计算得出服务器的负载值Load(Si),作为评价服务器负载情况指标。并以每个服务器本身硬件参数为基础,通过公式W(si)计算得出各个服务器权值。在程序运行过程中,周期性的用负载判断公式O(Si)检测整个集群的负载状况。当某个服务器短时间处理请求数较大,负载较重出现负载不均时,动态的降低该服务器的权重以减少处理的请求数。当服务器处理请求数较少,处于相对空闲时,加大权重,增加处理请求数以提高整体效率。
3.2 算法模型建立
算法模型的建立需要考虑以下几个问题:1)采集服务器各负载因子时,如何尽量减少对服务器的侵人性;2)各项硬件的权重该如何合理分配;3)怎样把各服务器整体硬件配置的差异,抽象出来用数值化表现;4)如何判断调整权重的时机及如何调整权重。
采集负载因子对运行中的系统来说,是一种额外的开销,降低采集过程中对系统的侵人性有利于提高系统的性能。传统采集方式有Perfmon检测、Linux命令或向服务器植入程序等方式,这些方式会周期性的发送采集数据到数据库或日志中,研究人员再取出数据进行分析,使用这些方法需要对数据进行二次处理分析且较为复杂。本实验加入了阿里云开发工具包(Alibaba Cloud SDK for Java),使用RPC风格直接通过Http请求的方式,调用云监控的API采集数据。此种方法对服务器侵人性小且采集的数据不需要二次处理,可直接使用在算法中。
服务器运行过程中各项硬件使用率是实时变化的,硬件使用率越高,说明当前状态下的服务器负载越高。将各个硬件参数的权重系数与负载因子乘积之和作为服务器Si的负载指标函数Load(Si),如公式(1)所示。服务器负载Load(Si):
其中,k1+k2+k3+k4+k5=1。
k1代表相应硬件或指标的权重,表示该硬件在整个服务中的重要程度。L(Ci),L(Mi),L(Di),L(Ni)分别代表CPU使用率,内存使用率,磁盘使用率和带宽使用率,L(LJ是Load average數值,是Linux系统特有的属性。表示在一定时间间隔内,在CPU中运行列队的平均进程数。服务器运行过程中,各硬件的使用率越高,负载值Load(Si)越大,说明当前服务器的负载状况越高。
使用层次分析法( Analytic Hierarchy Process)确定公式(1)中的k值。建立层次分析模型,如图1所示:
在服务器硬件构成中,CPU负责大量的运算,是整个系统的核心。内存和网络带宽也是相对重要的部分,通过对比分析这些硬件的相对重要程度得出目标层对比表2。
服务器集群中各机器的配置并不是相同的,服务器的硬件配置越高,性能越好,处理请求的效率也就越高。本实验选取4台硬件配置各不相同的服务器,做了差异化处理,如表4所示。所有服务器的cpu型号皆为Intel⑩Xeon⑧系列。其中一台服务器使用Nacos和Dubbo架构提供分布式系统的远程过程调用(Remote Procedure Call.RPC)服务,以Nacos作为服务的注册中心,结合Dubbo自身的容错机制[12]呵保证服务的高可用性和可靠性[13]。其余服务器作为服务提供者,构成一个小型的服务器集群。
把服务器不同的硬件配置抽象出来,用具体的数值表示,得出服务器性能指数P(Si)。P(Si)用于衡量某个服务器在整个集群中的性能状况。
服务器性能综合指数P(S.):
P(Si)= P(Ci)+ P(Mi)+ P(Ni)
(2)
其中,P(Ci)代表服务器i的CPU性能在整个集群中的性能比值,通过查阅资料可知:型号为Platinum 8269CY的CPU单核计算能力是型号为E5-2682 V4的CPU单核计算能力的1.7倍,可近似认为两者CPU性能比值为1.7:1。同理,认为内存为IGiB的内存与2GiB内存的性能比值为1:2。以各项硬件性能比值之和作为评价服务器性能综合指数P(Si),P(Si)越大代表该服务器的硬件配置越高,处理请求的速度越快,可承受的负载能力也越强。
在初始情况下,为每个服务器分配权重。初始权重的大小由服务器硬件性能指数和当前硬件剩余性能组成,通过公式(3)计算得出权重W(Si)。权重的大小代表着处理请求能力的大小,服务器性能越好,处理请求效率越高,所分配的权重应该越大。
服务器权重W(Si):
P(ratio)代表某个服务器在集群中的性能比值,D(Si)是当前服务器的剩余性能。剩余性能的组成由各硬件剩余使用率和CPU空闲状况构成。
采集服务器负载信息的常见方式有周期式和贪婪式[14j。周期式是每隔一定的时间段或次数采集服务器的信息,贪婪式是每次请求都收集信息,再进行任务分配。过于频繁的收集、更新权值不但不会提高负载均衡能力,而且会对系统运行造成额外的负担。本实验使用周期式,引入了计数器i,每当服务器处理一次请求时,i加1,当i值达到某个阈值时,根据(6)的负载判断公式判断各服务器负载状况,并把i重置为0。
负载判断公式O(si):
a是失衡指数,作为阈值来衡量负载失衡程度,代表着基于本身性能基础上,该服务器负载失衡程度。O(si)的值越接近于0,说明当前服务器的负载状况越好。设定a值为0.3,若O(si)值小于0,说明服务器的负载较为均衡,不用调整权重,若O(s.)值大于0,说明系统负载不均,需要调用公式(3)重新计算并分配权值。使用此种权重更新策略既不会对系统本身的运行造成太大的负担,又能很好地均衡负载情况。
3.3 算法步骤与流程
算法执行的关键步骤如下:
第一步:使用Dubbo的RPC远程服务调用方案,将服务注册到Nacos上。构成可访问的服务提供集群。
第二步:服务初始化,调用云监控EMS接口采集服务器参数,通过公式(3)为每个服务器分配初始权重w(s,)。
第三步:开始处理请求,并设置计数器i,i的值随着处理的请求数增加而增大,i到达阈值时,通过公式(6)开始判断当前服务器负载情况。
第四步:若O(si)值大于0,说明当前服务器负载不均,调用公式重新分配权重w(si)。若O(Si)小于0,说明服务器状况良好,进行下一步。
第五步:计数器重新置为0,跳转到第三步,直至所有请求处理完毕。
算法流程图如图2所示。
4 实验结果与分析
把相同的服务分别部署到三台硬件配置各不相同的服务器上,使用Nacos和Dubbo架构实现服务的发现与治理。用本地主机作为请求端模拟用户高并发请求,访问部署在服务器上的服务。
在上述相同的实验环境下,对RR算法和改进后的RRBHR算法进行实验,得出表6。从表6中可以看出,在不同并发数的情况下,RRBHR的响应时间都要小于RR算法,并且整体的吞吐量也有了约6%-10%左右的提升。根据实验结果可以验证改进后的RRBHR算法可以在一定程度上提升整体服务器集群的性能。
5 结束语
通过检测服务器的硬件运行状况来动态更改加权轮询算法的权值,并设立了调整机制,减少了部分服务器由于负载不均造成压力过大甚至瘫痪的风险,达到了优化服务器集群负载的效果。改进后的RRBHR算法在性能上优于原先的静态加权轮询算法,有了约6% -10%的提升。该算法尚有一点小的缺陷:人为设置的计数器i值过小时,会更频繁调用云监控CMS的接口,可能会造成调用方法出错,得不到准确的负载因子。计数器值过大时,可能会造成调整权重滞后。如何合理地设置计数器i以达到性能的最优,是值得进一步研究的地方。
参考文献:
[1]罗拥军,李晓乐,孙如祥.负载均衡算法综述[J].科技情报开发与经济,2008(23): 134-136.
[2]胡利军.Web集群服务器的负载均衡和性能优化[D].北京:北京邮电大学,2010.
[3]文婷婷,李洪赭,面向云服务平台的弹性负载均衡算法[J].计算机与现代化,2019(10): 28-33.
[4]汪佳文,王书培,徐立波,等.基于权重轮询负载均衡算法的优化[J].计算机系统应用,2018,27(4): 138-144.
[5]王宇耕,肖鹏,张力,等.基于负载预测的自适应权值负载均衡算法[J].计算机工程与设计,2019,40(4): 1033-1037.
[6]张慧芳,基于动态反馈的加权最小连接数服务器负载均衡算法研究[Dl.上海:华东理工大学,2013.
[7]王东.动态反馈负载均衡策略的研究[D].哈尔滨:哈尔滨工程大学,2018.
[8]王红斌.Web服务器集群系统的自适应负载均衡调度策略研究[D].长春:吉林大学,2013.
[9]覃川.基于Nginx的Web服务器负载均衡策略改进与实现[D].成都:西南交通大学,2017.
[10]彭云亚.网格服务的动态分布式策略负载均衡的研究与实现[D].北京:北京交通大学,2008.
[11]高振斌,潘亞辰,华中,等.改进的基于加权最小连接数的负载均衡算法[J].科学技术与工程,2016,16(6): 81-85.
[12]何珞,基于Dubbo的服务治理研究[D].武汉:武汉理工大学,2018.
[13]马威.云计算环境中高保证隔离模型及关键技术研究[D],北京:北京交通大学,2016.
[14]孙兰芳,张曦煌.基于蜜蜂采蜜机理的云计算负载均衡策略[J].计算机应用研究,2016,33(4): 1179-1182,1198.
【通联编辑:谢媛媛】
作者简介:陈震(1995-),男,安徽合肥人,硕士,主要研究方向为智能信息处理;廖涛,男,副教授,硕士导师,主要研究方向为智能信息处理、数据挖掘。
