基于LDA和LSTM模型的研究主题关联与预测研究
2020-08-19朱光刘蕾李凤景
朱光 刘蕾 李凤景
摘 要:[目的/意义]如何挖掘海量学术论文中的研究主题,梳理研究主题的演化脉络和关联关系,预测主题前沿热点,对掌握科技竞争先机至关重要。[方法/过程]针对当前主题关联和预测研究中存在的不足,提出基于隐含狄利克雷(Latent Dirichlet allocation,LDA)和长短期记忆(Long Short Term Memory,LSTM)模型的研究关联与预测方法,首先基于生命周期理论划分多时序窗口,并利用LDA主题模型挖掘学术文献中的隐性研究主题,分析主题间的关联关系;基于主题预测指标的时间序列特征,运用LSTM模型对主题研究的发展趋势和研究热点进行预测,并结合基金立项和论文发表情况对预测结果进行定性修正。[结果/结论]案例分析结果表明,本文方法可以准确挖掘研究主题,分析主题关联关系,对研究主题研究走势和热点的预测具有实用价值。
关键词:LDA;LSTM;主题关联;主题预测;隐私
Abstract:[Purpose/Significance]Mining the research topics from a large number of academic literature,investigating the research evolution process and topic relation,and predicting the research fronts have significant importance to the technological competition.[Method/Process]Considering the research limitations of topic relation and prediction,a research framework of topic relation and prediction based on LDA and LSTM was proposed.First,multi-temporal windows were divided based on life cycle theory.Then,the hidden research topics from academic literature were mined based on LDA topic model,as well as the topic relation was analyzed.Furthermore,considering the characteristics of time series of topic predictors,research trends and fronts were explored based on LSTM,while the research results were improved in combination with funding programs and literature publication.[Result/Conclusion]The experimental results showed that the proposed method can accurately mine the discipline topics and analyze the topic relation,while has practical values in predicting the research trend.
Key words:LDA;LSTM;topic relation;topic prediction;privacy
進入21世纪后,互联网技术、移动通信技术、生物科技、新能源技术等成为新兴产业发展的强大推动力。为提升国际影响力,各国都在开展新一代科技革命,如中国实施5G通信战略,德国提出工业4.0战略,美国提出智能制造战略[1]。在此背景下,科技工作者和决策者需要准确把握领域发展趋势,对研究前沿动态进行识别与预测,以支撑国家科技政策的制定。学术论文作为重要和权威的知识载体,如何运用科学计量和文本挖掘等方法从海量文献中梳理研究脉络,预测研究前沿,对掌握全球科技竞争先机,建设科技强国起着极为关键的作用[2]。
近年来,众多学者在研究主题挖掘与识别、关联演化和前沿预测等领域开展了诸多研究,研究方法包括引文分析、社会网络分析、文本挖掘、技术路线图等[3-4],已形成一定范式,但仍存在以下不足:其一,主题关联的相似度计算方法不科学,词频分析、几何距离、余弦夹角等计算方法不能很好地反映主题和关键词的概率分布情况;其二,时序窗口切分不合理,多数研究将时间跨度平均切分,没有考虑到研究主题的生命周期特性;其三,主题预测较少分析时序变化趋势,指标设计不够全面,没有考虑到研究主题在时间维度上存在演化性和迁徙性。同时,基于时间序列的预测结果存在误差,现有研究缺乏定性修正的分析。
基于此,本文提出基于LDA(Latent Dirichlet Allocation)和LSTM(Long Short Term Memory)模型的多时序研究主题关联与预测方法,首先基于生命周期理论将主题跨度切分为萌芽期、成长期和成熟期等时序窗口,对不同窗口下的数据进行LDA主题挖掘和识别,并计算不同主题间的概率分布相似度,分析研究主题的演化趋势。进一步,引入主题热度、新颖度和迁徙度等前沿预测指标,利用LSTM神经网络模型对研究主题的发展态势和前沿热点进行预测,并结合近年的基金立项和论文发表对模型预测结果进行定性修正。最后,以隐私研究主题为例,通过实证分析验证所提方法的正确性和有效性。
1 相关研究
1.1 主题挖掘
主题挖掘是指情报分析人员从学术论文、技术专利、政策文件等科技文献中探测和识别隐含主题,追踪学科研究动态的过程[5]。目前,不同领域的主题挖掘研究主要运用文本聚类、共词分析、主题模型等文本分析方法,谭章禄等[6]以CNKI数据库中的研究文献为数据来源,抽取文章关键词并构建词频矩阵,运用SPSS软件对其进行聚类分析,并采用卡方统计抽取高关联度关键词对聚类结果进行分析;曲靖野等[7]以国家科技报告服务系统中的科技报告为数据源,采用Ward与K-means相结合的聚类算法对文本向量进行聚类分析;杨颖等[8]基于共词分析和社会复杂网络理论,利用科学计量工具BICOMB分析近两年间发文主题的社会网络结构,同时利用gCLUTO软件对其词频矩阵进行双向聚类,探索研究前沿。然而,文本分析方法依赖于词频统计和文本空间距离的计算,聚类结果也无法体现隐含的语义。
主题模型是一种概率统计方法,其假设主题根据一定的规则和概率生成关键词,因此在已知关键词的情况下,可以通过概率统计反推出文档的主题分布情况[9]。最具代表性的主题模型是2003年Blei D M等提出的LDA主题模型:引入Dirichlet先验分布,构建“文档—主题—关键词”三层贝叶斯模型,運用概率方法对模型求解,挖掘文档主题[10]。目前LDA模型在不同领域的主题挖掘研究中已被深入应用,曾子明等[11]以雾霾谣言为数据来源,定义用户可信度和微博影响力特征变量,采用LDA主题模型深入挖掘微博文本的主题分布特征,并采用随机森林算法进行谣言识别的模型训练;吴江等[12]基于社会支持理论,运用LDA模型研究在线医疗社区中的社会支持类型和用户参与程度;Kim Y等[13]利用LDA主题模型对Twitter用户发布的信息进行兴趣主题挖掘,实现兴趣内容推送和好友推荐;Song B等[14]构建基于“主语—行为—宾语”结构的LDA主题模型,实现对产业领域中专利文献主题的内容分析。
1.2 主题关联与演化
主题关联与演化是指对不同阶段的研究主题进行相似度计算或相关性分析,揭示主题的发展变化,从而了解当前研究的演化脉络[15]。主题关联与演化的研究方法主要有两种,一种是引文分析方法;另一种是文本挖掘方法。引文网络作为描述主题结构和关联的分析方法,可以深入挖掘主题信息,并凭借引用与被引用关系分析主题的关联和演化情况,但引文网络侧重于时间维度上的主题挖掘和演化分析,且容易因“跟风效应”产生虚假派系而阻碍主题辨识[16]。
近年来,研究学者尝试将时间维度引入LDA主题模型,提出了TOT(Topic Over Topic)、DTM(Dynamic Topic Model)、OLDA(Online Latent Dirichlet Allocation)等主题时序演化模型[17-18],关鹏等[19]以锂离子电池领域为例,基于时间窗口将文档划分为多个数据集,将研究过程分为成长期、快速发展期和融合期;夏立新等[20]利用LDA主题模型获取不同时间段的用户标签主题,通过标签兴趣度来动态感知用户兴趣,进而分析用户兴趣层级结构的演化规律;刘雅姝等[21]运用LDA模型对网络舆情数据进行主题划分,从实体属性、时间属性等多维特征追踪舆情话题的演化情况;Garroppo R G等[22]运用LDA模型对不同时间窗口的用户生成内容(User Generated Content,UGC)进行主题聚类,通过比较关键词突变分析主题的演化趋势。然而,现有主题关联与演化研究大多基于主题的时间跨度平均切分窗口,未考虑学科领域的生命周期特性。同时,LDA模型训练得到的“主题—文档—关键词”具有多项式概率分布特性,几何距离和余弦夹角的关联分析方法并不科学。
1.3 主题前沿预测
1965年,Price D J D S[23]最早提出研究前沿(Research Front)这一概念,此后众多学者分别从定性和定量角度对研究前沿的识别与预测展开研究,定性方法主要包括文献综述法和德尔菲法,然而定性研究的结果具有主观性和不确定性[24]。定量方法主要包括引文分析和文本分析方法,Kessler M M[25]最早将文献耦合分析方法引入到前沿识别与预测领域,该方法有效揭示文献的内在联系和学科架构变化;Morris S A等[26]基于文献耦合方法可视化展示热点主题分布、演变与衰老动态时序变化;侯剑华等[27]通过绘制文献共被引和引文结构变换的知识图谱,分别从共被引文献和施引文献的视角,对大数据领域的研究前沿进行预测。然而,引文分析法存在时间探测的滞后性,同时存在未深入文本语义内容等问题,一定程度上制约了研究前沿预测的准确性。
针对上述问题,研究学者采用文本分析方法,从词频探测和主题演化角度,追踪学科领域的发展趋势,预测研究前沿。He X等[28]利用突发词检测算法,通过分析文献的关键词和参考文献,研究其前沿趋势;张英杰等[29]采用基于高频词的因子分析法和战略坐标图法,预测领域的研究前沿;刘自强等[30]利用关键词词频排序、热点关键词群构建和时间序列模型分析等方法,分析梳理了近10年竞争情报领域的研究现状,运用关键词群分析、社会网络分析和时间序列模型分析预测其研究热点的发展趋势;陈伟等[31]利用双重随机过程的隐马尔可夫模型对技术主题的演化趋势进行定量预测。
针对文本分析方法中前沿预测指标的片面性,研究人员尝试利用多维指标识别和预测研究前沿,郑彦宁等[32]采用关键词共现方法,对研究主题的新颖性、集中性和时效性进行分析,规避了词频分析单一性的缺点;张丽华[33]从研究时效性、突破性、跨学科性和继承性等指标入手,对主题演化情况进行了详细的指标量化;Funk R J等[34]从主题强度和主题结构出发,从主题演化角度设计了主题前沿识别与预测指标。然而,现有预测指标体系未考虑主题的演化与迁徙特征,且缺乏定性与定量结合的分析。
1.4 研究述评
综合来看,现有研究在主题挖掘、主题关联与演化、主题前沿预测等领域已取得诸多成果,但仍存在以下问题:
1)现有研究大多对主题的时间跨度进行平均切分,未考虑研究主题的生命周期特性;
2)现有主题关联分析大多采用词频统计、几何距离和余弦夹角的相似度计算方法,未考虑“主题—关键词”的多项式概率分布特征;
3)相对于词频变化的突发性和片面性,研究主题在其生命周期演化过程中具有迁徙的稳定性和规律性,现有主题前沿的预测指标不够全面。
基于此,本文提出基于LDA和LSTM模型的多时序研究主题关联与预测方法,主要贡献在于:
1)从研究主题的生命周期视角切入,将主题时间跨度切分为萌芽期、发展期和快速成长期等多个时序窗口;
2)对不同时序窗口进行LDA主题挖掘与识别,采用JS散度(Jensen-Shannon Divergence)更合理地描述主题间的概率分布相似度和关联关系;
3)考虑主题演化的迁徙特征和时序特征,设计主题热度、新颖度和迁徙度等主题前沿预测指标,利用LSTM神经网络模型对研究主题的发展态势和前沿热点进行预测。进一步,结合基金立项和论文发表的定性分析,对定量预测结果进行修正。
2 研究设计
本文以生命周期理论和时間序列分析为理论基础,归纳研究领域的生命周期特性,挖掘多时序窗口下的研究主题,分析主题研究热度、新颖度和迁徙度等时间序列数据的短期可预测性,以之为基础,设计研究思路与框架。
2.1 理论基础
1)生命周期理论
生命周期理论源于个体发展模型,是指一个生命体从出生到死亡所经历的各个阶段。经延伸和扩展后,生命周期理论被广泛应用于产品管理、行业发展、客户关系管理和信息计量学等诸多领域[35]。马费成等[36]指出某个领域的研究主题也遵循生命周期的一般规律,经历萌芽期、成长期、成熟期、稳定期和衰退期等不同阶段,不同阶段的研究主题存在产生、迁徙、转移、交叉、融合和消亡等不同状态。因此,基于生命周期理论对研究主题的时间跨度进行切分,并对多时序窗口下的研究主题进行挖掘与识别,有助于梳理主题的研究脉络,为学科知识的演化分析提供支撑。
2)时间序列分析理论
时间序列分析理论指出,如果某个时序窗口下的变量与前后时序窗口的变量存在某种关联,则可以根据过往的变量值来预测未来某一时序窗口的变量值[37]。相对于词频变化的突变性和引文关联的波动性,多时序窗口下研究主题的关键词概率分布更加稳定,主题变量与相邻窗口的主题变量的相似度关联更加紧密,具有明显的时序变化特征。因此,LSTM等时间序列预测模型可应用于多时序窗口下的主题关联和预测。
2.2 研究思路与方法
本文研究框架如图1所示,主要包括3个模块:LDA主题挖掘与关联、前沿预测指标设计、LSTM神经网络预测。
2.2.1 LDA主题挖掘与关联
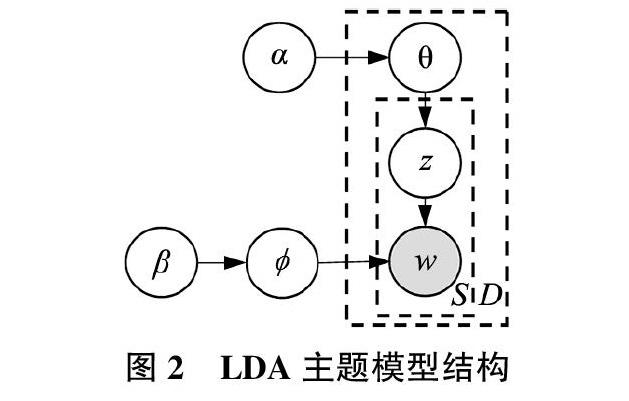
LDA是一种文档主题生成模型,包含词、主题和文档3层结构[38]。LDA主题模型认为文档到主题服从多项式分布,主题到关键词也服从多项式分布。与传统文本分析方法相比,LDA主题模型克服了文本矩阵稀疏、忽略文本语义等缺陷,是分析大规模非结构化文档集的最有效方法之一[39],其基本结构如图2所示。
其中,表示关键词分布,θ表示主题分布,α是主题分布θ的先验分布(即Dirichlet分布)参数,β是关键词分布的先验分布参数,z表示模型生成的主题,w表示模型最终生成的关键词,S表示文档的词语数量,D表示文档数量。LDA主题模型生成过程主要包括以下步骤:
1)从参数为β的Dirichlet分布中为每个主题采样“主题—关键词分布”;
2)从参数为α的Dirichlet分布中为每个文档采样“文档—主题分布θ”;
3)从参数为θ的多项式分布中采样1个主题z;
4)从参数为的多项式分布中采用1个关键词w。
本文基于生命周期理论将研究数据划分为多个时序窗口,利用Python语言下的Sklearn包(https://scikit-learn.org/stable/)进行LDA主题挖掘。进一步,本文采用JS散度(Jensen-Shannon Divergence)描述不同时序窗口下学科主题的相似度和关联关系,JS散度计算如式(1)所示[40]:
相对于词频分析、几何距离和余弦夹角等文本相似度的计算方法,JS散度是一种衡量概率分布相似度的指标,且解决了KL散度非对称的问题,更适用于LDA模型中“主题—关键词”的多项式概率分布特征。
2.2.2 前沿预测指标设计
研究主题前沿是指针对特定研究领域和特定时间,具有较高学术关注度的新颖主题[41]。本文在借鉴相关研究的基础上,结合研究主题演化的迁徙特征和时序特征,设计前沿预测指标,包括主题热度、主题新颖度和主题迁徙度。
1)主题热度:主题热度是指某个时间段该主题的受关注程度,其表现形式可以定义为该主题下文献数量的多少。因此,本文在LDA模型主题挖掘的基础上,定义主题热度的计算公式为:
2)主题新颖度:某个主题下文献第1次的发表年限越近,则表明该主题的新颖度越高。定义主题新颖度计算公式为[42]:
其中,NT(t)为某个时序窗口下主题T的研究新颖度,t为当前时序窗口的上限,Tstart为主题T下文献第1次的发表时间。可以看出,随着主题出现时间的推移,新颖度也不断下降。比如Tstart=2010,当t=2011时,NT(t)=0.5;当t=2015时,NT(t)=0.167;当t=2019时,NT(t)=0.1。
3)主题迁徙度:主题迁徙度是指当前时序窗口下t的某个主题Ti转移至下一个时序窗口t+1下的主题Tj的概率,反映了研究主题的演化趋势和时序特征。本文采用相邻时序窗口主题间的JS散度来描述主体迁徙度。
2.2.3 基于LSTM的主题预测
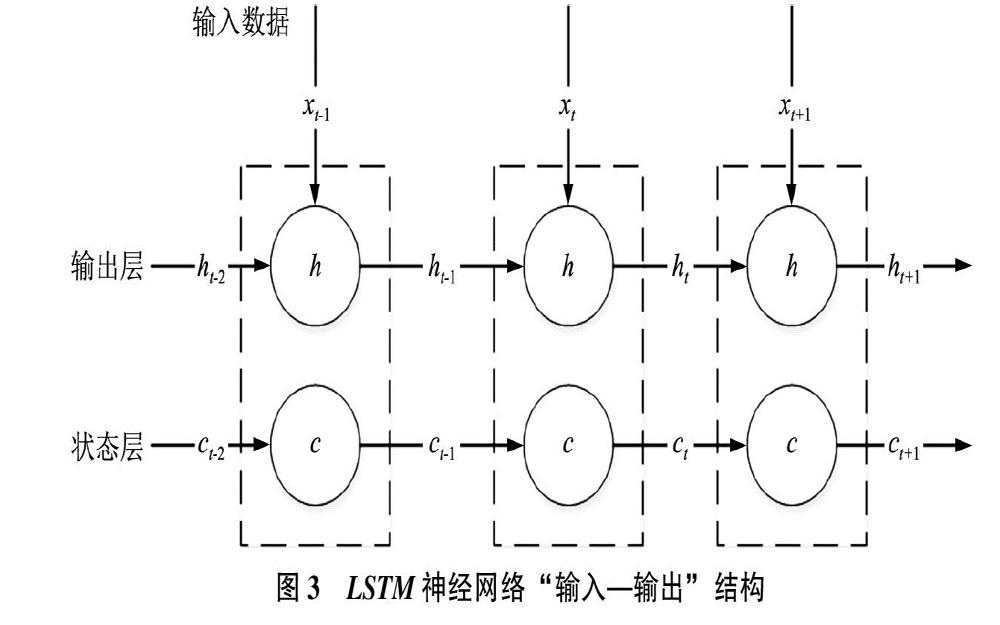
LSTM是一种特殊的循环神经网络(Recurrent Neural Network,RNN),可以解决长序列训练过程中的梯度消失和爆炸问题,目前广泛地应用于时间序列分析、机器翻译和语音识别等领域[43]。相对于RNN的单层结构,LSTM神经网络增加了单元状态层用来保存长期的状态,其输入参数包括:t时刻的输入值xi、t-1时刻的输出值ht-1、t-1时刻的单元状态ct-1,输出参数包括t时刻的输出值ht和单元状态ct,基本结构如图3所示。LSTM神经网络通过遗忘门(Forget Gate)决定t-1的单元状态ct-1有多少保留到t时刻的状态ct,通过输入门(Input Gate)决定t时刻的输入xt有多少保存到单元状态ct,通过输出门决定单元状态ct有多少输出到t时刻的输出值ht[44]。
本文基于前文设计的主题预测指标,采用LSTM神经网络对研究主题的演化趋势及前沿热点进行预测,进一步结合近年基金立项和论文发表情况,对定量预测结果进行定性修正,基本步骤如表1所示。
输入:过去若干个时序窗口下的主题热度、新颖度和迁徙度
输出:未来若干个时序窗口下主题熱度、新颖度和迁徙度的预测值
方法:
1)划分多个时序窗口,设置步长。将输入数据划分为训练集与测试集,并进行规范化处理;
2)将输入参数传递到隐藏层进行门阀计算,结合Sigmoid神经网络产生二维分布0和1以决定信息是否通过;
3)运用tanh函数计算xt、ht-1和ct-1等参数值经过遗忘门后的t时刻单元状态值ct;
4)利用Sigmoid函数得到初始输出,并利用tanh函数进行数据缩放得到预测输出ht;
5)输入测试数据集,验证模型准确性;
6)运用训练后的LSTM模型对未来研究主题的热度、新颖度和迁徙度进行预测;
7)主题预测的定性修正。
3 案例分析
随着大数据及移动通讯技术的发展和成熟,个性化和定制式的泛在信息服务逐渐应用至社交网络、智慧城市和地图导航等多个领域,给用户带来了全新的服务体验。然而,用户在享受高质量便捷服务的同时,大数据环境的开放性和共享性导致各类隐私泄露事件层出不穷,如“棱镜门”事件、“Icloud”云泄露事件、“夜莺计划”等[45]。因此,如何有效地保护个人隐私成为业界和学术界共同关注的问题。从国内外学术文献来看,众多研究学者在隐私保护的法律法规、技术方法、行为模型等领域取得了诸多研究成果。基于此,本文采用第2节提出的研究方法,对隐私研究领域进行主题挖掘,梳理隐私研究主题的演化脉络,分析不同时序窗口主题间的关联关系,并对研究主题的发展趋势和前沿热点进行预测。
3.1 数据来源及预处理
本文使用CNKI中的期刊论文数据库进行文献检索,检索关键词为“隐私”、“个人信息”、“信息泄露”等,检索时间为2019年11月30日,时间跨度为2000-2019年。去除新闻、短评、征稿启事等数据来源后,得到相关文献13 298篇。整体来看,文献数量呈稳步增长态势(2019年数据未统计完全)。
为更好地分析隐私研究主题的演化趋势和路径,本文从时间维度对文献分布进行多时序窗口切分。基于研究主题的生命周期,并结合文献数量增长的趋势线,本文将整个时间跨度分为萌芽发展期和快速成长期,共分为2000-2005年、2006-2007年、2008-2009年、2010-2011年、2012-2013年、2014年、2015年、2016年、2017年、2018年和2019年共11个时序窗口,如图4所示。在此基础上,根据隐私研究主题,结合多个中文停用词表,运用Jieba分词工具每个时序窗口下的文献标题和摘要进行分词,得到“隐私权”、“侵犯”、“立法”、“认证”、“匿名”、“风险”、“披露”、“加密”、“媒体”、“公众”等领域词汇。对分词后的文本向量进行tf-idf特征提取,作为LDA主题模型的输入参数。
3.2 主题挖掘分析
LDA主题模型是一种无监督机器学习算法,可以用来挖掘大规模文档集中隐含的主题信息,其主题挖掘效果与迭代次数(Iteration)密切相关。本文以文献数量最多的2018年区间为例,设置测试主题数分别为10、20、30,当迭代次数增加时,模型迅速收敛,迭代至100次之后,不同主题数的收敛效果均无明显区别。综合考虑运算速度和收敛效果,本文将迭代次数设定为200次。
本文运用LDA模型中的Perplexity(困惑度)参数确定不同区间下文献的最优主题数,如图5所示。进一步,对每个区间的主题进行筛选,如去除文献数量为0的主题、去除由虚词组成的主题聚类、去除与隐私研究无关或相关度较小的主题聚类等。对筛选后的主题进行编号和命名,结果如表2所示。
基于LDA主题挖掘结果,绘制论文主题的数量趋势热度图,如图6所示,可以得出如下结论:
1)根据LDA主题挖掘的结果,可以将不同区间下的论文主题分为5个类别:类别1—隐私权利与隐私法律(隐私权利、隐私法律法规、隐私伦理等)、类别2—隐私技术研究(隐私匿名算法、差分隐私、隐私加密等)、类别3—数据开放与隐私保护(公众隐私、个人信息保护、数据流动与隐私监管等)、类别4—隐私行为(隐私感知与行为、隐私偏好)、类别5—不同应用领域的隐私保护(医疗隐私、图书馆隐私、金融隐私等)。
2)热度图中颜色较深的区域为论文数量较多的研究主题,主要包括隐私法律法规、隐私匿名算法、隐私权利、公众隐私、图书馆隐私、医疗隐私等,论文数量较少的研究主题主要包括隐私感知、隐私偏好、隐私伦理、金融隐私等。
3)早在2000年,最高人民检察院的杨立新对公民隐私权的范围进行了界定,并对其法律保护形式进行了阐述[46]。此后,国外法律制度的借鉴、新兴信息技术的发展以及各类隐私泄露事件都促使了国内隐私法律法规的制定和完善,典型事件包括:①2008年初,“艳照门”事件引发社会各界对个人隐私的关注,呼吁政府部门加强隐私监管和隐私立法;②2013年,工信部颁布《电信和互联网用户个人信息保护规定》,该方案为互联网环境下隐私信息的收集、分析与利用提供了保障;③2014年5月,白宫发布《Big Data and Privacy:A Technological Perspective》白皮书,探讨了大数据环境
下个人隐私泄露的风险及保护机制,为各国大数据隐私法律的制定提供了参考。
4)隐私技术研究大致分为两方面:匿名和访问控制。匿名是指在获取用户隐私信息时,通过匿名的方式,防止将获取的信息与用户身份相关联,以此来达到隐私保护的目的。卡耐基梅隆大学的Sweeney教授于2002年提出K-anonymity隐私匿名算法,该算法对隐私匿名研究具有开创性意义,此后国内关于隐私匿名算法研究的文献一直保持较高热度[47]。
5)在不同应用领域的隐私保护中,医疗隐私和图书馆隐私是国内研究学者关注的焦点,原因主要包括两点:①医疗数据具有高度的私密性和敏感性,如过敏药品、家族病史、影像报告等医疗记录如果泄露,会给患者带来严重的隐私侵害和人身安全问题。因此,众多学者从患者医疗信息使用、电子医疗记录共享(Electronic Medical Record,EMR)、移动医疗APP权限等角度对医疗隐私保护的相关问题展开了研究;②随着数据开放和共享的进一步深入,以及大数据、物联网等新兴技术的飞速发展,图书馆的运营、管理和服务模式也发生了改变。如何有效采集读者阅读行为、身份特征、个人爱好与习惯和社会关系等隐私数据,实现对读者阅读需求和阅读行为准确、详细的跟踪、挖掘、分析和预测,成为图书馆提高服务针对性和市场竞争力的关键[48]。为避免侵害读者隐私,图书馆必须从保障和维护读者权益出发,自觉遵守相关的法律、法规,形成保护读者个人隐私的长效机制。
6)2018年,区块链隐私主题逐渐受到研究学者的关注。区块链是随着比特币等数字加密货币普及而兴起的技术,具有“去中心化”和“不可篡改”等特点,可应用于物联网、社交媒体、电子医疗记录等多个领域的隐私保护[49]。2019年10月,习近平总书记提出区块链技术的集成应用在新的技术革新和产业变革中起着重要作用,应加快推动区块链技术和产业创新发展[50]。可以预见,未来區块链隐私主题的研究热度会显著提升。
3.3 主题演化分析
为了解研究主题间的演化规律和关联关系,本文通过LDA模型挖掘得到的主题及关键词,计算相邻时间窗口下研究主题的JS散度。JS散度值相似度越高,主题间出现迁徙和演化的概率越大。为了使演化路径更加清晰,本文筛选文献数量较少(数量少于20)和相似度较低的研究主题(相似度小于0.3),研究主题的演化路径和关联关系如图7所示,矩形块之间连线的粗细代表主题相似度,连线越粗,相似度越高。具体结论如下:
1)类别1(隐私法律法规)一直是隐私研究主题的重点和热点,主题文献数量较多,不同时间窗口的主题相似度也较高。从关键词分布来看,随着隐私法律法规的修订和完善,主题研究重点从普通公民的隐私权保护演化为如何构建法制社会。与此同时,随着互联网的发展和普及,研究主题从关注网络隐私安全逐渐演化至如何规范、合理的使用个人信息。
2)不同于类别1(隐私法律法规)在研究主题上的延续性,类别2(隐私技术研究)的主题演化存在较强的关联性和迁徙性,比较显著的演化路径包括:
①隐私挖掘(2006-2007)→(0.511)隐私挖掘(2008-2009)→…→(0.304)隐私加密(2019)
②RFID隐私(2006-2007)→(0.667)RFID隐私(2008-2009)→…→(0.652)位置隐私(2017)
③LBS隐私(2010-2011)→(0.34)隐私认证协议(2012-2013)→…→(0.391)隐私匿名(2019)
与此同时,隐私技术是众多应用领域隐私保护的重要手段,与隐私法律法规互为补充。从时间维度上看,随着隐私技术研究的深入,其研究主题逐渐应用至医疗、金融、图书馆服务等具体领域,比较显著的演化路径包括:
①隐私匿名(2010-2011)→(0.468)医疗隐私(2012-2013)→…→(0.468)医疗隐私(2019)
②隐私挖掘(2008-2009)→(0.458)隐私匿名(2010-2011)→…→(0.52)金融隐私(2019)
③隐私挖掘(2008-2009)→(0.371)隐私匿名(2010-2011)→…→(0.36)图书馆隐私(2018)
3)类别4(隐私行为研究)与类别1(隐私法律法规)、类别2(隐私技术)、类别5(具体应用领域的隐私保护)的主题关联性和相似度都较高,原因在于针对不同应用领域的隐私问题,不同类型主体的隐私关注程度和隐私披露意愿具有差异性。然而,宏观层面的隐私法律法规和微观层面的隐私技术无法解决这一问题,因此众多学者运用计划行为理论、期望确认理论、享乐理论等理论模型去研究隐私悖论、隐私忧虑、隐私披露意愿等隐私感知与行为问题。比较显著的演化路径包括:
①无线通信隐私(2012-2013)→(0.565)隐私认证协议(2014)→…→(0.478)隐私匿名(2018)→(0.383)隐私披露与意愿(2019)
②隐私匿名(2010-2011)→(0.426)位置隐私(2012-2013)→…→(0.468)隐私感知与行为(2018)→(0.426)隐私感知与行为(2019)
4)从研究主题扩散和演化的角度分析,隐私匿名研究的衍生路径较多,迁徙概率较大,说明其是隐私研究中的基础和桥梁,如消费者隐私和医疗隐私的主要保护措施就是匿名机制。比较显著的衍生路径包括:
①隐私匿名(2010-2011)→(0.304)医疗隐私(2012-2013)
②隐私匿名(2010-2011)→(0.391)无线通信隐私(2012-2013)
③隐私匿名(2015)→(0.314)图书馆隐私(2016)
④隐私匿名(2018)→(0.383)隐私披露与意愿(2019)
⑤隐私匿名(2018)→(0.391)个人信息保护(2019)
⑥隐私匿名(2018)→(0.347)隐私感知与行为(2019)
3.4 主题预测分析
在主题挖掘和关联分析的基础上,本文选取主题热度、新颖度和迁徙度作为LSTM神经网络模型的预测指标,并定义相对误差(RE,Relative Error)来评估模型预测的准确度:
其中ya为实际数值,yp为模型预测值。本文同时选取BP神经网络和支持向量机进行预测结果对比,以验证LSTM神经网络模型的有效性和优越性。BP神经网络选用三层神经元结构,神经元参数为1-20-1分布,迭代次数为200,支持向量机Gamma参数设置为1,惩罚系数设置为1.5,两种机器学习算法均采用Python语言的Sklearn库实现。LSTM神经网络模型在Keras框架下搭建两层10维神经元和一层Dense输出,迭代次数设置为200。
将前8个时序窗口的数据作为训练数据集,后3个时序窗口的数据作为测试数据集,部分主题的预测评估结果如表3所示。可以看出,相对于BP神经网络和支持向量机的预测模型,LSTM神经网络模型预测的准确度更高,误差更小。
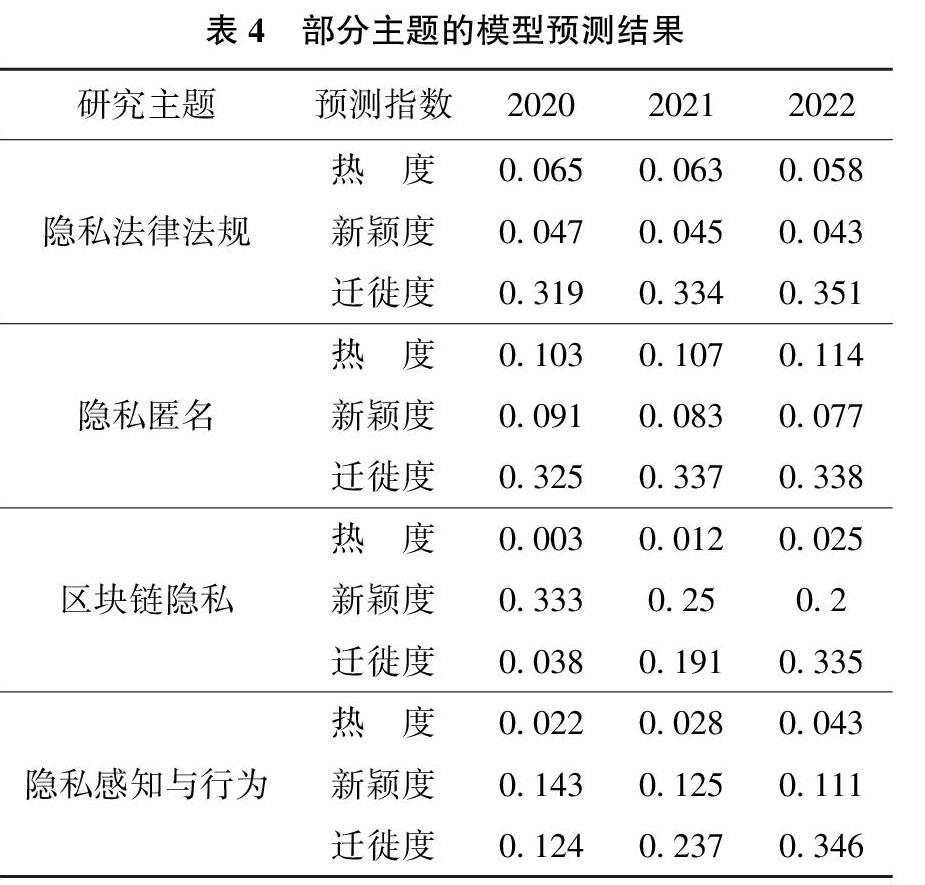
基于此,本文利用LSTM神经网络模型对未来3个时序窗口(2020年、2021年、2022年)下隐私研究主题的演化趋势和前沿热点进行预测,部分主题的预测结果如表4所示,在未来3年,隐私法律法规、隐私匿名、区块链隐私、隐私感知与行业等主题是隐私研究领域的热点。
结合近年来的基金立项和论文发表情况,对模型预测结果进行定性修正,可以得到以下结论:
1)国家自然科学基金中隐私主题的立项主要集中在信息学部和管理学部,信息学部立足于隐私技术研究,主要涉及云计算、车联网、位置服务、社交网络等不同领域的隐私保护技术,管理学部立足于隐私行为和宏观隐私保护研究,主要涉及隐私风险、隐私行为、隐私关注和隐私决策等领域。结合LSTM神经网络模型的预测结果,隐私匿名、位置隐私以及数据关联与隐私挖掘等研究主题会保持热度,文献数量稳步增长。
2)国家社会科学基金中隐私主题的立项范围涵盖较广,涵盖了隐私行为、隐私法律和不同应用领域的隐私保护,不同于国家自然科学基金偏重微观研究,集中于隱私技术和隐私行为研究,国家社会科学基金偏重于宏观政策和机制研究。基于此,隐私感知和隐私行为、隐私法律法规以及个人信息保护等主题的文献数量也会保持稳步增长。
3)考虑到国外研究对国内研究主题的借鉴性和启发性,本文对近3年UTD 24期刊中隐私主题的论文进行归纳,未来隐私研究的前沿热点包括区块链隐私(Block Chain Privacy )隐私关注(Privacy Concern)、隐私计算(Privacy Calculation)、隐私悖论(Privacy Paradox)及隐私态度(Privacy Attitude)等主题,即隐私行为研究主题的文献数量会显著增长。
4 结 语
本文在生命周期理论和时间序列分析理论的基础上,提出基于LDA和LSTM模型的主题关联与预测方法,可以用来梳理具体领域的研究脉络和主题关联,预测研究主题的发展趋势和前沿热点。创新之处主要有两点:一是基于生命周期理论,合理划分多时序窗口,并用JS散度描述主题间的关联关系;二是基于主题预测指标的时间序列特征,利用LSTM模型进行主题预测。最后以隐私研究领域为例,选取2000-2019年间共13 298篇学术论文作为数据源进行了实证研究,证明了本文方法的准确性和有效性。未来的研究可以进一步改进LDA主题挖掘的准确性,综合宏观文献引用维度和微观主题演化维度进行关联分析。
参考文献
[1]刘自强,许海云,岳丽欣.面向研究前沿预测的主题扩散演化滞后效应研究[J].情报学报,2018,37(10):979-988.
[2]李樵.外部引用视角下的中国图书情报学知识影响力研究[J].中国图书馆学报,2019,45(6):1-19.
[3]李纲,巴志超.共词分析过程中的若干问题研究[J].中国图书馆学报,2017,43(4):93-113.
[4]Lu Y,Xiong X.Topic Analysis of Microblog About“Didi Taxi”Based on K-means Algorithm[J].American Journal of Information Science and Technology,2019,3(3):72-79.
[5]廖海涵,王曰芬,关鹏.微博舆情传播周期中不同传播者的主题挖掘与观点识别[J].图书情报工作,2018,62(19):77-85.
[6]谭章禄,彭胜男,王兆刚.基于聚类分析的国内文本挖掘热点与趋势研究[J].情报学报,2019,38(6):578-585.
[7]曲靖野,陈震,郑彦宁.基于主题模型的科技报告文档聚类方法研究[J].图书情报工作,2018,62(4):113-120.
[8]杨颖,许丹,陈斯斯,等.基于自然指数刊文数据对全球医学研究领域热点的探析[J].情报学报,2019,38(11):1129-1137.
[9]张颖怡,章成志,陈果.基于关键词的学术文本聚类集成研究[J].情报学报,2019,38(8):860-871.
[10]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,(3):993-1022.
[11]曾子明,王婧.基于LDA和随机森林的微博谣言识别研究——以2016年雾霾谣言为例[J].情报学报,2019,38(1):89-96.
[12]吴江,侯绍新,靳萌萌,等.基于LDA模型特征选择的在线医疗社区文本分类及用户聚类研究[J].情报学报,2017,36(11):1183-1191.
[13]Kim Y,Shim K.TWILITE:A Recommendation System for Twitter Using a Probabilistic Model Based on Latent Dirichlet Allocation[J].Information Systems,2014,42:59-77.
[14]Song B,Suh Y.Identifying Convergence Fields and Technologies for Industrial Safety:LDA-based Network Analysis[J].Technological Forecasting and Social Change,2019,138:115-126.
[15]赵蓉英,张心源,张扬,等.我国“五计学”演化过程及其进展研究[J].图书情报工作,2018,62(13):127-138.
[16]张娴,方曙.专利引用网络主路径方法研究述评与展望[J].图书情报工作,2016,60(20):140-148.
[17]Ibrahim R,Elbagoury A,Kamel M S,et al.Tools and Approaches for Topic Detection from Twitter Streams:Survey[J].Knowledge and Information Systems,2018,54(3):511-539.
[18]Li Q,Liu L,Xu M,et al.GDTM:A Gaussian Dynamic Topic Model for Forwarding Prediction Under Complex Mechanisms[J].IEEE Transactions on Computational Social Systems,2019,6(2):338-349.
[19]关鹏,王曰芬,傅柱.基于LDA的主题语义演化分析方法研究——以锂离子电池领域为例[J].数据分析与知识发现,2019,3(7):61-72
[20]夏立新,曾杰妍,畢崇武,等.基于LDA主题模型的用户兴趣层级演化研究[J].数据分析与知识发现,2019,3(7):1-13.
[21]刘雅姝,张海涛,徐海玲,等.多维特征融合的网络舆情突发事件演化话题图谱研究[J].情报学报,2019,38(8):798-806.
[22]Garroppo R G,Ahmed M,Niccolini S,et al.A Vocabulary for Growth:Topic Modeling of Content Popularity Evolution[J].IEEE Transactions on Multimedia,2018,20(10):2683-2692.
[23]Price D J D S.Networks of Scientific Papers[J].Science,1965,149(3683):510-515.
[24]范云满,马建霞.基于LDA 与新兴主题特征分析的新兴主题探测研究[J].情报学报,2014,33(7):698-711.
[25]Kessler M M.Bibliographic Coupling Between Scientific Papers[J].Journal of the American Society for Information Science & Technology,1963,14(1):10-25.
[26]Morris S A,Yen G Wu Z,et al.Time Line Visualization of Research Fronts[J].Journal of the Association for Information Science & Technology,2003,54(5):413-422.
[27]侯剑华,李莲姬,杨秀财.基于引文网络结构变换的大数据研究前沿预测[J].情报科学,2018,36(6):142-148,168.
[28]He X,Wu Y,Yu D,et al.Exploring the Ordered Weighted Averaging Operator Knowledge Domain:A Bibliometric Analysis[J].International Journal of Intelligent Systems,2017,32(11):1151-1166.
[29]张英杰,冷伏海.基于案例的科学前沿探测方法比较研究[J].图书情报工作,2012,56(20):42-46.
[30]刘自强,王效岳,白如江.基于时间序列模型的研究热点分析预测方法研究[J].情报理论与实践,2016,39(5):27-33.
[31]陈伟,林超然,李金秋,等.基于LDA-HMM的专利技术主题演化趋势分析——以船用柴油机技术为例[J].情报学报,2018,37(7):732-741.
[32]郑彦宁,许晓阳,刘志辉.基于关键词共现的研究前沿识别方法研究[J].图书情报工作,2016,60(4):85-92.
[33]张丽华.研究前沿探测及其演化分析方法与实证研究[D].北京:中国科学院大学,2015.
[34]Funk R J,Owen-Smith J.A Dynamic Network Measure of Technologic Change[J].Management Science,2017,63(3):791-817.
[35]Santos A C,Mendes P,Teixeira M R.Social Life Cycle Analysis as a Tool for Sustainable Management of Illegal Waste Dumping in Municipal Services[J].Journal of Cleaner Production,2019,210:1141-1149.
[36]马费成,夏永红.网络信息的生命周期实证研究[J].情报理论与实践,2009,32(6):1-7.
[37]Feyrer J.Trade and Income—Exploiting Time Series in Geography[J].American Economic Journal:Applied Economics,2019,11(4):1-35.
[38]Blei D M,Jordan M I,Griffiths T L.The Nested Chinese Restaurant Process and Bayesian Nonparametric inference of Topic Hierarchies[J].Advances in Neural Information Processing Systems,2010,57(2):17-24.
[39]Tazibt A A,Aoughlis F.Latent Dirichlet Allocation-based Temporal Summarization[J].International Journal of Web Information Systems,2019,15(1):83-102.
[40]Bai L,Hancock E R.Graph Kernels from the Jensen-Shannon Divergence[J].Journal of Mathematical Imaging and Vision,2013,47(1-2):60-69.
[41]牌艳欣,李长玲,刘运梅.基于z指数的AAS高关注度学科研究主题识别[J].情报资料工作,2019,40(6):30-37
[42]范云满,马建霞.基于LDA与新兴主题特征分析的新兴主题探测研究[J].情报学报,2014,33(7):698-711.
[43]Graves A,Schmidhuber J.Framewise Phoneme Classification with Bidirectional LSTM and other Neural Network Architectures[J].Neural networks,2005,18(5-6):602-610.
[44]Greff K,Srivastava R K,Koutník J,et al.LSTM:A Search Space Odyssey[J].IEEE Transactions on Neural Networks and Learning Systems,2016,28(10):2222-2232.
[45]朱光,丰米宁,陈叶,等.大数据环境下社交网络隐私风险的模糊评估研究[J].情报科学,2016,34(9):94-98.
[46]杨立新.关于隐私权及其法律保护的几个问题[J].人民检察,2000,(1):26-28.
[47]Sweeney L.K-anonymity:A Model for Protecting Privacy[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):557-570.
[48]白美程,阳广元.近五年我国数字图书馆用户隐私保护研究进展[J].图书馆理论与实践,2019,(8):79-84.
[49]艾瓊,刘纯璐,游林.科研用户访问国外学术数据库的隐私保护与对策[J].图书情报工作,2019,63(10):12-20.
[50]光明网.区块链创新中国价值链 创新技术发展广泛惠及民生[EB/OL].http://politics.gmw.cn/2019-12/26/content_33430734.htm,2019-12-21.
(责任编辑:陈 媛)
