基于多重图的社交网络用户可信度评价方法研究
2020-08-19沈旺代旺高雪倩
沈旺 代旺 高雪倩

摘 要:[目的/意义]提出基于多重图的社交网络用户可信度评价方法,为网络信息生态治理提供有效依据,为有害次生舆情管理提供理论基础。[方法/过程]构建了网络欺凌和隐私泄露特征抽取指标体系;利用多重图表示社交网络用户动态信息网络;根据提取到的网络欺凌和隐私泄露信息进行用户信息行为分析;利用德尔菲法确定网络欺凌行为与隐私泄露行为概率的权重,综合分析社交网络用户可信度。[结果/结论]实验结果表明,基于多重图的用户可信度评价结果与基于调查问卷的用户可信度评价结果基本一致,说明利用多重图的社交网络用户可信度评价方法具有一定的可行性。
关键词:社交网络;多重图;网络欺凌;隐私泄露;用户可信度
Abstract:[Purpose/Significance]A credibility evaluation method for social network users based on multigraph was proposed,aiming to provide an effective method for ecological governance of network information and a theoretical basis for the management of network secondary public opinion with negative effects.[Method/Process]The paper constructed the index system of feature extraction of cyberbullying and privacy disclosure,and the dynamic information network of social network users was expressed by using multigraph.The extracted information of cyberbullying and privacy disclosure was used to evaluate information behavior of network users.The probability weight of cyberbullying and privacy disclosure was determined by Delphi method,and the credibility of social network users was comprehensively analyzed.[Result/Conclusion] The experimental results showed that the result of the users credibility evaluation based on multigraph was basically the same as the result obtained by the questionnaire,indicating that it is feasible to use multigraph to evaluate the credibility of social network users.
Key words:social network;multigraph;cyberbullying;privacy disclosure;credibility of users
随着移动互聯网的发展,微博和知乎等社交网络平台已成为我国大多数人获取信息和发表言论的重要平台,成为网络舆论及意识形态争论的高地。目前,由某热点事件衍生次生舆情的情况十分常见,此类舆情往往会产生“倒逼”性的压力,致使当事主体难以应对[1]。
从狭义上来讲,所谓次生舆情是当原生的舆情为负面事件,亦或是可能引起负面次生舆情时所产生的关联舆情情况[2-3]。网络负面舆情常常会衍生出包含网络欺凌和隐私泄露的次生舆情,如在新冠肺炎疫情期间,部分社交媒体用户对作出其不认同行为或发布其不认同信息的用户进行谩骂甚至泄露其他用户的隐私。根据于2020年3月1日开始施行的《网络信息内容生态治理规定》,网络用户不得利用网络和相关信息技术实施侮辱、诽谤、威胁、散布谣言及侵犯他人隐私等违法行为[4]。因此,本文拟利用多重图表示网络动态时用户发送的信息,从网络欺凌和隐私泄露两个视角出发,对社交网络用户进行可信度评价,以便为网络信息内容生态治理提供依据,同时给有关网络欺凌和隐私泄露的网络次生舆情管控提供理论基础。
1 相关概念及理论基础
1.1 多重图理论
在经典图论中,一个有序的二元组(V,E)称为一个图,记为G=(V,E),其中V称为G的顶点集,V≠,其元素称为顶点或者节点,一般记为V={v1,v2,…,vm};E称为图G的边集,一般可记为E={e1,e2,…,en},其元素称为边,它连接V中的两个顶点,如果这两点是无序的,则称改边为无向边,相应的G称为无向图;否则称为有向边,相应的G称为有向图。在图G=(V,E)中,如果允许有多重边,也就是有至少2个边的2个顶点完全相同,至少有2个顶点可以由2个边相连接,则称G为多重图,拥有共同顶点的边称为平行边。
毛明松等[5]学者利用有向多重图表示多元异构信息环境中用户的网络关系,针对推荐系统中用户社会网络多样化的特征提出了多重图排序方法;王娜娜等[6]学者运用可拓学中的基元理论构建了一种基于物元特征的异质边多重图网络模型,用于实现物流节点之间的异质边的统一度量;任亮等[7]学者用多重图的节点表示物流运输中的站点,边表示物流路径,边的序列号表示运输中所需要的时间和费用,利用多重图原理对物流运输路径选择进行优化处理。
Chikhaoui B等[8]学者使用时间加权多重图表示社会网络的动态,分析了社区之间随时间的影响关系;Sarna G等[9]学者利用多重图表示了社交网络用户间的信息往来,并在此基础上提出了一种评价社交网络用户可信度的方法;Gjoka M等[10]学者构建了多重图随机游走模型用来探索并表示社交网络用户潜在的好友关系、群组关系和时间关系。
从国内外学者的研究中可以看出,不论是多元异构信息环境中用户的网络关系还是现实的物流网络关系和社会网络关系都能够用多重图很好地表示,多重图的节点通常用于表示社会网络或者信息网络中的实体,多重图的边通常用于表示实体间的关系。本文利用多重图来表示社交网络用户的动态信息网络。在一个用户信息网络中,多重图中节点表示社交网络用户,每条边各表示一次社交网络用户信息过程,边的起点连接的是信息发送者,边的终点连接的是信息的接受者,边的权重由信息内容,信息发送时间,信息种类表示。
1.2 用户可信度研究
可信度研究最初于20世纪50年代在大众传播研究领域展开。用户信息传播行为本身总是由3个实体组成:发送者(传播者)、消息和接收者。目前,学者们尚未对可信度概念和测量达成一致意见,对社交网络信息可信度的研究主要从4个方面进行:1)从信源可信度出发,根据用户特征信息、用户专业背景及用户历史信息进行用户可信度评价[11];2)从信息传播媒介出发,根据信息的转发率、评论数来考虑信息在传播过程中对其可信度的影响[12];3)从信息内容出发,对信息文本长度、标签和情感词等文本特征对信息进行可信度评价[13];4)综合信源、信息内容和媒介3个因素对信息可信度进行评价[14]。
前人对信息可信度的研究不论是从信源、信息传播媒介还是信息内容出发,都是主要关注信息的真实性、准确性,即信息越真实、准确其可信度就越高。本文对信息可信度的研究不再局限于信息的真实性和准确性,而是将信息的合法性作为判断信息是否可信的标准,认为信息内容不符合法律规定或者用户对信息的不合法使用那么该信息就是不可信的。根据2020年3月1日开始施行《网络信息内容生态治理规定》,网络用户不得利用网络和相关信息技术实施侮辱、诽谤、威胁、散布谣言及侵犯他人隐私等违法行为[4]。因此本文从信息内容出发,对于信息内容合法性的判断依据于该信息是否属于网络欺凌信息和隐私泄露信息,从而分析用户的网络欺凌与隐私泄露行为,并综合评价社交网络用户的可信度。
1.3 网络欺凌
网络欺凌是指利用数字技术进行的欺凌行为,即通过社交媒体、即时通讯平台、游戏平台和手机等,以恐吓、激怒或羞辱他人为目的的重复行为[15]。网络欺凌所涉及的形式包括通过数字平台,如社交网站、聊天室、博客、即时消息应用程序和短信,以文本、图片或视频等形式发布电子信息,意图对他人进行骚扰、威胁、排挤或散布关于他人的谣言。有时这些行为是以匿名的形式实施的[16]。
网络欺凌是随着信息技术发展而产生的一种新型的欺凌形式,网络欺凌有着与传统欺凌相同的特征与要素,但也有其独特的特点。网络欺凌颠覆了传统欺凌的“权力原则”,只要欺凌者可以使用网络发表言论,他们就能欺凌网络世界中的弱者。与传统的欺凌相比,网络欺凌的危害程度更大,监控难度也更大[17],网络欺凌的影响更广,不仅受网络欺凌者会出现抑郁、自杀倾向等情绪与行为问题[18],而且实施网络欺凌者也会出现人格缺陷、缺乏道德感及攻击行为等心理问题[19]。
1.4 隐私泄露
个体隐私的研究起源于法学领域学者Warren和Brands,他们在1890对隐私权进行了解释。1967年,Westin进一步指出,個人隐私是“一个人独处的权利”,也是“人类对于表达自我时机、程度的选择权”。随着社会的进步与网络的发展,越来越多人关注个人隐私,而且隐私也慢慢地被认为是一种商品,具有商品的属性,它是一种服从成本效益分析和经济原则的个人财产,而这一观点也被随后的学者用来解释个体自愿在社会化媒体平台上提供信息的现象:消费者将个人隐私看作是商品,以此换取可以感知的利益[20]。
隐私不是一个静态和唯一确定的概念,它会随时间的推移和行业领域的不同而不断发生变化,因社会、经济、政治、文化等宏观环境的不同而不同[21]。而且,有研究显示,对于相同的隐私状况,不同用户的隐私关注程度也并不一定相同,用户隐私关注程度越高,则会觉得自身的隐私安全水平越低[22]。而用户对隐私安全的感知水平又会直接影响用户的网络行为。
隐私保护的核心在于与环境、他人和个人信息的交互。只要没有与他人互动或个人没有共享任何信息,信息的隐私权就不成问题。一旦人们变得活跃起来,他们就开始披露自己甚至他人的信息。此外有研究表明,在一些情景下,人们可能更倾向于披露一些个人信息并以此为代价来获得某种收益[23]。因此,社交网络用户在与他人互动和共享信息的过程中常常会造成自身和他人隐私的泄露,本文拟利用多重图表示社交网络用户的动态信息网络,获取社交网络用户的互动过程。
2 基于多重图的社交网络用户可信度评价方法
本文对社交网络用户的可信度评价框架参见图1,具体步骤如下:1)利用网络爬虫工具抓取新浪微博中的用户所发送的信息并进行预处理;2)从网络欺凌与隐私泄露视角出发,构建特征抽取指标体系,根据建立的特征抽取指标体系对处理后的数据进行特征抽取;3)将信息分为欺凌信息、非欺凌信息、隐私泄露信息和非隐私泄露信息;4)多重图表示用户动态信息网络,根据用户发送信息的类型和数量对用户进行行为分析;5)根据德尔菲法确定的网络欺凌与隐私泄露的权重,在用户行为分析的基础上进行用户可信度分析。
2.1 特征抽取与信息分类
2.1.1 网络欺凌特征抽取指标
福柯曾尖锐地指出,话语并不是被动反映一种“预先存在的现实”,而是一种“我们对事物施加的暴力”[24]。言语的暴力是网络欺凌的主要表现形式,因此对网络欺凌特征的抽取主要从言语方面入手。
1)本文选取了《现代汉语词典》中以詈言分类的词语和被标注为“骂人的话”“也用做骂人用的话”“多用于骂人或开玩笑”“多用于骂人”“用于骂人或开玩笑”“骂人或诙谐的话”“讥讽人……的”“含有讽意”“含轻蔑意”“对……的憎称”的词语,以及在《现代汉语词典》中一部分不在以上分类中但日常生活中常被用作骂人以及讽刺的词语,将上述词语作为网络欺凌特征抽取的关键词。上述词语在后文中,统称为詈言类词语。
2)有些信息虽然没有出现上述分类的词语,但是带着强烈的负面情绪,能够给信息接受者造成心理负担和实质性的伤害,因此本文选取了《现代汉语词典》中表示负面情绪的词语用于检测欺凌信息。
3)在检测欺凌信息时,表示积极情绪的词语也会对检测造成影响。例如:“我很高兴见到你这个蠢货”一句。虽然这句话中包含了詈言类词语“蠢货”,但是由于“蠢货”之前的修饰词语有“很高兴”,因此,这句话的整体基调定位为高兴,而“蠢货”一词在此句中是调侃的意思,并非欺凌。因此我们添加积极情绪词这一因素来检测非欺凌信息,通过这种方式,我们将非欺凌行为信息与获得的总信息隔离开。在此之后,根据詈言类词语与负面情绪将其余信息分为欺凌信息。
综上所述,本文根据詈言类词语,负面情绪词语和积极情绪词语建立了用于抽取网络欺凌特征的词库,详细情况如表1所示,受篇幅限制,只选取部分关键词展示。
2.1.2 隐私泄露特征抽取指标
对于隐私泄露的特征抽取,本文主要从4个方面进行,分别是信息隐私、通信隐私、空间隐私和社会隐私。
1)信息隐私。本文将姓名、性别、年龄、民族、身体状态(身高、体重、疾病等)、财政状况归为用户的信息隐私。由于社交网络上用户对公众人物的关注度较高,公众人物的姓名出现频率较高,本文不将姓名作为隐私关键词。表示性别的词语包括:男、女、变性人、人妖,我们将这些表示性别的词语作为隐私关键词。此外,我们将我国56个民族作为隐私关键词来检测隐私泄露情况。对于身体状态,本文主要将个人疾病作为隐私关键词,我们收集了常见的疾病作为信息隐私抽取的关键词。对于财政状况,本文选取了《现代汉语词典》中用于表示财政状况的词语以及日常生活中人们常用来表示财政状况的词语作为特征抽取关键词。
2)通信隐私。通信隐私主要包括微信号码、QQ号码、电话号码、邮箱和一些个人社交媒体账号。
3)空间隐私。空间隐私包括个人行程、个人户籍地、居住地、单位所在地等。不论是个人行程、户籍地址、居住地还是单位所在地等都与城市名称有着直接的联系,因此本文将城市名称作为空间隐私关键词。此外,个人行程与火车站飞机站名称会联系在一起,由于火车站名称常常会包含城市名,本文选取所有国内机场名称和一些常见国外机场名称作为隐私关键词。
4)社会隐私。社会隐私包括个人的教育背景、工作经历和恋爱婚姻状况。对于个人教育背景,由于小学、中学数量过多且名称常与城市相关,本文选取国内大学和国外知名大学名称作为隐私关键词;对于工作经历,由于工作单位包含的词语千变万化,本文将常见的职位名称和职业名称作为个人工作经历的隐私关键词;对于恋爱和婚姻状况的检测,本文选取了《现代汉语词典》和日常生活中用于描述个人恋爱和婚姻状况词语作为隐私关键词。
根据上述4种隐私分类,建立的隐私披露特征抽取词库如表2所示。
2.1.3 信息分类
从社交网络上采集的信息是没有进行标记的。我们将信息分为4类:欺凌信息、非欺凌信息、隐私泄露信息和非隐私泄露信息。根据上述所建立的特征抽取指标,利用Excel提取关键词来进行网络欺凌和隐私泄露的特征抽取,并对抽取后的信息按照如下分类机制进行分类。
1)欺凌信息与非欺凌信息的分类机制如图2所示:
积极情绪是用于区分出那些含有詈言类词语却又非网络欺凌的信息,有些网络用户会因为自身习惯使用一些脏话来表达自身情绪,因此如果信息中含有詈言类词语却又带着积极情绪,往往不能判断为欺凌信息。我们首先利用积极情绪来筛选出原始数据集中一部分的非欺凌信息,对除去这一部分非欺凌信息数据集再利用消极情绪和詈言类词语来筛选出欺凌信息。
詈言类词语的主要用途是对除去利用积极情绪筛选出的部分非欺凌信息的数据集中包含詈言类词语的信息进行检测。对于筛选出来的包含詈言类词语的信息则有更大的可能成为欺凌信息,然后根据信息中是否詈言类词语来判断该信息是否属于欺凌信息。
消极情绪是强烈的显示欺凌行为的指标。对于消极情绪而言,一条信息中若只包含少量消極情绪词语有很大可能是该用户表达自身的情感,往往不能判定为欺凌信息。对于信息中既包含消极情绪和詈言类词语的信息我们认定为欺凌信息;对于一条信息中包含较多消极情绪的词语,往往能给信息接受者带来心理压力甚至伤害,因此我们将包含超过3个消极情绪词的信息认定为欺凌信息。
2)隐私泄露信息与非隐私泄露信息分类机制如图3所示:
信息隐私词、空间隐私词、通信隐私词和社会隐私词用于在大数据集中筛选出包含上述四类隐私关键词的信息。然后根据信息中包含关键词的种类和数量来判断一条信息是否属于隐私泄露信息。包含一类以上隐私关键词的信息将会被判定为隐私泄露信息,对于只包含一类隐私信息,若一条信息中,隐私关键词的数量不小于2,则该信息为隐私泄露信息。
2.2 用户行为分析(BAU)
本文利用多重图建立节点之间的平行边来表示用户信息动态网络。多重图中的节点表示网络信息的发送者和接收者,如果消息从发送者传递到接受者,则边缘存在。同时,序列号被分配给边缘,边缘指示信息的顺序,边缘的权重由信息发送的时间、信息的内容和信息的种类表示。这样的一个动态的信息过程,可以清楚地表示每个单位时间社交网络用户发送的消息数量、信息内容和信息的种类,这有助于观察用户的信息行为。
实例1:某非常有害用户
表3表示的是利用多重图表示的某用户动态信息网络。该多重图包含信息发送者,信息接收者以及信息内容与信息属性。根据表3,该用户共发送了6条信息。其中欺凌信息4条,且都为包含詈言类词语的欺凌信息;隐私泄露信息2条,这两条信息都涉及了其他用户的信息隐私和空间隐私泄露。
因此,BM=4,NBM=2,PM=2,NPM=4
根据前文的计算公式(式2、4、5)可得,
P(BM)=0.667
P(PM)=0.333
P(CAU)=0.467
根据前文的用户可信度评价规则,该用户P(BM)=0.667>0.6,因此该用户属于网络欺凌的非常有害用户。P(PM)=0.333<0.4,该用户属于隐私泄露有害用户。综合隐私泄露与网络欺凌两方面,该用户的P(CAU)=0.467<0.48,因此该用户属于非常有害用户。
实例2:某可信用户
根据表4,该用户共发送5条信息,其中欺凌信息一条,这条信息属于包含消极情绪词的欺凌信息。此外,值得注意的是,该用户所发送的一条信息中包含了詈言类词语,但带有积极情绪,因此被判定为非欺凌信息。因此,BM=1,NMB=4,PM=0,NPM=5。根据前文的计算公式可得:
P(BM)=0.2
P(PM)=0
P(CAU)=0.88
根据用户可信度计算规则,P(BM)=0.2,0.2是评价网络欺凌有害用户的临界值,因此该用户属于网络欺凌有害用户,但是有可能朝可信用户发展。P(PM)=0<0.1,该用户被评为隐私泄露可信用户。综合网络欺凌与隐私泄露两方面,P(CAU)=0.88>0.84,该用户被评为可信用户。
3.3 评价结果分析
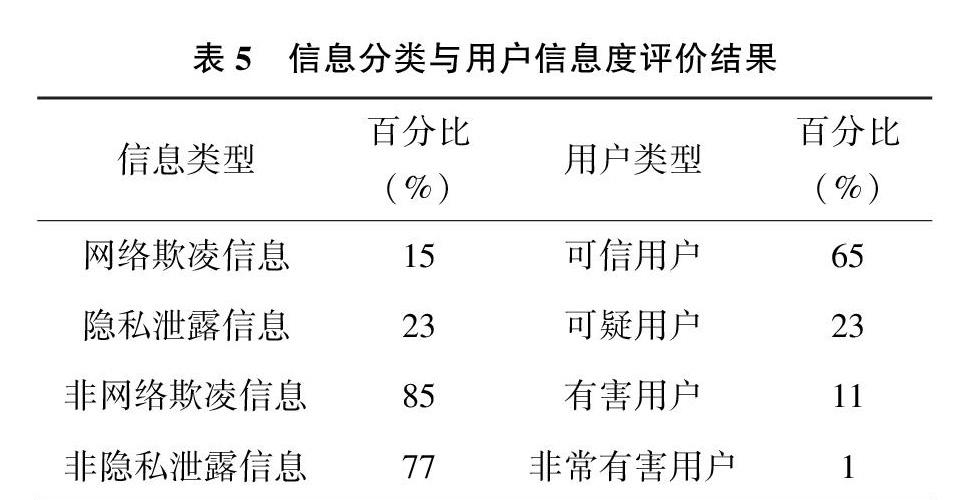
通过对采集到的超10 000条信息进行特征抽取与分类和对超2 000的微博用户的进行信息行为分析和可信度分析后,研究结果如表5所示:
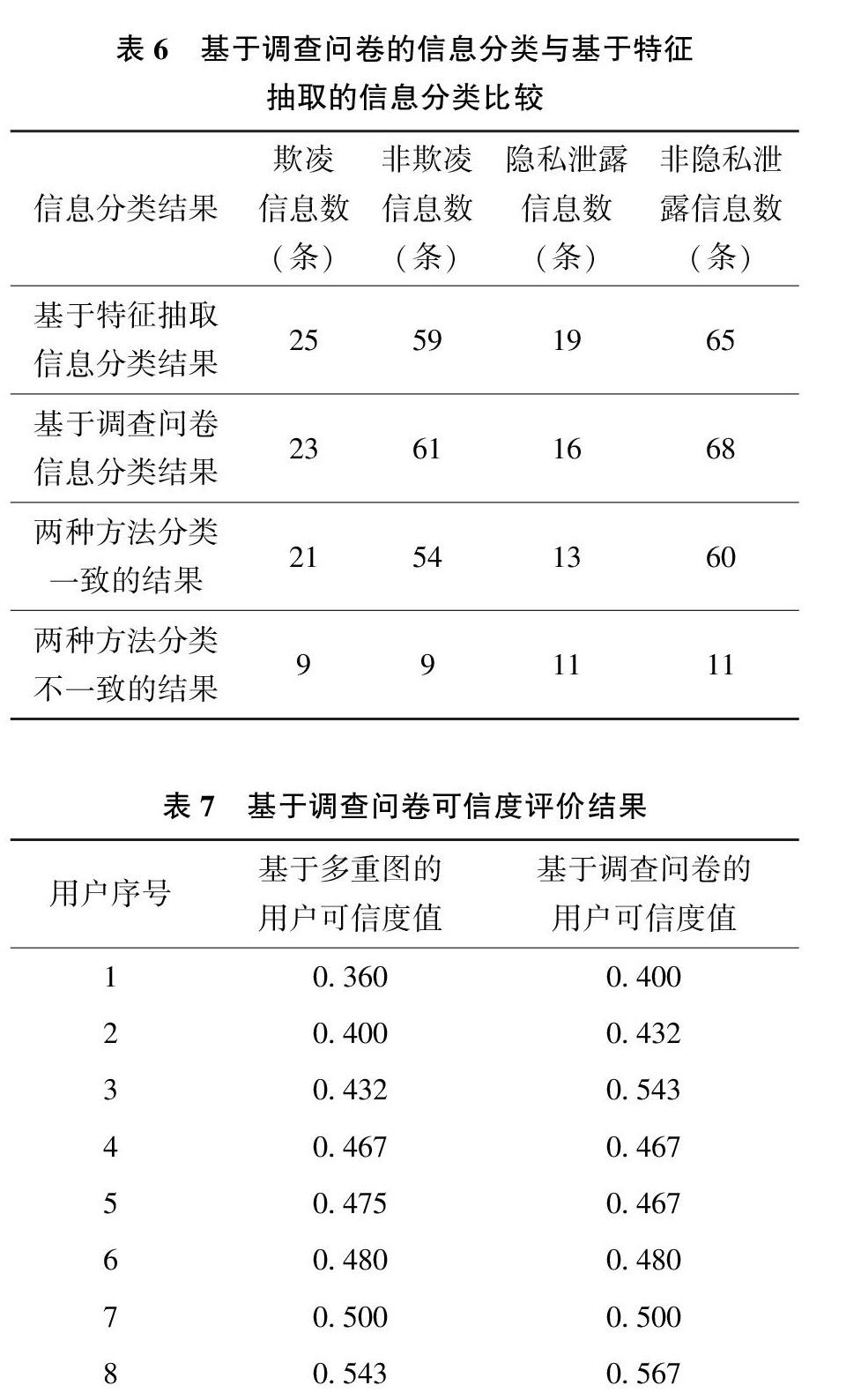
本文对用户可信度的判断主要依赖于对信息的分类,而判断一条信息是否属于网络欺凌信息与隐私泄露信息,是用户根据接收到该信息时的主观感受(例如,信息接受者收一条信息时,虽然该信息包含一些负面情绪词或者詈言类词语,但该信息并不能带给用户心理上的压力或者实质性的伤害,那么用户可能认为该信息并非欺凌信息)。为了验证本次实验结果的有效性,本文根据用户可信度评分对用户进行了排序,在4类用户中各随机选取5名用户的信息網络多重图用于实例分析。根据选择的20名用户的信息网络多重图,本文提取了这20份多重图中共84条信息,用于发放问卷。本文选择了50位调查者来对每条信息进行判断,去除其中无效问卷7份,最终采集问卷43份,管中窥豹,希望能够获得用户对每条信息类型的主观判断。调查者的年龄范围在18~35岁,涉及15个专业和行业,学历为高中、本科、硕士。调查者需要详细阅读每条信息,并根据自身感受来判断该信息是否属于网络欺凌信息与隐私泄露信息。根据问卷调查结果,我们对每条信息类型进行统计,如果一条信息50%以上的人认为该信息属于欺凌信息,说明该信息能够大多数人带来心理压力或者伤害,因此该信息将被判定为欺凌信息,对于隐私泄露信息的判断亦是如此。经过统计整理后,信息分类结果如表6所示。根据调查结果,并结合前文所建立的用户可信度计算式(2)、式(4)、式(5)计算每个用户的可信度值,计算结果见表7。
通过对基于调查问卷与基于特征抽取的信息分类比较,可以发现两种方法对于欺凌信息分类的一致率达到了89.29%,对于隐私泄露信息分类的一致率达到了86.90%。由此可见基于特征抽取的信息分类方法是具有一定可行性,利用詈言类词语、消极情绪词和涉及隐私的词语有助于发现网络欺凌信息和隐私泄露信息。通过对基于调查问卷与基于多重图的用户可信度评价值的比较,20位用户中有9位用户通过两种不同方法得到的可信度值是相同的。20名用户中通过两种不同方法得到可信度差别较大的有4位,这4位用户通过两种不同的方法被分为不同的用户类型,其余16位用户中,可信度值一致性较高,而且通过两种不同的方法被分为的用户类型一致,两种方法对于用户类型划分的一致率达到了80%。由此可见,基于多重图的用户可信度评价方法具有一定的可行性。
4 结论与展望
本文提出了一种基于多重图获取社交网络用户动态信息网络,计算用户可信度的方法。首先,本文从网络欺凌与隐私泄露视角出发,构建了网络欺凌与隐私泄露特征抽取指标体系,然后利用多重图表示用户动态信息网络;通过网络欺凌和隐私泄露信息数量进行用户信息行为分析;根据德尔菲法,确定网络欺凌行为与隐私泄露行为的权重,根据网络欺凌行为概率和隐私泄露行为概率对用户可信度进行评价。实验结果表明,基于多重图的用户可信度评价方法是可行的;在提取网络欺凌与隐私泄露特征中,詈言类词语和消极情绪词语有助于发现网络欺凌信息,涉及隐私的词语有助于发现隐私泄露信息。同时本文具有一定的局限,在特征抽取指标体系的构建中,词库中表示网络欺凌和情绪以及涉及隐私的关键词并未完全收录;对于隐私泄露信息,并未对用户自身信息披露和他人信息披露进行严格区分。在后续的研究中,笔者会对网络欺凌与隐私泄露词库进行扩充,将隐私泄露信息进行进一步的区分;并希望能够利用马尔科夫链等数学模型,根据用户以前的信息预测用户的行为。
参考文献
[1]冯丙奇.次生舆情是如何生成的[J].人民论坛,2019,(11):112-113.
[2]宋凯,刘叶子.新媒体环境下国有企业舆情生态系统研究[J].现代传播(中国传媒大学学报),2017,39(7):124-129.
[3]黄星,刘樑.突发事件网络舆情风险评价方法及应用[J].情报科学,2018,36(4):3-9.
[4]庄荣文.网络信息内容生态治理规定[EB/OL].http://www.cac.gov.cn/2019-12/20/c_1578375159509309.htm,2019-12-15.
[5]毛明松,张富国.基于多重图排序的用户冷启动推荐方法[J].计算机工程,2019,45(5):175-181.
[6]王娜娜,高红,刘巍.异质边多重图网络模型研究[J].智能系统学报,2017,12(4):475-481.
[7]任亮,黄敏,王洪峰,等.第四方物流多目标路径集成优化[J].复杂系统与复杂性科学,2018,15(1):62-67.
[8]Chikhaoui B,Chiazzaro M,Wang S.A New Granger Causal Model for Influence Evolution in Dynamic Social Networks:The Case of DBLP[C]//Proceeding of Twenty-Ninth AAAI Conference on Artificial Intelligence,2015:51-57.
[9]Sarna G,Bhatia M P S.Content Based Approach to Find the Credibility of User in Social Networks:An Application of Cyberbullying[J].International Journal of Machine Learning & Cybernetics,2015,8(2):1-13.
[10]Gjoka M,Butts C T,Kurant M,et al.Multigraph Sampling of Online Social Networks[J].IEEE Journal on Selected Areas in Communications,2011,29(9):1893-1905.
[11]Wu S,Liu Q,Liu Y,et al.Information Credibility Evaluation on Social Media[C]//California:AAAI Press,2016:1-2.
[12]張子良,董红斌,谭成予,等.微博信息可信度评估的数据起源方法[J].计算机应用研究,2018,35(11):3330-3334.
[13]闫光辉,刘晓飞,王梦阳.基于链接的微博用户可信度研究[J].计算机应用研究,2015,32(10):2910-2913,2917.
[14]国佳,郭勇,沈旺,等.基于在线评论的网络社区信息可信度评价方法研究[J].图书情报工作,2019,63(17):137-144.
[15]Schinder S K,ODonnell L,Stueve A,et al.Cyberbullying,School Bullying,and Psychological Distress:A Regional Census of High School Students[J].Am J Public Health,2012,102(1):171-177.
[16]Hutson E,Kelly S,Miltello L K.Systematic Review of Cyberbullying Interventions for Youth and Parents with Implications for Evidence-based Practice[J].World Evidence-Based Nurs,2018,15(1):72-79.
[17]石国亮,徐子梁.网络欺凌的界定及其特点分析[J].中国青年研究,2010,(12):5-8.
[18]曹晓琪,田苗,宋雅琼,等.大学生遭受网络欺凌与抑郁的相关性[J].中国学校卫生,2020,41(2):235-238.
[19]Peled Y.Cyberbullying and Its Influence on Academic,Social,and Emotional Development of Undergraduate Students[J].Heliyon,2019,5(3):e01393.
[20]李凯,于艺.社会化媒体中的网络隐私披露研究综述及展望[J].情报理论与实践,2018,41(12):155-160.
[21]邵明.基于进化博弈的LBSNS用户隐私信息披露行为研究[D].广州:华南理工大学,2016.
[22]魏明侠.感知隐私和感知安全对电子商务信用的影响研究[J].管理学报,2005,(1):61-65,75.
[23]凡菊,姜元春,张结魁.网络隐私问题研究综述[J].情报理论与实践,2008,(1):153-157.
[24](英)路易斯·麦克尼.福柯[M].贾湜,译.哈尔滨:黑龙江人民出版社,1999:103-105.
(责任编辑:孙国雷)
