基于注意力机制的高效点云识别方法
2020-08-17林钦壮何昭水
林钦壮,何昭水
(广东工业大学自动化学院,广东 广州 510006)
0 引 言
点云数据是一种几何数据格式基本类型,可以理想地表现空间流形的几何特征[1]。因此,随着云计算和人工智能算法的发展,点云数据在自动驾驶[2-3]、3D物体识别和检索[4-6]、机器人视觉[7],甚至灾害破坏检测[8]等诸多方面有日渐广泛的应用。然而,由于点云数据具有非结构化、排列不变性以及点云数量不确定等特点,使得现有的很多深度学习方法[9]在点云识别上的运用具有效率低、计算量大、场景通用性差等诸多缺点。为此,研究深度神经网络如何高效地进行点云识别对自动驾驶等现实场景应用具有重要的研究意义。
深度学习方法以神经网络为基础,运用在点云数据上面临以下几点挑战:1)点云数据是非结构化数据,即点云是分布在空间中、以坐标xyz呈现的点,这使得典型的结构化网络的卷积神经网络(CNN)难以直接使用;2)点云具有排列不变性,即点云数据中点的顺序是无序的,不同顺序的点可以表示一个相同的物体或场景,这使深度神经网络在获取特征时更加困难;3)点云数据具有数量变化的不确定性,这是激光雷达等传感器在现实场景下常遇到的问题。
1 点云识别的挑战与研究现状
针对点云的特点,目前深度学习方法在点云识别上的运用大致可以分为3类。一类是将三维点云数据映射成多个角度的二维图片,再采用深度神经网络对映射成的结构化的图片进行处理,典型的如MVCNN[10]、RotationNet[11]等。这种方式虽然可以方便地使用在图片识别取得良好效果的神经网络模型上,但需要获取点云数据在不同角度的映射图片,在自动驾驶等多种现实场景下并不适用。另一类是将三维点云还原成三维空间,再采用空间的3D卷积神经网络进行处理,典型的如VoxNet[12]、3D ShapeNet[13]等。这类方法计算了整个立体空间,大量为空的空间也参与了计算,使得整个模型计算量很大,通常需要通过降低分辨率等方式来减少计算,但这也在一定程度丢失了数据空间联系的细节特征。第三类则是直接处理点云数据,通过在网络中计算变换矩阵或者近邻点来获取特征,从而实现点云识别,典型的如PointNet[14]、PointNet++[15]等。PointNet通过一个子网络学习点云数据及其特征的变换矩阵,从而达到直接处理点云数据,但该方法却忽略了点云数据间点与点的关系,参数量较大。PointNet++可以看作是在PointNet基础上加以提升,通过采样局部近邻内的点来获取点云局部点的关系,进而提高识别率,该方法虽然减少了参数量并提高了识别精度,但方法具有计算量大、时间消耗大等缺点。
综上所述,由于点云数据自身特点给深度神经网络解决方法带来的困难,目前的研究方法有着计算量大、参数量大、场景通用性差的缺点。针对现有深度学习算法在点云上应用存在的问题,本文提出一种结合注意力机制(Attention Mechanism)与深度残差神经网络的方法,直接处理点云数据进行高效识别。研究对比了不同的处理点云方式的深度学习方法,包括映射成二维图片的方法、基于空间立体的方法以及直接处理点云的方法,并在MNIST、ModelNet40等数据集上对比不同方法对2D点云和3D点云的识别效果。实验结果表明,本文提出的方法在保证高识别精度的同时,具有参数量小、计算量小、更高效等优点。
2 基于注意力机制的点云识别方法
2.1 注意力机制与残差学习结合
注意力机制的研究源于人体视觉对环境的注意力[16]。近年来,随着深度学习的运用,注意力机制在自然语言处理[17]和图片识别[18]等多个领域均有研究和应用。图1(a)为注意力机制的结构示意图,其中FCN为多层全卷积层,包括卷积层、Batch Normalization层[19]以及ReLU激活层[20]等。对于给定输入x,通过网络学习得到特征T(x),特征之间权重W(x),则通过注意力机制后输出为:
Fi,c=Wi(x)·Ti,c(x)
其中,i为第i个点(或特征),c∈{1,…,C}为通道索引,特征与权值间的运算为Hadamard乘积。注意力机制通过网络学习获得特征及其相关权值,使得重要的点或特征凸显出来。
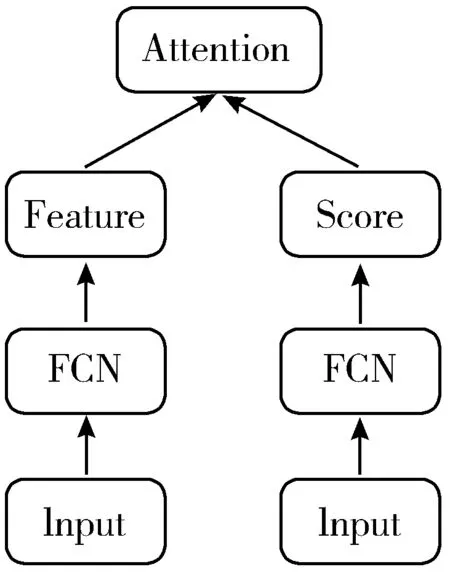
(a) 注意力机制
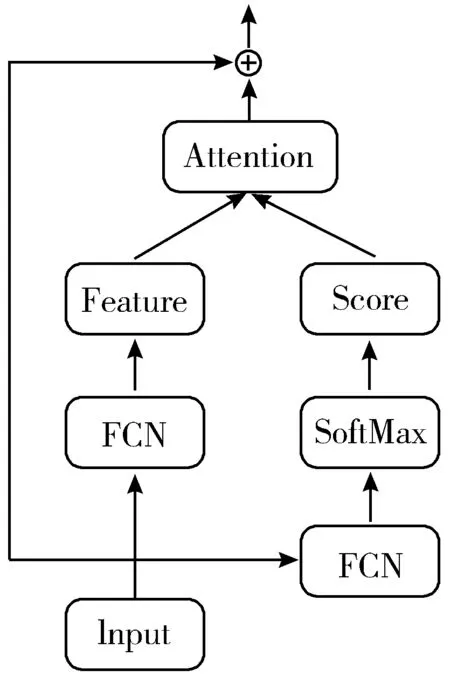
(b) 结合残差学习的注意力模块
为了进一步有效地学习点云的整体分布,本文方法结合残差学习的方式。残差学习源于残差网络[21],用于解决深度学习中由于梯度消失带来的性能下降问题。由于点云数据具有无序的特点,而残差学习的网络可以通过显式地学习多个堆叠的残差映射,有利于扩大网络的容量,提高网络对数据的拟合能力,提高对点云数据的识别精度。本文方法采用图1(b)所示的结合残差学习的注意力机制模块。对给定输入x,通过该模块后输出为:
H(x)=F(x)+x
=Wi(x)·Ti,c(x)+x
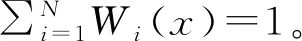
2.2 整体学习框架
本文方法可以直接处理输入的点云数据。该方法的整体框架示意图如图2所示,输入点云的形式为(n×d×1),其中n为点云点的数量,d为点云的维度,图中其他模块的大小设置也与此类似。点云数据流经Conv层后流入多个结合残差学习的注意力模块堆叠而成的网络结构,其中Conv层由卷积层、Batch Normalization层以及ReLU激活层组成。由残差注意力模块学习得到的特征,经过最大池化层(Max Pooling)后,再通过多层感知机(MLP),最后输出分别隶属于k个类别的分数,得到输入点云数据所属的类别。对于网络输出,采用Softmax计算,将输出转化为属于每个类别的概率:
其中v为输出向量。网络经过Softmax计算后,再使用Cross-Entropy计算整体的损失(loss):
其中,y′i为标签中的第i个值,yi为经过Softmax归一化后输出向量的第i个分量。最后对同个batch中的样本的loss计算平均值,获得最后的反馈损失。
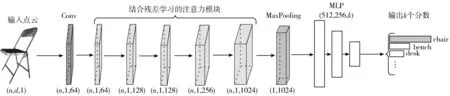
图2 基于注意力机制的高效点云识别方法的整体框架
3 实验与结果分析
本文实验采用MNIST数据集和ModelNet40数据集,对比分析在2D点云和3D点云数据上不同方法的表现。实验运行的硬件环境CPU为Intel Xeon E5-1650 v4, GPU为NVIDIA TITAN Xp,实验运行的软件环境为64位的Ubuntu 16.4 LTS并采用TensorFlow 1.4进行实验。实验采用准确率作为评价指标,即:
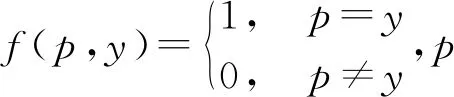
3.1 2D点云识别
对于2D点云识别,本文采用了典型的手写数字数据集MNIST[22]。该数据集包含60000个手写数字图像样本作为训练集和10000个手写数字图像样本作为测试集。在预处理阶段,以128作为阈值,将手写数字图像中灰度值大于该阈值的像素点转换为二维点云,点云中的点以二维坐标(x,y)的形式组成。实验设置了点云集合的大小为256,对于点云数量大于256的样本,采用随机采样的方式,对于点云数量小于256的样本,则使用其全部的点,并从该样本中随机采样点补足到256个。
本文将实验的batch大小设置为128,将dropout层的神经元失活概率设置为0.3,将学习率初始化为0.05并以每30个epoch乘以0.7的速率递减。实验结果如表1所示,本文方法在2D点云识别上展现了优于其他方法的准确率。
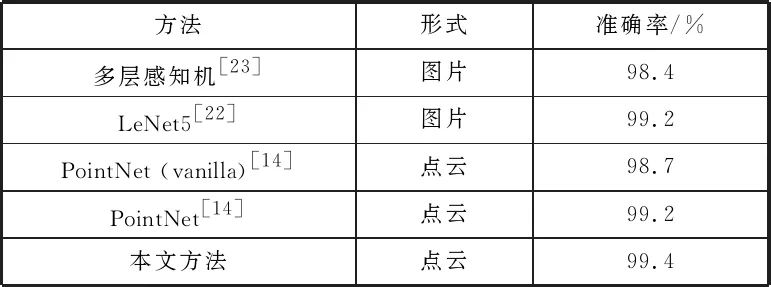
表1 各方法在MNIST上进行2D点云识别的准确率比较
3.2 3D点云识别
针对3D点云识别,本文采用了典型的3D数据集ModelNet40[13]。该数据集包含了40类物体,一共12311个三维网格化的3D模型。其中,训练集包含9843个样本,测试集包含2468个样本。本文采用PointNet方法处理数据,通过对于每一个3D模型进行均匀随机采样1024个点,将网格化的3D模型转换成三维点云的形式,即模型的三维点云以(x,y,z)三维坐标存在,并将整个模型的三维点云归一化到单位空间。
本文实验采用了Adam优化方法,将学习率设置为0.001,将动量(momentum)设置为0.9,将batch大小设置为32。为了提高对数据的利用,使网络学习到本质的特征,本文在训练过程同时采用了2种数据增强操作。一种是随机让3D模型选择绕x轴、y轴或z轴旋转一定角度,即点云数据乘以一个0~2π之间随机角度的旋转矩阵。另一种数据增强操作是对点云数据中的点进行随机抖动,实验将抖动范围设置在[-0.05, 0.05]区间。图3(a)为实验过程中损失函数收敛曲线,图3(b)为随着训练epoch增加的测试准确率曲线,可见该网络模型具有快速、良好的收敛性能。

(b) 测试准确率曲线
实验结果如表2所示,本文方法在3D点云识别上达到了与前沿算法近似甚至超过的准确率。
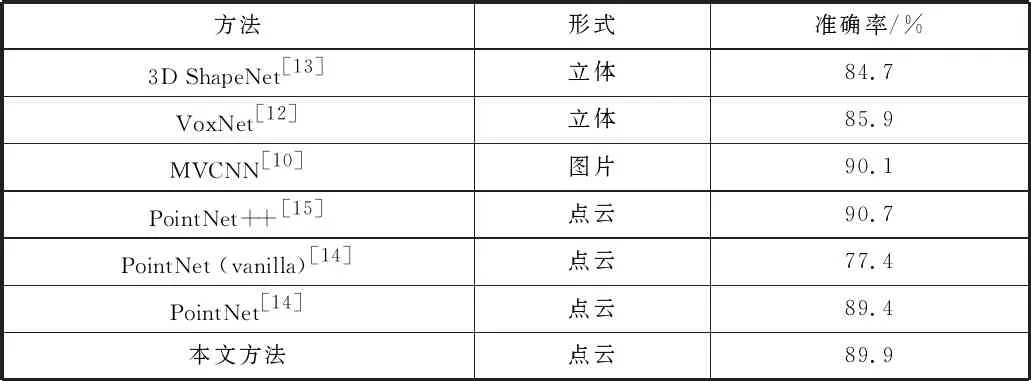
表2 各方法在ModelNet40上进行3D点云识别的准确率比较
3.3 算法对比分析
在2D点云识别和3D点云识别实验中,本文方法表现出了高识别准确率。为了更全面地分析本文方法的特点,验证该网络算法的优势和实际可应用性,选择了同样直接处理点云数据且具有良好识别率的算法来比较其模型大小与运行效率。

表3 各方法在3D点云识别实验中的网络参数量及运行速度比较
以3D点云识别为例,各方法网络参数量和运行速度对比如表3所示。从网络大小而言,本文方法对比PointNet模型减少了50%以上的参数量,对比PointNet++减少了17%以上的参数量,这是由于本文方法采用注意力机制的方式直接获取点云特征,避免了采用子网络学习变换矩阵的方式,从而使模型更加简单,更有利于实际应用。从网络运行速度而言,本文方法略快于PointNet,对比PointNet++运行时间减少60%以上,这是由于通过注意力机制与残差学习的结合方式可以获取点云之间关系,减少了显式查找点云局部关系,使得网络模型更为快速和高效。通过对比分析可知,本文方法具有更加简单、更加高效的特点,也使得其在实际应用中更有优势。
4 结束语
针对当前深度学习方法在点云识别上的运用具有效率低、计算量大、场景通用性差等诸多缺点,本文提出了一种高效的点云识别方法。通过结合注意力机制与残差学习,该方法直接处理点云数据,并获取其重要特征,从而达到对点云数据的高效识别。实验结果表明,该方法在2D与3D点云数据中都具有良好的识别准确率,并且具有模型简单、参数量小、计算量小、更高效等诸多优点。
