近红外光谱技术在中草药口服液在线质量监控中的模型建立和模型转移
2020-08-17胡丽萍黄生权田淑华黄延盛胡流云FALOLAAkinola李璇舒逸聃王学重
胡丽萍,黄生权,田淑华,黄延盛,胡流云,A FALOLA Akinola,李璇,舒逸聃,王学重,
(1 华南理工大学化学与化工学院,广东广州510640;2 无限极(中国)有限公司,广东广州510623;3 晶格码(青岛)智能科技有限公司,山东青岛266109;4 北京石油化工学院化学工程学院,恩泽生物质精细化工北京市重点实验室,制药和结晶系统工程中心,北京102617)
中草药是中华民族的瑰宝,在中国已有上千年的历史。中草药是中医预防治疗疾病所使用的独特药物,也是中医区别于其他医学的重要标志。利用过程分析技术(process analytical technology, PAT)对产品质量进行在线检测和调控是提高中药制造检测水平的有效手段[1]。本文研究近红外光谱(NIR)技术进行在线质量检测的对象是中药口服液,其有效成分复合多糖是从多种天然植物中提取的免疫调节剂,具有增强人体免疫力、提高机体抵抗力、提升睡眠质量、降血脂、抗衰老、抗癌等功效[2]。保障多糖含量是保障口服液质量的关键。多糖含量的检测方法主要有色谱法、化学法[3]以及近红外光谱法[1],其中近红外光谱法具有快速、高效、实时在线、操作简单、无样品预处理、对样品无破坏等特点,在食品[4]和药品[5-7]的定性定量在线分析中有着广泛的应用。
但近红外模型在使用过程中对于环境条件以及设备要求严苛,当检测条件、检测环境或仪器设备变化时,光谱的吸光度会出现差异以及出现波长漂移的现象,使得原模型对于新数据不再有预测效果或预测效果差。为了解决这一现象,模型转移的概念被提出。模型转移可以解决由于更换仪器部件、更换仪器、检测条件变化、检测环境变化或随时间推移而产生的一些其他变化所导致的原有模型预测准确度降低的问题,从而确保模型的长期有效性。近红外光谱受测量仪器或测量条件的影响较大,模型转移对近红外光谱技术的推广应用显得尤为重要[8]。
按照是否需要在主仪器(已有模型仪器)和从仪器(待转移模型仪器)上采集一一对应的标准光谱,模型转移可分为有标样模型转移和无标样模型转移。有标样模型转移是通过回归算法对源机及目标机光谱或进行回归得到二者之间的转换关系,目前模型转移方法主要有:直接标准化法[9-11](direct standardization,DS)、斜率截距法[12-15](slope/bias,S/B)、分段 直接标准化法[15-18](piecewise direct standardization, PDS)、Shenk’s 算 法[19-20](Shenk’s algorithm)、典型相关分析[21-22](canonical correlation analysis,CCA)。在实际应用中,往往无法从主从仪器上获取一一对应的标准光谱,这时就需要使用无标样的模型转移算法——利用基线校正、光谱求异、数字滤波、信号平滑等方法减小仪器间光谱差异的方法。常见算法有正交信号校正[23-28](orthogonal signal correction,OSC)、稳定竞争自适应重 加 权 采 样[29](stability competitive adaptive reweighted sampling, SCARS)、 小 波 变 换[30-31](wavelet transform, WT)等。对于有标样的模型转移算法,刘翠玲等[11]利用直接标准化法对食用油的食用油酸值和过氧化值两个指标的模型进行转移,实现了不同仪器间的模型共享。李鸿儒等[10]对直接标准化算法进行改进,对光谱矩阵进行主成分分解后再进行模型转移,并用玉米和烟草为实验对象进行验证,结果表明改进后的DS法对玉米和烟草模型转移有着不同维度的提升。吉纳玉等[12]用SB算法研究了不同水果间的模型转移,成功实现苹果、梨、桃这3种水果的可溶性固形物模型之间的相互传递。信晓伟等[14]对SB算法进行改进,解决两组数据的非线性问题,提高模型转移准确性。李鑫等[18]以烟叶的两种物理形态为研究对象,对比分析Shenk’s 算法、PDS、CCA 这3 种算法的模型转移稳健性。苏虹[20]以烟叶的不同产地为研究对象,采用Shenk’s算法研究分析了烟叶在不同仪器间的模型转移。对于无标样的模型转移算法,刘贤等[27]研究了OSC法的不同数据预处理方法在秸杆饲料近红外光谱模型传递中的应用。张晓羽等[29]采用SARCS法研究在无标样模型转移中的应用。杜文等[31]以烟草中还原糖、总糖、总碱和游离氯为研究对象,研究了WT的不同前处理方式对烟草模型转移的影响。对于有干扰物的混合物样品光谱建模,Zhao等[32]基于独立成分分析提出了一种新的鲁棒校准建模策略O-ICR(orthogonal signal correction-independent component regression),不仅能增强模型的稳健性,还能提高模型转移的预测性能。此方法将光谱信号划分为干扰信号、质量正交信号和质量相关信号,通过两步校正消除干扰信号和质量正交信号,仅使用质量相关信号来创建回归模型,基于少量样本即可以消除仪器间光谱差异和温度对光谱的影响。
标准标样是指用主仪器和从仪器分别采集光谱的样品,其中主仪器光谱叫标准光谱,所测样品叫标准标样。在工业生产中,难以获得能在主仪器和从仪器上均采集光谱的标准标样,而使用无标样算法对本文研究对象的模型转移预测效果差。本文使用较为广泛应用的有标样模型算法直接标准化(DS)法,结合PCA降维,在无法获取标准标样的情况下,使用与从仪器样品化学值一一对应后误差不超过3%的主仪器光谱作为虚拟标样进行有标样转移,解决工业生产过程中无法采集一一对应的标准标样,并且无标样算法预测效果差的问题,实现工业上模型的在线转移。王安冬等[33]将经直接正交信号校正法(direct orthogonal signal correction,DOSC)校正的光谱与其参考值之比定义为虚拟标准平均光谱,并以虚拟标准平均光谱的回归为核心来消除样本批次间的背景差异。本文沿用王安冬等[33]有关虚拟标准平均光谱的思想,为此,考虑到本文研究对象在模型转移前后的样品原料、制备工艺、检测方法均未发生变化。本文将转移前后化学值一一对应后误差不超过3%的样品称为虚拟标样,与从机样品化学值对应的主机样品光谱称为虚拟标样光谱。利用虚拟标样进行有标样的模型转移,实现无标准标样时的有标样模型转移。与王安东等[33]的方法相比较,用直接正交信号校正将主从机光谱进行预处理后再虚拟化,是一种有标准标样的模型转移光谱虚拟方式,消除由原料变异引起的光谱背景差异。本文采用的方法是根据样本原料相同,将主机样本光谱虚拟成标样,消除由于更换仪器带来的光谱差异,实现无标样模型转移。
本文基于中草药口服液多糖、可溶性固形物和pH这3项指标,研究模型转移情况。采用x-y共生距离(sample set partitioning based on joint X-Y distances,SPXY)样本划分方法,划分训练集和验证集,使用遗传算法[34](genetic algorithm,GA)选择有效波段,建立偏最小二乘(partial least squares, PLS)模型;再利用直接标准化(DS)方法进行在线模型转移。
1 实验部分
1.1 样品与仪器
实验所用样品为某药企某中药口服液,该口服液前期(2017 年10 月以前)在一车间,即一期(主仪器)生产,模型已完善成功并在线使用。后期由于一车间厂房升级改造,该产品转入二车间,即二期(从仪器)生产,光谱采集的主仪器、探头、光纤长度均发生变化,并且一、二期主机分辨率不同,导致一期红外变量为1557 个,二期红外变量为778个,一期模型对二期数据完全没有预测效果。其中2017年2月至2017年9月于生产一车间在线采集的不同月份不同批次的该口服液样品186组用于建立主仪器模型(原模型);2017年10月至2018年6月于生产二车间在线采集的不同月份不同批次的该口服液样品158 组用于从仪器模型转移;2018 年8 月至10 月于生产二车间在线采集的不同月份不同批次的该口服液样品34批。
光谱采集主要仪器为Antaris MX 傅里叶近红外在线光谱分析仪(美国Thermo Fisher Scientific 公司)。采集光谱探头为透反射探头。以空气为参比,采集波长范围为1000~2500nm,扫描次数为32 次,主仪器主机分辨率为8cm-1(变量1557),从仪器主机分辨率为16cm-1(变量778),吸光度数据格式为SPA,每个样品重复3 次扫描,采用3 次扫描光谱的平均光谱作为该样品的模型数据。
1.2 化学值测定
口服液检测指标为多糖、可溶性固形物和pH。多糖总糖含量的测定方法参考《食品中还原糖的测定》GB/T 5009.7—2008 第一法:高锰酸钾滴定法进行测定,每个样品测定3组平行样,取平均值作为模型数据。可溶性固形物含量的测定方法为折光计法,每个样品测定3组平行样,取平均值作为模型数据。pH 的测定使用酸度计进行测定,每个样品测定3组平行样,取平均值作为模型数据。
所用仪器主要有:ME2002 电子天平,梅特勒-托利多公司;LXJ-IIB 大容量多管离心机,上海安亭科学仪器厂;DGG-9240BD 电热恒温干燥箱,上海森信实验仪器有限公司;RX-5000a 数字折光仪,ATAGO公司。试剂主要有:五水硫酸铜、酒石酸钾钠、氢氧化钠、浓硫酸、浓盐酸、硫酸铁铵、高锰酸钾、无水乙醇,均为分析纯,广州化学试剂厂;蒸馏水,自制。
2 模型建立与转移的方法和步骤
本文采用PLS-GA法建立最优主仪器模型,采用DS-PCA法进行模型转移。
2.1 直接标准化法(DS)原理
首先确定主仪器和从仪器上采集的光谱之间的数学函数关系,再用已经确定的函数关系转换从仪器上所采集的对应样本的光谱数据,从而减少不同仪器间所测同一样本光谱数据的差异,实现模型在不同仪器间转移,按式(1)计算。

式中,Xm、Xs分别为样品标准集在主仪器和从仪器上测得的经过中心化处理的光谱矩阵;F为转移矩阵。由于在线转移过程无法在主从仪器上采集一一对应的标准光谱作为标准标样,因此在模型转移过程中采用主从仪器化学值对应后误差不超过3%的样品作为转移的虚拟标样集,其所对应的光谱为虚拟标样光谱。
经转移过的从仪器光谱矩阵Xstd用式(2)计算。

式中,Xunknown为待转移的从仪器光谱。
2.2 模型转移步骤
(1)采集分析数据 获取主仪器与从仪器样品光谱值及化学值,对样品化学值及光谱值进行分析,剔除异常值。
(2)主仪器模型建立 采用SPXY 分组主仪器样品,划分训练及验证数据,用PLS-GA法建立最优的主仪器模型。
(3)虚拟标样集确立 DS 法是有标样的模型转移方法,模型转移过程中需要联合标准标样的主仪器与从仪器的光谱值确立转移矩阵,转移矩阵的好坏是模型转移成功与否的关键。而工业生产中难以获得主仪器与从仪器一一对应的标准标样光谱。王安冬等[33]将经DOSC 校正的光谱与其参考值之比定义为虚拟标准平均光谱,将主仪器与从仪器的标准标样光谱集均转换为相应的虚拟标准平均光谱集,再用PLS法拟合主仪器与从仪器虚拟标准平均光谱集之间的线性关系,拟合出回归系数与常数项的值,得出转移后的PLS模型,再用该PLS模型转换待转移光谱进行验证。王安东等[33]将主从仪器光谱的标准标样光谱均用DOSC 法进行转换并用PLS建立转移矩阵,因此,本文在沿用王安冬等[33]的虚拟思想的同时,保留主仪器与从仪器的光谱特性,用原光谱进行转移,并采用DS法进行转移,再结合本文研究对象的特性,提出以模型转移前后,主从仪器样品集中化学值对应后误差不超过3%的样品集作为虚拟标样集,与从机样品化学值对应的主机样品光谱称为虚拟标样光谱。采用SPXY分组从仪器样品,划分训练及验证数据。分析主仪器光谱与从仪器光谱值及化学值,以主仪器中与从仪器训练集样品化学值对应后误差不超过3%的样品作为虚拟标样,与此相应的主仪器光谱为虚拟标样光谱。
(4)转移矩阵的建立 以虚拟标样集中主从仪器光谱集为基准,采用DS 联合PCA 降维计算转移矩阵。
(5)模型转移结果检验 用转移矩阵转移从仪器的验证集光谱,用原主仪器模型预测转移后的从仪器验证集光谱,计算相对误差。调整虚拟标样集以获得最准确的转移矩阵,提高模型转移准确性。
2.3 模型评价指标
模型评价指标为误差均方根(RMSEC)、交叉验证均方根(RMSECV)、预测均方根(RMSEP)。模型转移结果评价指标为模型转移预测值(yp)与测量真值(化学值,ym)之间的相对误差(δ),由式(3)计算。

2.4 建模环境
建模环境为Matlab(R2014a)及Matlab 自带的工具箱PLS_Toolbox_86。
3 模型建立与转移的结果与讨论
主仪器模型建模数据为186组,光谱变量1557个,用SPXY 样本划分方法,划分训练集150 组用于建模和验证集36组用于验证。
从仪器转移数据为158 组,光谱变量778 个。其中多糖转移训练数据90 组,验证数据68 组;可溶性固形物转移训练数据90 组,验证数据68 组;pH转移训练数据90组,验证数据68组。转移数据中的训练数据联合虚拟标样使用DS 算法建立转移矩阵。图1为一期二期光谱对比图。由图可直接观察到一期二期光谱存在肉眼可见的差异。
3.1 一期模型建立过程
近红外模型建立方法参考李晶晶等[5]的建模方法。一期已上线应用模型的建立过程如下。一期数据采集完成后,首先对光谱数据进行查看,发现有一组数据明显无吸收峰,光谱如图2所示,一组明显区别于其他光谱,在200以上区域无吸收峰,视为异常光谱。其他光谱数据均为3次扫描的平均光谱,而此组数据仅一张单张光谱。分析了各种可能的原因都不能下结论。对于此组光谱数据就直接作为异常光谱剔除了。周昭露等[1]对通过算法检查异常数据的方法做了综述,包括光谱残差、马氏距离、光谱峰异常等。这些方法在本课题组的软件中都集成了。剔除异常光谱数据后,余下186组用于一期模型建立。采用SPXY 分组方法选出150 组作为训练数据,36 组用作验证数据。建模过程采用PLS 方法建立线性模型,经预处理、留一交叉验证、GA 自动选择波段后建立一期模型。一期模型在线应用过程中对一期生产产品多糖96%相对误差在10%以内,可溶性固形物96%相对误差在5%以内,pH 100%相对误差在3%以内。
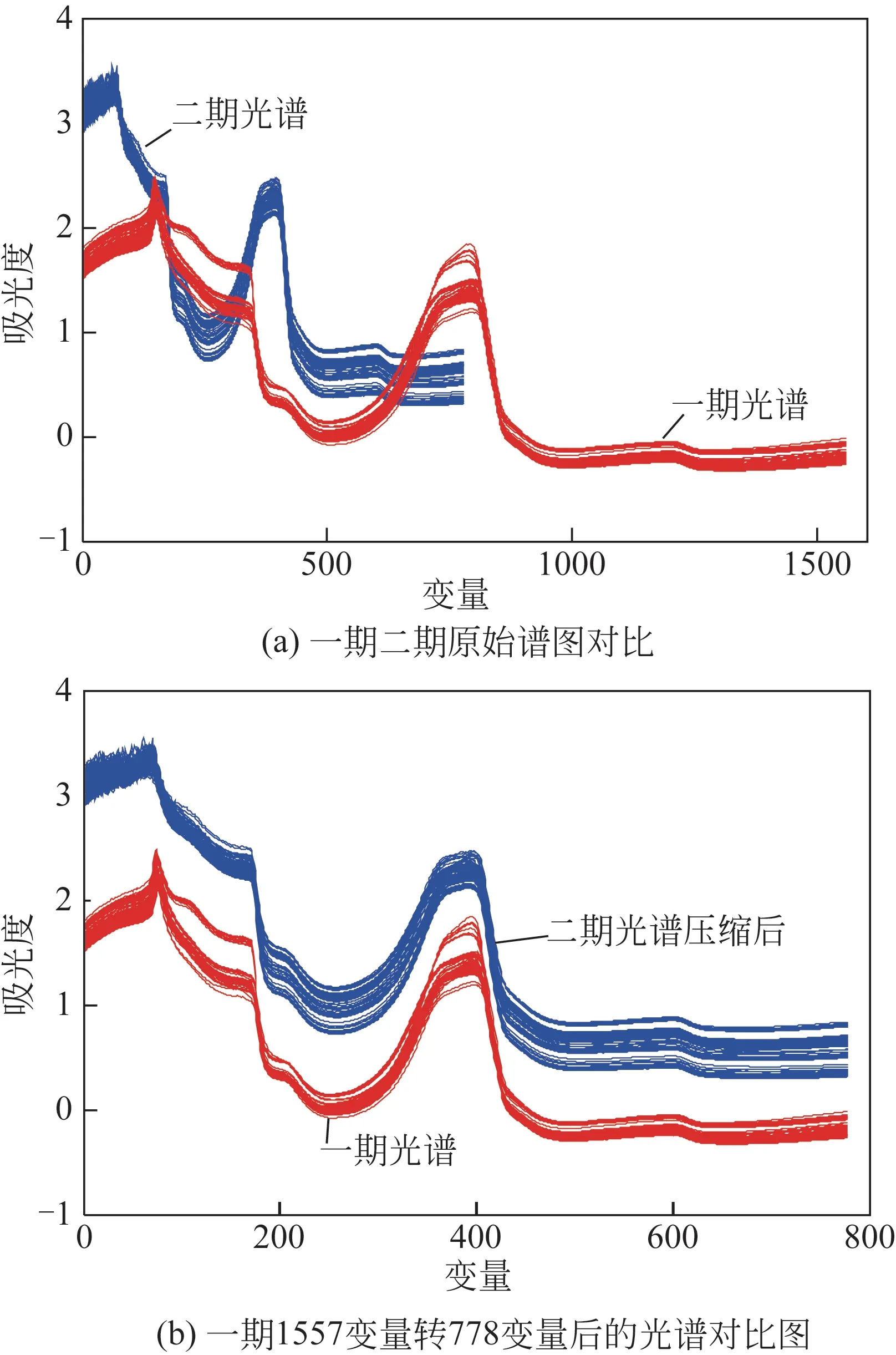
图1 一期二期光谱对比图
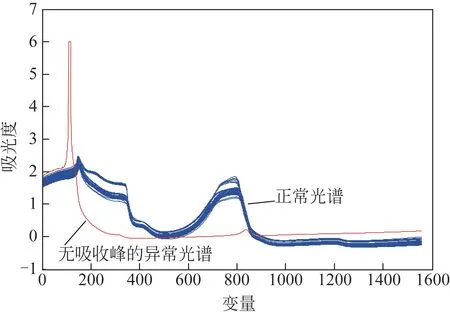
图2 一期光谱原始图
3.2 多糖模型转移
由于一期光谱变量1557 个,对二期778 个变量,光谱不能直接用一期1557 个变量模型为原模型进行转移。因此转移的第一步是将一期1557 个变量模型转变为778个变量模型,并以此模型(一期778个变量模型)为原模型进行模型转移。
1557模型转变为778模型的方法:将旧一期的1557个变量里按波数相同挑出778个变量,将1557个变量压缩成778 个。再用778 个变量用于建立模型,建模所用分组和预处理方法选择与1557 个变量模型相同,之后再用GA 选择合适的波段进行建模。
多糖模型建模最佳方法为:预处理方法1st Derivative,波段选择采用GA自动选择波段,所选变量为198 个。模型RMSEC:24.5138,RMSECV:45.8971,RMSEP: 43.862,建模结果见表1,最大相对误差在15%以内,96%的数据误差集中在10%以内。一期778 个变量模型预测二期数据结果见表2。

表1 一期多糖778模型建模结果

表2 一期多糖778模型预测二期数据结果
从表2 的结果可以看出,一期778 模型对二期数据预测的最大相对误差达到206%,对二期数据没有预测效果,需要进行模型转移。
多糖模型转移以一期778变量模型为主仪器模型进行模型转移。模型转移方法为DS(直接标准化)法。由于模型转移为在线转移,不能在主仪器和从仪器上采集一一对应的标准光谱。为了解决这一问题,经研究分析后采用一期样品中与二期样品化学值对应后误差不超过3%的样品光谱集作为虚拟标样进行模型转移。通过主成分分析法(PCA)对光谱数据进行了降维处理,利用PCA 降维处理的方法文献[35-36]中有描述。例如,首先对主机虚拟标样光谱,应用PCA 分析,其第一主成分贡献率为93.3%,第二主成分贡献率为9%,第三主成分贡献率为1%,其中第一、二主成分总贡献率超过95%,包含超过95%的信息,因此选取主元数为2对虚拟标样光谱进行降维处理。其次对从机训练数据光谱应用PCA 分析,其第一主成分贡献率为98.5%,第二主成分贡献率为16.8%,第三主成分贡献率为2.5%,其中第一、二主成分总贡献率超过95%,包含超过95%的信息,因此选取主元数为2对从机训练数据进行降维处理。再将降维后的主从机光谱联合DS 法进行模型转移,形成DS-PCA自编辑的光谱转移算法,以提高模型转移的效率以及预测性能。
虚拟标样的选取是模型转移成功与否的关键。首先要保证一、二期生产的口服液原料、生产工艺、质量指标化学检测方法不变,以确保一、二期产品的统一,这是一期样品光谱能作为二期光谱转移虚拟标样的前提,一期、二期多糖浓度范围见表3。对比分析一期、二期样品化学值,对多糖化学值数据,一期186 组样品多糖浓度范围是559~916mg/100mL,二期158 组样品多糖浓度范围是594~807mg/100mL。分布图见图3,散点图见图4(红色代表一期多糖浓度,蓝色代表二期多糖浓度),可见一期、二期数据均集中在650~750之间,将二期数据与一期数据一一对应后,二期与一期多糖化学值误差在2%以内,而工业上可接受的误差范围为10%,因此人为设定当误差在3%以下即为可接受数据,可作为虚拟标样。对二期158组数据采用SPXY分组法进行分组,其中训练集90组,验证集68 组。将与二期训练集样品化学值一一对应的一期样品光谱作为虚拟标样,联合训练集光谱采用DS-PCA法建立转移矩阵F,得到转移模型。
再利用光谱转移矩阵F转移训练验证数据光谱,用原模型进行预测。光谱转移结果见图5。模型转移结果如表4所示,训练集、验证集与化学值的相对误差结果见图6。
从图和表中可以看出,多糖模型转移结果92%的数据能保证误差在10%以内,能满足工业生产需求。

表3 一期、二期多糖浓度范围
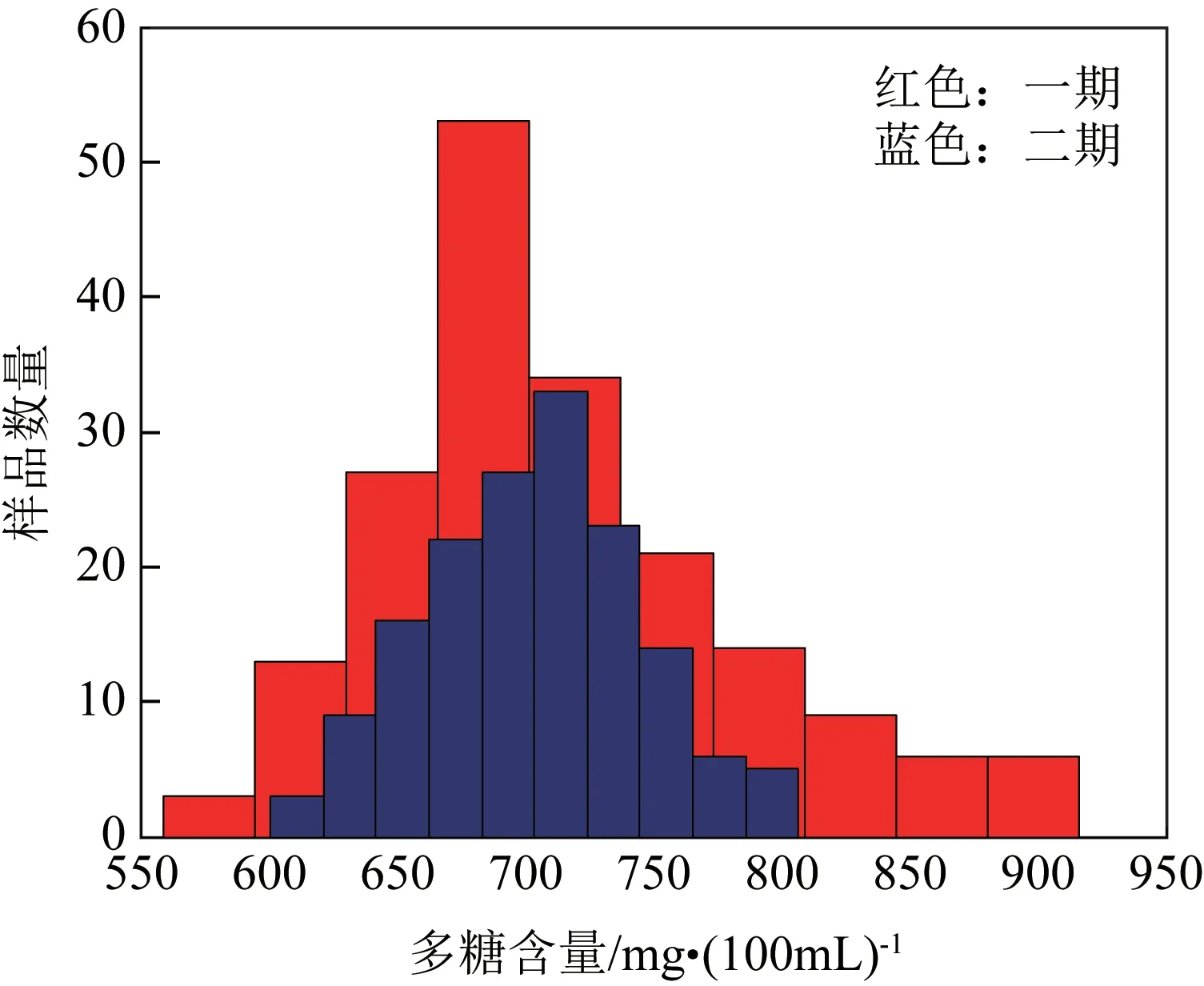
图3 多糖化学值分布图

图4 多糖化学值散点图
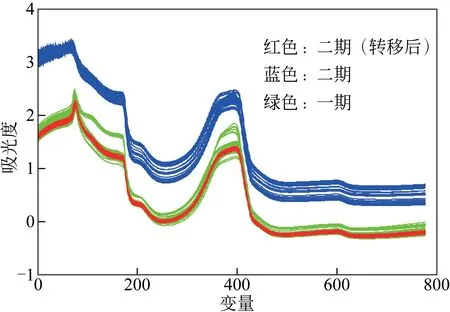
图5 转移光谱对比

表4 多糖模型转移结果

图6 多糖模型转移的训练集、验证集与化学值的相对误差结果
3.3 可溶性固形物与pH模型转移
可溶性固形物与pH 的一期原模型建立方法、二期模型转移方法与多糖的建模方法和模型转移方法相同。可溶性固形物模型转移结果见表5,训练集、验证集与化学值的相对误差结果见图7;pH模型转移结果见表6,训练集、验证集与化学值的相对误差结果见图8。

表5 可溶性固形物模型转移结果

图7 可溶性固形物模型转移的训练集、验证集与化学值的相对误差结果

表6 pH模型转移结果
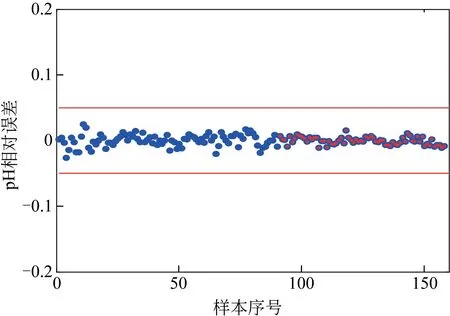
图8 pH模型转移的训练集、验证集与化学值的相对误差结果
从图表可见,可溶性固形物模型转移结果95%的数据能保证误差在5%以内;pH 模型转移结果100%的数据能保证误差在3%以内,完全能满足适用于工业生产。
3.4 模型实用价值考察

图9 盲样光谱
为了考察转移后的模型在该口服液生产过程中的应用价值,2018 年8 月至10 月于生产二车间同一生产线在线采集该口服液样品34 批用作盲样(盲样光谱见图9),使用上文所述的转移模型进行多糖、可溶性固形物和pH的预测,34组盲样的化学值与预测值间相对误差见表7。
由表7可知,经转移的模型对盲样数据预测效果很好,基本满足工艺需求,十分有工业应用价值。
4 结论
在使用有标样的PCA 降维的直接标准化DS 的光谱转移算法对中草药口服液的转移过程中,对于无法取得标准标样数据,使用与从机样品化学值一一对应后误差不超过3%的主机样品作为虚拟标样进行模型转移能满足工业需求。其中,转移后的多糖模型对训练集、验证集及盲样,预测值与化学值之间的相对误差均控制在10%以内;转移后的可溶性固形物模型对训练集、验证集及盲样,预测值与化学值之间的相对误差均控制在5%以内;转移后的pH 模型对训练集、验证集及盲样,预测值与化学值之间的相对误差均控制在3%以内。使用这种寻求虚拟标样的方法,用有标样的模型转移算法,只需要少量的从仪器数据即可实现模型的高准确性转移,提高模型利用率,也能拓宽有标样模型转移算法的使用范围。从另一个方面寻求标准标样的替代品,从而解决工业生产上标准标样获取困难的难题。并且无需重新建模,节省了大量的人力物力。最后,需要指出的是,本文所用的PLS建模方法是比较成熟的技术,虽然尚不具有增量学习的能力,即如果有新的数据需要对模型进行更新,则需要把新旧数据合在一起重新训练模型。所谓增量学习能力是当新的数据可以用于对模型进行改进或修正时,只需要之前的模型知识而不需要把旧的数据和新的数据合在一起重新对模型进行训练。增量学习对数据非常大的情况显然非常有益。学者对支持向量机(SVM)和RBF 神经网络都发展出了有增量学习能力的算法。也有学者提出了有增量学习能力的PLS方法,虽然其可靠性尚需在实际工业应用中充分验证,仍然值得关注。
致谢:本工作是在无限极(中国)有限公司的资助下完成的,还受益于国家自然科学基金(61633006)。
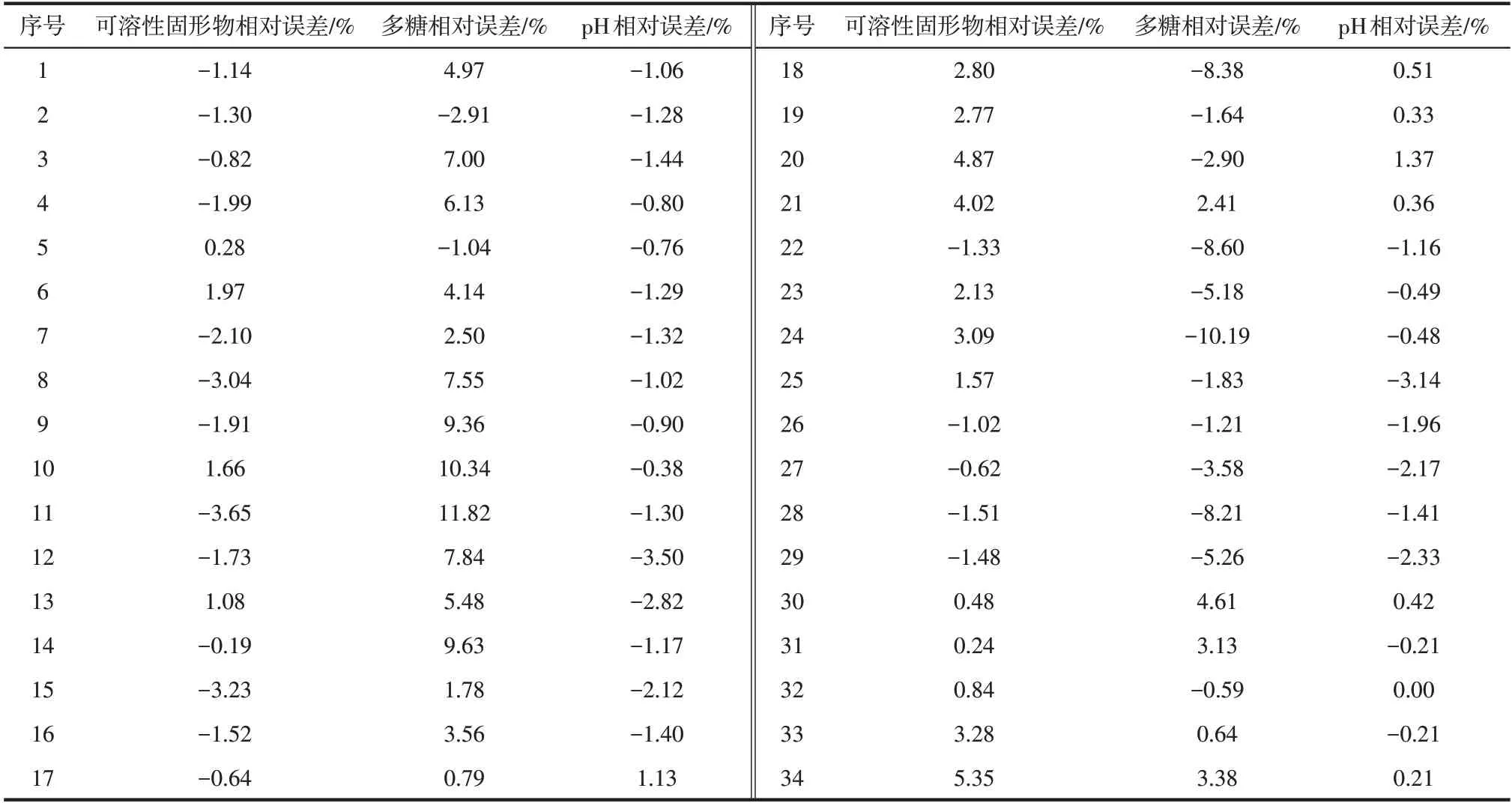
表7 盲样可溶性固形物、多糖、pH预测结果
