基于机器学习算法的脉冲星探测
2020-08-15周宇
摘 要:脉冲星是一种具有极大的科学价值的中子星。其在旋转时,地球上可探测到其发射的无线电,而且这种辐射存在周期性。对脉冲星的分类主要采用机器学习算法,各种算法表现不同。该研究对K邻近,决策树,朴素贝叶斯,梯度提升树算法对脉冲星信号进行了二分类,基于F1值和AUC值评估模型,算法对脉冲星的旋转轨迹进行研究,以此来判定各种分类算法的表现,结果显示对于未调参的算法,逻辑回归表现最好,梯度提升树其次。K邻近和决策树表现相对较差。
关键词:脉冲星;脉冲星候选样本;机器学习;分类算法;二分类
中图分类号:TP181;TP391.41 文献标识码:A 文章编号:2096-4706(2020)07-0076-04
Pulsar Detection Based on Machine Learning Algorithm
ZHOU Yu
(Xuzhou University of Technology,Xuzhou 221018,China)
Abstract:Pulsar is a neutron star with great scientific value. When it rotates,the radio it sends can be detected on the earth,and the radiation is periodic. The classification of pulsars mainly uses machine learning algorithm,and each algorithm has different performance. In this study,K-neighborhood,decision tree,naive Bayes,and gradient lifting tree algorithm are used to classify pulsar signals. Based on the evaluation model of F1 and AUC values,the algorithm studies the rotation path of pulsar,so as to determine the performance of various classification algorithms. The results show that for the algorithm without parameter adjustment,logical regression is the best,and gradient lifting tree is the second. K-proximity and decision tree performance are relatively poor.
Keywords:pulsar;pulsar candidate samples;machine learning;classification algorithm;binary classification
0 引 言
隨着现代搜索设备性能的不断提升,可以接收到更弱的信号,到目前为止,候选的脉冲星信号多达100万以上[1,2]。关于脉冲星候选样本分类方法的发展历史和发展状态主要有人工识别和机器学习分类算法两种方式。但是人工识别方式太过繁琐,容易出错。机器学习分类算法种类繁多,需要研究哪一种算法更适合用于识别脉冲星。基于此,本文基于Kaggle上公布的脉冲星探测数据集,应用主要的几种分类算法对数据集进行研究。通过研究分析逻辑回归和梯度提升树这两种算法对识别脉冲星精确度较高。
1 相关知识介绍
1.1 机器学习
机器学习是人工智能的一个分支,作为人工智能的核心技术和实现手段,通过机器学习的方法解决人工智能面对的问题。机器学习关注的是计算机程序如何随着经验积累,自动提高性能。他同时给出了形式化的描述:对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验而自我完善,那么就称这个计算机程序从经验E学习。[3]
1.2 各类算法介绍
逻辑回归:logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。[4]
K邻近算法:K近邻(K-Nearest Neighbor,KNN)算法,是一个理论上比较成熟的方法,同时也是最简单的机器学习算法之一。K邻近算法的描述是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。决策树(Decision Tree)通过把数据样本分配到某个叶子节点来确定数据集中样本所属分类,由三个节点:决策节点、分支节点和叶子节点组成,因此称之为决策树[5]。在机器学习中,决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,NBC)发源于古典数学理论,有着坚实的数学基础以及稳定的分类效率[6]。同时,NBC模型需要估算的参数很少,对缺失数据也并不敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为使用NBC模型假设的属性之间是相互独立的,而这个假设在实际应用中往往是不成立的,这些都给NBC模型的正确分类带来了一定影响。
2 研究过程及方法
2.1 數据说明与预处理
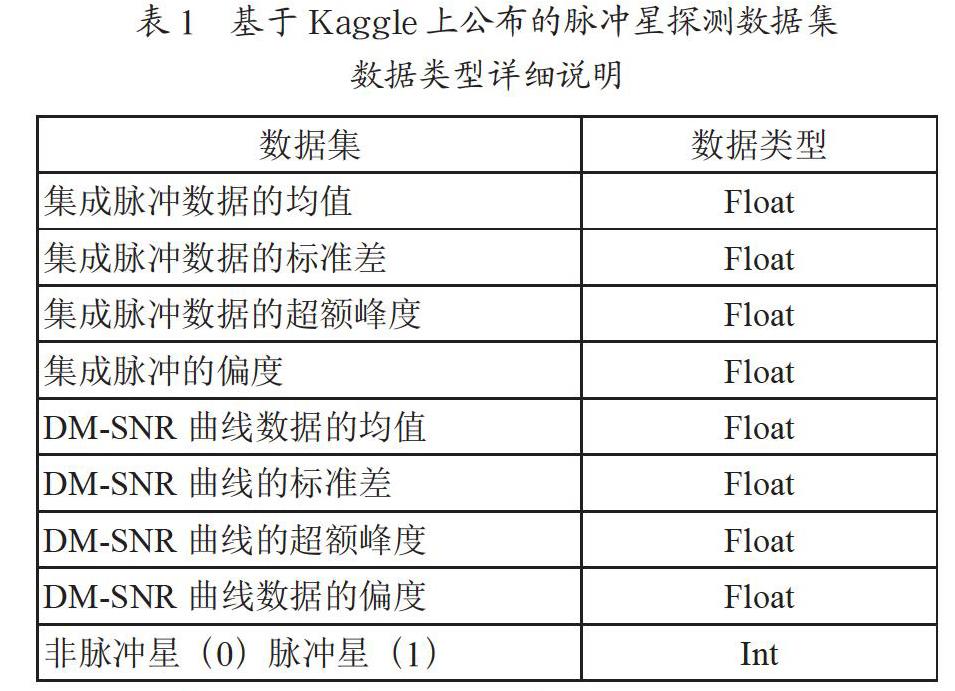
本案例基于Kaggle上公布的脉冲星探测数据集,数据集包含由射频干扰引起的虚假脉冲星样本和真正的脉冲星样本,由8个连续变量和1个离散变量组成,前4个连续变量是集成脉冲探测数据的各个统计量,后4个连续变量是从DM-SNR曲线获得的统计量,离散变量表示案例是否为脉冲星,如表1所示。
注意到各列均无缺失值,无需进行缺失值处理。为方便调用,我们将各列命名简化。代码如下:
fromsklearn.model_selection import train_test_split,cross_val_score,cross_val_predict
x=data.drop('target',axis=1)
y=data['target']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,radom_state=30)
将数据集随机划分为训练集和测试集,其中70%为训练集,30%为测试集。
2.2 过采样处理
下面探讨正类(脉冲星,1)和负类(非脉冲星,0)分布的均衡情况。
注意到正类样本与负类样本分布极不均衡,这可能会导致训练后模型只适应多数类而不适应少数类的情况,在这里应用SMOTE进行过采样处理。并应用collections包中的Counter()函数检查过采样后样本的类别分布。可以看到,过采样后正类和负类分布均衡。
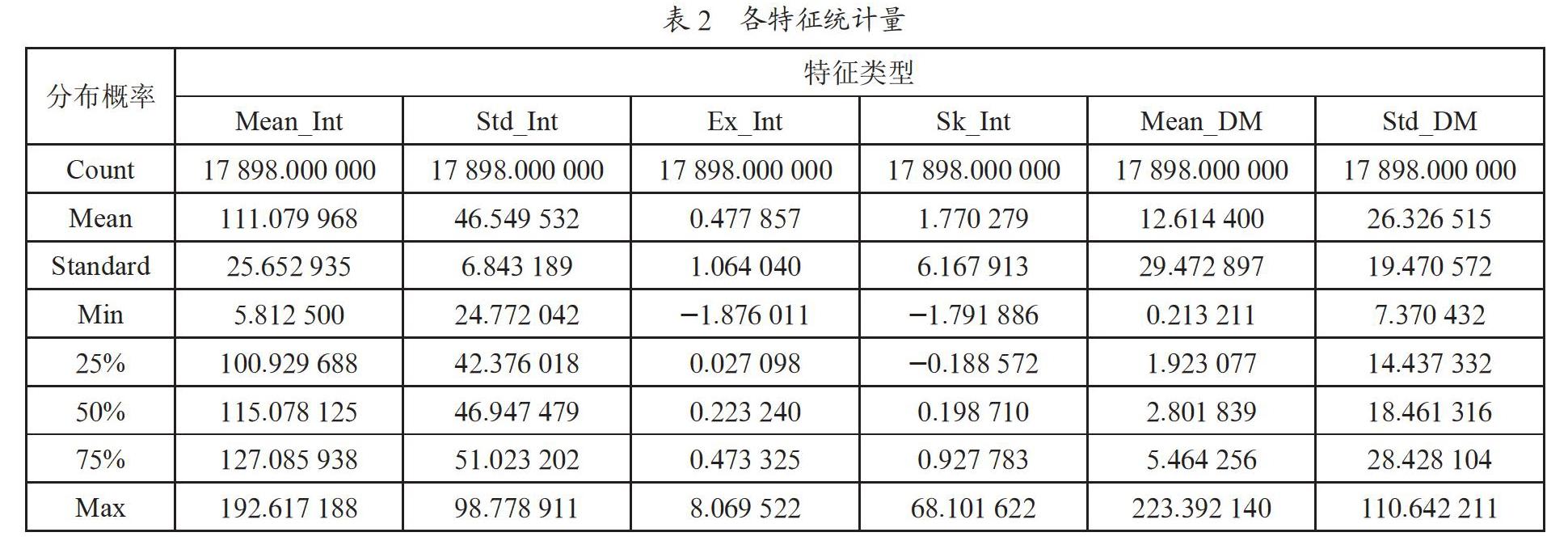
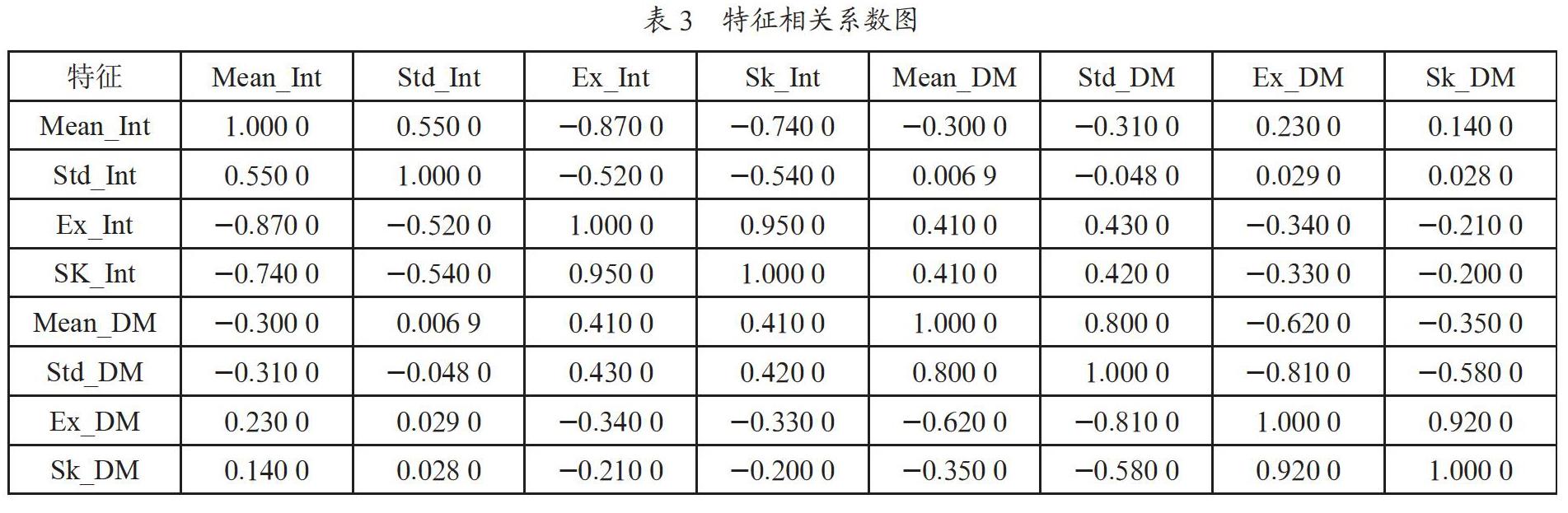
下面我们生成各特征的统计量,如表2所示。注意到各特征均具有明显的方差,这保证了其被用于分类的有效性。下面我们进一步分析,作出特征相关系数表,如表3所示。
注意到Mean_Int与Ex_Int,Mean_Int与Sk_Int,Ex_DM与Std_DM,Sk_Int与Ex_Int,Sk_DM与Ex_DM,Std_DM与Mean_DM均表现出较强的相关性,但由于本案例中特征较少,我们先不进行特征选择。在最后尝试用特征重要性剔除部分特征,并比较其与未剔除特征算法的优劣。
2.3 分类算法训练
下面我们应用逻辑回归、K邻近、决策树、朴素贝叶斯和集成算法梯度提升树进行训练,输出结果包括召回率、精确率、F1值、准确率、运行时间、AUC值、混淆矩阵、ROC曲线。
我们首先对各算法应用默认参数进行分类,为简化代码,我们将模型拟合和结果输出整合在一个函数中。需要注意的是,sklearn.metrics中的recall_score()、precision_score()等函数的计算基于标签值0表示负类,1表示正类这一事实,正类即为我们关注的类,如疾病监测中的患病者、金融风险检测中的异常交易等,在本文中为脉冲星。若0表示正类,1表示负类,则上述函数输出的召回率、精确率的分子为分类正确的负类,而非分类正确的正类。
我们注意到Class列0表示非脉冲星,1表示脉冲星,因此无需调整标签,可直接应用如上函数。若要提高输出结果的准确性,还可采用cross_val_score()进行多折交叉验证。
2.4 结果输出与分析
输入要应用的算法,运行函数,对于脉冲星探测问题,由于其巨大的科研价值,我们首先希望能够将潜在的脉冲星都探测出来,即关注预测正确的脉冲星占真正脉冲星数量的比例,这里对应着召回率Recall,注意到逻辑回归和梯度提升树的召回率较高。然而,在应用机器学习算法得到分类结果后,科学家进一步验证被预测为脉冲星的数据也需要耗费较大的人力物力,因此我们也希望预测为正的结果尽可能准确,即关注预测正确的脉冲星占所有预测为正的比例,这里对应着精确率Precise。注意到逻辑回归和梯度提升树精确度也较高。
在这种情况下,我们需要对召回率和精确率进行综合。一般而言,F1值和AUC值能够描述模型的综合效果。我们发现在F1值上,逻辑回归表现最好,梯度提升树其次;在AUC值上,逻辑回归表现最好,梯度提升树其次,K邻近和决策树表现不佳。因此我们认为:如果从F1值和AUC值的角度评估模型,逻辑回归表现最优,其次为梯度提升树。我们接下来的分析也主要基于F1值和AUC值评估模型。
输入要应用的算法,运行函数:
fromsklearn.linear_model import LogisticRegression
fromsklearn.neighbors import KNeighborsClassifier
fromsklearn.tree import DecisionTreeClassifier
fromsklearn.naive_bayes import GaussianNB
fromsklearn.ensemble import GradientBoostingClassifier
models={'逻辑回归':LogisticRegression(random_state=1),
'K邻近':KNeighborsClassifier(),
'决策树':DecisionTreeClassifier(random_state=1),
'朴素贝叶斯':GaussianNB(),
'梯度提升树':GradientBoostingClassifier(random_state=1)
}
forn,m in models.items():
classification_model(n,m,x_train_sm,y_train_sm,x_test)
从混淆矩阵上来看,各算法具有一定差异,但不显著,下面我们输出各指标结果进行对比,如表4所示。
3 结 论
本案例中我们应用了逻辑回归、K邻近、决策树、朴素贝叶斯、梯度提升树算法对脉冲星进行了二分类,基于F1值和AUC值评估模型,对于未调参的算法,逻辑回归表现最好,梯度提升树其次。K邻近和决策树表现相对较差。
我们选取K邻近和决策树调参,调参后二者性能均获得提升,K邻近算法F1值从0.684 7提高到0.695 9,AUC值从93.78%提高到95.13%,决策树F1值从0.747 7提高到0.856 9,AUC值从91.58%提升到96.48%。K邻近性能提升相对不明显,原因可能是我们为节省运算时间限制了其需调参数的取值范围。
我们选取了F1值最大的模型——调参后的决策树模型探究特征的重要性,发现Ex_Int(集成脉冲数据的超额峰度)对结果有决定性影响,Std_DM(DM-SNR曲线数据的标准差)有较小影响,而其他特征近无影响。因此我们仅提取Ex_Int与Std_DM作为特征组成新的训练集,使用逻辑回归、K邻近、决策树、朴素贝叶斯、梯度提升树再次进行训练后发现:使用两个特征训练的模型相比于全特征训练的模型,可以实现近似的分类效果。
参考文献:
[1] BATES S D,BAILES M,BARSDELL B R,et al. The High Time Resolution Universe Pulsar Survey - VI. An artificial neural network and timing of 75 pulsars [J].Monthly Notices of the Royal Astronomical Society,2012,427(2):1052-1065.
[2] LEVIN L,BAILES M,BATES S D,et al. Radio emission evolution,polarimetry and multifrequency single pulse analysis of the radio magnetar PSR J1622?4950 [J].Monthly Notices of the Royal Astronomical Society,2012,422(3):2489-2500.
[3] KEITH M J,JOHNSTON S,BAILES M,et al. The High Time Resolution Universe Pulsar Survey-IV. Discovery and polarimetry of millisecond pulsars [J].Monthly Notices of the Royal Astronomical Society,2012,419(2):1752-1765.
[4] 王东刚.残余引力波:引力子、真空与规则化 [D].合肥:中国科学技术大学,2016.
[5] 刘良端.双中子星并合产生的电磁信号研究 [D].南京:南京大学,2016.
[6] 张璐.高频引力波电磁諧振效应的最优参数选择与噪声初步分析 [D].重庆:重庆大学,2016.
作者简介:周宇(1979.06—),男,汉族,江苏徐州人,工程师,硕士,研究方向:计算机。
