矿山设备预测性维修大数据分析系统的建设
2020-08-15王晓云
王晓云
摘 要:本文介绍了大数据分析系统概念及在矿山设备预测性维修中的应用,形成一套符合应用实际的矿山设备预测性维修大数据分析系统,其中包括前端数据采集、中层数据传输与存储(状态监测)、后端数据分析及系统优化(故障诊断、状态预测、维修决策)等。预测性维修以“相似学模型(Similarity Based Modeling - SBM)”的大数据设备诊断技术为基础,结合设备故障的历史和现状,参考运行环境及其它同类设备的运行情况,采集数据、挖掘建模,对设备运行情况进行综合判断分析,提前判断设备内部可能出现故障和异常的情况,确定预测隐患的发展趋势,提出防范措施和治理对策,进而延长设备使用时间,降低成本、提高产能。
关键词:大数据分析 预测性维修 相似性建模算法 数字化双胞胎
中图分类号:TD67 文献标识码:A 文章编号:1674-098X(2020)06(b)-0006-04
近年来,国务院印发了一系列政策措施推进大数据发展,其中包括《关于深化“互联网+先进制造业”发展工业互联网的指导意见》中提到“开发工业大数据软件,聚焦重点领域,围绕生产流程优化、质量分析、设备预测性维护、智能排产等应用场景,开发工业大数据分析应用软件,实现产业化部署”。矿山设备预测性大数据分析系统的建设是以“降本增效”为目标,以实现传感器、设备和生产系统的自动化和智能化为手段,在数据监测、可视化、基本统计计算、超限报警的基础上,更好地利用收集的数据,基于相似性算法,针对每台设备进行模型数据训练,建立每一台设备专有的数据模型,利用大数据分析结果预测性诊断设备潜在故障,达到提升安全保障、减少设备非计划停机、提高维修效率、降低维修成本、提高设备运用效率的结果。
1 大数据分析概念
1.1 大数据分析概论
大数据的特殊之处主要体现于:体积、速度、质量。其中体积是指由于数据格式的多样化造成的数据存储指数级增长;速度与数据的变化率有关;质量体现在数据的多种格式存储,这种情况下,应该考虑如何处理各种格式的数据[1]。
大数据分析主要遵循三个基本概念。
(1)大数据分析是宏观数据分析,需要通过充分观察所有收集数据整体的本质、特征、属性及规律,而非通过样本围观观察,否则将切断数据和现象之间的联系,无法实现大数据分析的目的。
(2)在大数据时代,面对大量数据的挑战,知道什么比知道为什么更重要。大数据分析在数据采集的基础上,通过不同算法将数据进行清洗、分析,最终实现数据挖掘和预测分析。
(3)大数据分析偏向于发现事先不知道的新模式及目前未知的相关性,通过利用可能发现的新模式及未知相关性探索即将发现的事件本质,过程中时间和成本的意义将重于所谓准确的结果。
1.2 大数据分析应用
1.2.1 数据挖掘
大数据分析的理论核心就是数据挖掘。数据挖掘即从数据获取到深度学习,通过机器深入数据内部去挖掘价值。其中本文大数据分析系统中数据收集汇总后采用的算法是相似性建模算法。
1.2.2 预测性分析
预测性分析及利用数据挖掘的结果做出预测性判断。预测性维修系统结合大数据分析结果形成动态的报警限值,对设备状态进行预判。
2 矿山设备预测性维修系统建设意义及存在问题
2.1 建设意义
目前大部分设备维修主要以故障维修和计划性检修为主。
(1)故障维修,又称事后维修,如设备发生部分或全部故障后再修理,是一种非计划性的、纯被动的维修方式。这将对正在运行的设备带来破坏,极大降低设备的生产效率;这种盲目、失控的状态无法对维修计划进行安排,将造成备品备件库存积压严重或急缺无法及时维修。
(2)计划性检修,又称预防性检修,针对设备的维修间隔期制定维修计划,按规定的时间间隔进行停机检修,这样可以消除可能的和隐藏的故障,预防设备未知的损坏、继发性毁坏。但是这种维修方式会由于频繁维修造成维修资源浪费、造成生产和管理的矛盾激化,降低设备可用性或生产效率。
矿山设备预测性维修是基于以上两种维修方式缺点采用的一种新兴的维修方式。在机器运行时,通过采集设备运行相关数据,初步获取设备状态信息。对其重要部位进行不间断的状态监测和故障诊断,预测设备未来的发展趋势,提前预测设备故障模式以制定有效维修计划,确定设备修理时间、内容、方式和必需的技术和物资支持。
这种预测性维修方式包含状态监测、故障诊断、故障预测、维修决策支持和维修活动。存在以下优点:
①以设备实际状态为依据,减少可能出现的密集维修,延长了维修周期,提高设备利用率的同时也节约维修费用。
②预先诊断得出潜在故障,有效避免可能爆发的继发性或突发性的意外事故,保证安全生产同时降低生产损失。
③对维修资源进行宏观调控,减少备品备件库存和积压,大幅降低维修费用。
④提前安排生產维修计划,最低限度降低维修与生产中存在的设备使用矛盾,优化排产。
2.2 存在问题
由于设备预测性维修要通过状态监测、故障诊断、故障(状态)预测进而实现维修决策。但目前设备状态数据监测手段及能力不足,无法对所有设备的实时数据进行全面采集和分析。
(1)因生产控制设备多数购置时间较早,设备厂家不同,没有统一的接口规范,造成设备信息采集困难,急需对传感、控制层进行增补或完善。同时,也没有统一的监测监控平台进行采集和集中控制,系统间、设备间的直接沟通和综合利用还有很大的提升空间。
(2)数据的二次分析和利用不充分。对已经采集到的数据,未能充分的分析和挖掘,不能及时用数据反映和预测生产及设备的实时状态,无法进行全面准确预测性维修,会在维修中存在事后维修、过度维修或欠维修情况,影响维修效率和成本。
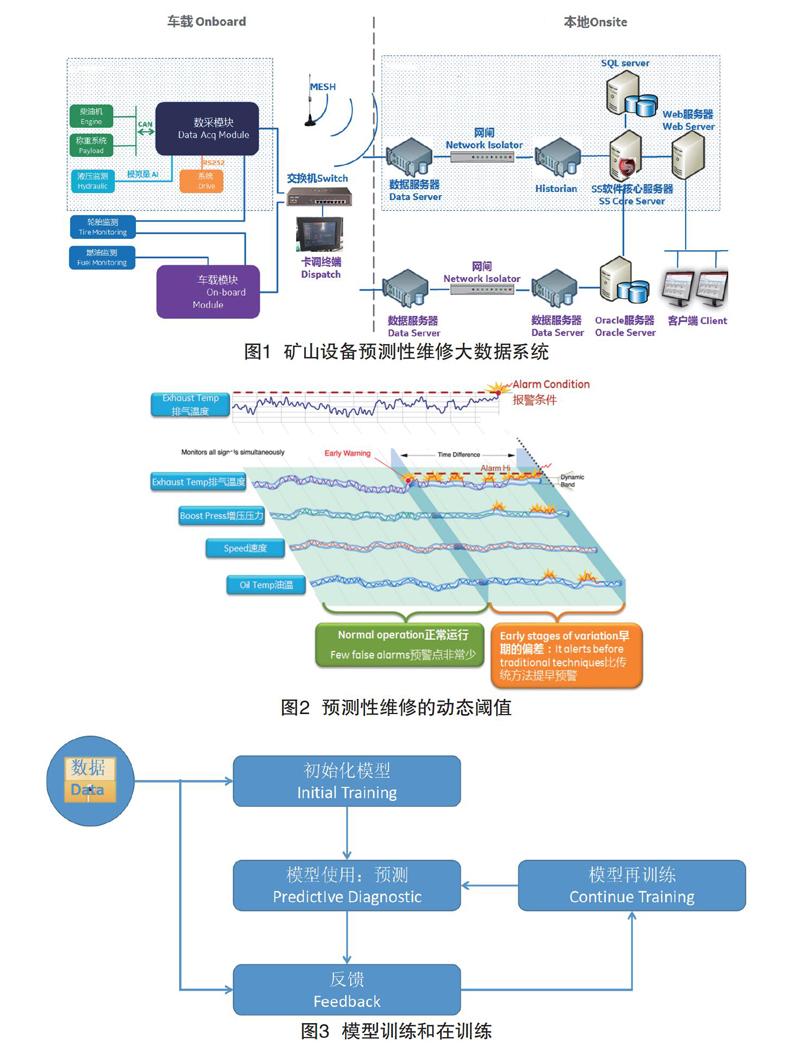
3 矿山设备预测性维修大数据系统的建设方案
本系统采用“相似学模型”的大数据预测诊断分析技术,对所有采集数据进行实时分析。以MT4400矿用卡车为例(如图1):预测性诊断将通过柴油机、称重系统、液压监测系统、胎压监测系统、燃油监测系统等多个传感器提供的数据,集中由数采模块汇集,获取每台设备的历史数据,进行模型匹配、数据清洗,按照现行工况获取正常运行数据训练模型,结合当前状态及模型训练结果,并形成动态的报警限值。这样即使设备没有满功率/满负荷运转,仍可预判设备异常,在故障早期报警,及时获得维修维护,避免设备发生不可逆损伤或意外停机[2]。
3.1 数据采集
3.1.1 柴油机的CAN接口数据
通过从柴油机到数据采集模块的线束改造,以读取发动机数据,通过数据采集模块发送到工控机。采集以下7个数据点:坐排前部进气温度、机油压力、柴油机转速、柴油机力矩、燃油温度、冷却液压力、冷却液温度。预期可实现柴油机以下方面的预测性诊断:
(1)涡轮增压器:增压不足或机械磨损;
(2)冷却系统:冷却损失;
(3)燃油系统:温度/压力异常、燃油稀释(机油/水)问题。
3.1.2 称重系统的CAN接口数据
新增称重系统,读取装载重量和悬挂压力。采集以下6个数据点:载重、倾角、左前悬挂压力、右前悬挂压力、左后悬挂压力、右后悬挂压力。预期可实现以下故障的预测性诊断:
(1)悬挂的压力异常、泄漏方面的预测性诊断;
(2)结合其他信息可对称重系统的传感器故障进行判断。
此外,称重系统的数据也作为模型输入,帮助进行电动轮电气、制动、轮胎方面的预测性诊断。
3.1.3 轮胎监测系统的网口数据
安装轮胎监测系统,实现将轮胎检测系统数据传输至卡车工控机。采集以下12个数据点:左前轮胎压力、右前轮胎压力、左后轮胎1压力、左后轮胎2压力、右后轮胎1压力、右后轮胎2压力、左前轮胎温度、右前轮胎温度、左后轮胎1温度、左后轮胎2温度、右后轮胎1温度、右后轮胎2温度。可结合称重系统数据,对轮胎的渐进性故障进行预测性诊断:
(1)轮胎压力异常;
(2)轮胎温度异常。
3.1.4 电传系统的RS232串口数据
基于串口提供数据,进行线束的改造,通过数据采集模块读取数据并传到工控机。采集以下11个数据点:加速踏板位置、电制动状态、左后轮马达速度、左后轮马达力矩、右后轮马达速度、右后轮马达力矩、母线电压、母线电流、启动电池电压、风冷温度。结合称重系统、采油机数据,可进行如下诊断:
(1)电动轮的基本监控状况;
(2)控制柜冷卻。
启动电池电压可用于柴油机不能正常启动相关故障的诊断,包括充电机、皮带的异常。
3.1.5 液压压力的模拟信号
改造卡车上的液压管路并且安装油压、油温传感器将数据通过AI接口发送到数据采集模块。采集如下7个数据点:举升压力、转向压力、前制动压力、制动蓄能器压力、后制动压力、驻车制动压力、液压油温。可进行压力相关的预测性诊断:
(1)漏油、压力损失、转向异常;
(2)结合卡车工作状态(柴油机、称重系统、电气数据),诊断压力传感器本身的故障。
3.2 数据传输与存储
通过矿区现有的无线网络将移动设备的数据从卡车工控机上传送到本地HISTORIAN服务器。通过车载数据采集终端将数据经CAN2.0B总线实时传送给车载工控机,传送周期为500ms。在工控机上安装数据采集器程序,数据采集器程序支持断点续传,工控机上的数据采集器通过4G网络,将工控机上的设备数据,传送到HISTORIAN服务器上。HISTORIAN实时数据服务器将作为存储采集的所有实时数据源的核心数据库,用于检测分析设备应用状态。为了实现信息传输和网络运行的安全保障,同时部署单向物理隔离网闸,将卡车生产侧的网络与预测性分析系统进行网络隔离,有效防范可能发生的内部和外部的非法攻击。
HISTORIAN对数据的存储是以文件形式存储,通过采集、存储及分发的存储机制,使历史数据具有高效、可用及开放的特性,实现数据层级结构化、高压缩、安全、强健的冗余机制。
3.3 数据分析
预测性维修的关键技术在于预测分析技术。本系统采用了相似性建模算法,该算法是一种多参数预测方法,其他建模技术如主成分分析和神经网络等,在面对品质不高的数据时会很困难。很多建模技术要做大量计算,相似学模型技术在现成的商业化Intel硬件以及普通的微软软件的运行环境下,即可根据每隔5~10min的采集数据实现数千个数据点的高级建模。设备的建模被划分成了多个逻辑模块,每个模块包含互相关联的参数以及进行预测所需要的参数。根据每个模块,可以预测性地判断设备性能降低的主要因素,并根据相应的设备组件定位故障。同时系统针对一台设备、利用其正常工作状态的多个测点的历史数据,为每台设备建立独立的数据模型。由于使用了来自于多个传感器的多种数据,可以有效抑制干扰和容错。
图2阐述了常规报警方式与预测性诊断的区别。
常规报警方式设置固定的报警条件或报警触发限值,只有监测到的状态值超过报警限值时,才会触发报警。此报警触发限值的设置不可过低,以免造成过多的误判断,报警频发,引起不必要的停工以及人工检查;另一方面,限值的设置也不可过高,否则将导致设备已经发生不可逆转或巨大的损伤。当设备没有满功率/满负荷运转时,即使设备有损伤,也由于没有达到触发条件,无法触发报警。
针对MT4400矿用卡车的不同子系统有效收集所有数据进行大数据分析进而预测性诊断,现有模型可以涵盖如下子系统的诊断:
(1)柴油机子系统:涡轮增压器、空气过滤器、后冷却缸、油缸、冷却系统、润滑油系统;
(2)悬挂子系统:悬挂、轮胎;
(3)液压子系统:制动器冷却、制动器液压、转向;
(4)传动子系统:机械变速器;
(5)电传驱动系统:电机、传动装置、发电机。
3.4 系统优化
系统优化是基于“数字双胞胎”理论上对设备预测性维修的完善。
“数字双胞胎”[3]即数字孪生,可以在虚拟数字模型和现实物理对象间建立映像。包括产品数字双胞胎、生产工艺流程数字双胞胎、设备性能数字双胞胎三个阶段,以上三项前后形成不断循环,服务于产品全生命周期。其中设备数字双胞胎用于故障预测、健康管理及预测性维护,并回馈运行信息用以优化设计、改善产品性能。
在设备使用过程中,各参数都可能发生相应的变化:
(1)系统会根据变化的情况,使用新的历史数据,对模型进行再训练:
(2)工作环境条件超出预定范围,设备负载不再满足原始设定;
(3)设备出现新的工作状态,不确定能否在正常的工作条件下健康运行。
根据“数字双胞胎”的概念,通常在初始模型训练完成后,在后续的使用过程中继续模型的维护性训练,使用新的数据对模型进行再训练和优化。
4 结语
大数据分析与预测性诊断维修的完美结合实现了矿山设备预测性维修,这个案例可复制推广到其他露天煤矿,提升我国露天煤矿设备管理水平,但预测性维修只是大数据应用的冰山一角。实际上,近年来数据集成、数据清洗、数据统计[4]以及各类聚类算法、分类算法、回归算法、关联算法、增强算法的衍进,从数据获取到深度学习全方位提升大数据分析的使用效率、应用领域,下一步可以以国家战略、市场需求、人民需要为牵引,不断促进大数据在农业、能源、交通、醫疗等领域融合发展,同时与工业互联网、工业大数据、工业云协同发展,推动制造业数字化、网络化、智能化转型[5]。
参考文献
[1] 景宇.基于大数据分析的农化产品物流网点规划[D].南京邮电大学,2019.
[2] 邓筑鑫.预测性维修分析系统在露天煤矿设备上的应用[J].电脑编程技巧与维护,2017(21):91-94.
[3] 华应强,王启发.抽水蓄能机组数字双胞胎(运维检修)研究与实施[J].黑龙江水利科技,2019,47(6):136-138.
[4] 国家工业信息安全发展研究中心.大数据优秀产品案例[M].北京:人民出版社,2017.
[5] 梁栋,张兆静,彭木根.大数据、数据挖掘与智慧运营[M].北京:清华大学出版社,2018.
