基于时间衰减的物品相似度协同推荐算法改进
2020-08-14陈昕宇杨帆
陈昕宇 杨帆
摘 要:推荐系统作为信息过滤技术的典型代表,是目前解决信息过载问题的重要实现手段。其中协同过滤算法是目前推荐系统中应用最广泛的推荐算法之一。基于物品的协同过滤推荐算法,实质上是在邻近相似度计算的基础上,根据用户的历史行为特征,给用户推荐与用户之前喜欢物品相似物品的过程。文章在传统的基于物品推荐的协同算法基础上,针对用户-物品评分矩阵以及数据处理时可能存在的数据稀疏性问题,辅以时间衰减函数与修正的夹角余弦,对传统物品相似度计算方法做出改进,经过实验证明,基于时间衰减的物品相似度协同推荐算法可提高推荐结果准确性。
关键词:时间衰减;物品相似度;协同过滤推荐;相似度计算;推荐准确性
Abstract:The recommended system,as a typical representative of the information filtering technology,is an important one of realization methods. The collaborative filtering algorithm was applied most extensively compared with other algorithms. The collaborative filtering algorithm based on items and similarity calculation between item scores of uses is a process which recommends users their similar items liked by users before with their history behavior characteristics. Based on the traditional collaborative algorithm on item recommendation,aiming at the problem of data sparsity in user item scoring matrix and data processing,this paper improves the traditional method of calculating item similarity with the help of time decay function and modified cosine,experimental results show that the collaborative recommendation algorithm based on time decay can improve the accuracy of recommendation results.
Keywords:time decay;item similarity;collaborative recommendation;similarity calculation;recommendation accuracy
0 引 言
伴随着互联网用户的增多、网络互联技术的发展,网络带给了人们许多便利,而在享受便利的同时,我们也会被网络中各种各样、不计其数的信息困扰。面对信息过载问题,推荐系统应运而生,其中的核心便是推荐算法,一个推荐系统的推荐效果、推荐性能和推荐准确性,很大程度上受算法的影响。常用的推荐算法有:协同过滤推荐算法(Collaborative Filtering Recommendation)、内容推荐算法(Content-based Recommendation)[1]、相似性推荐算法(Simi-larity Recommendation)[2]、关联规则推荐算法(Association Rule Based Recommendations)[3]。
笔者一直从事Python算法方面的研究工作,本文的研究是基于物品的协同过滤算法。传统的基于物品的协同过滤算法主要依赖于用户的行为特征,也就是用户-物品评分矩阵,来计算物品间的相似程度和用户对物品的喜好程度,进而为用户推荐与用户之前喜欢的物品相似的物品。但是在传统的算法中存在很多问题:数据处理问题、算法过于依赖用户-物品评分矩阵,以及在现如今推薦系统个性化等问题。本文会针对这些问题,在计算物品相似度的基础上改进计算方法,使计算结果准确性增加,并加入时间因子增强推荐系统个性化服务[4,5]。
本文接下来内容组织如下:第1部分主要介绍传统的基于物品的协同过滤推荐算法;第2部分介绍了本文提出了改进的协同过滤算法的主要思想及处理流程;第3部分在改进的算法的基础上,进行实验验证;第4部分对全文总结。
1 基于物品的协同过滤算法
基于物品的协同过滤推荐算法的原理和基于用户的协同过滤推荐算法相似,在计算时计算的是物品之间的关系,而不是用户之间的关系,从物品本身出发,基于用户对物品的偏好找到相似的物品,然后利用K个最近邻居物品的加权来预测当前用户对这K个邻居物品的喜好程度,从而将喜好程度高的若干个物品推荐给用户。基于物品的协同过滤推荐算法实现主要有两个核心部分:计算物品之间的相似度和计算推荐结果完成向用户推荐。
1.1 算法实现流程
下载相关数据集,对初始的数据进行数据处理,分离出用户-物品评分表、物品、用户属性表等数据文件;选择基于物品的协同过滤作为算法,构建模型;根据用户对物品评分数据文件,建立用户物品倒排表,从倒排表中找出不同用户对不同物品的行为记录,并构建物品同现矩阵;计算物品(item)之间的相似度,通过计算出的相似度,得到物品之间的相似度矩阵,再对每个用户构建评分矩阵;得到物品的相似度矩阵之后,ItemCF通过公式计算用户对物品的感兴趣程度,返回用户最可能喜欢的物品。
1.2 物品相似度计算
相似度计算在数据挖掘和推荐系统中有着广泛的应用场景。主要常见的相似度计算方法有:欧几里得距离、曼哈顿距离[6]、切比雪夫距离[7]、马氏距离[8]、夹角余弦距离、杰卡德距离。不同的计算方法有着不同的使用环境和优缺点,而在基于物品的协同过滤中,主要使用欧几里得、余弦相似度、皮尔逊相似度、杰卡德相似度。
1.2.1 修正的余弦相似度
余弦相似度只计算向量的夹角,但是在数值计算时,向量夹角只能表示两向量在方向上的差距,并不能表示实际差距。特别在将目标映射到多维数值坐标中进行运算时,如果同一夹角的两个向量数值相差很大,将会出现计算偏差,所以本文采用从传统余弦相似度演变来的修正余弦相似度,并在此修正余弦相似度基础上,进行物品相似度改进计算。修正的余弦相似度计算,是对用户评分过的所有项目进行去中心化,从而减小用户对物品过好或过坏的评分所带来的影响,提高了推荐准确性。修正的余弦相似度计算公式[9]如下:
此修正的余弦相似度计算公式,是传统余弦与皮尔森系数的结合,其中Ru,i和Ru,j表示用户u对物品i,j的评分, 表示的是用户u已评级项目的平均值,即计算时未被评级的项目不采取置0而是直接忽略。
1.2.2 杰卡德相似度
杰卡德相似性系数[10]表示为集合中样本集交集个数和样本集并集个数的比值。与其他传统相似性计算公式相比,杰卡德算法弥补了余弦相似度可能忽略其他信息量以及数据稀疏性过高的不足。本文在引用杰卡德相似性系数时,在原有式子上做出了一点改变,得到了式(2)所示的加权的杰卡德相似系数计算公式。
2 基于物品相似度的改进
2.1 加入时间因子
如今的推荐系统在个性化服务方面,必须具有实时性,而时间因子便能很好地体现出时间效应这方面。由于用户最近的行为最能表达用户当前的兴趣,所以在相似度计算时加入时间衰减函数[11]。时间衰减函数又多种形式,本文中的时间衰减函数公式如下:
其中tui和tuj分别表示用户u对物品i和j产生的行为时间。b为时间因子,在这里取b=0.5。
2.2 算法改进步骤
根据文中提出的问题及对问题的分析,本文提出一种基于物品相似度计算改进的推荐算法,算法步骤如下:
第一步:输入物品-用户集,并且进行预处理来建立物品-用户的倒排表;
第二步:产生物品之间的共现矩阵C[i][j],表示物品i与j被不同用户评分的矩阵;
第三步:根据用户-物品评分矩阵计算物品相似度。本文的相似度计算在修正余弦相似度的基础上融合杰卡德相似性[12]和时间衰减函数,在填补用户-物品评分数据稀疏、个性化推荐服务方面,提高了推荐结果准确性,联系式(1)、式(2)、式(3)得物品相似度计算公式如下:
第四步:返回推荐结果。
3 实验数据与结果分析
3.1 实验数据
本文采用推荐系统中常用的MovieLens数据集,下载地址为http://files.grouplens.org/datasets/movielens,其中movies.dat记录每部电影所属类型,文件rating.dat记录了用户对电影评分数据。本文使用的是其中一个较小的数据集,里面含有6 040个用户对3 900部电影的1 000 209条评分记录,评分在1至5分之间。数据集随机分为测试集和训练集两部分,训练集随机分配80%数据,测试集随机分配20%数据。
3.2 实验环境
硬件环境:Windows 10(64位)操作系统,内存4G,2.5 GHz Intel Core i5-7200U CPU。
软件环境:Python 3.8,Pycharm集成开发环境,MySQL 8.0.19,Navicat Premium 12。
3.3 评估标准
实验以推荐准确率为评估标准,准确率(Precision)表示的是在所有预测为真阳(TP)和假阳(FP)的样本中有多少样本是真阳(TP)。准确率可以用TP/(TP+FP)表示,其意义为真正的正例占总正例的比重:
检验算法的标准还有召回率(Recall)和F-measure值(又称F-score)是一种统计量,是精确率和召回率的加权调和平均,召回率公式如下:
3.4 實验结果分析
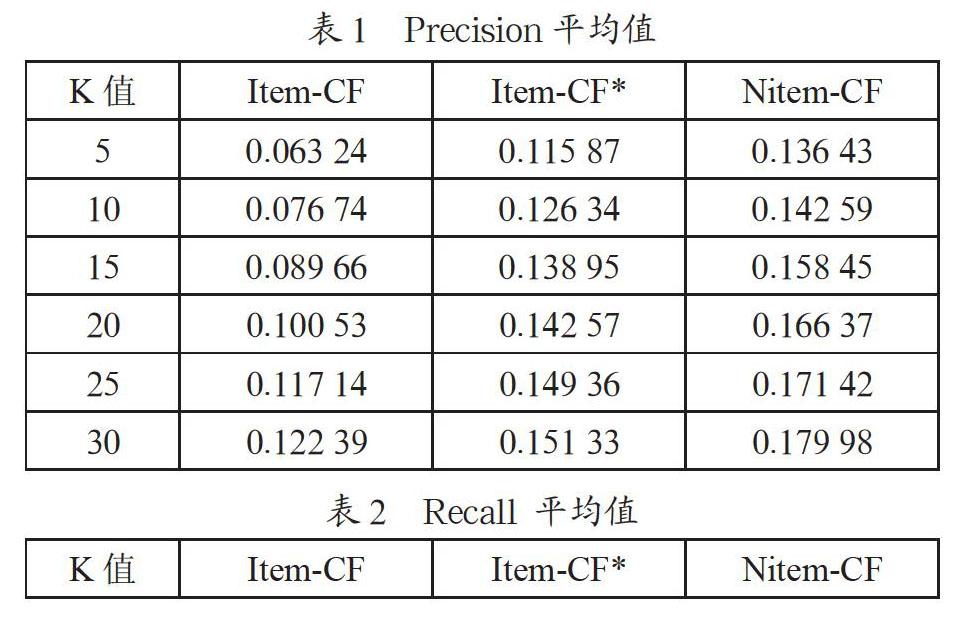
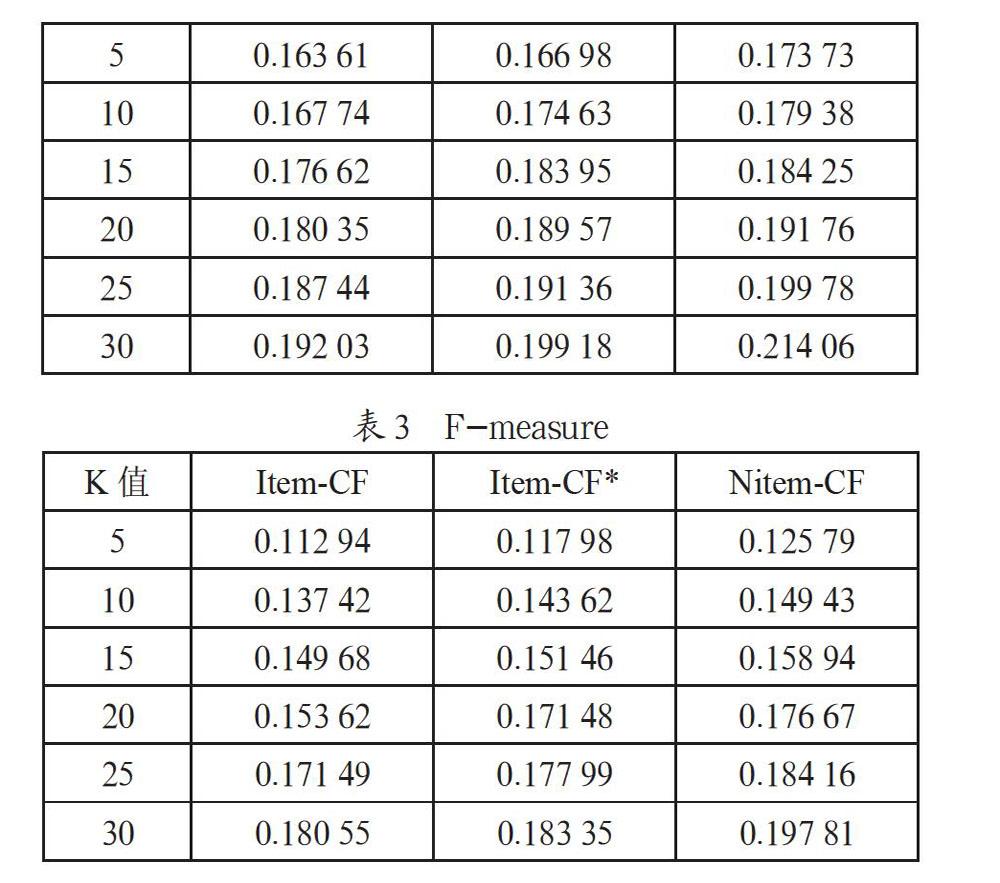
按照上述式(5)(6)(7)计算在不同K值下三种算法的精确率、召回率和F-measure值。表1表示三种算法在K值范围5~30之间,评估标准准确率的平均值;表2表示三种算法在K值范围5~30之间,评估标准召回率的平均值;表3表示三种算法在K值范围5~30之间,评估标准F-measure的平均值。
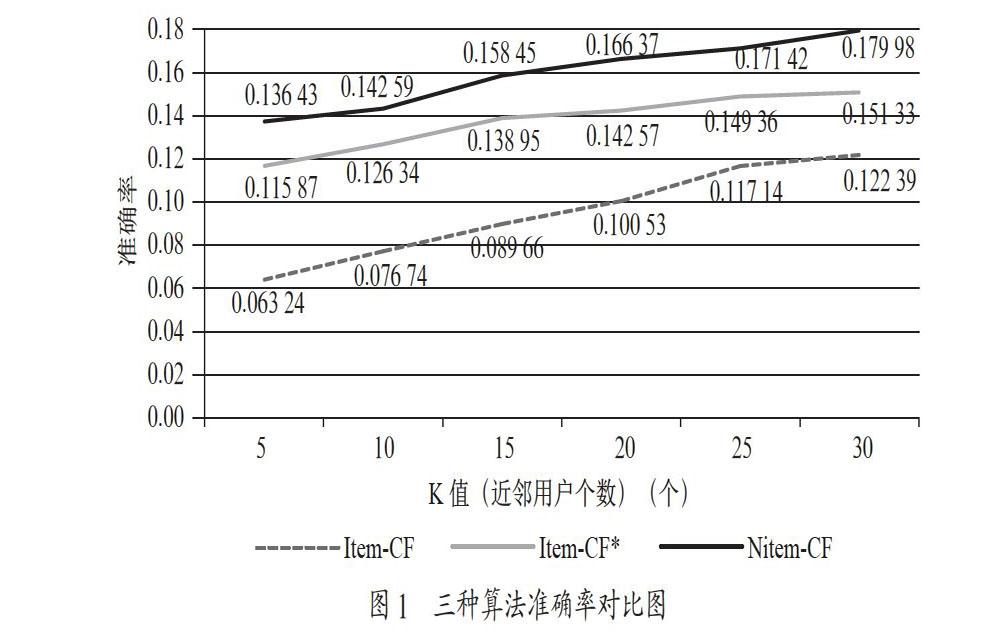
本文称改进后的算法为Nitem-CF,在本小节中,Nitem-CF算法会和传统的Item-CF算法、修正的余弦相似度算法,以推荐准确率为评估标准做对比实验。为方便起见,在文中以Item-CF*代表修正的余弦相似度算法。图1是在K值(近邻用户个数)不同,物品返回数为20的条件下,对三种不同算法得出的不同数据,作出准确率对比折线图(图1折线图中,只可以参考走势,具体数据参照表1)。
从图1中我们可以清晰地看到改进后的算法准确率要高于传统的余弦相似度算法和修正的余弦相似度算法。
4 结 论
本文在传统基于物品的协同过滤算法上,对物品相似度计算方法做了一些改进,在修正的余弦相似度的基础上,针对用户-物品评分矩阵可能会存在的数据缺失、数据集稀疏性高、用户活跃度过高等,影响用户-物品评分矩阵,进而影响推荐结果的问题,本文改进的算法在计算物品之间相似度时,融合了加权后的杰卡德相似性,并在追求个性化的同时,引进时间衰减函数,突显个性化推荐系统时效性。在实验过程中,本文采用的数据集较小,而且实验数据集单一,不能保证在其他环境下不同数据集适应此种算法。因此文中算法需要进一步进行扩展性行为实验,研究此算法能应用的场景。
参考文献:
[1] 杨凯,王利,周志平,等.基于内容和协同过滤的科技文献个性化推荐 [J].信息技术,2019,43(12):11-14.
[2] 韩志俊.基于关联规则优化的协同过滤混合推荐算法研究 [D].银川:宁夏大学,2018.
[3] VUZA D T,VLADESCU M. Solving an EMC/EMI problem occurred inside a complex programmable logic device [C]//Electronics Technology(ISSE),Proceedings of the 2014 37th International Spring Seminar on. S.l.:s.n.,2014:390-394.
[4] 刘源.基于特征距离和时间效应的上下文感知推荐技术研究 [D].北京:北京邮电大学,2019.
[5] 张宇航,姚文娟,姜姗.个性化推荐系统综述 [J].价值工程,2020,39(2):287-292.
[6] 方樂笛,李顺东,窦家维.曼哈顿距离的保密计算 [J].密码学报,2019,6(4):512-525.
[7] KISEOK LEE. Chebyshev collocation method for the constant mobility Cahn-Hilliard equation in a square domain [J].Applied Mathematics and Computation,2020:370.
[8] MOHAMMAD M N,MOHAMMAD A M,RASOOLZADEGAN A. Software defect prediction using over-sampling and feature extraction based on Mahalanobis distance [J].Journal of Supercomputing,2020,76(1):602-635.
[9] 唐积益.推荐系统中相似度计算方法的研究 [D].镇江:江苏科技大学,2015.
[10] 高文尧.基于协同过滤的推荐算法研究 [D].广州:华南理工大学,2016.
[11] 李世伟.基于协同过滤算法的推荐系统研究与应用 [D].北京:北京工业大学,2017.
[12] 袁煦聪.基于长尾理论的物品协同过滤推荐算法研究 [D].淮南:安徽理工大学,2019.
作者简介:陈昕宇(1998.05—),男,汉族,湖北枣阳人,本科,学士学位,研究方向:推荐系统、计算机软件开发;杨帆(1980.06—),女,汉族,湖北武汉人,博士,教授,研究方向:推荐系统、电子商务。
