并行随机抽样贪心算法分区的MapReduce负载均衡研究
2020-08-14黄伟建贾孟玉黄亮
黄伟建 贾孟玉 黄亮
摘 要: 针对传统MapReduce环境下Hash分区处理偏差数据时存在效率低下负载不均衡问题,采用两阶段分区,即基于并行相似随机抽样贪心算法分区。该抽样是基于Hadoop随机抽样在给定样本比率或特定置信度下的误差范围内快速且低错误率的预测key分布结果。优点在于利用MapReduce框架的并行性减少抽样开销成本,并采用一种评估模型来确定合适的抽样率,达到减少抽样开销成本和提高抽样准确性的目的。结合贪心算法分区代替Hadoop平台默认的Hash分区算法来划分中间数据,实现MapReduce负载均衡。Matlab实验仿真结果表明,并行随机抽样贪心算法分区无论从负载均衡还是执行时间上都优于原生Hadoop中Hash分区算法。
关键词: MapReduce; 负载均衡; 贪心算法分区; 并行随机抽样; 分区建模; 对比验证
Abstract: In allusion to inefficiency and load imbalance in the traditional MapReduce environment when the Hash partitioning is used to process the bias data, the two?stage partitioning algorithm?greedy partitioning based on the parallel similarity random sampling is adopted. This sampling is based on Hadoop random sampling to predict key distribution results with fast and low error rate throughout the error range of the given sample ratio or the specific confidence coefficient. The advantage of this sampling way is that the overhead costs of sampling are reduced by means of the parallelism of MapReduce framework, and the appropriate sampling rate is determined with an evaluation model to reduce the overhead cost of sampling and improve the sampling′s accuracy. The intermediate data is divided by using the greedy algorithm partitioning to replace the default Hash partitioning algorithm of Hadoop platform, so as to realize the MapReduce load balancing. The Matlab simulation results show that the greedy partitioning algorithm based on the parallel sampling is superior to the Hash partitioning algorithm in the native Hadoop in terms of load balancing and execution time.
Keywords: MapReduce; load balancing; greedy algorithm partitioning; parallel random sampling; partitioning modeling; comparison validation
0 引 言
目前,两阶分区(抽样和分区)是一种解决MapReduce处理偏差数据时存在Redcue负载不均衡问题的简单且高效的算法。文献[1]研究抽样过程影响开销与成本的各种因素,如准确率、节点个数、样本规模,并给出理论证明,为两阶段分区提供了理论支撑。有学者提出用贪心算法代替Hash算法,但其抽样采用普通系统抽样,当抽样率到达一定阈值时抽样开销成本会影响MapReduce整体性能[2]。文献[3?4]缺乏有效估计数据分布的预处理。然而很少学者在抽样过程中考虑抽样结果准确性和抽样带来的开销成本问题,所以有必要对此问题进行研究。
于是在上述学者研究的基础上对抽样分区进行优化,采用一种argMin函数方法来解决抽样开销和结果准确性之间的平衡问题。本文将针对数据倾斜问题提出一种并行相似随机抽样贪心算法分区来实现Reduce负载均衡。Matlab实验仿真结果表明,该算法在处理数据倾斜问题上能进一步优化执行时间和实现负载均衡。
1 并行随机抽样贪心算法分区模型
采用两阶段分区,第一阶段利用MapRedcue框架进行并行抽样预测Key分布制定分区方法,如图1所示。
第二阶段将贪心算法分区代替Hash分区运行MapReduce工作,如图2所示。
2 随机抽样率选择
本文提出一种评估模型,以更好地选择适当的抽样率来减少开销,并全面考虑这些受影响的因素。评估模型公式如下:
式中:函数[fi(Ei,Di,Vi)]综合考虑抽样效果,以及时间成本和变化;[α,β]和[γ]是反映这些受影响因素重要性的权重系数。
在函数[fi]中,[Ei]表示当抽样率设置为[i]时的抽样效果,文中侧重于5倍不同的抽样率:10%,25%,50%,75%,100%。因此[1≤i≤SN],[SN]表示不同的抽样率的数量,这里[SN]=5。[Ei]具体表示为当前采用的百分比与整个输入数据集的CoV(变异系数)值序列之间的差异的抽样效果。
式中:[covi,j]表示当抽样率为i时第j次抽样实验的CoV值,即错误率值;[N]为重复的实验次数。例如[cov5,j]为抽样率为100%时的CoV值。平均抽样时间[Di]为:
式中:[di,j]表示在抽样率[i]和[j]次抽样实验执行的时间,[1≤i≤SN],[1≤j≤N];[SN]表示不同的抽样率的数量。由于本文的集群组件性能是不同的,因此在并行抽样存在计算时间的变化。为了考虑这个因素,本文使用式(4)来计算变化,在抽样率[i]下用[Vi]表示为:
在实验中进行Sort和Grep基准测试,分别采用不同的抽样率,每组实验重复进行10次,在95%的置信区间根据不同抽样率对应的时间,简单地假设效率、成本、变化权重系数相同,则[α=β=γ=1]。计算其结果如表1所示。
从表1可以看出,随着抽样率的提高,数据准确性在提高,Di即抽样耗费的时间也随之增高。具体来讲,在10%抽样率的实验中,Ei的值远大于抽样率为100%的实验组。抽样率会缩短抽样时间,但无法证明输入数据的分布准确性。由表1得出在并行抽样中,在95%置信区间抽样率为25%是抽样率最合适的选择。
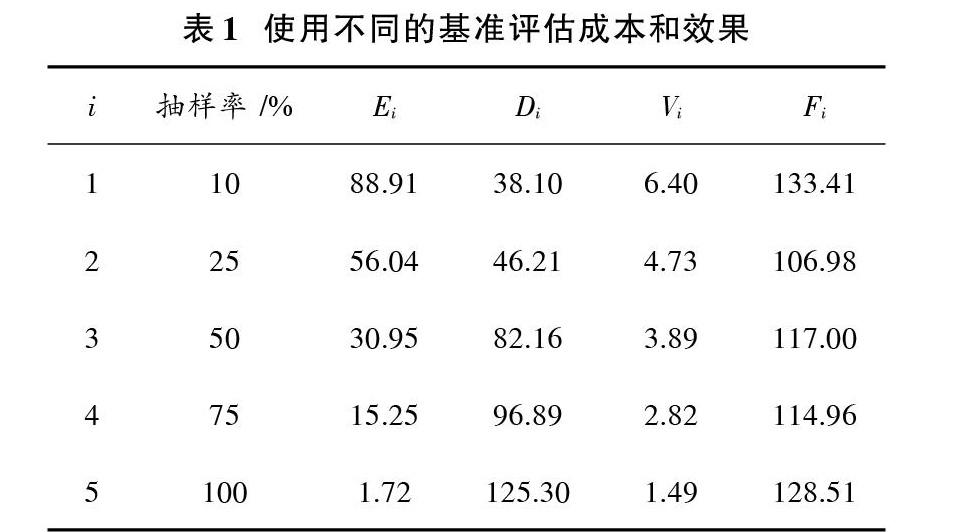
3 抽样贪心算法分区思想
贪心算法分区思想是把所有的Reduce抽象为一个整体,每个Reduce获得平均值负载则为子问题。
找出整体当中局部的最优解,并且将所有的这些局部最优解合起来形成整体上的一个最优解。贪心算法思想是根据抽样数据预测Key分布结果,求取每个Reduce负载平均值,然后为每个Reduce分配接近平均值的负载,从而达到整体的负载均衡。具体算法流程图如图3所示。
4 实驗过程与结果分析
4.1 实验环境
本文使用虚拟机软件为VMware Workstation 8.0.4 build?744019,虚拟机操作系统是CentOS?6.5,设置为单核,2 GB内存,Java开发工具版本使用JDK?1.8.0_102;Hadoop版本为2.8.1,采用zookeeper?3.4.6组件为实验平台。本实验集群包括1个NameNode和3个DataNode,其中节点可以相互通信。
4.2 实验过程
本文数据集是真实的网页数据,利用爬虫技术得到了红帽官方网站的数据并将其转化为键值对。其记录大小为128 MB~2 GB。
1) 抽样参数设置
原数据大小为652 MB,记录为13 491 498条,经上文分析得出合适的抽样率为0.25%,置信区间为0.95,错误率为0.07%,Reduce个数为5。
2) 抽样结果和分析
抽样平均花费时间为46.21 s。原数据Key类型总数为53 070 602,样本Key类型总数为10 373 686,经过实验结果表明,所抽取样本在45个Key类型与原数据类型中样本原数据相似比例近似为0.195 5。
这充分说明本文提出的并行随机抽样数据的有效性,即正确反映原数据的分布规律,为接下来分区提供有效且准确的Key分布信息。
3) 抽样准确率分析
为了验证抽样率的准确性,本文采取不同抽样来观察抽样的准确性。不同规模的数据集所需要样本规模是相同的,当样本规模增长到一个不大的阈值时,准确率的增长将非常缓慢,并在一个接近于1的值上趋于平稳[1]。
经实验证明抽样率在0.25%以后准确率的增长趋于缓慢,但随着抽样率的增加时间在增长,时间的增长速度远远超过准确率的提高速度。于是0.25%的抽样证明是有效可行的,并且并行随机抽样比普通随机抽样时间大大减少。
4.3 实验结果对比图
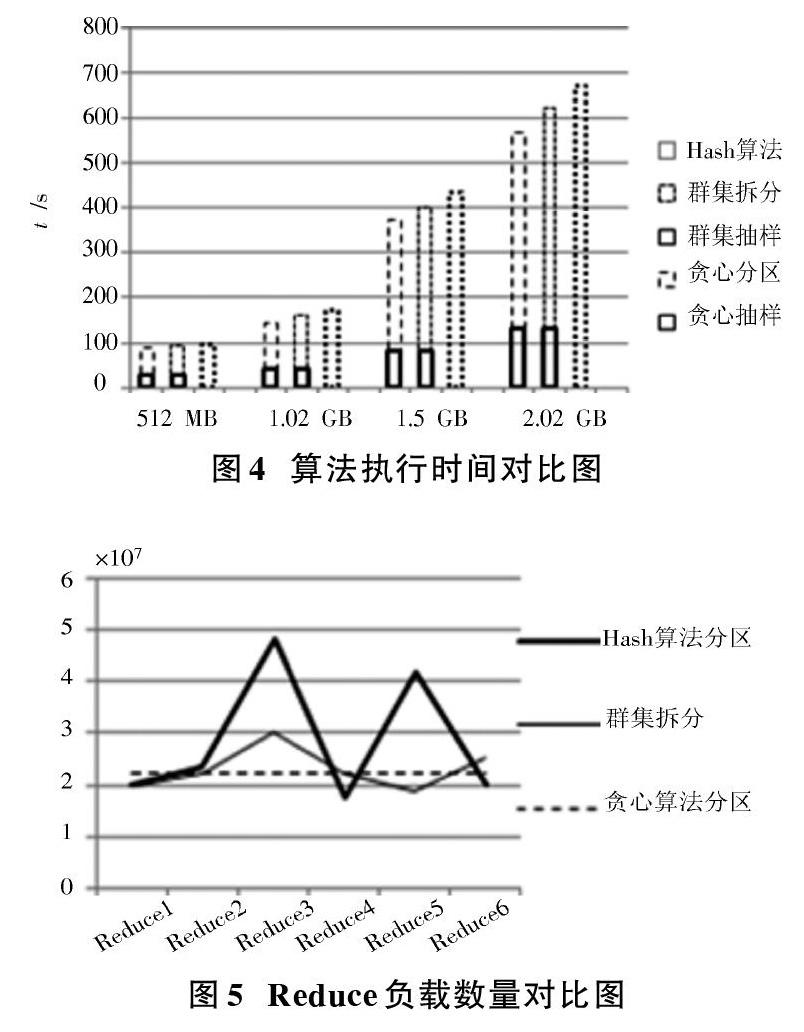
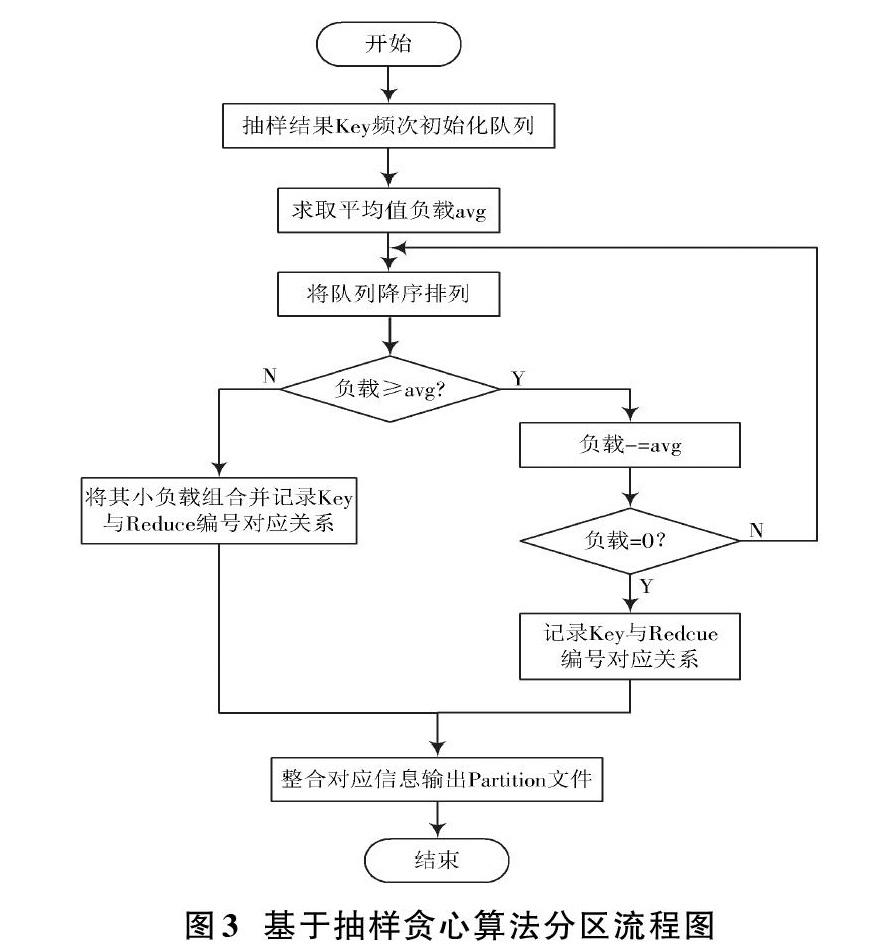
以WordCount为实例,进行实验,分别比较默认的Hash、群集拆分和贪心算法分区。从运行时间和Reduce负载均衡两个角度比较3种算法的优劣数据集抽样率为0.25,数据集为1.02 GB,Reduce个数为15,本文分区算法中群集拆分和贪心算法分区抽样时间、抽样率是相同的。3种分区算法执行时间对比图如图4所示。Reduce负载数量对比图如图5所示。
实验结果表明,数据集在500 MB左右时,3种分区算法执行时间相差甚少,Reduce负载也相对均衡。但随着数据集的增大,贪心算法优于两者,Hash分区算法不均衡,群集拆分负载相对平均值偏差较贪心算法波动幅度大。由此可见,在时间效率和负载均衡两个方面,抽样分区优于一次性Hash分区,并行相似抽样贪心分区优于群集拆分分区。
5 结 语
本文采用一种基于并行相似随机抽样贪心算法来解决传统Hash分区处理偏斜数据存在负载不均衡问题,提出一种评估模型来选择合适的抽样百分百来减少抽样时间和准确率对MapReduce性能带来的影响,根据抽样结果使用贪心算法分区实现负载均衡。
实验结果表明,并行相似随机抽样贪心算法分区不仅解决了采样抽样结果准确性和抽样带来的开销成本问题,整体分区算法在任务执行时间和Reduce负载均衡方面都优于传统Hash算法分区。在接下来的工作中会将该算法应用到真实的系统环境中,来体现该算法的实用性。
参考文献
[1] XU Y J, QU W Y, LI Z Y, et al. Balancing reducer workload for skewed data using sampling?based partitioning [J]. Computers & electrical engineering, 2014, 40(2): 675?687.
[2] 刘朵,曾锋,陈志刚,等.Hadoop平台中一种Reduce负载均衡贪心算法[J].计算机应用研究,2016,33(9):2656?2659.
[3] 陶永才,丁雷道,石磊,等.MapReduce在线抽样分区负载均衡研究[J].小型微型计算机系统,2017,38(2):238?242.
[4] 王诚,李奇源.基于贪心算法的一致性哈希负载均衡优化[J].南京邮电大学学报(自然科学版),2018,38(3):89?97.
[5] 宛婉,周国祥.Hadoop平台的海量数据并行随机抽样[J].计算机工程与应用,2014,50(20):115?118.
[6] 李娜,余省威.云计算环境下多服务器多分区数据的高效挖掘方法设计[J].现代电子技术,2017,40(10):43?45.
[7] LIU G P, ZHU X M, WANG J, et al. SP?partitioner: a novel partition method to handle intermediate data skew in spark streaming [J]. Future generation computer systems, 2018, 86: 1054?1063.
[8] 罗永青.基于Key值解决MapReduce中Reduce负载不均衡算法[D].淮南:安徽理工大学,2017.
[9] 张元鸣,蒋建波,陆佳炜,等.面向MapReduce的迭代式数据均衡分区策略[J].计算机学报,2019,42(8):1873?1885.
[10] LU W, CHEN L, WANG L Q, et al. NPIY: a novel partitioner for improving mapreduce performance [J]. Journal of visual languages & computing, 2018, 46: 1?11.
[11] BERLI?SKA J, DROZDOWSKI M. Comparing load?balancing algorithms for mapreduce under Zipfian data skews [J]. Parallel computing, 2018, 72: 14?28.
