基于Hadoop的人口大数据平台设计与实现
2020-08-14王洪岭
王洪岭,肖 丽
(广州泰尔智信科技有限公司,广东 广州 510000)
1 人口流动检测调查
检测人口的流动过程中,存在行为多变性,政策的人才引进、企业的变迁、某些大型活动的举办或者某些短暂的节假日等,均可导致人口的流动。统计人口流动的方式也是多样的,如根据人员来往的机票火车票等交通数据、根据政府单位登记的人员统计等,但以上测算方法都存在延迟性,无法实时更新。
在2019年6月中国互联网络信息中心发布的《第44次中国互联网络发展状况统计报告》中写到,中国网民规模达到8.54亿人,互联网普及率达到61.2%,其中手机网民有8.47亿人,庞大的网民数量为运营商提供大数据集,包括购物、定位、兴趣爱好等行为数据。
在人口流动和分布中,需要根据运营商提供的用户信息去匹配其所属的区域。由于某市各镇的区域范围属于不规则图形的闭环,所以需要判断用户所在位置是否在某个不规则图形中或者边上。如图1所示,判断点在区域内,则需要区域边界点并且是形成闭环,点的数量越多,则判断越准确,且数据中经纬度坐标需要使用统一标准。本平台采用BD09坐标系,属于百度坐标偏移标准。
在不规则区域中判断点是否在区域内,可以采用PNPoly算法、多边形面积算法等方法。本文采用射线法来判断,通过点假设性两端无限延长,形成两端射线去与不规则区域边界查看是否有交点,如果交点个数为偶数,则点在区域外,奇数则在区域内。因为射线法需要满足多种条件,去排除因为独特区域造成的与点有奇数交点而又不在区域内的情况,所以此方法适用于各种不规则图形,算法代码如表1所示,是实现判断射线测算点是否在区域内的具体算法。

图1 在不规则区域中定位

表1 射线测算算法代码实现
2 基于Hadoop数据存储分析
随着数据量不断增加,大数据分析平台在多项领域中被应用,而大数据主要指传统数据处理软件无法处理的数据集,有着海量、多样等特点,主要分为结构化、半结构化和非结构化,目前非结构化数据占70%~80%,通过数据挖掘技术和算法去提高处理非结构化数据[1]。非结构化数据对比结构化数据的处理难度要大,数据的预处理能够有效替身数据挖掘的质量和效果,大大提高了数据挖掘的效率[2]。
调查通信数据发现,某市每月用户文本信息可达TB级别,基于多个Hadoop大数据平台分析系统的对比,支撑平台分布式存储均使用HDFS,而且HDFS也可作为其他云存储的存储系统[3]。作为核心系统需要保持稳定性,在HDFS中用于元数据信息管理的NameNode存在不稳定性,当NameNode发生故障的时候,可能导致系统宕机。通过在内存中保存NameNode镜像,并且进行实时备份和之后在高可用NameNode去进行Checkpoint[4],可进一步提高平台在海量数据处理下的稳定性。
3 人口大数据平台系统设计
基于移动通信数据,可以运算得出有价值的报告,本研究就是通过运营商提供的通信信息,利用数据分析模块对电信数据进行数据清洗与处理,建立用户数据画像,根据政务需求,形成服务清单,并进行清洗、过滤、筛选、聚合等操作,将数据转换为个人人口迁移、人口分布、人口的迁入迁出等数据可视化。
3.1 设计思路
人口大数据可视化平台可为政府在交通、物流、城市应急事件等领域作为数据分析参考,在确认目标需求之前分析领域需要数据的要求,获得足够的分析源数据。获取最终数据之前需要建设平台分析方案,进行平台的环境搭建、辅助数据收集、清洗数据和数据的预处理、数据的完全处理和存储等步骤的流程式处理。电信大数据的人口分析平台建设方法如图2所示。
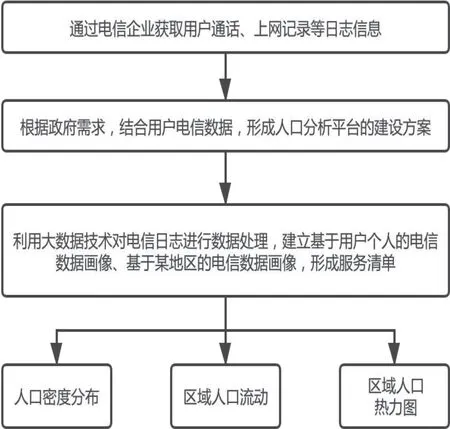
图2 电信大数据的人口分析平台建设方法
在设计过程中应遵循设计原则的稳定性、先进性和可维护性。对于稳定性,平台可采用实时和离线处理,对于个人移动轨迹查询,需要快速从大量数据中获取结果,则使用实时处理,而对时间间隔要求较短的人口分布和密度等需求,可通过定时离线分析数据,保证平台的稳定性。先进性与可维护性可采用前沿技术且应用型较为广泛的技术去实现平台架构的搭建,如Flink,Logstash,Elasticsearch等较多开发者维护的技术。
3.2 数据准备
数据源来自电信运营商在2014年6—10月,是广东省某市所有用户的语音数据和流量数据,数据文件大小分别为2.92 GB和28.9 GB,流量数据共有506 198 944行,语音数据有70 740 696行,具体的数据形式如表2—3所示。
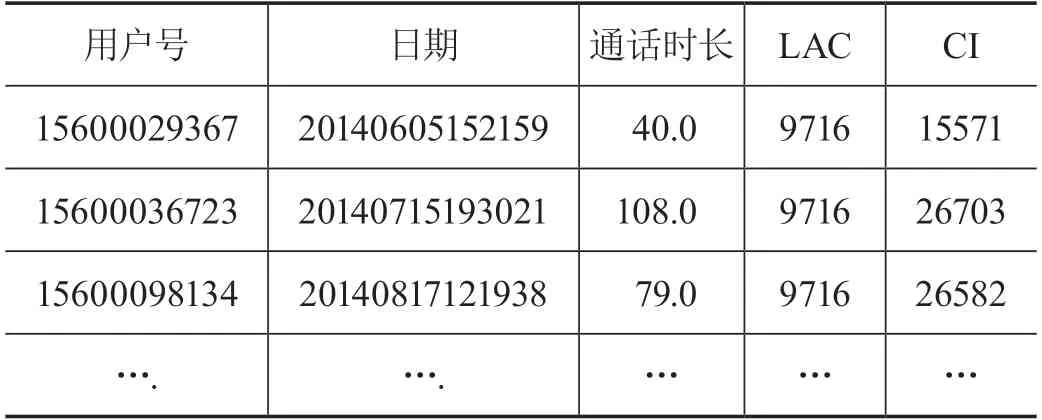
表2 语音数据

表3 流量数据
由于是直接从运营商中获取出来的数据,数据清洗和处理难度可能会较低,但仍需做脏数据处理,保证结果更加精确。用户语音数据包含的字段有用户号(经过加密的脱敏处理)、时间戳、基站LAC和CI、通话时长;流量数据包含的字段有用户号、时间戳、基站LAC和CI、上行流量、下行流量、上网时长。其中基站的LAC和CI对应的Long和Lat数据包含在电信运营商提供的某市内所有地区中基站的数据中,数据中基站对应的Long,Lat属于WGS坐标。
通过使用Java中的HttpClient技术,使用某些网站提供的公开API,获取某市各镇的边界经纬度坐标和某市小区区域边界坐标,供369个小区数据。后期经过ETL工具对已采集数据进行清洗和纠正,将两份数据在时间间隔较短中重复的用户号去除,并将数据格式转换成合适的格式和类型,方便ELASTICSEARCH进行数据检索和存储。
3.3 实际运算
本文基于人口大数据平台处理运营商提供源数据和采集系统获取到的相关数据,对某市的各镇做了人口密度统计、人口流动统计和个人位置移动记录,此平台总共可分为4个模块,分别是采集模块、数据存储模块、分析处理模块、面板显示模块。本平台采用7台服务器进行搭建分布式的平台环境,系统使用的版本号分别为:elasticsearch-6.7.0,hadoop-2.7.7,flink-1.8.0,kafka_2.11-2.2.0,springboot-2.1.7。
通过数据采集获取源数据和辅助数据,本次使用测试数据大约在50 GB左右,考虑传统数据库后期处理TB数据时各项压力较大,则采用HDFS存储数据。存储在HDFS中的源数据可通过Flume提供的接口导入在Flink中,在两项流程中插入Kafka,可降低对服务器的IO操作,进行数据缓存。整个平台数据挖掘则利用Flink批处理技术进行数据清洗,对人口密度、个人流动轨迹、区域流动做出不同处理方式和数据的处理。最后将数据导入Elasticsearch中检索出数据可视化对应的数据。平台整个具体操作流程如图3所示,包括从数据采集到数据可视化的一整流程。
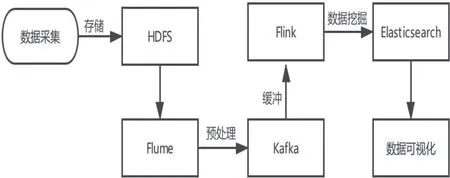
图3 数据处理流程
为满足不同需求而对数据进行不同的处理,Flink作为此平台的数据清洗,导入Elasticsearch进行数据检索,因此对后期数据检索的效率有重大影响。人口密度功能的数据实时性相对于人口流动轨迹和区域人口流动来说较弱,所以采用流式处理,而另外两个采用批示处理。Flink数据清理流程如图4所示。
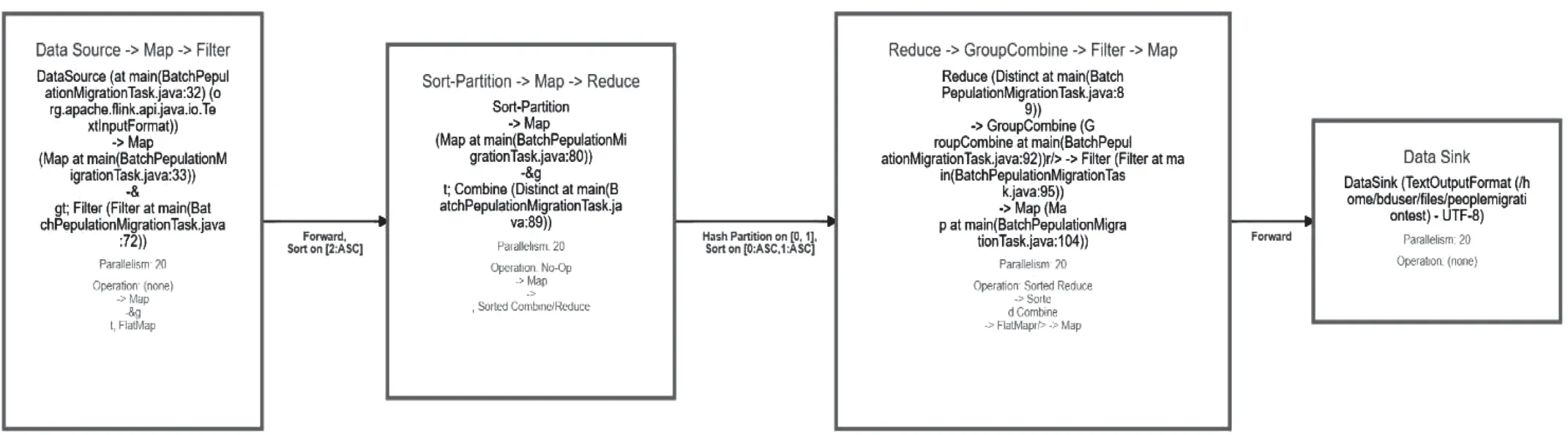
图4 平台钟Flink数据清洗过程
4 结语
文章主要构建一个以大数据技术分析通信数据的平台,最终以可视化形式展示平台分析内容。通过市级数据展开分析,从多角度和多功能进行数据挖掘,描述了人口大数据分析平台的设计过程和原则,对Hadoop的相关研究和平台相关架构展开描述,最终设计出某市的各镇人口密度、各镇人口流动、小区人口分布以及个人人口流动轨迹的4个功能,对4个功能提供了可视化面板。
在平台开发过程中,通过不断测试和修改,再将结果与报告进行对比后不断完善平台,希望最大限度地以精准、高效、人性化方式支撑各领域政府工作。
