一种基于卷积神经网络的小篆识别方法
2020-08-10袁柱
袁柱
(广东工业大学计算机学院,广州 510006)
0 引言
作为秦始皇统一六国后官方指定的文字,小篆广泛存在于牌匾、印章、碑文等地方。但由于中国汉字经过了多次的演变和简化,距今两千多年的小篆和现如今的简体汉字相差甚远,普通人或许可以通过搜索引擎查找出某些简体汉字所对应的小篆字体,却很难认出牌匾或印章中的小篆是哪些汉字,所指何意,更别说古籍中成文的小篆。因此,在很多时候,我们需要一种从小篆转换到简体汉字的方法。但是由于中国的汉字个数众多,小篆字体较为复杂,很长一段时间内都没有找到一种较好的识别方法。
最近几年来,随着深度学习的兴起和不断地发展,卷积神经网络(Convolutional Neural Network,CNN)在图像识别领域上取得了大量突破性的成果。从奠基性的LeNet[],到将卷积神经网络发扬光大的AlexNet[2]、VGG[3]、GoogLeNet[4]、ResNet等,都在越来越复杂的场景下,进一步地提高了图像识别的准确率。众多的模型结构证明,卷积神经网络所学习到的特征可以超越手工提取的特征,而经过良好设计的卷积神经网络模型比传统的机器学习模型在图像识别领域更具有优势。与此同时,众多取得成功的网络模型也为从业者提供了方向上的指导。本文基于识别小篆字体的目的,在AlexNet的基础上设计了适合于识别小类别小篆字体的模型,并取得了较好的结果。
1 数据集和数据预处理
1.1 数据集
本文使用的小类别小篆数据集是通过网络爬取和多人手写的方式所得。该数据集包含20类小篆的字体,分别代表了20个姓氏。每类小篆字体都包含了120张训练数据和60张测试数据,每张图片的规格都是112×112像素颜色不同的png格式。

图1 部分训练数据集
1.2 数据增广
大规模的数据集是成功应用深度卷积神经网络的前提。由于构建的数据集较小,因此需要通过数据增广(Data Augmentation)技术来对训练图像做一系列的随机改变,产生更多相似却又不相同的训练样本。本文用到的数据增广技术包括:小角度的旋转、平移和拉伸[5]。小角度的旋转包括向左旋转和向右旋转一定的角度。由于汉字有上下左右之别,本文的旋转的角度范围在-25°~+25°之间。平移包括将文字从原来的位置沿着X轴和Y轴的方向平移到另外一个地方去。由于CNN对图像具有平移不变性,文字的位置虽然发生了变化,但平移之后的图像,CNN依然能够探测出来。拉伸将文字沿着某个方向增大文字的覆盖范围。

图2 数据增广
通过上述的四种数据增广技术,可以产生大量的训练样本,从而扩大训练数据集的规模,丰富样本空间中的样本个数。
1.3 数据预处理
在原始的数据集中,小篆字体包含不同的颜色。由于字体的颜色与字体的识别在本文并无本质的关系,因此在训练网络之前,需要将所有的字体图片都转换为灰度图片,用黑白两色就可以完整地表达了特征的信息。
2 模型的设计
基于AlexNet模型结构的设计思想,构建了适用于小篆识别的卷积神经网络模型。为了加快模型的训练,在该模型的基础上引入了批量归一化(Batch Normalization,BN)算法。
2.1 批量归一化算法
批量归一化算法是由谷歌研究院Sergey Ioffe[6]提出来的,该算法通过减轻神经网络训练时的内部协变量偏移(Internal Covariate Shift),从而有效地提高神经网络的训练速度。在模型的训练过程中,批量归一化算法利用小批量训练样本上的均值和方差,不断调整神经网络的中间输出,使整个神经网络在各层的中间输出数值更稳定,从而更容易训练。
假设神经网络中某层的输入是大小为m的小批量数据X={x1,…,xm},其中小批量X中任意的样本xi∈Rd,1≤i≤m。对小批量X求均值和方差:

接着标准化xi中的每一维度,得到:

其中ϵ是一个大于0很小的常数,是为了保证分母大于0。
在上面标准化的基础上,批量归一化引入了两个可以学习的d维向量模型参数:拉伸参数γ和偏移参数β,它们与̂分别做按元素乘法和加法计算:

得到的yi就是批量归一化算法对于输入xi的输出。
在神经网络的训练中,批量归一化算法常常作为网络模型中的一层BN层,且通常应用在卷积层和全连接层中。在对卷积层做批量归一化的时候,BN层通常加在卷积计算之后、应用激活函数之前。在对全连接层做批量归一化的时候,BN层通常加在仿射变换和激活函数之间。本文选择除了输出层外,对所有的全连接层和卷积层做批量归一化处理。
2.2 模型结构
与AlexNet相似,本文构建的卷积神经网络结构主要由卷积层、池化层和全连接层组成。卷积层具有较强的特征抽象和提取的能力,通过多个卷积核能够学到多种不同的特征。池化层对卷积层输出的特征图做聚合统计,降低特征图的维度。与AlexNet不同的是,为了提高模型的训练速度,本文的模型在卷积层和全连接层中均加入了BN层。此外,与ImageNet数据集相比,考虑到本文所使用的数据集的真实情况,在一定程度上减少卷积层的通道个数,降低部分卷积层的卷积核大小。具体模型结构如图3所示。

图3 CNN模型结构
在该模型中,池化层maxpooling都设计为步幅(strides)为 2、填充(padding)为 0、池化区域为 3×3 的固定结构。卷积层的结构如表1所示。
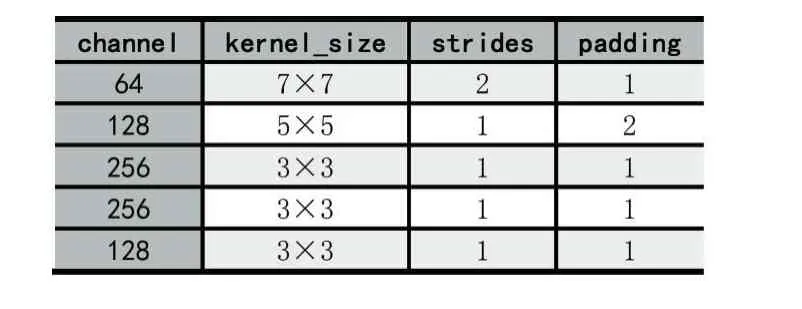
表1 卷积层的结构
对于每个输入数据,该模型将进行如下处理:
首先,数据将通过一个包含了64个通道、卷积核大小为7×7的卷积层C1,卷积计算后输出的中间数据变为64张规格为54×54的特征图,接着经过池化层,特征图的大小变成了26×26。
其次,上一层的特征图输入到第二个卷积层C2时(C2包含了128个通道、卷积核大小为5×5),经过卷积计算后得到了128张26×26的特征图,同样经过池化层后规格变为12×12。
随后,数据将经过三个相似的卷积层,每个卷积层中卷积核大小都是 3×3,strides为 1,padding为 1;前两层包含256个通道,最后一层卷积层包含128个通道。上一层特征图经过连续的三个卷积层后规格依然是128张12×12的特征图,再进行池化处理后,特征图的规格变为128张5×5,展开成为128×5×5=3200维的向量连接到三个全连接层上。三个全连接层的神经元个数分别为1024、512和20。其中最后一层的20代表类别的个数。得到20个神经元的输出后,进行Softmax处理,即对于每个神经元的输出,进行如下计算:其中k代表输出神经元的个数,V代表输出i层第i个神经元的输出。
最后,在每个卷积层中,卷积计算过后,都会进行批量归一化的处理,处理过后经过ReLU激活函数作为下一层的输入。同样的,除了最后一层输出层外,其他两个全连接层在ReLU激活函数之前都经过了批量归一化的处理。
2.3 模型的训练
模型的训练优化算法为带有动量(momentum)的小批量随机梯度下降(SGD)算法[7],初始学习率learning_rate设定为0.01,momentum设定为0.9。模型每迭代15次计算一次模型在当前小批量数据上的识别准确率。在模型的训练过程中,尽可能大地设置训练循环次数,当观察到模型在测试集上地识别准确率不再增加时,停止训练过程。
3 实验结果
实验环境:Windows 10操作系统、NVIDIA GTX 1650显卡、8G内存,深度学习框架为TensorFlow[8]。
本文采用对照实验的方法,一组是不做批量归一化处理,另外一组对卷积层和全连接层做批量归一化处理。实验结果如图5、图6所示,两组实验都能达到较好的识别效果,训练数据集和测试数据集的识别率均可达到了94%。值得注意的是,不做批量归一化处理的模型最少需要经过500次的迭代才能够收敛,而经过批量归一化处理的模型仅需要300次的迭代就可以收敛了。实验表明,设计良好的卷积神经网络对小类别的小篆识别能够达到较好的识别效果;批量归一化处理可以明显提高网络模型的收敛速度。
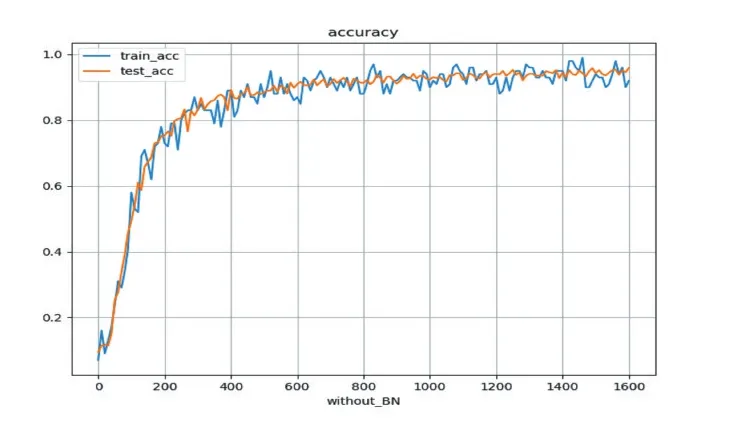
图4 无批量归一化
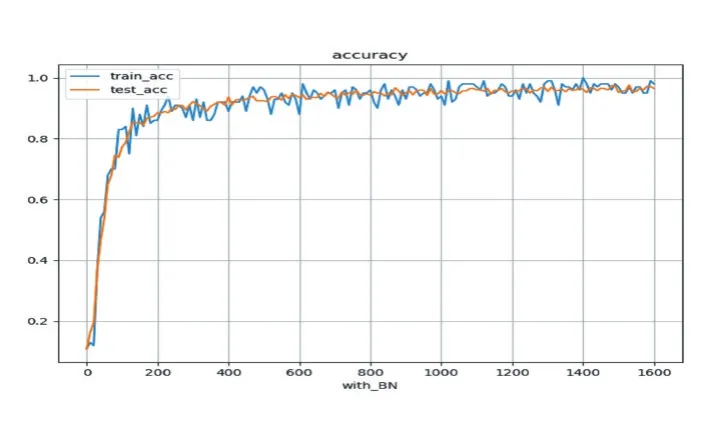
图5 有批量归一化
4 结语
本文通过多种数据增广技术扩大了训练数据集,基于AlexNet设计了用于识别小类别小篆字体的网络模型,取得了94%的识别准确率。同时探讨了批量归一化算法对模型训练的加速效果,为小篆字体识别的研究和模型的训练加速提供了新的思路,在工程上具有一定的实际意义。
