AI被数据扯了后腿
2020-08-09
亚马逊的“Go”商店令人眼前一亮。这些不设收银员的店铺2018年首次在西雅图开业,顾客只要亮出手机应用,就可以拿了商品直接走人。该系统使用了大量传感器,但其魔法主要是由连接到AI系统的摄像头完成的。AI系统会追踪商品从架子上被取走的过程。一旦顾客拿着商品离店,账单就结算完毕,会自动向顾客收费。
在一个拥挤的商店里做到这一点并不容易。系统要能够应付人员密集的环境:摄像头可能被其他顾客阻挡而看不到某些人的动作。它必须能识别单个顾客,还有同行的朋友或是全家出动。如果一个孩子把一件商品放进自家购物篮,系统必须意识到应该向Ta的父母收费。而且它必须实时又高度准确地完成这一切。
为指导机器做这些,需要向它们展示大量“训练数据”:顾客浏览货架上的商品、拿取商品、把商品放回货架等各种行为的视频。对于像图像识别这样的标准化任务,AI开发人员可以使用公用训练数据集,每个都包含成千上万张图片。但记录人们逛商店的公用训练集尚不存在。
有些数据可由亚马逊自己的员工生成,公司此前让他们进入测试版店铺中。但这么做有其局限。人们会用各种各样的方式从架子上取走一件商品并决定买下它、立即把它放回架子,或稍后再放回去。要在现实世界中真正奏效,系统必须涵盖尽可能多的可能性。
从理论上讲,世界充斥着数据,这是现代AI的命脉。市场研究公司国际数据公司(IDC)估计,2018年全球生成了33ZB的数据,足以填满7万亿张DVD。但是,专注于AI领域的咨询公司Cognilytica的凯瑟琳·沃尔克(Kathleen Walch)表示,尽管如此,数据问题仍是所有AI项目中最常见的症结之一。和亚马逊Go商店的例子一样,某个项目需要的数据可能根本就不存在,或者数据可能被锁在竞争对手的保险库中。即便相关数据可以被挖出,可能也不适合输送给计算机。
Cognilytica表示,一个典型AI项目约80%的时间都花在了各种数据整理上。训练机器学习系统需要大量仔细标注的样本,而这些标注通常需由人类添加。大型技术公司通常在内部开展这项工作。那些缺少相关资源或技术知识的公司可以借力一个不断发展的外包产业来完成这个部分。例如,中国公司莫比嗨客雇用了30多万人来标注源源不断的人脸照片、街道场景或医疗扫描影像以便后续的机器处理。亚马逊的另一个部门土耳其机器人(Mechanical Turk)为企业与一个临时工大军牵线搭桥,向这些工人支付计件工资来执行重复性任务。
Cognilytica估计,第三方“数据准备”市场在2019年价值超过15亿美元,到2024年可能增至35亿美元。数据标注业务也差不多:2019年企业在这方面至少支出了17亿美元,到2024年可能达到41亿美元。Cognilytica的罗恩·施梅尔策(RonSchmelzer)说,掌握某个专业课题并非必要,例如在医学诊断中,业余数据标注员经训练后在识别骨折和肿瘤等方面几乎可以和医生媲美。但掌握一定的AI研究人员口中的“领域知识”至关重要。
数据本身可能包含陷阱。机器学习系统将输入与输出相关联,但它们只是盲目地执行,并不理解更广泛的语境。1968年,编程大师高德纳(Donald Knuth)警告说,计算机会“完全按你告诉它们的去做,不多也不少”。机器学习中充满了这句话的例证——机器精确遵循规则的字眼,对其精神却一无所知。
人工智能部分事件

数据来源:《经济学人》
2018年,纽约西奈山医疗系统(Mount Sinai)的研究人员发现,一个经训练通过X光胸片识别肺炎的AI系统,在它受训的医院以外的其他医院使用时能力明显降低。研究人员发现,机器能够识别出胸片来自哪家医院,方法之一是分析片子角上的小块金属标记—各家医院的标记各不相同。
由于训练集里的一家医院的肺炎基准发生率远高于其他医院,胸片来自哪家医院这个信息本身就足以大幅提高系統的准确性。研究人员把这种巧妙的伎俩称为“作弊”,因为在向系统出示陌生医院的数据时,它就失灵了。
偏见导致了另一种问题。去年,美国国家标准技术研究院(National Institute of Standards andTechnology)测试了近200种人脸识别算法,发现许多算法在识别黑人面部时准确性明显低于识别白人面部。这个问题可能反映出白人面部在机器的训练数据中占了多数。IBM去年发表的一项研究发现,3种被广泛使用的训练集中,超过80%的人脸都是较浅的肤色。
至少从理论上讲,这类缺陷很容易纠正(IBM提供了一个更具代表性的数据集供所有人使用)。其他的偏见来源可能更难消除。2017年,亚马逊叫停了一个通过简历寻找合适人选的招聘项目,因为他们发现该系统对男性申请人有利。事后经检验他们发现了一个循环的、自我增强的问题:公司用以前成功被录取的申请人的简历训练该系统,但技术人员的队伍里大部分是男性,因此根据历史数据来训练的系统会把男性这个特征作为适合度的强预测指标。
普华永道机器学习英国团队的负责人法布里斯·西亚斯(Fabrice Ciais)说,人类可以尝试禁止机器做这类推导(亚马逊正是这么做的)。在许多情况下他们必须这么做:在大多数富裕国家,雇主不能基于性别、年龄或种族等因素雇用人员。但算法可以比它的人类主人更聪明,西亚斯说,它们能用替代变量重构出被禁用的信息。从业余爱好到工作经历,再到电话号码中的区号,各种信息都可能暗示申请者很可能是女性、年轻人或少数族裔。
在机器学习项目的各项任务上的平均耗时
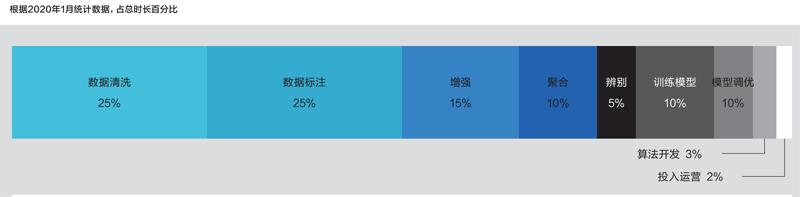
数据来源:《经济学人》
如果现实世界中的数据难题太过艰巨,那么一种选择是自己创造一些数据。这正是亚马逊改进Go商店时所用的方法。该公司使用图形软件来生成虚拟购物者。这些“人造人”被拿来训练机器处理许多困难或异常的情景,它们在真实训练数据中未曾出现,在实际环境中部署系统时却可能发生。
此举并非亚马逊独树一帜。无人车公司用高保真模拟现实来做大量训练,在这种模拟中如果出错不会造成真正的破坏。芯片制造商英伟达2018年发表的一篇论文描述了一种为无人车快速创建综合训练数据的方法,并得出结论称由此生成的算法效果比仅用真实数据训练的算法更好。
隐私关切是“合成数据”的另一个吸引力所在。希望在医学或金融中使用AI的公司必须遵守美国的《健康保险可携性和责任法案》(HIPAA)或欧盟的《通用数据保护条例》(GDPR)等法律。要对真实数据做恰当的匿名处理可能会很难,而用虚拟人训练的系统根本不用担心这个。
西亚斯的同事尤安·卡梅伦(Euan Cameron)说,诀窍在于确保模拟足够接近现实,使经验得以推广。对于像欺诈识别或信用评分这样能清晰界定的问题,这很简单。还可以将统计噪声添加到真实数据中来创建合成数据。这样,尽管单个交易是虚拟的,但可以保证它们整体上具有与源数据相同的统计特征。但一个问题越复杂,就越难确保从虚拟数据中汲取的经验能被顺畅地用于现实世界。
希望在于所有这些与数据相关的折腾都是一次性的,一旦训练好,机器学习模型将用数百万次自动决策来回报这番努力。亚马逊已经开设了26家Go商店,并提出将相关技术授权给其他零售商。但即使到了这一步也仍需要谨慎。研究公司高德纳(Gartner)的斯韦特兰娜·希克尔勒(Svetlana Sicular)说,许多AI模型都受到“漂移”(drift)的影响,即随着时间流逝,世界运转方式的变化意味着它们的决策变得不那么准确。顾客的行为在变化,语言在演变,监管机构也会改变公司能做什么的规定。
有时漂移会在一夜之间发生。“购买单程机票在自动检测模型中曾是一个很好的预测欺诈的指标。”希克尔勒说,“但新冠肺炎导致封城后,突然有很多人都在买单程票,他们都是清白的。”如今戴口罩已成為常态,一些习惯了识别裸露面部的人脸识别系统碰到了麻烦。自动化物流系统现在需要人员的帮助才能应对卷筒纸、面粉及其他生活必需品的需求激增。世界的可变性意味着机器需要更多训练,也就是要为它们提供更多数据—这是一个无休止的再培训循环。卡梅伦警告说:“人工智能不是个一劳永逸的系统。”
