基于部件精细化分割的行人检索方法
2020-08-07赵延
赵延
(北方工业大学城市道路交通智能控制技术北京市重点实验室,北京100144)
0 引言
行人检索是利用计算机视觉的技术和方法,在摄像头等设备采集到的图像数据集中,搜索目标行人的图像。行人检索可以作为人脸识别的一个补充,当行人图像中缺乏有效的人脸信息时,通过识别行人图像的非人脸信息是一个常用的检索方法。行人检索是一个复杂的问题,同一个行人受到多种因素干扰,如行人走路姿态、服装穿戴、图像清晰度等,大大提高了行人检索的难度。
近年来,随着深度学习的飞速发展,对于行人检索已提出许多方法。文献[1]采用了垂直分割行人图像的方式,利用长短时记忆网络提取部件特征,这种方法对行人图像对齐有较高的要求。文献[2-3]采用人体骨架关键点模型,将人体分为若干个区域,提取部件特征和全局特征,最终得到一个融合全局特征和多个尺度部件特征的行人特征。
1 基于部件精细化分割的行人检索方法
1.1 行人对齐
在行人检索过程中,行人所处的不同背景会影响图像检索的准确率。采取部件特征提高识别准确的前提是部件的准确定位[9],所以,行人图像的对齐是提高识别准确率的方法。文献[4]提出了一种基于SP 距离自动对齐模型,采用动态对齐算法,可以在无额外信息的情况下自动对齐部件特征。
1.2 行人精细化分割
行人图像分割主要有两种分割方式:按语义划分成头部、躯干、四肢等,或将图像垂直划分成多个水平横条部件。
本文采用垂直划分的方式,提出一种行人图像部件的精细化分割方法,将图像划分为p 个水平横条,每个水平横条再按像素划分成m*n 个色块,将色块按照颜色区分,匹配最近的同色色块,加强部件内部的一致性。通过部件池化来纠正内部的不一致,根据各部件的相似性来分配所有列向量,为此我们需要动态的对所有列向量进行分类。使用线性层和Softmax 激活函数作为部件分类器。
1.3 部件特征提取
本文使用卷积神经网络提取特征,选择相似性度量方法对提取的特征进行度量,本文采用Triplet Loss[8],Triplet Loss 是深度学习中的一种损失函数,用于训练差异性较小的样本。
将进行精细化分割处理后的p 个水平横条通过一个传统的平均池化,将p 个水平横条在空间上进行下采样,得到p 个列向量gi(i=1,2,…,p)。然后通过一个1*1 的conv 卷积,降至256 维,得到p 个列向量hi(1*1*256),并输入到分类器中。本文经过验证,将p值取为6。
1.4 多分支特征融合
得到部件特征后,将各部件特征、全局特征作为分支特征,输入到多分支网络中,得到一个增强的特征,提高了行人检索的准确率。多分支网络如图1 所示。
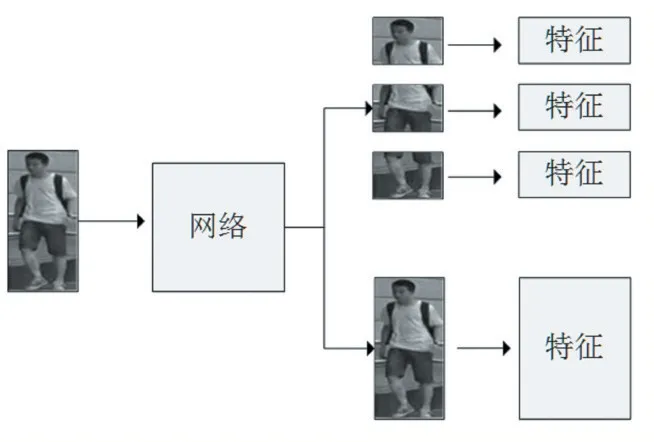
图1 多分支网络
2 实验与分析
实验环境是基于PyTorch 框架,实验硬件设备:
NVIDIA GeForce GTX 1060 6GB。
2.1 实验所用数据集与评价指标
本文算法在Market-1501、DukeMTMC-reID 两个数据集上进行测试。
Market-1501[5]在清华大学校园中采集,拍摄时间为夏季。采集所用摄像头共6 个(高清摄像头5 个,低清摄像头1 个),共拍摄1501 个行人、32688 个行人图像。其中训练集751 人、12936 个行人图像;测试集750 人、19732 个行人图像。
DukeMTMC-reID[6]源自在杜克大学中8 个不同的摄像头采集的85 分钟高分辨率视频,拍摄时间为冬季。从视频中每隔120 帧采样一张行人图像,共1404个行人、36411 个行人图像。其中来自702 人的16522个训练图像;702 人的2228 个查询图像和17661 个待匹配图像。
评价指标有:Rank-1:指检索结果中最靠前的一张图是正确结果的概率,一般通过实验多次来取平均值。mAP:平均检索精度,是检索中,用于衡量精度的指标,数值越高,检索结果越好。
2.2 精细化分割与其他分割方法的对比
在表1 和表2 中将我们提出的方法分别在Market-1501 和DukeMTMC-reID 数据集上与已发布的方法进行了比较。与现有技术相比,本文的方法取得了很好的效果。在Market-1501 测试中,Rank-1 为93.8%,mAP 为80.8%。在DukeMTMC-reID 上,Rank-1为65.1%,mAP 为55.6%。检索结果示例如图2 所示。

表1 Market-1501 数据集实验结果

表2 DukeMTMC-reID 数据集实验结果

图2 检索结果示例
3 结语
本文采用了一种新的部件分割方法,同时采用多分支的网络结构提取图像特征,提高了行人图像检索的精度。在Market-1501 和DukeMTMC-reID 两个数据集上进行试验,取得了很好的结果。
