基于流形距离的高速公路短时交通流预测模型
2020-08-06张善关谢云驰张跃进
雷 毅, 张善关, 谢云驰, 胡 勇, 喻 蒙, 张跃进*
(1.江西省高速公路联网管理中心,南昌 330036;2.华东交通大学信息工程学院,南昌 330013)
高速公路作为城市间互相联通的重要纽带,在长途出行及货物的运输中扮演了极其重要的角色,提供了长距离、快速出行的重要保障。高速公路的交通管理越来越受到重点关注[1]。利用实时车流量数据进行管理属于“被动式反应”,而通过分析历史交通流变化规律,预测下一时间间隔内的交通流量进行管理属于“主动式动作”。被动式的管理只能在交通拥堵发生时进行车辆诱导、避免二次拥堵,而主动式管理能从根本上提高高速公路通行能力和服务水平,同时驾驶员也能根据预测的交通流情况进行路线规划,避免交通拥堵[2]。因此,对高速公路交通流进行准确、实时的预测是智能交通系统从“被动式反应”转变到“主动式动作”的关键,在高速公路联网管理过程中至关重要[3]。
短时交通流预测是指预测通过道路指定断面5~15 min跨度内的车辆数量[4]。通常,交通流预测可以视为学习问题。首先,通过从给定的历史流量数据中学习基本流量模式,然后基于实时流量数据预测未来状况,来构建预测模型。在过去的几十年里,已有多种交通流预测方法被提出。然而,准确和实时的交通流预测仍然是一个具有挑战性的问题,因为道路交通系统是一个时变且复杂的非线性系统,其发展很大程度上取决于交通流之间的相互作用。时空交通流数据的有效提取和数据挖掘技术的进步,为短期交通流预测提供了合理的预测准确性和更短的预处理时间[5]。
针对交通流时空特性,提出一种基于流形距离的K邻近(K-nearest neighbor,KNN)-长短期记忆(long short-term memory,LSTM)预测模型。该模型采用流形距离度量任意两点之间的空间相关性,筛选出k个最近邻站点,将这k个站点和目标站点数据输入LSTM模型进行训练和测试。同时,通过降低学习速率来提高模型的收敛速度和收敛稳定性;在测试过程中,利用滚动预测的方法提高预测精度。
1 时空特性分析
交通流量是指单位时间内通过道路某一地点或某一断面的实际车辆数,又称交通量。高速公路某一站点的交通流量主要来源于相邻站点。预测某一路段交通流时,不仅需要考虑到历史数据的变化特征,还要考虑来自相邻站点的交通流影响,即交通流的时间相关性和空间相关性[6]。以美国华盛顿州 I-5 高速公路上实时交通流为原始数据,验证交通流的相关特性。
1.1 时间相关性
高速公路交通流的时间序列具有非线性和波动性。图1为2019年11月21日站点1581交通流时间序列,交通流有过两次高峰,一次在6:00左右,另一次在17:00左右,而在其他时刻流量有所下降。尽管整体趋势明显,但数据点之间交替出现局部极大值和极小值,呈现出随机波动特性[7]。此外,高速公路交通流的时间序列整体呈现出相似趋势。图2为2019年11月11—17日站点1581交通流时间序列。从图2(a)中可以看出相同断面的交通流量在工作日(周一 —周五)中呈现出日相似性。而周末(周六至周日)的交通流趋势又和工作日不同,具体变化如图2(b)所示。高速公路的交通流时间序列受各种因素影响呈现非线性变化,但当前时刻的交通流量必然与前几个时刻的交通流量有关。因此,根据交通流的时间特性,所提出预测算法不仅需要有处理周期性分布变化的能力,而且还可以根据外部因素变化重新学习[8]。
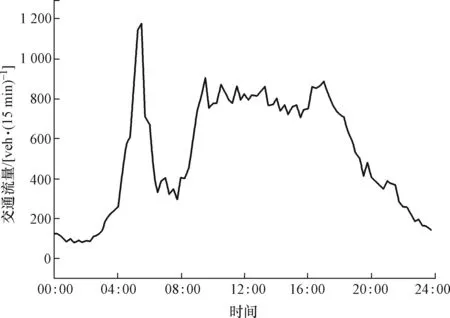
图1 站点1581交通流时间序列Fig.1 Traffic flow time series for station 1581
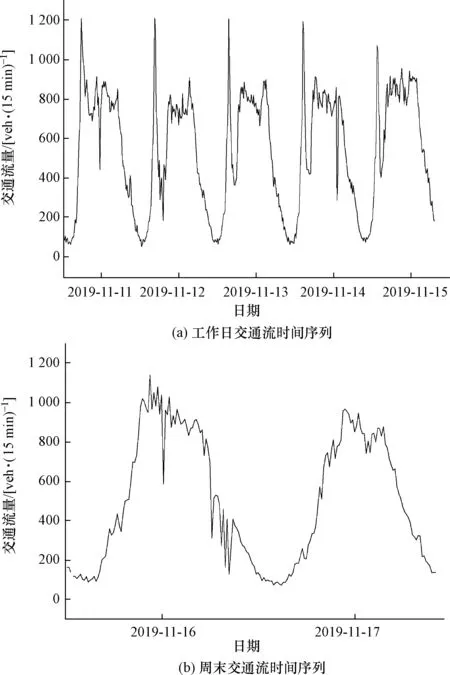
图2 站点1581一周内交通流时间序列Fig.2 Traffic flow time series for station 1581 in a week
1.2 空间相关性
在高速路网中,道路交通是一个复杂的网络,网络中的交叉口相互联系,相互影响。选择空间相关性强的站点可以提高预测精度[9]。图3为2019年11月21日探测器在 WA I-5公路不同站点采集的交通流速度数据。从图3中可以看出,交通流的拥堵和分散过程,红色表示路段拥挤,车速较小;绿色表示道路平坦,车速快。上游路段的交通流状态可以扩散到下游路段,距离越近,扩散程度越大[10]。由此可见,高速公路交通流在空间上呈现出流形相似性。
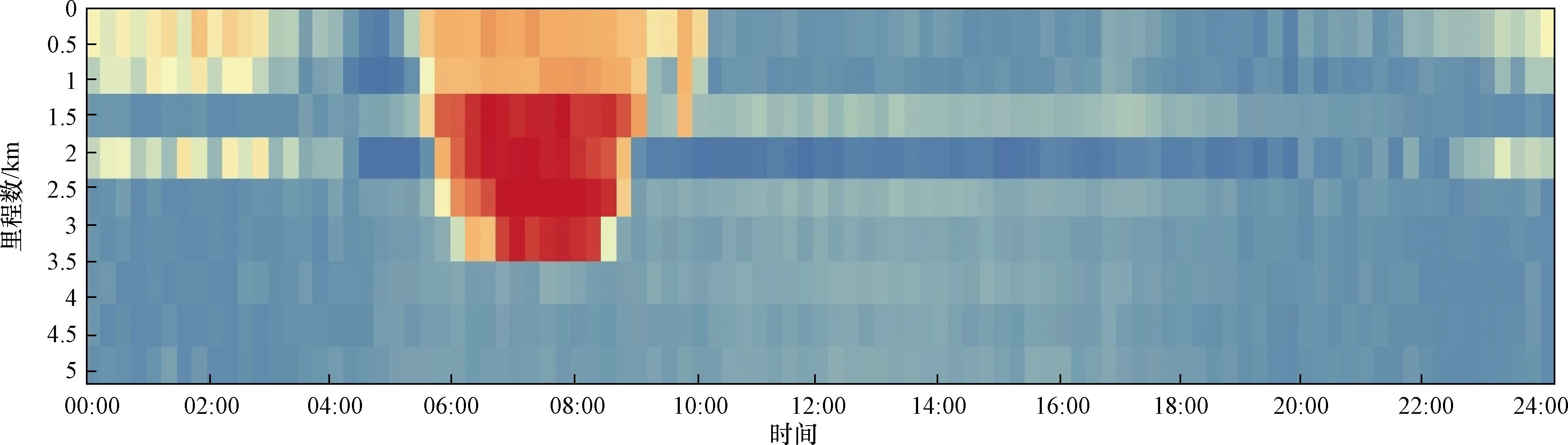
图3 WA I-5 部分站点速度分布Fig.3 WA I-5 some sections traffic speed distribution
2 预测模型构建
2.1 基于流形距离的KNN算法
KNN算法是通过测量不同特征值之间的距离进行分类或回归。利用KNN算法思想,找出距离目标站点最近邻的k个站点构造交通流数据集。常用的测量距离包括欧式距离、曼哈顿距离等[11]。然而,这些距离指标无法准确地描述两站点之间的流形特性,因此,对于邻近站点的选取,引入流形距离概念。利用流形距离来衡量目标站点与附近站点之间的相关程度,定义如式(1)所示[12]:
(1)
将交通流站点当作无向图中的结点,D(xi,xj)则是两结点(xi,xj)之间的流形距离,Pk和Pk+1分别代表第k和第k+1个结点路径,Pij代表连接两结点(xi,xj)的所有路径,L(xi,xj)则是两结点(xi,xj)之间的边长,定义如式(2)所示:
L(xi,xy)=eδd(xi,xy)-1
(2)
式(2)中:δ为调节参数,经过多次测试,δ取0.2效果更好;d(xi,xj)为两结点之间(xi,xj)的欧式距离:
(3)
式(3)中:(X,Y)为两个交通流站点;n为交通流序列样本个数。
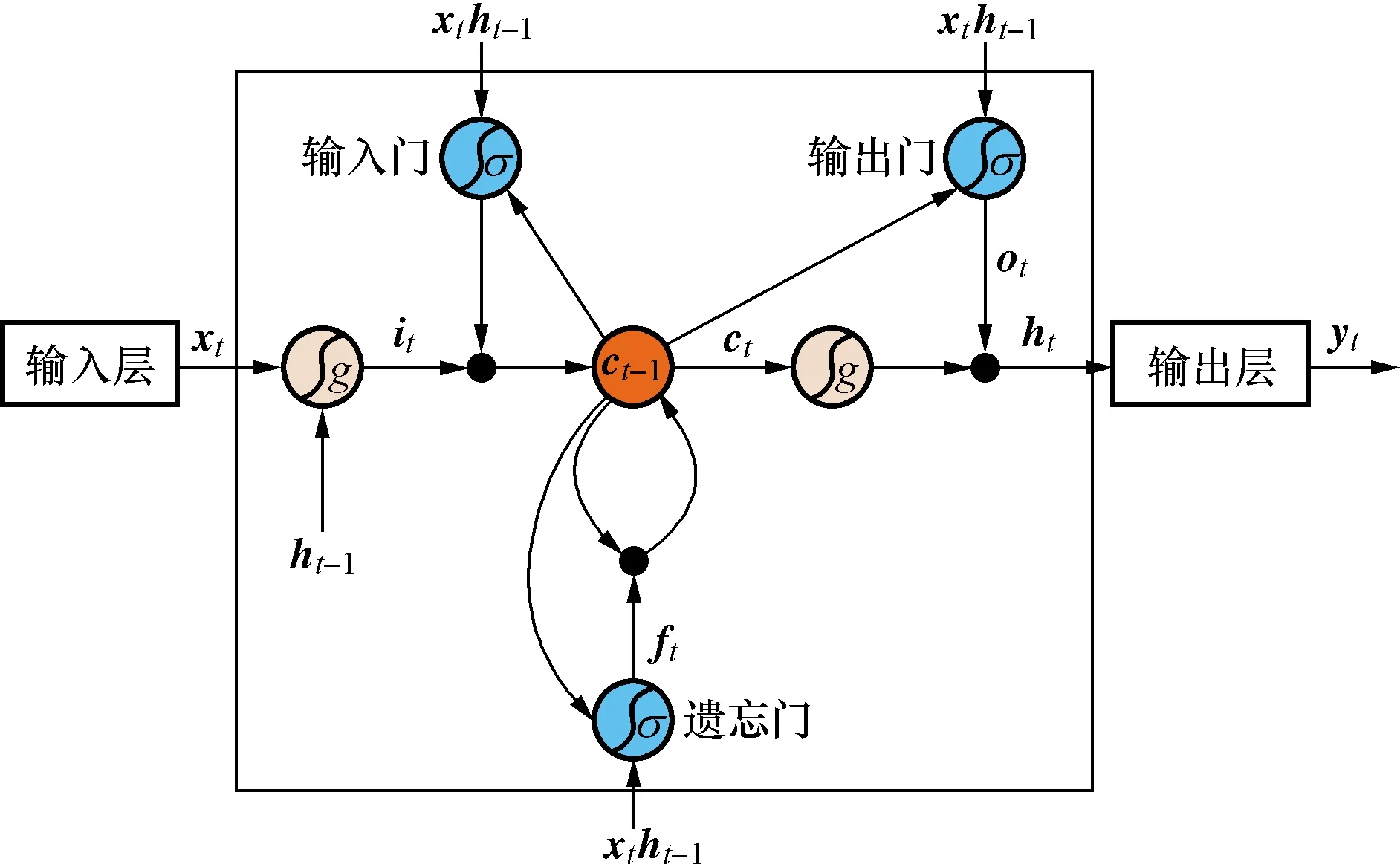
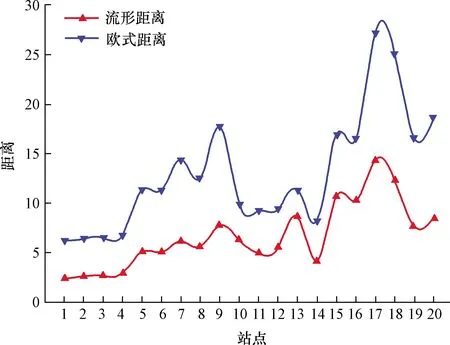
Pij为两结点(xi,xj)之间的所有路径,k为Pij的路径数之和,对于每一个结点k,如果L(xi,xk)+L(xk,xj) 通过式(1)~式(3)可以得出,目标站点与各站点之间的流形距离,选择合适的邻近站点构造交通流数据集。 长短时记忆(LSTM)网络是一种改进的递归神经网络(recurrent neural network,RNN),适用于处理和预测具有较长时间间隔和高相关性的时间序列问题[13]。LSTM与RNN的区别在于LSTM的每个单元都增加了一个细胞来判断历史信息的有效性。每个细胞放置了三个门,分别是遗忘门、输入门和输出门,LSTM单元的结构如图4所示。xt、yt和ht分别为t时刻的输入数据、输出数据和隐藏层的输出数据。对于输入的时间序列,LSTM网络可以使用细胞来确定之前的序列是否对预测有影响。影响越大,权重越高。为了防止梯度爆炸,低影响力的数据会被遗忘。最后,整个网络得到遗忘门的输出数据ft、输入门的输出数据it、存储单元的状态值ct和最终输出门的预测结果ot[14]。 图4 LSTM单元结构Fig.4 The cell structure of LSTM block LSTM模型各门的输出公式如式(4)~式(9)所示[15]: ft=σ(Wf[xt,ht-1]+bf) (4) it=σ(Wi[xt,ht+1]+bi) (5) ct=ft⊗ct-1+it⊗g(Wc[xt,ht-1]+bc) (6) ot=σ(Wo[xt,ht-1]+bo) (7) ht=ot⊗g(ct) (8) yt=Wyht+by(9) 式中:σ()为sigmoid激活函数;g()为双曲正切激活函数;ht-1为上一层细胞的输出;xt为当前输入;W为权重矩阵;b为偏置向量。 实验数据来源于PORTAL(Portland Oregon regional transportation archive listing)提供的官方交通电子数据库。使用WA I-5、SR-14和SR500三条州际公路上共21个站点的交通数据作为实验对象。数据收集周期为43 d,从2019年10月16日—11月27日。图5为路网的环路探测器分布图。探测器的数据采集间隔为15 min,每个站点的交通流量为该道路上探测器流量之和。站点1581为目标站点,前36 d的数据作为预测模型的训练集,最后7 d的数据作为测试集进行测试。 图5 探测器分布Fig.5 Detectors distribution 对环路检测器采集到的数据进行检测。当数据异常或缺失时,使用周相似性或相邻点均值来处理数据,如式(10)所示[16]: (10) 式(10)中:k为观测数据的周期;xt-1、xt+1分别为t-1和t+1时刻目标站点的交通流量。 为提高算法精度及模型学习速度,使用Z-score标准化方法对数据x进行归一化。归一化值x*为 (11) 式(11)中:σ为数据的均值;μ为数据的标准差。 在实验中,为了评价和比较预测模型的性能,使用了平均绝对百分误差(mean absolute percentage error,MAPE)和均方根误差(root mean square error,RMSE)作为预测性能的评价指标。 (12) (13) 利用改进的KNN算法计算各站点与目标站点的流形距离,各站点的流形距离和欧式距离如图6所示。经过多次实验,选流形距离数值最小的8个站点的交通流量(即k=8)构造交通流数据集训练LSTM模型。在训练LSTM模型前,先对数据集进行预处理。LSTM模型层数设置为4层,包含一个输入层、两个隐藏层和一个输出层。节点数分别为9、20、40和1。其他最优结构参数:优化器使用Adam,学习率设置为0.01,最大迭代数为500次,在250次时乘以迭代因子0.5降低学习率。预测时,利用滚动预测方法,即把实测数据作为已知数据继续进行预测,预测结果如图7所示。 图6 目标站点与各站点间的相关性度量Fig.6 The corrdlation measurement between target site and other sites 图7 MDKNN-LSTM预测值Fig.7 The prediction results of MDKNN-LSTM 为了评价MDKNN-LSTM模型的预测性能,将ARIMA(autoregressive integrated moving average model)、SVR(support vector regression)、LSTM和KNN-LSTM模型的预测结果作为对比。每个模型的实测数据与预测数据之间的EMAPE和ERMSE结果如表1所示。预测结果表明,MDKNN-LSTM的预测精度最高,EMAPE降至9.28%。与常规的KNN-LSTM相比,EMAPE和ERMSE分别下降了1.48%和6.48。更重要的是,多站点输入的LSTM模型的预测效果要比单一输入的LSTM模型的效果更好。这说明空间特性因素对短时交通流的预测至关重要,可以有效地提高预测精度。此外,基于深度神经网络的预测结果要优于ARIMA和SVR等传统模型。其中,SVR的ERMSE较ARIMA低5.96,但其EMAPE则较ARIMA高0.34%。这是因为当交通流量较低时,SVM的预测性能较差。 表1 短时交通流预测模型误差评价指标比较Table 1 Comparison of error evaluation indexes of short-term traffic flow prediction models 准确的高速公路短时交通流预测可以为交通管理和道路规划提供有效的帮助。提出了一种利用流形距离来预测交通流量的KNN-LSTM算法。经试验验证,得出以下结论。 (1)交通流的时空特性和流形特性可用于提高短时交通流预测的准确性。 (2)流形距离比传统的欧式距离更能反映上下游站点对交通流的影响。 (3)KNN和LSTM的混合模型比单一模型的预测效果更好。 但该预测模型也存在着局限性,比如预测模型较为复杂、预测所需时间长及预测没有考虑到交通事故、大型车辆比例等外部因素对交通流的影响。因此,下一步的工作将集中在寻找优化算法优化模型参数并将影响交通流的外部因素纳入预测模型,从而进一步提高预测精度。2.2 LSTM网络
3 实验与结果分析
3.1 数据来源

3.2 数据预处理及误差定义指标
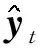
3.3 预测结果及分析


4 结论
