基于Hadoop技术的高校数字图书馆文献检索方法研究与设计
2020-07-29张小娟张永恒杨斐
张小娟 张永恒 杨斐

摘 要: 传统方法评价结果高于MAP@all标准值,为了解决这一问题,提出了基于Hadoop技术的高校数字图书馆文献检索方法。运用Hadoop算法提取语义关键词,再根据文献检索关键词计算流程计算语义相似度。完成上述工作后,运用快速匹配法,获得每个主题关键字比重权值。考虑不同主题生成文档权值不同,构建文献检索模型,实现高效数字图书馆文献检索。由此,完成基于Hadoop技术的高校数字图书馆文献检索方法的设计。实验中,在ACM数字图书馆中选取数据 40 000篇文献,用于评价两种方法的MAP@all值。实验结果表明,所提方法MAP@all值小于0.004 0,传统方法MAP@all值高于0.004 0。由此可知,所提方法的漏查率较低,符合设计需求。
关键词: Hadoop技术; 高校数字图书馆; 文献检索; 语义相似度; 文本向量; 先验概率; 相似度矩阵
中图分类号: TP 391文献标志码: A
Research and Design of Document Retrieval Method of University
Digital Library Based on Hadoop Technology
ZHANG Xiaojuan, ZHANG Yongheng, YANG Fei
(School of Information Engineering, Yulin University, Yulin, Shanxi 719000, China)
Abstract: The evaluation results of traditional methods are higher than the MAP@ all standard value. In order to solve this problem, this paper proposes the document retrieval of university digital library based on Hadoop technology. The method uses Hadoop algorithm to extract semantic keywords, and then calculate semantic similarity according to the process of keyword calculation. After completing the above work, we use the fast matching method to obtain the proportion weight of each subject key. Considering the different weight of documents generated by different topics, a document retrieval model is constructed to realize efficient document retrieval in digital library. Therefore, the design of document retrieval method of university digital library based on Hadoop technology is completed. In the experiment, 40 000 documents were selected from ACM digital library to evaluate the MAP @ all value of the two methods. The experimental results show that the MAP @ all value of the proposed method is less than 0.004 0, and the MAP@ all value of the traditional method is higher than 0.004 0. It can be seen that the miss rate of the proposed method is low, and it meets the design requirements.
Key words: Hadoop technology; university digital library; document retrieval; semantic similarity; text vector; prior probability; similarity matrix
0 引言
在1995年美国数字图书馆就已经走在世界各国的前列。当前,国内的图书馆资料大多是以纸质为主,要实现数字图书馆就需要将纸质材料信息化。并在现有的电子文档和视频资源基础上,构建数字图书馆的资料库[1]。据报道大部分学校都建立了中国期刊网站点,维普中文科技期刊数据库和万方数据库都已被广泛采用。
传统文献检索方法运用分层次检索模型判断信息,这对用户所输入的检索字段准确性要求很高,导致返回结果出现很多无关数据。为了解决这一问题,提出基于Hadoop技术的高校数字图书馆文献检索方法。Hadoop技术是基于Map 编程思想的分布式计算环境。运行原理:将一个任务分解成多个子任务。这些子任务会被分配到不同服務器计算。Hadoop能够保证每一次运算结果的可靠性,当Hadoop在同一时间维护了多个工作数据副本,就会重新分配计算任务,保证文献检索的准确性。基于Hadoop技术的高效数字图书馆文献检索方法的具体实现过程如下。
1 文献检索语义关键词提取
先处理输入文本,删除文本中的数字和标点符号,再根据Hadoop算法对文本进行分词。分词后,删除不符合的关键词[2]。在语义分析的过程中,字词不是处理目标,词义才是处理对象。当一个文本中出现单个词或者组合词时,要在WORDNET中寻找,词义分析表达式为式(1)。
其中,s表示词义,t表示处理对象,k表示组合词。
运用公式(1)即可在WORDNET中寻找对应的含义。为了更精准的获取候选词的词义,要消除歧义,分析语句消歧词的语句,运用Hadoop技术得到候选词词义[3]。计算式为式(2)。
其中,k表示语句,用SenseScore函数计算s词义相关度,c表示所有词集合。
分析上下文集合c的语句时,要先消歧s,若s可以直接在语义表内找到对应候选词,即可运用(2)进行消歧处理[3]。在计算的过程中,要迭代计算词s和c中所有词的相关度大小。通过比较每个词义相关度,提取关键词。排序结果最大的候选词就是正确的词义。
2 文献检索语义相似度计算
在提取文献检索语义关键词后,考虑到文献所包含的语义与关键字的语义会出现模糊问题,在方法的计算思路上,选择Hadoop算法计算文献检索语义相似度[4]。计算过程展示如下。
文献检索关键词计算流程,如图1所示。
图1中的wn为计算的关键字样本1和样本2的潜在的n个关键词分向量[5]。
基于Hadoop的文本向量为d=(w1,w2,w3,…,wn),n为潜在主题数目。两个文本的相似度计算公式为式(3):
其中,d1,d2表示待计算的两个文本向量,θ表示这两个文本向量的夹角,d1wi表示d1文本的第
wi个分向量。运用公式(3)即可避免模糊问题[6]。
在计算的过程中,要使用关键字作为文本分量,根据表1填充文本相似度矩阵的行和列,如表1所示。
运用表1时,要注意以下几点;
(1) 矩阵不是对称,在两个矩阵单元的文本关键字相似度计算时,不同主题下的关键字计算结果不同,但这不是一个对称矩阵[7]。
(2) 计算过程复杂,当文本中包含很多关键字时,不同关键字可能处于不同主题下,计算过程较为复杂,需要在后续数据挖掘的过程中不断改进[8]。
3 文献检索设计
先提取文献检索关键词,再计算语义相似度[9]。为了更好的满足高校学生的需求,运用快速匹配法,获得每个主题关键字的比重权值,计算式为式(4)。
其中,T表示关键词总数,freq(keyi)表示关键词key次数,p表示输入文字[10]。
运用公式(4)计算每个关键词出现的次数,即为关键字在输入文字p中的权重。
考虑不同主题生成的文档权值不同,需要构建文献检索模型[11]。基于Hadoop技术的高校数字图书馆文献检索模型,如图2所示。
当文本在处理阶段时,需要预先处理文本数据源,利用Hadoop算法逐一计算,得到关键词下文献的权重。利用文献间的引用关系构建应用网络[12]。网络中的每个顶点代表一篇文献,每条边代表一个引文上下文。运用Hadoop技术得到一个有向网络图,用于改变不同主题下的先验概率分布情况。其次,当用户生成查询时,用户检索词可以是一段上下文信息的文本。当文本处于匹配查找阶段,系统会预先处理输入长文本,将涉及到的主体关键字进行基于Hadoop技术的匹配查询工作[13]。考虑到不同关键字下文献相对权重不同,需要根据用户需求计算每一篇文献的先验概率。
在完成文献检索模型构建后,需要对提出的基于Hadoop技术的高校数字图书馆文献检索模型进行评价[14]。研究中,采用常用的评价指标,选取准则为,要选取一定量已知摘要,输入这部分文字,将文献已知的引用信息作为评价标准,用于比对文献推荐结果和标准结果。在NDCG评价指标过程中,要先划分每个数据的权重,划分原则为,测试数据中的文献若被引用 ,权值应大于0.若测试数据中的文献未被引用,权值应为0。对于已经引用的测试数据应根据被引次数确定权值,权值应为1-4。若被测数据引用过1次,权值应为1。若被测数据引用次数大于4次,权值应为4[15]。
基于Hadoop技术的高校数字图书馆文献检索方法实现,具体检索流程如下;
Step1,输入任意长度文本,系统会根据给定的信息找出有关输入对象的相关文献,并以相似度大小的排序结果给出。
Step2,在输入文本信息后,会直接给出相关文献检索结果。
Step3 ,点击每条文献给定的连接,从高校官方网站中浏览文献的详细信息。
Step4,系统提供高级检索,可以调整相关参数,得到不同检索结果。
Step5,参数值会影响检索结果,若用户在意文本相似度,参数1应该取值更大。若用户更关注特定主题下的结果,参数2应该取值更大。若用户更关注近几年发表的文献,参数3应该取值更大。
由此,完成基于Hadoop技术的高校数字图书馆文献检索方法的设计。
4 仿真测试析
4.1 实验数据及实验环境
实验针对基于Hadoop技术的高校数字图书馆文献检索方法设计的关键要素设置实验环境。首先,采用MATLAB仿真软件作为实验平台,在ACM数字图书馆中选取数据 40 000篇文献,计算这些文献在3 500个主题下的权值。主题个数是由Hadoop技术训练得到的。涵盖了ACM数据集中使用频率最高的关键词。全部文献的权重之和为1。运用这些数据,構成文献检索的训练数据。为了评价传统方法和基于Hadoop技术的高校数字图书馆文献检索方法的效率,选取200篇文献,分别采用传统方法和基于Hadoop技术的高校数字图书馆文献检索方法对200篇文献进行检索。实验数据具有以下特点;
(1) 第一,这200篇文献都可以获取全文信息。其中,摘要的字数长度为200字左右,全文信息长度为1 000字左右。
(2) 可以保证检验数据的准确性。
(3) 这200篇文献都包含20条文献。这些文献是指定的。
(4) 文献贡献值较高。
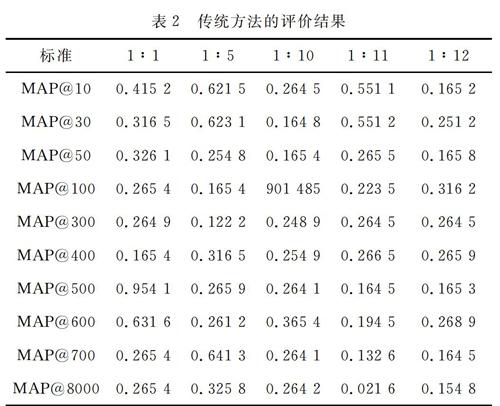
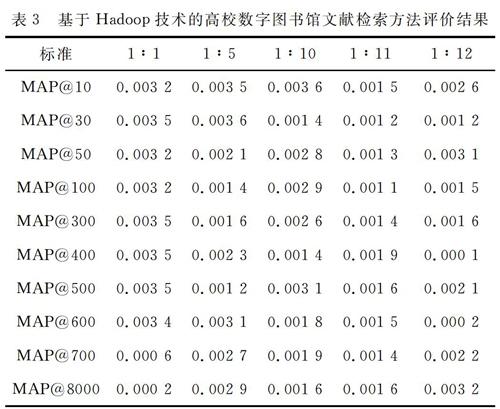
以MAP@all值作为实验评价标准,MAP@all值表示文献检索中所有类别漏查率的平均值。MAP@all的标准值为0.004 0。
4.2 结果与分析
传统方法和本文方法评价结果如表2和表3所示。
由表2和表3可知,使用传统方法的评价结果较差。出现这样的原因是因为在文献检索时,没有考虑到被检索的文本信息。基于Hadoop技术的高校数字图书馆文献检索方法的评价结果在0.003 0左右,低于标准值,漏查率较低,符合设计需求。由此,证明所建的基于Hadoop技术的高校数字图书馆文献检索方法符合设计需求。
5 总结
针对传统方法存在的问题,提出基于Hadoop技术的高校数字图书馆文献检索方法。先提取文献检索关键词,再计算文献语义相似度,完成上述工作后,构建高效数字图书馆文献检索模型的构建,实现文献检索。由此,完成本次设计。
上接第13页)
参考文献
[1] 谷参. 基于分布式结构的图书馆信息检索服务系统研究[J]. 现代电子技术, 2017, 40(1):83-85.
[2] 徐彤陽, 任浩然. 数字图书馆图像资源检索框架的构建与实现——基于非下采样的Contourlet变换[J]. 现代情报, 2017, 37(6):55-60.
[3] 魏晓萍, 李红培. 基于RFID的低利用率文献高密度存储——上海大学图书馆RFID密集库建设实践[J]. 图书馆理论与实践, 2017.22(10):88-91.
[4] 刘飞. 基于4I营销原则的高校图书馆阅读推广研究[J]. 图书馆工作与研究, 2017, 1(9):36-39.
[5] 王翠英. 基于经典扎根理论的我国高校图书馆FOLKSONOMY实施机制实证研究[J]. 情报科学, 2017, 35(1):90-102.
[6] 顾海兵, 朱凯. 国家经济安全指标确定和修正的文献检索法:方法论与案例[J]. 南京社会科学, 2017.32(3):26-33.
[7] 张聪, 赵怡晴. 基于Hadoop技术的突水治理平台的云服务及实现[J]. 工业安全与环保, 2017, 43(12):16-20.
[8] 韩平平, 张祥民. Hadoop数据存储分析技术在风电并网系统中的应用[J]. 电力系统及其自动化学报, 2018, 30(1):43-50.
[9] 蒙杰, 杨生举. 基于Hadoop的海量科技信息资源管理系统设计与实现[J]. 科技管理研究, 2017, 37(13):181-186.
[10] 于万钧, 沈斌. 基于角色与信任的访问控制及其在Hadoop上的实现[J]. 现代电子技术, 2017, 40(24):9-11.
[11] 高玉平. 海量图书检索信息的快速查询系统优化设计研究[J]. 现代电子技术, 2017, 40(6):13-17.
[12] 韩正彪, 罗瑞. 学术用户情感控制与心智模型对信息检索绩效影响的实验研究[J]. 情报理论与实践, 2017, 40(1):59-64.
[13] 周栋, 赵文玉. 个性化跨语言信息检索中结果重排序研究[J]. 计算机工程与科学, 2017, 39(10):1922-1929.
[14] 江小燕, 王明辉. 基于本体的PPP项目风险信息建模与检索[J]. 土木工程与管理学报, 2018, 35(1):66-72.
[15] 袁敏, 段景辉. 基于云计算环境下的信息检索及智能融合的研究[J]. 现代电子技术, 2018, 41(6):162-164.
(收稿日期: 2019.12.12)
基金项目:陕西省教育科学规划课题(编号:SGH18H418);陕西省教育厅科学研究项目(编号:18JK0909);陕西省教育科学规划课题(编号: SGH17H282)
作者简介:
张小娟(1981-),女,硕士,讲师,研究方向:信息组织与检索、云计算、知识图谱与大数据分析。
张永恒(1968-),男,硕士,教授,研究方向:计算机应用与技术、云计算、农业大数据等。
杨斐(1982-),男,硕士,副教授,研究方向:大数据、电子商务等。
